- 성능은 곧 쿼리 응답 시간
- 쿼리 응답 시간: MySQL이 쿼리를 실행하는 데 소요되는 시간
- 같은 의미: 응답 시간, 쿼리 시간, 실행 시간, 쿼리 지연 시간
- 소요 시간: MySQL이 쿼리를 받았을 떄 시작되고 셜과 세트를 클라이언트에 전송한 시점까지의 경과 시간
핵심 지표#
- 갑작스럽게 벌어진 MySQL 성능 저하 현상은 여러 가지를 고려해야 해서 해결 방법을 파악하기 어려울 수 있다.
- 또한 MySQL 전문가가 아닌 응용 프로그램 엔지니어라면 이 문제가 크게 느껴질 수 있다.
- 이 때 쿼리 응답 시간은 실제 해결책으로 이어지는 2가지 특성이 있으므로 가장 먼저 살펴보야 한다.
- 의미 있는 것: 누구나 관심을 가지는 유일한 메트릭.
- 실행 가능한 것: 코드를 담당하고 있고 응답 시간을 직접 확인할 수 있다면 쿼리를 변경할 수 있다. 코드를 담당하지 않거나 접근 권한이 없을 때도 쿼리 응답 시간을 간접적으로 최적화 할 수 있다.
쿼리 보고#
- 쿼리 메트릭: 응답 시간, 잠금 시간, 조회된 행 등 쿼리 실행에 관하여 통찰력은 제공한다.
- 다른 메트릭과 마찬가지로 엔지니어에게 의미 있는 방식으로 수집, 집계, 보고해야 하는 원시 값
- 쿼리 메트릭 도구가 쿼리 메트릭을 쿼리 보고서로 변환한다.
- 쿼리 분석: 실제 수행할 작업
- 쿼리 실행을 이해하기 목적으로, 보고된 쿼리 메트릭가 메타데이터 등을 분석하게 된다
- 쿼리 메트릭과 관련된 3가지 개념
- 소스: 쿼리 메트릭은 2개의 소스에서 비롯되며 MySQL 배포 및 버전에 따라 다르다.
- 집계: 쿼리 메트릭 값은 정규화된 SQL 문법을 기준으로 그룹화되고 집계된다.
- 보고: 쿼리 보고서는 고급 프로파일과 쿼리에 특화된 보고서로 구성된다.
- 쿼리 메트릭을 제공하는 2가지 소스
- 슬로 쿼리 로그(slow query log): 로그 파일
- 성능 스키마(performance schema):
performance_schema 같은 이름의 데이터베이스
- 참고: 슬로 쿼리 로그 이름의 역사
- 예전에는 MySQL은 N초 이상 실행되는 쿼리들만 기록했고, 이때 N초의 최솟값은 1이었다.
- 오늘날엔 최솟값이 0이며 이렇게 설정하면 MySQL은 실행되는 모든 쿼리를 기록한다.
- N을 0으로 설정하면 모든 쿼리를 기록할 수 있지만, 디스크 입출력이 증가하고 상당한 양의 디스크 공간을 사용할 수 있기 때문에 주의해야된다.
- 슬로 쿼리 로그와 성능 스키마의 차이는 얼마나 많은 메트릭을 제공하는지다.
- 슬로 쿼리 로그는 기본적으로 비활성화되어 잇지만 MySQL을 다시 시작할 필요 없이 바로 활성화할 수 있다.
- 성능 스키마는 기본으로 활성화되어야 하지만 일부 클라우드 제공자는 비활성화를 기본으로 설정한다. 성능 스키마를 활성화하려면 MySQL을 다시 시작해야 한다.
- 쿼리 메트릭은 쿼리별로 그룹화되고 집계된다.
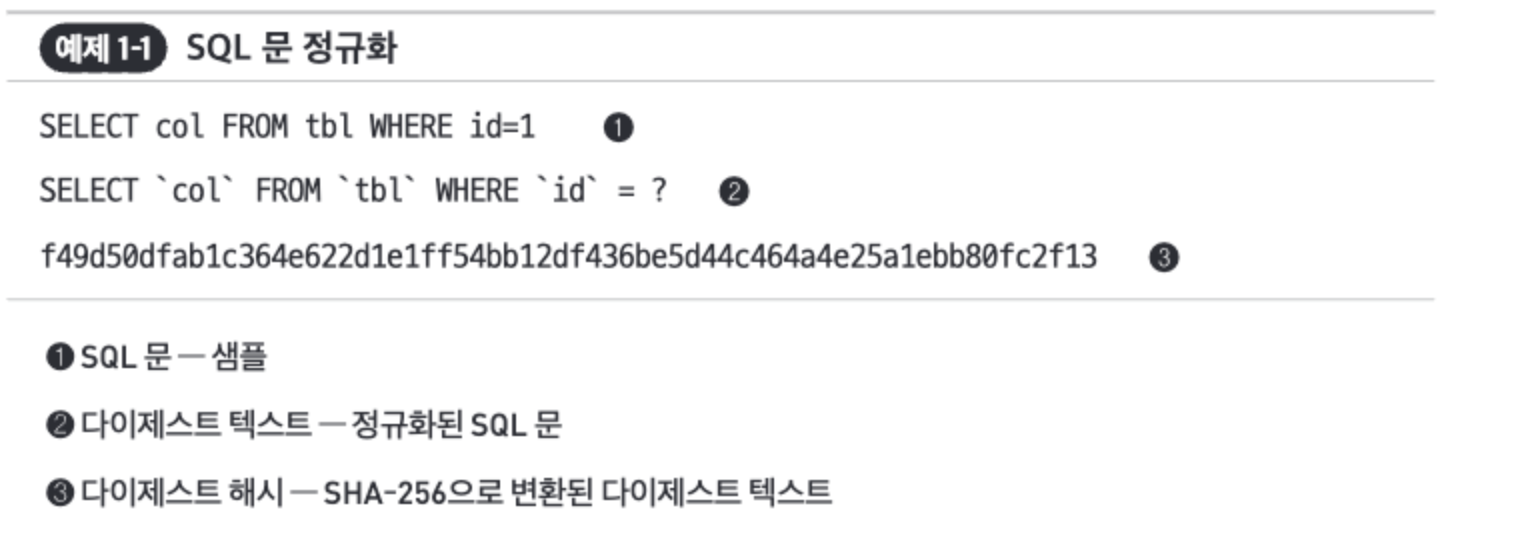
- 정규화된 SQL문을 SHA-256 해시로 변환하여 쿼리를 고유하게 식별된다.
- SQL 문을 정규화하여 다이제스트(digest) 텍스트를 생성한 다음, 이에 대해 SHA-256 해시를 계산해서 다이제스트 해시를 생성한다.
- 쿼리 메트릭의 맥락에서 ‘쿼리’라는 용어는 ‘다이제스트 텍스트’와 동의어다.
- SQL문은 ‘쿼리 샘플’이라고도 하며, 대부분의 쿼리 매트릭 도구는 (실제 값을 포함하고 있기 때문에)보안 때문에 샘플을 폐기하고 다이제스트 텍스트와 해시만 보고한다.
- 용어는 쿼리 메트릭 도구에 따라 크게 다르다.
- 쿼리 추상화: SQL 명령과 테이블 목록으로 고도로 추상회된 SQL 문
- 쿼리 추상화는 고유하지 않지만 간결해서 유용하다.
SELECT col FROM tbl WHERE id = 1 -쿼리 추상화-> SELECT tbl
WHERE 절은 쿼리 실행과 최적화에 영향을 미치므로 WHERE 절이 다르면, 정규화시에 다른 쿼리로 보고된다.- 아래 둘은 다른 쿼리다.

- 정규화시에 값은 제거되므로 다음 두 쿼리는 같은 다이제스트로 정규화된다.
- 거의 모든 쿼리 메트릭 도구는 쿼리 프로파일과 쿼리 보고서라는 2가지 수준의 계층 구조로 데이터를 제공한다.
- 쿼리 프로파일
- 느린 쿼리가 표시된다.
- 쿼리 보고를 위해 최상단에 구성된 것으로, 일반적으로 쿼리 메트릭 도구에 처음 표시되는 항목이다.
- 느림은 쿼리가 정렬되는 쿼리 메트릭의 집계치인 정렬 메트릭과 관련된다.
- 일반적으로 정렬 메트릭은 쿼리 시간이다.
- 정렬 메트릭은 평규적으로 전송된 행 수 등이 될 수 있다.
- 정렬 메트릭이 쿼리 시간이 아니더라도 첫 번쨰로 정렬된 쿼리를 가장 느리 쿼리라고 한다.
- 일반적으로 집계되는 쿼리 시간
- 쿼리 총시간: 쿼리당 실행 시간의 총합
- 쿼리 A의 응답시간이 1초이고 10번 실행, 쿼리 B의 응답시간이 0.1이고 1000번 실행
- B가 A보다 10배 더 많은 쿼리 총시간이 소요된다.
- 실행 시간 비율: 쿼리 총시간을 모든 쿼리의 실행 총시간으로 나눈 값
- 쿼리 C의 쿼리 총시간이 321ms, 쿼리 D의 쿼리 총시간이 100ms이면
- C는 76.2%, D는 23.8%
- 쿼리 부하: 쿼리 총시간을 클럭 타임으로 나눈 것
- 클럭 시간이 300초이고 쿼리 E의 쿼리 총시간이 250.2초이면 쿼리 부하는 0.83
- 쿼리 부하가 1.0보다 작으면 쿼리가 동시에 실행되지 않는다.
- 쿼리 부하가 1.0보다 크면 쿼리가 동시에 실행된 가능성이 높다.
- 쿼리 보고서
- 하나의 쿼리에 대해 알아야 할 모든 것을 보여준다.
- 쿼리 보고서는 메트릭 도구에 따라 달라진다.
- 기본적으로는 소스에서 비롯된 모든 쿼리 메트릭과 최소, 최대, 평균, 백분위수 등 해당 메트릭의 기본 통계값이 포함된다.
- 전체 보고서에는 쿼리 샘플, EXPLAIN 계획, 테이블 구조 등의 메타데이터가 포함된다.
- 쿼리 분석에는 보고서의 쿼리 메트릭만 있으면 된다.
- 메타데이터는 수동으로 수집할 수 있다.
- 만약 사용하는 쿼리 메트릭 도구가 쿼리 메트릭만 보고한다면 최소한
EXPLAIN 계획과 테이블 구조를 동으로 수집하는 것부터 시작해야된다.
쿼리 분석#
- 쿼리 분석의 목표: 느린 응답 시간을 해결하려는 것이 아니라 ‘쿼리 실행’을 이해하려는 것
- 느린 응답 시간을 해결하는 것은 쿼리 분석 후 쿼리 최적화 과정에서 이루어진다.
쿼리 메트릭#
- 성능 스키마는 9가지 필수 쿼리 메트릭을 제공한다.
- 쿼리 시간
- 가장 중요한 메트릭
- 쿼리 시간에는 또 다른 메트릭인 잠금 시간(lock time)이 포함된다.
- MySQL에서 성능 스키마로 이벤트를 수집하며, 이벤트는 다음과 같은 계층 구조로 구성된다.
- 트랜잭션: 최상위 이벤트
- 명령문: 쿼리 메트릭이 적용되는 쿼리
- 단계: 명령문 실행 과정 내의 단계. 명령문 구문 분석, 테이블 열기, 파일 정렬 수행과 같은 과정을 포함
- 대기: 시간이 걸리는 이벤트

- MySQL의 매뉴얼에서 이벤트의 정의: 시간이 소요되는 측정 정보를 수집할 수 있도록 구비된, 서버가 수행하는 모든 작업
- 아래는 단일
UPDATE 문 실행 과정에서 단계(stage)를 보여준다.stage/sql/updating에서 실제 UPDATE 문이 실행된다.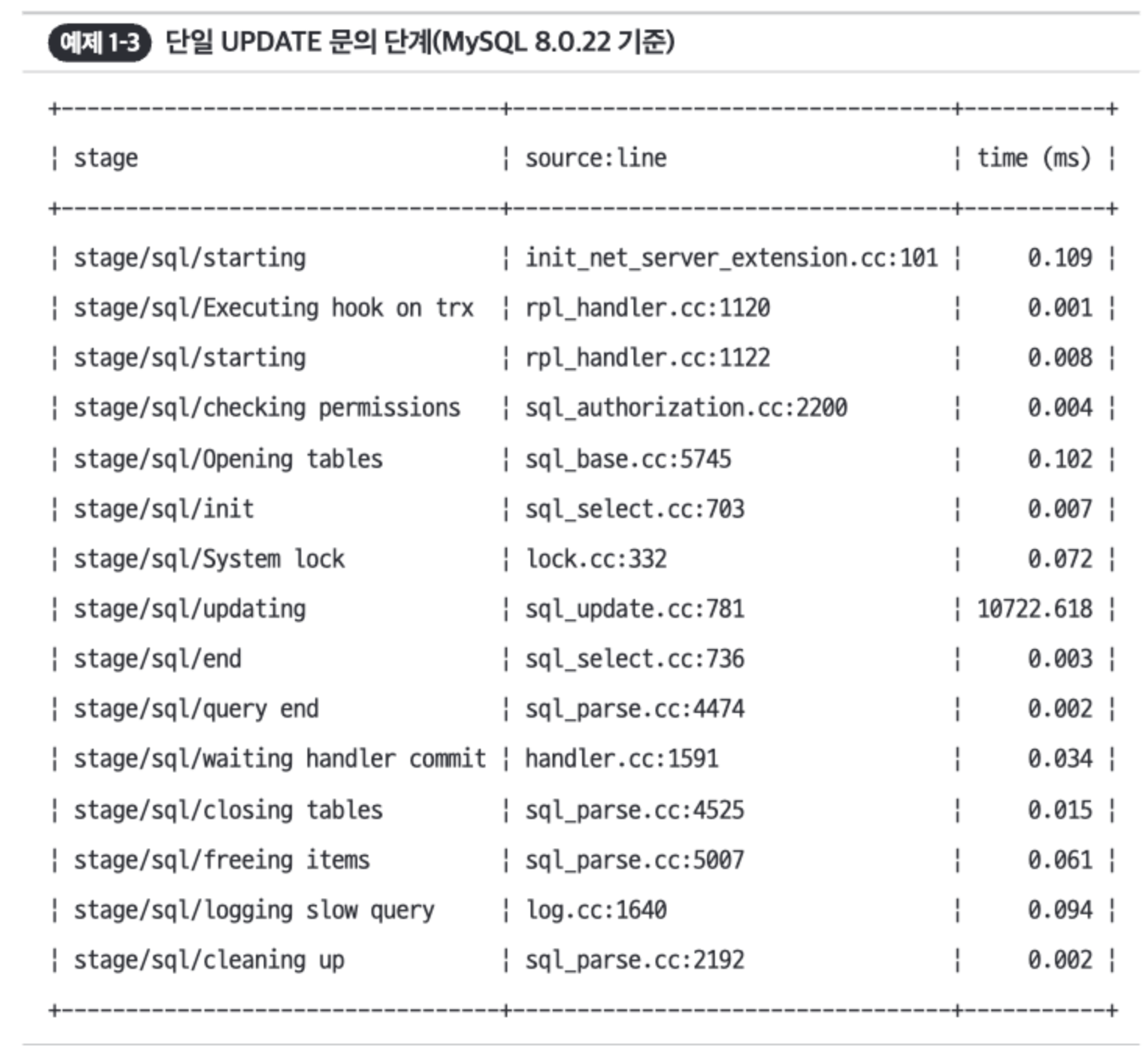
- 잠금 시간
- 쿼리를 실행하는 동안 락을 획득하여 사용한 시간
- 잠금 시간은 상대값이다.
- MySQL은 대기가 아니라 작업에 대부분의 시간을 사용해야 하므로 잠금 시간이 쿼리 시간의 50% 이상이면 문제라고 볼 수 있다.
- MySQL 스토리지 엔진과 락
- MySQL에는 많은 스토리지 엔진이 있지만, 기본 스토리지 엔진은 InnoDB이다.
- InnoDB 스토리지 엔진에는 테이블 락과 로우 락이 있다.
- 테이블 락은 스토리지 엔진 종류에 구애받지 않지만, 로우 락은 InnoDB 같이 지원하는 스토리지 엔진에서만 동작한다. 로우 락을 지원하지 않는 경우에는 테이블 락으로 데이터에 접근한다.
- innoDB는 로우 레벨 락을 지원하므로 달리 언급하지 않는 한 데이터 접근시 로우 레벨 락을 사용한다.
- 서버에서 관리하는 메타데이터 락이 있는데 스키마, 테이블, 저장 프로그램 등의 접근을 제어한다.
- 테이블 락과 로우 락은 테이블 데이터에 대한 접근을 제어하지만, 메타데이터 락은 테이블 구조에 대한 접근을 제어하여 테이블에 접근하는 동안 변경되는 것을 방지한다.
- 모든 쿼리는 접근하는 모든 테이블을 대상으로 메타데이터 락을 획득한다.
- 메타데이터 락은 쿼리가 아니라 트랜잭션이 끝날 때 해제된다.
- 락 종류
- 공유 락(shared lock): 다른 공유 락이 동시에 획득되지만, 배타적 락은 얻지 못한다.
- 배타적 락(exclusive lock): 다른 공유 락과 배타적 락을 얻지 못한다.
- 성능 스키마의 잠금 시간: 로우 락 대기가 포함되지 않고 테이블과 메타데이터 락 대기만 포함한다.
- 슬로 쿼리 로그의 잠금 시간: 로우 락, 테이블 락, 메타데이터 락 모두 포함한다.
INSERT, UPDATE, DELETE, REPLACE 같은 쓰기에는 로우 락을 획득하므로 응답 시간이 잠금 시간에 따라 달라진다.- 로우 락을 획득하는데 필요한 시간은 동시성에 따라 다르다.
- 읽기에는 비잠금 읽기(nonlocking reads)와 잠금 읽기(locking reads)가 있다.
- 잠금 읽기
SELECT ... FOR UPDATE- SELECT한 행에 대해서 배타적 로우 락이 잡힌다.
SELECT ... FOR SHARE- SELECT한 행에 대해서 공유 로우 락이 잡힌다.
- 아래 같이 선택적
SELECT를 사용한 쓰기의 경우에도 공유 로우 락이 잡힌다.
- 비잠금 읽기
- 일반적인
SELECT - 비잠금 읽기라고 잠금 시간이 0은 아니다.
- 비잠금 읽기가 non-blocking을 의미하는 것은 아니다.
SELECT 쿼리가 접근하는 모든 테이블에서 공유 메타데이터 락을 획득하기 때문이다.- 참고로,
ALTER TABLE은 베타 메타데이터 락을 획득한다.
- 잠금과 관련된 팁
innodb_lock_wait_timeout 시스템 변수가 각각의 로우 락에 접근되므로 잠금 시간은 시간은 이보다 상당히 클 수 있다.- 락과 트랜잭션 격리 수준은 서로 관련되어 있다.
- InnoDB는 쓰지 않는 행을 포함하여 접근하는 모든 행을 잠근다.
- 락은 트랜잭션 커밋이나 롤백할 때 해제되며 때로는 쿼리 실행 중에도 해제된다.
- InnoDB는
record, gap, next-key 등 다양한 유형의 락이 있다.
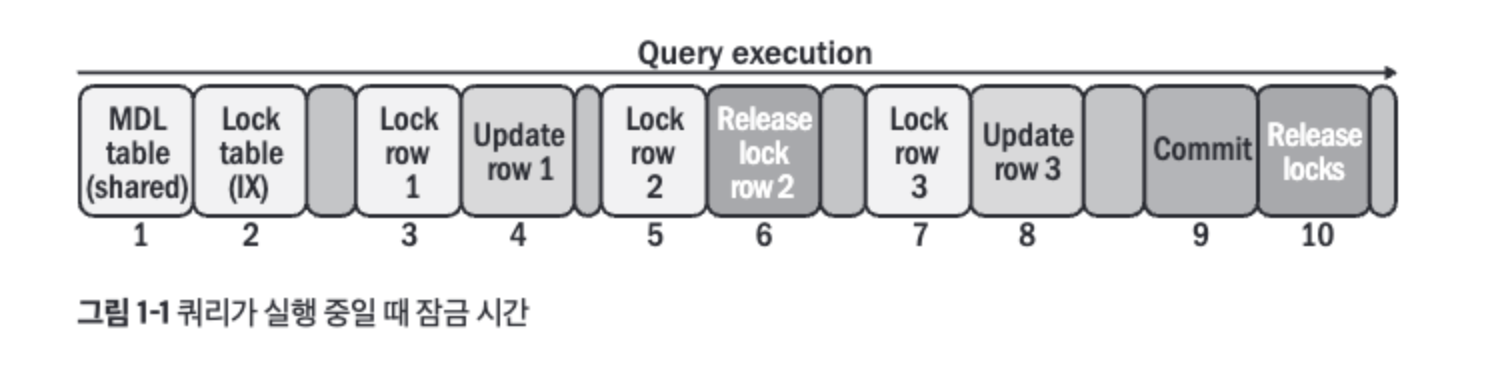
- 아래 그림은 잠금 시간이 포함된 쿼리 시간을 시각화 한 것이다.
- 성능 스키마의 잠금 시간에는 1, 2만 포함된다. 슬로 쿼리 로그에는 1, 2, 3, 5, 7이 포함된다.
- 행 2는 5에서 락이 되었다가 커밋되기 전에 갱신 없이 락이 해제된다. 이런 일이 발생할 수 있지만 항상 그런 것은 아니면 쿼리와 트랜잭션 격리 수준에 따라 다르다.
- 조회된 행(rows examined)
- MySQL이 쿼리 조건 절에 일치하는 행을 찾으려고 접근한 행의 수
- 쿼리와 인덱스의 선택도를 나타낸다.
- 선택도가 높을 수록 MySQL이 일치하는 행을 조회하는 데 낭비하는 시간이 줄어든다.
- 아래 상황에서
SELECT c FROM t1 WHERE c='b'는 c에 유니크 인덱스가 없으므로 3개의 행을 조회한다.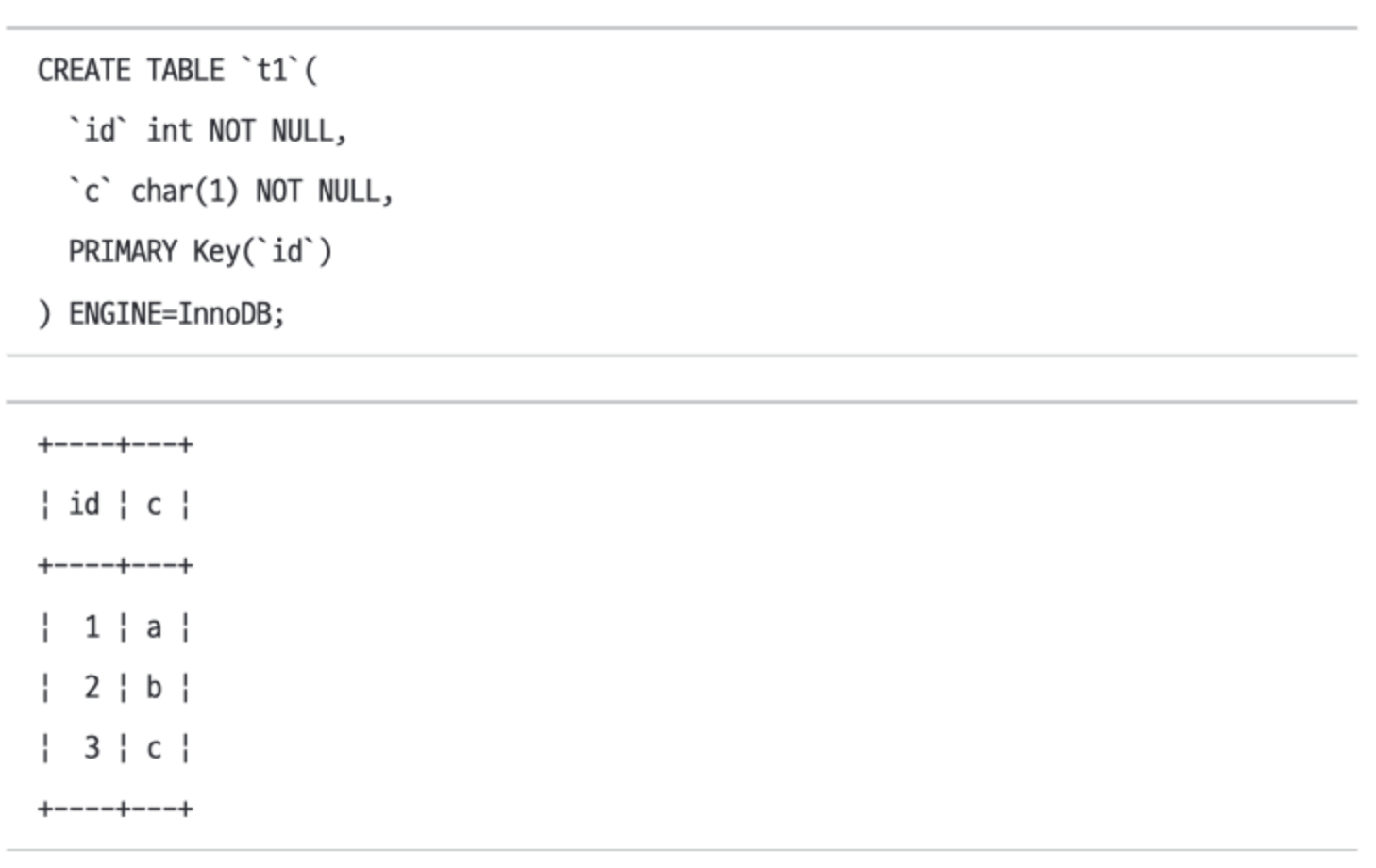
- 보낸 행(rows sent)
- 클라이언트에 반환된 행의 수를 나타낸다.
- 보낸 행 = 조회된 행
- 이상적인 경우. 특히 전체 행의 백분율로 계산했을 때 상대적으로 값이 작고, 허용할 수 있는 쿼리 응답 시간일 때가 이상적이다.
- 비율과 관계없이 보낸 행과 조회된 행이 같고 값이 의심스러울 정도로 높으면 쿼리가 테이블 스캔을 유발한다는 것을 의미으로 성능 면에서 매우 안 좋은 상황임을 암시한다.
- 보낸 행 < 조회된 행
- 쿼리나 인덱스의 선택도가 좋지 않다는 신호다.
- 이 쿼리로 인해 MySQL은 많은 시간을 낭비하고 있다는 뜻이다.
- 보낸 행 > 조회된 행
- 드문 경우다.
- MySQL이 쿼리를 최적화 할 수 있을 떄와 같은 특별한 조건에서 발생한다.
- 예)
SELECT COUNT(id) FROM t2는 COUNT(id) 값에 대해 1개 행을 보내지만 0개 행을 조회한다.
- 영향받는 행(rows affected)
- 삽입, 갱신, 삭제된 행의 수를 나타낸다.
- 해당하지 않는 행이 변경되면 심각한 버그가 발생하므로 주의해야된다.
- 영향받는 행을 확인하는 또 다른 방법은 대량 작업의 배치 크기이다.
INSERT, UPDATE, DELETE는 복제 지연, 변경 목록 길이, 잠금 시간, 전반적인 성능 저하와 같은 여러 문제를 야기한다. - MySQL과 애플리케이션이 쿼리 응답 시간에 영향을 미치지 않고 유지할 수 있는 배치 크기와 배율얼 결정해야 한다. (보편적인 정답은 없다)
- 셀렉트 스캔(select scan)
- 쿼리가 2개 이상의 테이블에 접근할 때 첫 번째로 접근한 테이블에서 수행한 전체 테이블 스캔 횟수를 나타낸다.
- 쿼리가 인덱스를 사용하지 않는다는 것을 의미하므로 일반적으로 성능에 좋지 않다.
- 셀렉트 스캔은 모두 0이거나 1일 가능성이 크다.
- 셀렉트 스캔이 0이 아니면 쿼리 최적화를 강력하게 권장한다.
- 셀렉트 풀 조인(select full join)
- 조인된 테이블을 대상으로 전체 테이블을 스캔한 수를 나타낸다.
- 셀렉트 스캔과 유사하지만 더 나쁘다.
- 셀렉트 풀 조인은 조인 수가 이전 테이블 행의 곱과 같아서 셀렉트 스캔보다 더 나쁘다.
- 디스크에 생성된 임시 테이블
- 쿼리가 메모리에 임시 테이블을 만드는 것은 정상이다.
- 그러나 메모리에 임시 테이블이 MySQL이 임시 테이블을 디스크에 쓴다. 이는 응답 시간에 영향을 미친다.
- 과도하게 사용되는 디스크의 임스 테이블을 쿼리 최적화를 하거나,
tmp_table_size 시스템 변수를 높여야 된다.- 쿼리를 먼저 최적화하고, 시스템 변수는 최후의 수단으로 변경해야 한다.
- 쿼리 카운트
- 쿼리 실행 횟수를 나타낸다.
- 매우 낮고 쿼리가 느리지 않는 한 기준이 없고 임의적이다.
메타데이터와 애플리케이션#
- 메타데이터로는 EXPLAIN 계획과 테이블 구조 등이 있다.
EXPLAIN과 SHOW CREATE TABLE은 각각 EXPLAIN 계획과 테이블 구조를 보여준다.- 애플리케이션이 쿼리를 실행하는 이유가 무엇인지 분석하고, 쿼리를 간결하게 하거나 제거하는 것도 중요하다.
평균, 백분위, 최대#
- 평균
- 평균에 속으면 안된다.
- 쿼리 수가 매우 크거나 작은 몇 개의 값이 평균 음답 시간을 왜곡할 수 있다.
- 백분위수
- 평균이 갖는 문제를 보완한다.
- P95: 샘플의 95%가 이보다 작거나 같은 값이다.
- 예시) P95가 100ms와 같으면 값의 95%가 100ms보다 작거나 같은 값으며, 5%가 100ms보다 크다.
- 평균보다 대표성을 띈다.
- 무시되는 값의 작은 비율을 특잇값으로 간주한다.(네트워크 지터, 플루크로 인해 적은 비율의 쿼리 실행이 평소보다 오래 걸릴 수 있다.)
- 하지만 N%의 상위값이 특잇값이 아닌 것으로 검증되기 전까지는 정상이 아니므로 관심을 가져야 한다.
- 최대
- 백분위수가 갖는 문제를 보완한다.
- 세계 어딘가에서 일부 애플리케이션 사용자는 최대 쿼리 응답 시간을 경험하였거나 몇 초 후에 절망하고 떠난다.
- 쿼리 메트릭 도구는 최대 응답 시간을 가진 쿼리를 샘플로 사용할 때가 많다.
- 해당 샘플을 사용해 문제를 재현하거나(이 경우 분석을 계속 진행) 문제를 재현하지 못하거나(이 경우 무시할 수 있는 특잇값임을 검증) 하는 일을 하게된다.
쿼리 응답 시간 개선#
직접 쿼리 최적화#
- 쿼리와 인덱스를 변경하는 것
- 쿼리 분석, EXPLAIN, 인덱스 등으로 쿼리 최적화를 할 수 있다.
- MySQL 매뉴얼에 명싱된 “SELECT 문 최적화”
- 범위 최적화
- 인덱스 머지 최적화
- 해시 조인 최적화
- 인덱스 컨디션 푸시다운 최적화
- 다중 범위 읽기 최적화
- Constant-Folding 최적화
- IS NULL 최적화
- ORDER BY 최적화
- GROUP BY 최적화
- DISTINCT 최적화
- LIMIT 쿼리 최적화
간접 쿼리 최적화#
- 데이터와 접근 패턴을 변경하는 것
TRUNCATE TABLE을 통해 데이터가 없으면 거의 0에 가까운 시간에 모든 쿼리를 실행할 수 있다.- 직접 쿼리 최적화로 문제가 해결되면 간접 쿼리 최적화는 하지 않는 게 바람직하다.
- 간접 쿼리 최적화는 더 많은 노력이 들어가기 때문이다.
언제 쿼리를 최적화해야 할까?#
- 느린 쿼리를 수정하려고 시간을 투자하는 게 항상 효율적인 건 아니기에 매번 쿼리를 최적화해서는 안된다.
- 쿼리를 최적화해야 하는 상황 3가지
- 성능이 고객에게 영향을 미칠 때
- 코드 변경 전후
- 한 달에 한 번: 코드와 쿼리가 변경되지 않더라도 데이터와 접근 패턴이라는 적어도 2가지 요소가 변경된다.
MySQL을 더 빠르게#
- MySQL이 동일한 시간 내에 더 많은 작업을 수행하도록 하는 3가지 옵션
- 시간의 본질 바꾸기
- 응답 시간 단축: 직접 쿼리 최적화. 간접 쿼리 최적화.
- 부하량 증가: 더 많은 CPU 코어를 사용하여 응답
- 하드웨어 성능이 한계에 도달하면 불안정해지므로, MySQL의 속도를 높이려면 직접 및 간접 쿼리 최적화라라는 여정을 시작해야만 한다.