가변성을 제한하라
- 상태를 구현하는 방법
var프로퍼티 사용mutable객체 사용 (MutableList,MutableSet등)
- 상태를 가질 때 문제점
- 상태를 추적해야되기 때문에, 프로그램을 이해하고 디버그하기 힘들어진다.
- 시점에 따라서 값이 달라질 수 있으므로, 코드의 실행을 추론하기 어려워진다.
- 멀티스레드 프로그램일 때는 적절한 동기화가 필요하다.
- 모든 상태를 테스트해야 하므로, 테스트하기 어렵다.
- 상태 변경이 일어날 때, 이러한 변경을 다른 부분에 알려야 하는 경우가 있다.
코루틴: 프로그램의 실행 흐름을 일시적으로 중단하고, 나중에 중단한 시점부터 실행을 재개할 수 있는 멀티 태스킹 기법. 코틀린 공식 라이브러리 중에 이를 지원하는 라이브러리가 있다. https://kotlinlang.org/docs/coroutines-overview.html
코틀린에서 가변성 제한하기
- 읽기 전용 프로퍼티(val) 사용하기
- 읽기 전용 프로퍼티에 mutable 객체를 담고 있으면 여전히 상태가 존재하니 유의한다.
- 읽기 전용 프로퍼티에서 사용자 정의 getter를 사용하면 상태가 존재할 수 있으니 유의한다.(사용자 정의 getter에 var 프로퍼티를 사용하는 경우)
- val은 var로 오버라이드할 수 있다.
- 읽기 전용 프로퍼티에서 사용자 정의 getter를 사용하면 스마트 캐스트가 불가능해진다.
- val 프로퍼티는 여전히 변경될 수 있지만, 참조 자체를 변경할 수는 없으므로 동기화 문제를 줄일 수 있다.
interface Element {
val active: Boolean
}
class ActualElement: Element {
override var active: Boolean = false
fun toggle() {
active = !active
}
}
- 가변 컬렉션과 읽기 전용 컬렉션 구분하기
- mutable이 붙은 인터페이스는 대응되는 읽기 전용 인터페이스를 상속받아서, 변경을 위한 메서드를 추가한 것이다.
- 읽기 전용 컬렉션은 실제로 불변하게 만들지 않았다.
- 내부적으로 immutable 하지 않은 컬렉션을 외부적으로 immutable하게 보이게 만들어서 안정성을 얻는다.
- 읽기 전용 컬렉션을 가변 컬렉션으로 다운캐스팅하면 계약을 위반하고, 추상화를 무시하게 된다.

listOf()는 자바의List인터페이스를 구현한Array.ArrayList인스턴스를 리턴한다. 자바의List는add와set같은 메서드를 제공해서,MutableList로 다운캐스팅이 가능한데,Array.ArrayList는 이러한 연산을 구현하고 있지 않다. 다운캐스팅을 사용하면 문제가 될 수 있다.
- 읽기 전용에서 mutable로 변경해야 한다면, 복제를 통해서 새로은 mutable 컬렉션을만드는 list.toMutableList를 활용해야 한다.
- immutable 객체의 장점
- 한 번 정의된 상태가 유지되므로, 코드를 이해하기 쉽다.
- immutable 객체는 공유했을 때도 충돌이 따로 이루어지지 않으므로, 병렬 처리를 안전하게 할 수 있다.
- immutable 객체에 대한 참조는 변경되지 않으므로, 쉽게 캐시할 수 있다.
- immutable 객체는 방어적 복사본을 만들 필요가 없다. 또한 객체를 복사할 때 낖은 복사를 따로 하지 않아도 된다.
- immutable 객체는 다른 객체를 만들 때 활용하기 좋다.
- immutable 객체는 set 또는 map의 키로 사용할 수 있다. 아래 사진은 가변 객체가 set 과 map에서 사용할 수 없는 이유다.

- immutable 객체의 단점
- 변경이 필요하면 자신의 일부를 수정한 새로운 객체를 만들어 내는 메서드를 가져야 한다.

class User(
val name: String,
val surname: String
) {
fun withSurname(surname: String) = User(name, surname)
}
- 데이터 클래스의 copy
- data 한정자는 copy라는 이름의 메서드를 만들어준다.
- copy 메서드: 모든 기본 생성자 프로퍼티가 같은 새로운 객체를 만들어 낼 수 있다.
다른 종류의 변경 가능 지점
- 변경할 수 있는 리스트를 만드는 선택지
- mutable 컬렉션 만들기
- var로 읽고 쓸 수 있는 프로퍼티 만들기
- mutable 컬렉션 만들기
- 리스트 구현 내부에 변경 가능 지점이 있어서, 멀티스레드 처리가 이루어질 경우, 내부적으로 적절한 동기화가 되었는지 확실하게 알 수 없다.
- var로 읽고 쓸 수 있는 프로퍼티 만들기
- 멀티스레드 처리의 안정성이 더 좋다.
- 사용자 정의 setter를 통해 변경을 추적하기 쉽다.
- setter를 private로 만들어서 객체 밖에서 리스트가 변경되는 것을 막을 수도 있다.

변경 가능 지점 노출하지 말기
- 상태를 나타내는 mutable 객체를 외부에 노출하는 것은 굉장히 위험하다.

- mutable 객체를 외부에 노출하는 경우 처리 방법
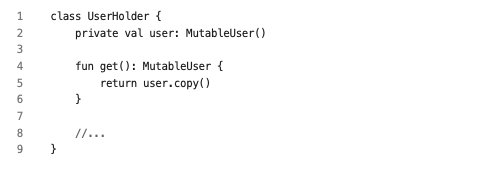
- 방어적 복제: copy 메서드 활용
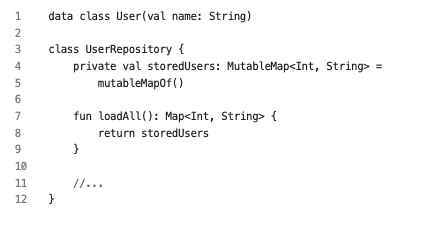
- 읽기 전용 슈퍼타입으로 업캐스트
- 방어적 복제: copy 메서드 활용
변수의 스코프를 최소화하라
- 상태를 정의할 때는 변수와 프로퍼티의 스코프를 최소화하는 것이 좋다.
- 프로퍼티보다는 지역 변수를 사용하는 것이 좋다.
- 최대한 좁은 스코프를 갖게 변수를 사용한다.
- 스코프를 좁게 만드는 것이 좋은 이유: 프로그램을 추적하고 관리하기 쉽다.
- mutable 프로퍼티가 좁은 스코프에 걸쳐 있을수록, 그 변경을 추적하는 것이 쉽다.
- 변수의 스코프 범위가 너무 넓으면, 다른 개발자에 의해 변수가 잘못 사용될 수 있다.
- 변수는 정의할 때 초기화하는 것이 좋다. if, when ,try-catch, Elvis 표현식 등을 활용하면, 최대한 변수를 정의할 때 초기화할 수 있다.
- 여러 프로퍼티를 한꺼번에 설정해야 하는 경우에는 구조분해 선언을 활용하는 것이 좋다.
캡처링
- 변수 스코프를 유의하지 않으면 시퀀스 사용시 캡처링으로인해 의도하지 않는 동작이 나올 수 있다.
- 아래 예시는 시퀀스의 filter가 지연 처리되면서 모두 최종적은 prime 값으로 필터링되고 있다.

generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence<T>seed부터 시작해서 nextFunction으로 다음 값을 구하는 시퀀스 생성 https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.sequences/generate-sequence.html
yield(value: T)Iterator에게 다음 값을 전달 https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.sequences/-sequence-scope/yield.html
drop(): 시퀀스의 첫번째 값 제거 https://kotlinlang.org/api/latest/jvm/stdlib/kotlin.sequences/drop.html
최대한 플랫폼 타입을 사용하지 말라
- 자바에서
String타입을 리턴하는 메서드가 있는 경우@Nullable어노테이션이 붙어 있으면, 코틀린에서String?으로 변경@NotNull어노테이션이 붙어 있으면, 코틀린에서String으로 변경- 아무것도 붙어있지 않는다면 문제가 될 수 있다.
- 플랫폼 타입: 다른 프로그래밍 언어에서 전달되어서 nullable 인지 아닌지 알 수 없는 타입
- 자바를 코틀린과 함께 사용할 때, 자바 코드를 직접 조작할 수 있다면, 가능한
@Nullable과@NotNull어노테이션을 붙여서 사용해라. - 현재 다음과 같은 여러 어노테이션을 지원하고 있다.(참고)
- JetBrains (
@Nullableand@NotNullfrom theorg.jetbrains.annotationspackage) - JSpecify (
org.jspecify.nullness) - Android (
com.android.annotationsandandroid.support.annotations) - JSR-305 (
javax.annotation, more details below) - FindBugs (
edu.umd.cs.findbugs.annotations) - Eclipse (
org.eclipse.jdt.annotation) - Lombok (
lombok.NonNull) - RxJava 3 (
io.reactivex.rxjava3.annotations)
- JetBrains (
- 코틀린 코드에서는 플랫폼 타입은 안전하지 않으므로, 최대한 빨리 제거하는 것이 좋다.
- 10번 라인처럼 플랫폼 타입을 바로 제거하면, 자바에서 값을 가져오는 위치에서 NPE가 발생해서 null이 발생하는 위치를 쉽게 추적할 수 있다.
- 18번 라인처럼 플랫폼 타입 사용을 오래 유지시키면, 실제로 값을 사용할 때 NPE가 발생해서 null이 발생하는 위치를 추적하기 어렵다.



inferred 타입으로 리턴하지 말라
- 할당 할 때 inferred 타입은 정확하게 오른쪽에 있는 피연산자에 맞게 설정된다.
- 절대로 슈퍼클래스 또는 인터페이스로는 설정되지 않는다.

- 원하는 타입보다 제한된 타입이 설정되었다면, 타입을 명시적으로 지정해서 문제를 해결할 수 있다.
- 리턴 타입은 API를 잘 모르는 사람에게 전달해 줄 수 있는 중요한 정보다.
- 따라서 리턴 타입은 외부에서 확인할 수 있게 명시적으로 지정해 주는 것이 좋다.
예외를 활용해 코드에 제한을 걸어라
- 확실하게 어떤 형태로 동작해야 하는 코드가 있다면, 예외를 활용해 제한을 걸어주는 것이 좋다.
- require 블록: 아규먼트를 제한할 수 있다.
- check 블록: 상태와 관련된 동작을 제한할 수 있다.
- assert 블록: 어떤 것이 true인지 확인할 수 있다. assert 블록은 테스트 모드에서만 작동한다.
- return 또는 throw와 함꼐 활용하는 Elvis 연산자

- 제한을 걸어주면 얻는 장점
- 제한을 걸면 문서를 읽지 않는 개발자도 문제를 확인할 수 있다.
- 문제가 있을 경우에 함수가 예상하지 못한 동작을 하지 않고 예외를 throw 한다.
- 코드가 어느 정도 자체적으로 검사된다.
- 스마트 캐스트 기능을 활용할 수 있게 되므로, 캐스트를 적게할 수 있다.
아규먼트
- 함수를 정의할 때 타입 시스템을 활용해서 아규먼트에 제한을 거는 코드를 많이 사용한다.
- 이와 같은 형태의 입력 유효성 검사 코드는 함수의 가장 앞부분에 배치되므로, 읽는 사람도 쉽게 확인할 수 있다.
require함수는 조건을 만족하지 못할 때 무조건적으로IllegalArgumentException을 발생시키므로 제한을 무시할 수 없다.
require 함수를 통해서 커스텀 예외를 던질 수 있는지 확인해보니 불가능한 것으로 보인다.
상태
- 어떤 구체적인 조건을 만족할 때만 함수를 사용할 수 있게 해야 할 때가 있다.
- 어떤 객체가 미리 초기화되어 있어야만 처리를 하게 하고 싶은 함수
- 사용자가 로그인했을 때만 처리를 하게 하고 싶은 함수
- 객체를 사용할 수 있는 시점에 사용하고 싶은 함수
check함수는 지정된 예측을 만족하지 못할 때,IllegalStateException을 throw 한다.
Assert 계열 함수 사용
- 코틀린/JVM에서만 활성화되며,
-eaJVM 옵션을 활성화해야 확인할 수 있다. - 다만 프로덕션 환경에서는 오류가 발생하지 않는다.
- 단위 테스트 대신 함수에서 assert를 사용하면 얻는 장점
- Assert 계열의 함수는 코드를 자체 점검하며, 더 효율적으로 테스트할 수 있게 해준다.
- 특정 상황이 아닌 모든 상황에 대한 테스트를 할 수 있다.
- 실행 시점에 정확하게 어떻게 되는지 확인할 수 있다.
- 실제 코드가 더 빠른 시점에 실패하게 만든다. 따라서 예쌍하지 못한 동작이 언제 어디서 실행되었는지 쉽게 찾을 수 있다.
- 이를 활용해도 여전히 단위 테스트는 따로 작성해야한다.
- 표준 애플리케이션 실행에서는 assert가 예외를 throw하지 않기 때문이다.
nullability와 스마트 캐스팅
require와check블록으로 타입 비교를 했다면, 스마트 캐스트가 작동한다.require와cehck블록으로 null인지 확인할 때도 스마트 캐스트가 발생한다.- null 체크는
requireNotNull,checkNotNull이라는 특수한 함수를 사용해도 괜찮다. - nullability를 목적으로, 오른쪽에 throw 또는 return을 두고 Elvis 연산자를 활용하는 경우가 많다.
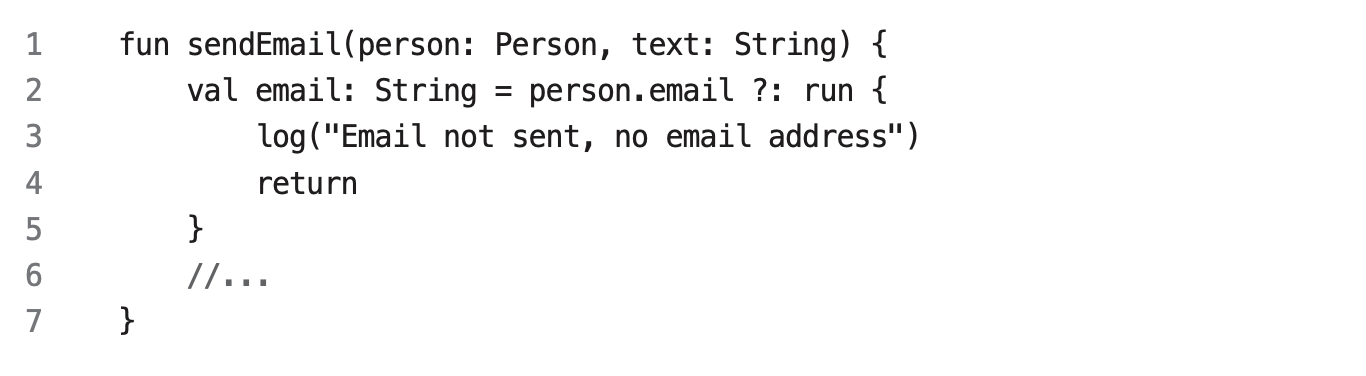
- 프로퍼티에 문제가 있어서 null일 때 여러 처리를 해야 할 때도, return/throw와
run함수를 조합해서 활용하면 된다.

사용자 정의 오류보다는 표준 오류를 사용하라
- 표준 라이브러리의 오류는 많은 개발자가 알고 있으므로, 이를 재사용하는 것이 좋다.
- 잘만들어진 규악을 가진 널리 알려진 요소를 재사용하면, 다른 사람들이 API를 더 쉽게 배우고 이해할 수 있다.
- 일반적으로 사용되는 예외
IllegalArgumentException,IllegalStateExceptionIndexOutOfBoundsException: 인덱스 파라미터의 값이 범위를 벗어났다는 것을 나타낸다. 일반적으로 컬렉션 또는 배열과 함께 사용한다.ConcurrentModificationException: 동시 수정을 금지했는데, 발생해 버렸다는 것을 나타낸다.UnsupportedOperationException: 사용자가 사용하려고 했던 메서드가 현재 객체에서는 사용할 수 없다는 것을 나타낸다.NoSuchElementException: 사용자가 사용하려고 했던 요소가 존재하지 않음을 나타낸다. 예를 들어 내부에 요소가 없는Iterable에 대해next를 호출할 때 발생한다.
결과 부족이 발생할 경우 null과 Failure를 사용하라
- 함수가 원하는 결과를 만들어 낼 수 없을 때 처리하는 메커니즘
- null 또는 ‘실패를 나타내는 sealed 클래스(일반적으로 Failure라는 이름을 붙인다.)‘를 리턴한다.
- 예외를 throw한다.
- 예외를 정보를 전달하는 방법으로 사용해서는 안된다.
- 많은 개발자가 예외가 전파되는 과정을 제대로 추적하지 못한다.
- 코틀린의 모든 예외는 unchecked 예외다. 따라서 사용자가 예외를 처리하지 않을 수도 있으며, 이와 관련된 내용은 문서에도 제대로 드러나지 않는다.
- 예외는 예외적인 상황을 처리하기 위해서 만들어졌으므로 명시적인 테스트만큼 빠르게 동작하지 않는다.
- try-catch 블록 내부에 코드를 배치하면, 컴파일러가 할 수 있는 최적화가 제한된다.
- Failure 사용 예
inline fun <reified K, V> Map<K, V>.get2(key: K): Result<V> {
val nullable: V = get(key) ?: return Failure(IllegalStateException())
return Success(nullable)
}
sealed class Result<out T>
class Success<out T>(val value: T): Result<T>()
class Failure(val throwable: Throwable): Result<Nothing>()
fun main() {
val map = mutableMapOf(1 to "one")
val string = when(val result = map.get2(2)) {
is Success -> result.value
is Failure -> "error!"
}
println(string)
}
- null 값과 sealed result는 명시적이고, 효율적이며, 간단한 방법으로 처리할 수 있다.
- 충분히 예측할 수 있는 범위의 오류는 null과 Failure를 사용하고, 예측하기 어려운 예외적인 범위의 오류는 예외를 throw하는 것이 좋다.
- null vs sealed result
- 추가적인 정보를 전달해야 한다면 sealed result
- 그렇지 않으면 null
적절하게 null을 처리하라
- null은 ‘값이 부족하다’는 것을 나타낸다.
- 프로퍼티가 null이라는 것은 값이 설정되지 않았거나, 제거되었다는 것을 나타낸다.
- 함수가 null을 리턴한다는 것은 함수에 따라서 여러 의미를 가질 수 있다.
- 기본적으로 nullable 타입을 세 가지 방법으로 처리한다.
?., 스마트 캐스팅, Elvis 연산자 등을 활용해서 안전하게 처리한다.- 오류를 throw 한다.
- 함수 또는 프로퍼티를 리팩터링해서 nullable 타입이 나오지 않게 바꾼다.
null을 안전하게 처리하기
- 안전 호출과 스마트 캐스팅
printer?.print() // 안전 호출
if (printer != null) printer.print() // 스마트 캐스팅
- return과 throw 모두
Nothing(모든 타입의 서브 타입)을 리턴하게 설계되어서, Elvis 연산 오른쪽에 return 또는 throw을 포함하는 모든 표현식이 허영된다.

- 스마트 캐스팅은 [Kotlin Contracts](../../../../3-Resource/개발언어/Kotlin/Kotlin%20Contracts.md Contracts.md>)을 지원한다.
- 방어적 프로그래밍과 공격적 프로그래밍
- 방어적 프로그래밍: 모든 가능성을 올바른 방식으로 처리하는 것.
- 코드가 프로덕션 환경으로 들어갔을 때 발생할 수 있는 수많은 것들로부터 프로그램을 방어해서 안정성을 높이는 방법
- 공격적 프로그래밍: 예상하지 못한 상황이 발생했을 때, 이러한 문제를 개발자에게 알려서 수정하게 만든느 것.
require,check,assert
- 방어적 프로그래밍: 모든 가능성을 올바른 방식으로 처리하는 것.
오류 throw 하기
- null이 발생했을 때, 개발자에게 알리지 않고 코드가 그대로 진행되면, 개발자가 오류를 찾기 어려워질 수 있다.
throw,!!,requireNotNull,checkNotNull등을 활용한다.
not-null assertion(!!)과 관련된 문제
- not-null assertion을 사용하는 것은 좋은 해결 방법이 아니다.
- 예외가 발생할 때, 어떤 설명도 없는 제네릭 에외가 발생한다.
- 코드가 짧고 너무 사용하기 쉽다보니 남용하게 되는 문제도 있다.
- 현재는 null이 아니라고 확신하지만, 미래에 확실한 것은 아니다.
- 변수를 선언하고, 이후에
!!연산자를 사용하는 방법은 좋은 방법이 아니다.- 이후에 프로퍼티를 계속해서 언팩해야 하므로 번거롭다.
- 해당 프로퍼티가 실제로 이후에 의미 있는 null 값을 가질 가능성 자체를 차단해 버린다.
- 대신
lateinit또는Delegates.notNull()을 사용한다.
의미 없는 nullability 피하기
- nullability는 어떻게든 적절하게 처리해야 하므로, 추가 비용이 발생한다.
- null은 중요한 메시지를 전달하는 데 사용할 수 있다.
- nullability를 피할 때 사용할 수 있는 방법
- 클래스에서 nullability에 따라 여러 함수를 만들어서 제공할 수 있다.
List<T>의get과getOrNull함수 - 어떤 값이 클래스 생성 이후에 확실하게 설정된다는 보장이 있따면,
lateinit프로퍼티와notNull델리게이트를 사용해라. - 빈 컬렉션 대신 null을 리턴하지마라.
- nullable enum과
Noneenum 값은 와전히 다른 의미다. null enum은 별도로 처리해야 하지만,Noneenum은 정의에 없으므로 필요한 경우에 사용하는 쪽에서 추가해서 활용할 수 있다.
- 클래스에서 nullability에 따라 여러 함수를 만들어서 제공할 수 있다.
lateinit 프로퍼티와 notNull 델리게이트
- 초기화 전에
lateinit값을 사용하려고 하면 예외가 발생한다. lateinit과 nullable의 차이점!!연산자로 언팩하지 않아도 된다.- 이후에 어떤 의미를 나타내기 위해서 null을 사용하고 싶을 때, nullable로 만들 수도 있다.
- 프로퍼티가 초기화된 이후에는 초기화되지 않은 상태로 돌아갈 수 없다.
- JVM에서
Int,Long,Double,Boolean과 같은 기본 타입과 연결된 타입으로 프로퍼티를 초기화해야 하는 경우에는lateinit을 사용할 수 없다.Delegates.notNull을 사용한다.
class Person {
var age: Int by Delegates.notNull()
init {
age = 3
}
}
use를 사용하여 리소스를 닫아라
- 자바 표준 라이브러리에는
close메서드를 사용해서 명시적으로 닫아야 하는 리소스가 있다.InputStream과OutputStreamjava.sql.Connectionjava.io.Reader(FileReader, BufferedReader, CSSParser)java.new.Socket과java.util.Scanner
- 명시적으로 닫아야 하는 리소스는
AutoClosable을 상속받는Closeable인터페이스를 구현하고 있다. - 이러한 리소스는 최종적으로 리소스에 대한 레퍼런스가 없어질 때, 가비지 컬렉터가 처리한다.
- 하지만 처리되기까지 굉장히 느리며, 리소스를 유지하는 비용이 많이들어간다.
- 따라서 더 이상 필요하지 않는 리소스는 명시적으로
close메서드를 호출해 주는 것이 좋다.
- 전통적으로 이런 리소스는 try-finally 블록을 사용해서 처리했는데 단점이 있다.
- 리소스를 닫을 때 예외가 발생하는 경우를 처리하기위해, 코드가 복잡해진다.
- try 블록과 finally 블록 내부에서 오류가 발생하면, 둘 중 하나만 전파된다. 둘 다 전파되는 것이 불가능하다.
- 코틀린에서는 use 함수를 사용해서 앞의 코드를 적절하게 변경가능하다.
fun countCharactersInFile(path: String): Int {
return BufferedReader(FileReader(path)).use { reader ->
reader.lineSequence().sumOf { it.length }
}}
- 코틀린 표준 라이브러리는 파일을 한 줄씩 처리할 때 활용할 수 있는
useLines함수도 제공한다.- 이렇게 처리하면 메모리에 파일의 내용을 할 줄씩만 유지하므로, 대용량 파일도 적절하게 처리할 수 있다.
- 다만 파일의 줄을 한 번만 사용할 수 있다는 단점이 있다.
fun countCharactersInFile2(path: String): Int {
return BufferedReader(FileReader(path)).useLines { lines ->
lines.sumOf { it.length }
}}
use 메소드 내부와 close 메서드에서 둘 다 예외 발생시 확인 두 예외 모두 확인이 가능하다.
class CloseableClass : Closeable {
fun methodA() {
println("methodA() called")
}
override fun close() {
throw IllegalStateException("close 예외 발생!")
}
}
fun main() {
CloseableClass().use {
throw IllegalStateException("main 예외 발생!")
}
}

단위 테스트를 만들어라
- 단위 테스트에서 확인하는 내용
- 일반적인 유스케이스(happy path)
- 일반적인 오류 케이스와 잠재적인 문제: 제대로 동작하지 않을거라고 예상되는 일반적인 부분, 과거에 문제가 발생했던 부분 등
- 엣지 케이스와 잘못된 아규먼트:
Int.MAX_VALUE,null등
- 단위 테스트의 장점
- 테스트가 잘 된 요소를 신뢰할 수 있다.
- 테스트가 잘 만들어져 있다면, 리팩터링하는 것이 두렵지 않다.
- 수동으로 테스트하는 것보다 단위 테스트로 확인하는 것이 빠르다.
- 단위 테스트의 단점
- 단위 테스트를 만드는 데 시간이 걸린다. 하지만 장기적으로 좋은 단위 테스트는 디버깅 시간과 버그를 찾는 데 소모되는 시간을 줄여준다.
- 테스트를 활용할 수 있게 코드를 조정해야 한다. 변경하기 어렵기는 하지만, 이러한 변경을 통해서 훌륭하고 잘 정립된 아키텍처를 사용하는 것이 강제된다.
- 좋은 단위 테스트를 만드는 작업이 꽤어렵다. 잘못 만들어진 단위 테스트는 득보다 실이 크다.
- 다음과 같은 부분에 대해 단위 테스트하는 방법을 알고 있어야 한다.
- 복잡한 부분
- 계속해서 수정이 일어나고 리팩터링이 일어날 수 있는 부분
- 비즈니스 로직 부분
- 공용 API 부분
- 문제가 자주 발생하는 부분
- 수정해야 하는 프로덕션 환경 버그