- LLM은 단순히 한 텍스트 블록의 다음에 올 단어를 예측하는 모델일 뿐이다.
- 따라서 LLM은 단순히 사용자가 어떤 작업을 수행하는 데 도움이 되는 도구일 뿐이며 이러한 도구와 상호작용하는 방법은 사용자가 완성해야 할 텍스트 블록, 즉 프롬르트를 만드는 것이다.
언어 모델: 어쩌다 우리가 여기까지 왔지?#
초기 언어 모델#
- 최초로 소개된 언어 모델: 마르코프 모델
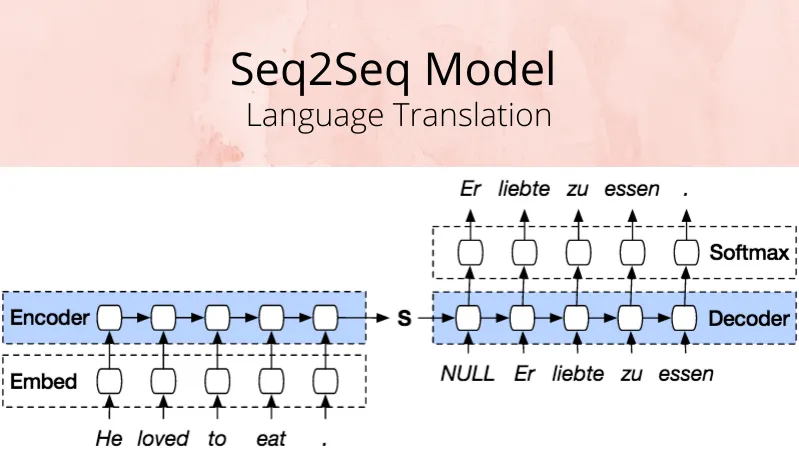
- 2014년까지 가장 강력한 언어 모델은 구글에서 소개한 seq2seq 아키텍처에 기반한다.
- 아키텍처: 인코더와 디코더 두 컴포넌트로 구성된다.
- 토큰 스트림을 인코더로 전송하면, 인코더는 입력 시퀀스의 정보를 축적하는 숨겨진 상태벡터를 업데이트한다.
- 마지막 토큰까지 인코더에서 처리 완료되면, 숨겨진 상태벡터(사고벡터)가 디코더에 전송된다.
- 디코더는 출력 토큰과 사고 벡터를 입력으로 사용해 새로운 출력 토큰을 내보낸다.
- seq2seq의 문제점(정보 병목)
- 텍스트 블록이 길면 중요한 정보를 종종 잊어버려 디코더가 작업할 수 있는 정보가 거의 없다. 문장 앞부분 정보가 뒤로 갈수록 희미해진다.
- 이를 해결하기 위해 어텐션 메커니즘을 사용했다.
- 어텐션 메커니즘: 인코더가 단일 사고 벡터를 제공하는 대신 인코더 프로세스에서 마주친 각 토큰에 대해 생성된 모든 숨겨진 상태벡터를 보존한 다음, 디코더가 모든 벡터에 대해 소프트 검색을 수행하도록 함
- 어텐션 메커니즘은 트랜스포머 아키텍처에 많이 활용되었다.
- 트랜스포머는 seq2seq 모델과 달리 모든 순환 회로가 삭제됐고 대신 어텐션 메커니즘에 완전히 의존한다.
- seq2seq가 임의로 긴 시퀀스를 처리할 수 있는 반면 트랜스포머는 고정된 길이의 유한한 입출력 시퀀스만 처리할 수 있었다. 트랜스포머는 GPT의 직접적인 전신이기 때문에 이 한계를 그때부터 계속 극복하려 노력해왔다.
프롬프트 엔지니어링#
- 프롬프트 엔지니어링: 당면한 문제를 해결하는 데 필요한 정보를 포함하도록 프롬프트를 구성하는 것
- 이 책에서는 확장된 관점에서의 프롬프트 엔지니어링를 다룬다.
- 프롬프트 구성의 응답 해석이 프로그래밍 방식으로 이루어지는 LLM 기반 애플리케이션 전체를 논의한다.
- 프롬프트 엔지니어링 단계(아래로 갈수록 정교함)
- 매우 빈약한 애플리케이션 레이어를 사용하는 경우
- 모델에 대한 사용자 입력을 수정하고 보강하는 경우
- LLM과의 상호작용이 상태 기반으로 이루어지는 경우
- LLM이 API 요청을 통해 정보를 읽어 들이거나 인터넷에 접근할 수 있는 자산을 생성하거나 수정함으로써 실제 세계에 영향을 미치도록 하는 경우
- LLM 애플리케이션에 사용자가 제안한 광범위한 목표를 달성하는 방법에 대해 스스로 결정을 내릴 수 있는 능력을 제공하는 경우