객체지향 쿼리 소개
- JPQL 특징
- 테이블이 아닌 객체를 대상으로 검색하는 객체지향 쿼리다.
- SQL을 추상화해서 특정 데이터베이스 SQL에 의존하지 않는다.
- 다음은 JPA가 공식 지원하는 기능이다.
- JPQL
- Criteria 쿼리: JPQL을 편하게 작성하도록 도와주는 API, 빌더 클래스 모음
- 네이티브 SQL: JPA에서 JPQL 대신 직접 SQL을 사용할 수 있다.
- 다음은 JPA가 공식 지원한느 기능은 아니지만 알아둘 가치가 있다.
- QueryDSL: Criteria 쿼리처럼 JPQL을 편하게 작성하도록 도와주는 빌더 클래스 모음, 비표준 오픈소스 프레임워크다.
- JDBC 직접 사용, MyBatis 같은 SQL 매퍼 프레임워크 사용: 필요하면 JDBC를 직접 사용할 수 있다.
JPQL 소개
- JPQL: 엔티티 객체를 조회하는 객체지향 쿼리
- JPQL은 SQL을 추상화해서 특정 데이터베이스에 의존하지 않는다.
- JPQL은 SQL보다 간결하다. 엔티티 직접 조회, 묵시적 조인, 다형서 지원으로 SQL보다 코드가 간결하다.

- 실제 실행된 SQL

Criteria 쿼리 소개
- 장점: 문자가 아닌
query.select(m).wher(...)처럼 프로그래밍 코드로 JPQL을 작성할 수 있다.- 컴파일 시점에 오류를 발견할 수 있다.
- IDE를 사용하면 코드 자동완성을 지원한다.
- 동적 쿼리를 작성하기 편하다.

- 엔티티의 필드도 문자가 아닌 코드로 작성하려면 메타 모델을 사용하면된다.
- 자바가 제공하는 어노테이션 프로세서 기능을 사용하면 어노테이션을 분석해서 클래스를 사용할 수 있다.
- JPA는 이 기능을 사용해서
Member엔티티 클래스로부터Member_라는 Criteria 전용 클래스를 생성하는데 이것을 메타 모델이라 한다. 
- 단점: 사용하기 불편하고 Criteria로 작성한 코드가 한눈에 들어오지 않는다.
QueryDSL 소개
- Ciriteria처럼 JPQL 빌더 역할이지만, Criteria에 비해 단순하고 사용하기 쉽다.

네이티브 SQL 소개
- 네이티브 SQL: JPA에서 SQL을 직접 사용할 수 있는 기능
- JPQL을 사용해도 가끔 특정 데이터베이스에 의존하는 기능을 사용해야 할 때 사용된다.

JDBC 직접 사용, 마이바티스 같은 SQL 매퍼 프레임워크사용
- JPA 구현체로 JDBC 커넥션을 획득하는 방법은 다음과 같다.
- JPA를 우회하는 SQL에 대해서는 JPA가 전혀 인식하지 못하기 때문에, 우회해서 SQL을 실행하기 직전에 영속성 컨텍스트를 수동으로 플러시해서 데이터베이스와 영속성 컨텍스트를 동기화하면 된다.
- 참고로 스프링 프레임워크를 사용하면 JPA와 마이바티스를 손쉽게 통합할 수 있다.
- 또한 스프링 프레임워크의 AOP를 적절히 활용해서 JPA를 우회하여 데이터베이스에 접근하는 메서드를 호출할 때마다 영속성 컨텍스트를 플러시하면 동기화 문제도 깔끔하게 해결할 수 있다.

JPQL
기본 문법과 쿼리 API
- SELECT 문:
SELECT m FROM Member AS m m.username = 'Hello'- 엔티티와 속성은 대소문자를 구분한다. 반면에 SELECT, FROM, AS 같은 JPQL 키워드는 대소문자를 구분하지 않는다.
- 엔티티 이름:
Member는 클래스 명이 아니라 엔티티 명이다.@Entity(name="XXX")같이 엔티티 명을 지정하지 않으면 클래스명을 기본값으로 사용한다. - 별칭은 필수:
Member AS m같이 JPQL은 별칭을 필수로 사용해야 한다.
- TypeQuery, Query
- JPQL을 실행하려면 쿼리 객체를 만들어야 한다.
- 타입을 명확하게 지정할 수 있으면
TypeQuery객체를 사용하고, 반환 타입을 명확하게 지정할 수 없으면Query객체를 사용한다. Query객체는 예제처럼 조회 대상이 둘 이상이면Object[]를 반환하고, 하나면Object를 반환한다.

- 결과 조회
query.getResultList(): 결과를 List 컬렉션으로 반환한다. 만약 결과가 없음녀 빈 컬렉션을 반환한다.query.getSingleResult(): 결과가 정확히 하나일 때 사용한다.- 결과가 없으면
NoResultException예외가 발생한다. - 결과가 1개보다 많으면
NonUniqueResultException예외가 발생한다.
- 결과가 없으면
파라미터 바인딩
- 이름 기준 파라미터: 이름 기준 파라미터는 앞에
:를 사용한다. - 위치 기준:
?다음에 위치 값을 주면 된다. 위치 값은 1부터 시작한다. - 파라미터 바인딩 방식은 선택이 아닌 필수다.
- 파라미터 바인딩을 사용하지 않으면 SQL 인젝션 공격을 당할 수 있다.
- 파라미터 바인딩 방식을 사용하면
- 파라미터의 값이 달라도 같은 쿼리로 인식해서 JPA는 JPQL을 SQL로 파싱한 결과를 재사용할 수 있다.
- 데이터베이스도 내부에서 실행한 SQL을 파싱해서 사용하는 같은 쿼리는 파싱한 결과를 재사용할 수 있다.


프로젝션
- SELECT 절에 조회할 대상을 지정하는 것을 프로젝션이라 하고
SELECT {프로젝션 대상} FROM으로 대상을 선택한다. - 엔티티 프로젝션
- 조회한 엔티티는 영속성 컨텍스트에서 관리한다.

- 임베디드 타입 프로젝션
- 임베디드 타입은 조회의 시작점이 될 수 없고, 엔티티가 시작점이 되어 엔티티를 통해서 임베디드 타입을 조회할 수 있다.
- 임베디드 타입은 엔티티 타입이 아닌 값 타입이다. 이렇게 조회한 임베디드 타입은 영속성 컨텍스트에서 관리되지 않는다.

- 스칼라 타입 프로젝션
- 스칼라 타입: 숫자, 문자, 날짜 같은 기본 데이터 타입
- 다음과 같은 통계 쿼리를 주로 스칼라 타입으로 조회한다.

- 여러 값 조회
- 프로젝션에 여러 값을 선택하려면
TypeQuery를 사용할 수 없고 대신에Query를 사용해야 한다. - 스칼라 타입 뿐만 아니라 엔티티 타입도 여러 값을 함께 조회할 수 있고, 이때 조회한 엔티티는 영속성 컨텍스트에서 관리된다.

- 프로젝션에 여러 값을 선택하려면
- NEW 명령어
- 여러 값 조회할 때
UserDTO처럼 의미 있는 객체로 변환하면TypeQuery를 사용할 수 있다. - NEW 명령어를 사용할 때 주의점
- 패키지 명을 포함한 전체 클래스 명을 입력해야 한다.
- 순서와 타입이 일치하는 생성자가 필요하다.

- 여러 값 조회할 때
페이징 API
- 데이터베이스마다 페이징을 처리하는 SQL 문법이 다르다.
- JPA 페이징은 당므 두 API로 추상화했다.
setFirstgResult(int startPosition): 조회 시작 위치(0부터 시작한다)setMaxResult(int maxResult): 조회할 데이터 수

- MySQL 변환 결과
- 페이징을 더 최적화하고 싶다면 JPA가 제공하는 페이징 API가 아닌 네이티브 SQL을 직접 사용해야 한다.
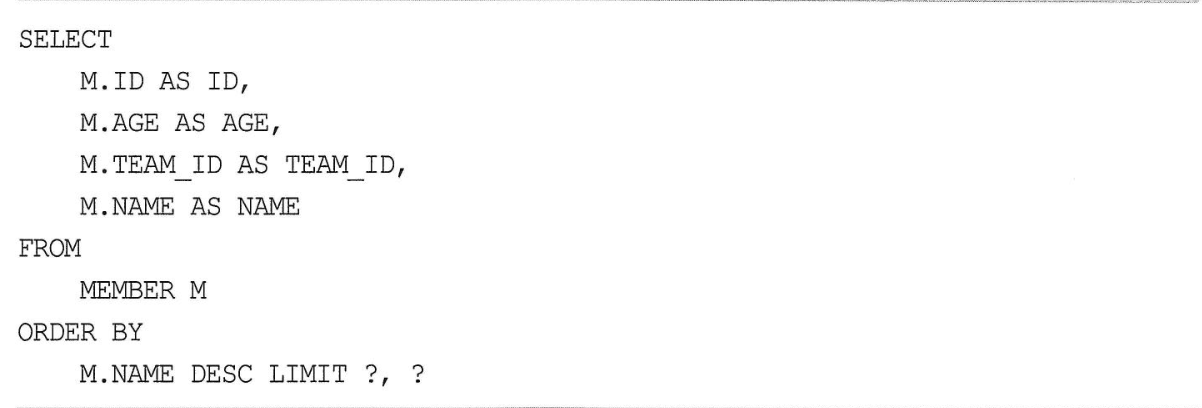
집합과 정렬
- 집합 함수
- 집합 함수 사용 시 참고사항
NULL값은 무시하므로 통계에 잡히지 않는다.- 만약 값이 없는데
SUM,AVG,MAX,MIN함수를 사용하면NULL값이 된다. 단COUNT는 0이 된다. DISTINCT를 집합 함수 안에 사용해서 중복된 값을 제거하고 나서 집합을 구할 수 있다.DISTICT를COUNT에서 사용할 때 임베디드 타입은 지원하지 않는다.
- GROUP BY, HAVING
- 정렬



JPQL 조인
- 내부 조인
- INNER JOIN을 사용한다. INNER는 생략할 수 있다.

- 실제 SQL
- 외부 조인
- OUTER LEFT JOIN을 사용한다. OUTER는 생략할 수 있다.

- 컬렉션 조인
- ‘회원 -> 팀’으로의 조인은 다대일 조인이면서 단일 값 연관 필드를 사용한다.
- ‘팀 -> 회원’으로 반대로 일대다 조인이면서 컬렉션 값 연관 필드를 사용한다.

- 세타 조인
- 세타 조인은 내부 조인만 지원한다.

- JOIN ON 절(JPA 2.1)
- JPA 2.1부터 조인할 때 ON 절을 지원한다.
- ON 절을 사용하면 조인 대상을 필터링하고 조인할 수 있다.
- 참고로 내부 조인의 ON 절은 WHERE 절ㅇ르 사용할 때와 결과가 같으므로 보통 ON절은 외부 조인에서만 사용한다.


페치 조인
- 페치 조인은 SQL에서 이야기하는 조인의 종류는 아니고 JPQL에서 성능 최적화를 위해 제공하는 기능이다.
- 엔티티 페치 조인

- 실행된 SQL
- 회원을 조회할 때 페치 조인을 사용해서 팀도 함께 조회했으므로 연관된 팀 엔티티는 프록시가 아닌 실제 엔티티다.
- 따라서 연관된 팀을 사용해도 지연 로딩이 일어나지 않는다.
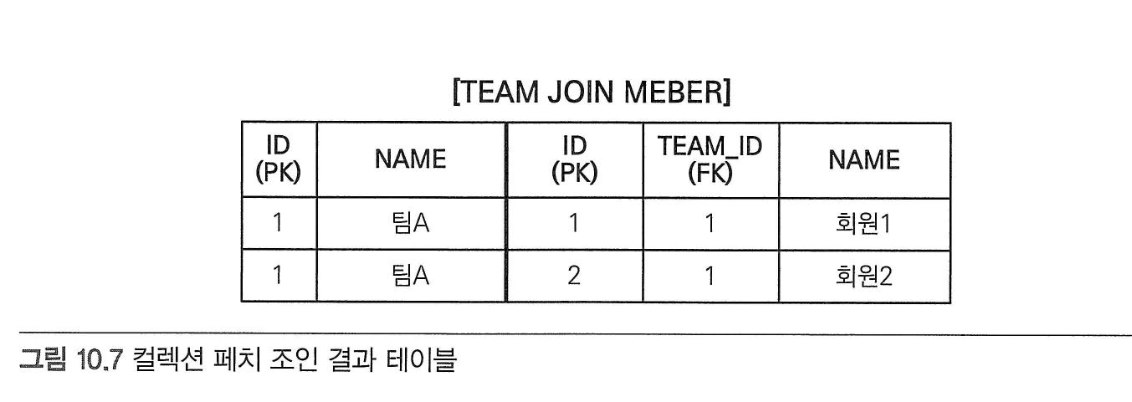
- 컬렉션 페치 조인

- 실행된 SQL
- 팀은 하나지만 멤버와 조인하면서 ‘팀A’를 2건 반환하게 된다.
- 페치 조인과 DISTINCT
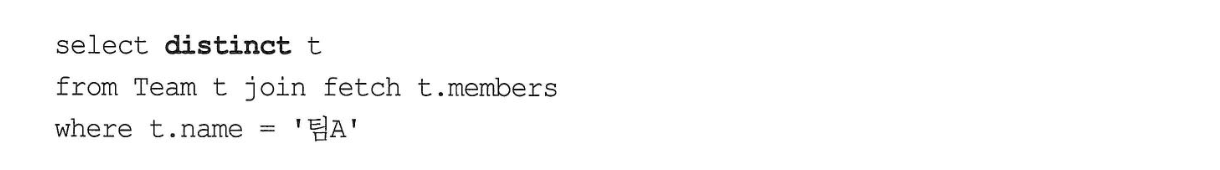
- distinct를 사용하면
- SQL에서
SELECT DISTINCT가 추가된다. - 다음으로 애플리케이션에서 엔티티 기준으로 중복을 제거한다.
- SQL에서
- 페치 조인과 일반 조인의 차이

- 일반 조인은 연관관계까지 고려하지 않는다. 단지 SELECT 절에 지정한 엔티티만 조회할 뿐이다.
- 그래서 회원 컬렉션 조회시 다시 쿼리를 실행한다.
- 페치 조인을 사용하면 연관된 엔티티도 함께 조회한다.
- 페치 조인의 특징과 한계
- 페치 조인을 사용하면 SQL 한 번으로 연관된 엔티티들을 함께 조회할 수 있어서 SQL 호출 횟수를 줄여 성능을 최적화할 수 있다.
- 글로벌 로딩 전략은 될 수 있으면 지연 로딩을 사용하고 최적화가 필요하면 페치 조인을 적용하는 것이 효과적이다.
- 페치 조인 한계
- 페치 조인 대상에는 별칭을 줄 수 없다.
- 둘 이상의 컬렉션을 페치할 수 없다.
- 구현체에 따라 되기도 하는데 컬렉션 * 컬렉션의 카테시안 곱이 만들어지므로 주의해야 한다.
- 컬렉션을 페치 조인하면 페이징 API(setFirstResult, setMaxResults)를 사용할 수 없다.
- 하이버네이트에서 컬렉션을 페치 조인하고 페이징 API를 사용하면 경고 로그를 남기면서 메모리에서 페이징 처리를 한다. 데이터가 적음녀 상관없지만 데이터가 많으면 성능 이슈와 메모리 초과 예외가 발생할 수 있어서 위험하다.
- 페치 조인은 객체 그래프를 유지할 때 사용하면 효과적이다. 반면에 여러 테이블을 조인해서 엔티티가 가진 모양이 아닌 전혀 다른 결과를 내야 하면 억지로 페치 조인을 사용하기보다는 여러 테이블에서 필요한 필드들만 조회해서 DTO로 반환하는 것이 더 효과적일 수 있다.



경로 표현식
- 경로 표현식의 용어 정리
- 상태 필드: 단순히 값을 저장하기 위한 필드(필드 or 프로퍼티)
- 연관 필드: 연관관계를 위한 필드, 임베디드 타입 포함(필드 or 프로퍼티)
- 단일 값 연관 필드:
@ManyToOne,@OneToOne대상이 엔티티 - 컬렉션 값 연관 필드:
@OneToMany,@ManyToMany대상이 컬렉션
- 단일 값 연관 필드:
- 경로의 표현식과 특징
- 상태 필드 경로: 경로 탐색의 끝이다. 더는 탐색할 수 없다.
- 단일 값 연관 경로: 묵시적으로 내부 조인이 일어난다. 단일 값 연관 경로는 계속 탐색할 수 있다.
- 컬렉션 값 연관 경로: 묵시적으로 내부 조인이 일어난다. 더는 탐색할 수 없다. 단 FROM 절에서 조인을 통해 별칭을 얻으면 별칭으로 탐색할 수 있다.


- 참고로 컬렉션은 컬렉션의 크기를 구할 수 있는
size라는 특별한 기능을 사용할 수 있다.
- 상태 필드 경로: 경로 탐색의 끝이다. 더는 탐색할 수 없다.
- 명시적 조인과 묵시적 조인
- 명시적 조인: JOIN을 직접 적어주는 것
- 묵시적 조인: 경로 표현식에 의해 묵시적으로 조인이 일어나는 것, 내부 조인만 할 수 있다.
- 명시적 조인: JOIN을 직접 적어주는 것


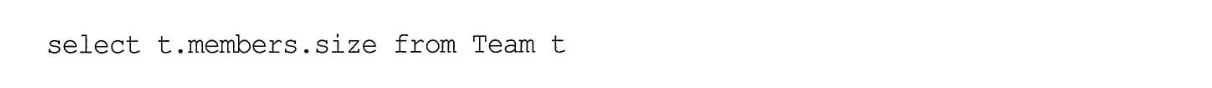


서브 쿼리
- JPQL도 서브 쿼리를 지원하지만 WHERE, HAVING 절에서만 사용할 수 있고 SELECT, FROM 절에서는 사용할 수 없다.
- 서브 쿼리 함수


다형성 쿼리


- 단일 테이블 전략인 경우
- 조인 전략인 경우
- 단일 테이블 전략인 경우
TYPE은 엔티티 상속 구조에서 조회 대상을 특정 자식 타입으로 한정할 때 주로 사용한다.TREAT는 JPA 2.1에 추가된 기능인데 자바의 타입 캐스팅과 비슷하다.- JPA 표준은 FROM, WHERE 절에서 사용할 수 있지만, 하이버네이트는 SELECT 절에서 TREAT를 사용할 수 있다.




사용자 정의 함수 호출(JPA 2.1)
- JPA 2.1부터 사용자 정의 함수를 지원한다.
- 하이버네이트 구현체를 사용하면 방언 클래스를 상속해서 구현하고 데이터베이스 함수를 미리 등록해야 한다.


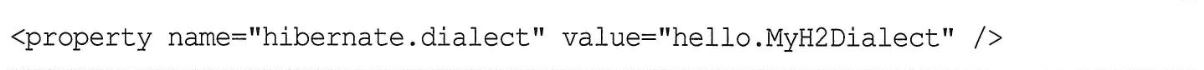
기타 정리
- enum은 = 비교 연산만 지원한다.
- 임베디드 타입은 비교를 지원하지 않는다.
- JPA 표준은 ‘‘을 길이 0인 empty string으로 정했지만 데이터베이스에 따라 ‘‘를 NULL로 사용하는 데이터베이스도 있으므로 확인하고 사용해야 한다.
- NULL 정의
- Null == Null은 알 수 없는 값이다.
- Null is Null은 참이다.
엔티티 직접 사용
- JPQL에서 엔티티 객체를 직접 사용하면 SQL에서는 해당 엔티티의 기본 키 값을 사용한다.
- 외래 키를 사용할 때도 기본 키로 비교한다.




Named 쿼리: 정적 쿼리
- 동적 쿼리: em.createQuery(“select ..")처럼 JPQL을 문자로 완성해서 직접 넘기는 것을 동적 쿼리라 한다. 런타임에 특정 조건에 따라 JPQL을 동적으로 구성할 수 있다.
- 정적 쿼리: 미리 정의한 쿼리에 이름을 부여해서 필요할 때 사용할 수 있는데 이 것을 Named 쿼리라 한다. Named 쿼리는 한 번 정의하면 변경할 수 없는 정적인 쿼리다.
- Named 쿼리는 애플리케이션 로딩 시점에 JPQL 문법을 체크하고 미리 파싱해둔다.
- 따라서 오류를 빨리 확인할 수 있고, 사용하는 싲머에 파싱된 결과를 재사용하므로 성능상 이점도 있다.
- 변하지 않는 정적 SQL 생성되므로 데이터베이스의 조회 성능 최적화에도 도움이 된다.
- Named 쿼리는
@NamedQuery어노테이션을 사용해서 자바 코드에 작성하거나 XML 문서에 작성할 수 있다.


QueryDSL
시작
- 쿼리 타입(Q)을 생성하는데 생성자에는 별칭을 주면 된다.

- 쿼리 타입은 사용하기 편리하도록 기본 인스턴스를 보관하고 있다.
- 하지만 같은 엔티티를 조인하거나 같은 엔티티를 서브쿼리에 사용하면 같은 별칭이 되므로 이때는 별칭을 직접 지정해서 사용해야 한다.



검색 조건 쿼리
- where 절에는 and나 or을 사용할 수 있다.
- 여러 검색 조건을 나열하면 and 연산이 된다.
- where에서 사용 가능한 여러 메소드



결과 조회
uniqueResult(): 조회 결과가 한 건일 때 사용한다. 조회 결과가 없으면 null을 반환하고 하나 이상이면com.mysema.query.NonUniqueResultException예외가 발생한다.singleResult():uniqueResult()와 같지만 결과가 하나 이상이면 처음 데이터를 반환한다.list(): 결과가 하나 이상일 때 사용한다. 결가가 없으면 빈 컬렉션을 반환한다.
페이징과 정렬

restrict()메소드에QueryModifier를 파라미터로 사용해도 된다.실제 페이징 처리를 하려면 전체 데이터 수를 알아야 한다. 이때는
list()대신에listResults()를 사용한다.


그룹

조인
innerJoin(join),leftJoin,rightJoin,fullJoin을 사용할 수 있고 추가로 JPQL의 on과 성능 최적화를 위한 fetch 조인도 사용할 수 있다.

- 페치 조인 사용법
- 세타 조인 사용법


서브 쿼리
JPASubQuery를 생성해서 서브 쿼리를 사용한다.- 서브 쿼리의 결과가 하나면
unique(), 여러 건이면list()를 사용할 수 있다.


프로젝션과 결과 반환
- 프로젝션 대상이 하나
- 여러 컬럼 반환과 튜플
- 프로젝션 대상으로 여러 필드를 선택하면 QueryDSL은 기본으로
Tuple이라는Map과 비슷한 내부 타입을 사용한다. 
- 프로젝션 대상으로 여러 필드를 선택하면 QueryDSL은 기본으로
- 빈 생성
- 쿼리 결과를 엔티티가 아닌 특정 객체로 받고 싶으면 빈 생성 기능을 사용한다.
- 빈 생성 기능은 다양한 방법을 제공한다.
- 프로퍼티 접근
- 필드 직접 접근
- 생성자 사용





수정, 삭제 배치 처리
- QueryDSL도 수정, 삭제 같은 배치 쿼리를 지원한다.
- JPQL 배치 쿼리와 같이 영속성 컨텍스트를 무시하고 데이터베이스를 직접 쿼리한다는 점에 유의하자.


동적 쿼리
BooleanBuilder를 사용하면 특정 조건에 따른 동적 쿼리를 편리하게 생성할 수 있다.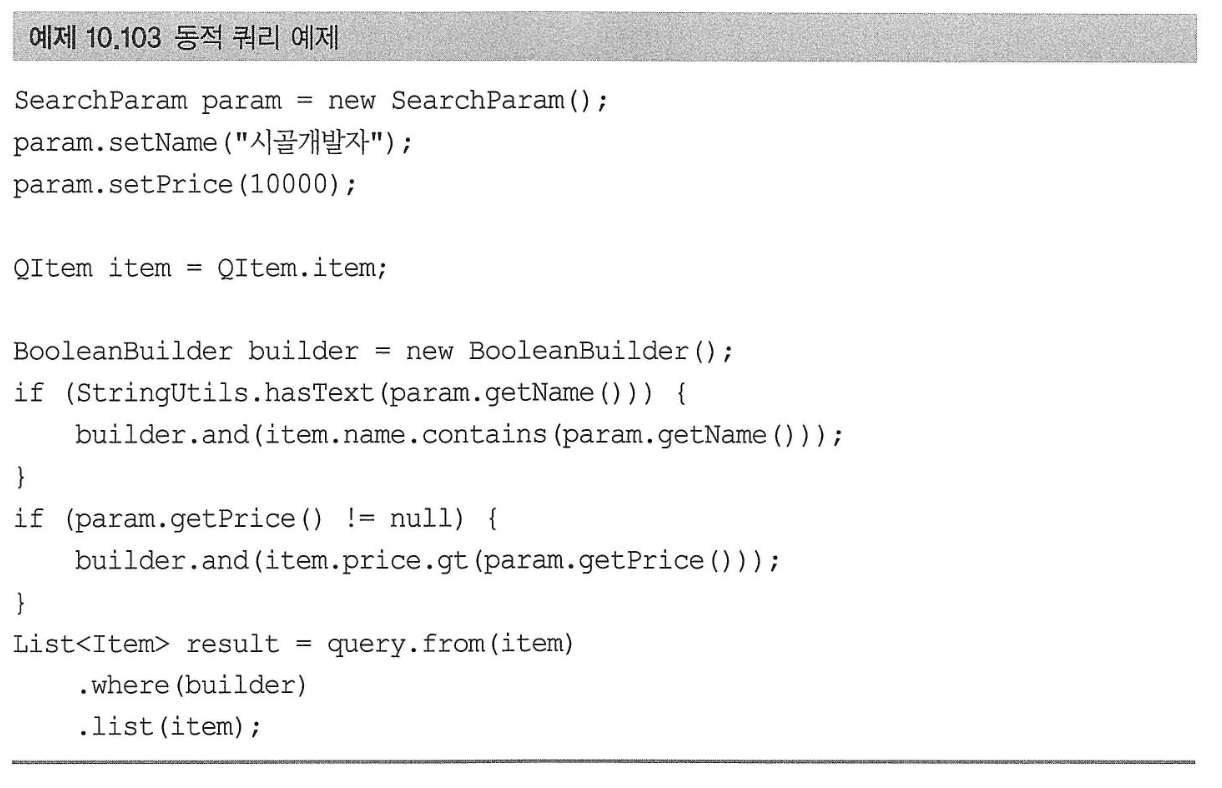
메소드 위임
- 메소드 위임 기능을 사용하면 쿼리 타입에 검색 조건을 직접 정의할 수 있다.
- 먼저 정적 메소드를 만들고
@QueryDelegate어노테이션에 속성으로 적용할 엔티티를 지정한다.- 정적 메소드의 첫 번째 파라미터엔즌 대상 엔티티의 쿼리 타입을 지정하고 나머지는 필요한 파라미털르 정의한다.



- 필요하다면
String,Date같은 자바 기본 내장 타입에도 메소드 위임 기능을 사용할 수 있다.

네이티브 SQL
- 데이터베이스에 종속적인 기능이 필요할 때 네이티브 SQL을 사용한다.
- 특정 데이터베이슴나 사용하는 함수
- 특정 데이터베이스만 지원하는 SQL 쿼리 힌트
- 인라인 뷰(From 절에서 사용하는 서브쿼리), UNION, INTERSECT
- 스토어 프로시저
- 특정 데이터베이스만 지원하는 문법
- 네이티브 SQL을 사용해도 엔티티를 조회할 수 있고 JPA가 지원하는 영속성 컨텍스트 기능을 그대로 사용할 수 있다.
네이티브 SQL 사용
- JPA는 공식적으로 네티이브 SQL에서 이름 기반 파라미터를 지원하지 않고 위치 기반 파라미터만 지원한다. 하지만 하이버네이트는 네이티브 SQL에 이름 기반 파라미터를 사용할 수 있다.

- 엔티티를 조회할 때는
resultClass파라미터를 같이 넘겨준다. - 값 타입을 조회할 때는 두 번째, 세 번째 방법을 사용할 수 있다.
resultSetMapping에 매핑 이름을 명시하면, 엔티티에 어노테이션으로 선언한 결과 매핑으로 결과를 치환해준다.@SqlResultSetMapping을 보면 한번에 엔티티와 값 타입을 매핑할 수 있다.


Named 네이티브 SQL
- JPQL처럼 네이티브 SQL도 Named 네이트 SQL을 사용해서 정적 SQL을 작성할 수 있다.

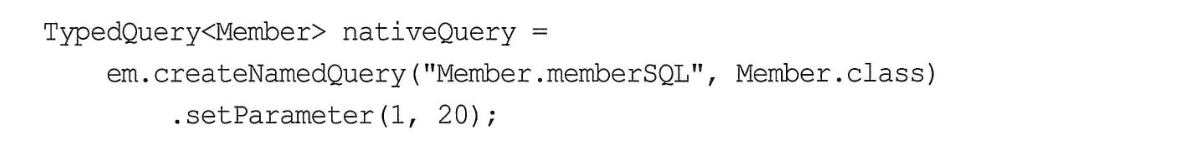
- Named 네이티브 SQL에 결과 매핑도 가능하다.


네이티브 SQL 정리
- 네이티브 SQL도 JPQL API를 그대로 사용할 수 있다.
- 예를 들어 네이티브 SQL을 사용해도 페이징 처리 API를 호출할 수 있다.


객체지향 쿼리 심화
벌크 연산
- 여러 건을 한 번에 수정하거나 삭제하는 벌크 연산을 사용할 수 있다.
- 벌크 연산을 사용할 때는 벌크 연산이 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리한다는 점에 주의해야 한다. 아래의 해결방법이 있다.
em.refresh(): 벌크 연산을 수행한 직후에 정확한 엔티티를 사용해야 한다면em.refresh()를 사용해서 데이터베이스에서 엔티티를 다시 조회하도록 한다.- 벌크 연산 먼저 수행: 벌크 연산을 먼저 실행하면 문제가 되지 않는다.
- 벌크 연산 수행 후 영속성 컨텍스트 초기화: 벌크 연산을 수행한 직후에 바로 영속성 컨텍스트를 초기화해서 영속성 컨텍스트에 남아 있는 엔티티를 제거하는 방법도 좋은 방법이다.

영속성 컨텍스트와 JPQL
- JPQL로 데이터베이스에서 조회한 엔티티가 영속성 컨텍스트에 이미 있으면 JPQL로 데이터베이스에서 조회한 결과를 버리고 대신에 영속성 컨텍스트에 있던 엔티티를 반환한다.
em.find()메소드는 엔티티를 영속성 컨텍스트에서 먼저 찾고 없으면 데이터베이스에서 찾는다.- 하지만 JPQL을 사용하면 항상 데이터베이스에 SQL을 실행해서 결과를 조회하고, 영속성 컨텍스트에 엔티티가 있으면 조회한 엔티티를 버린다.
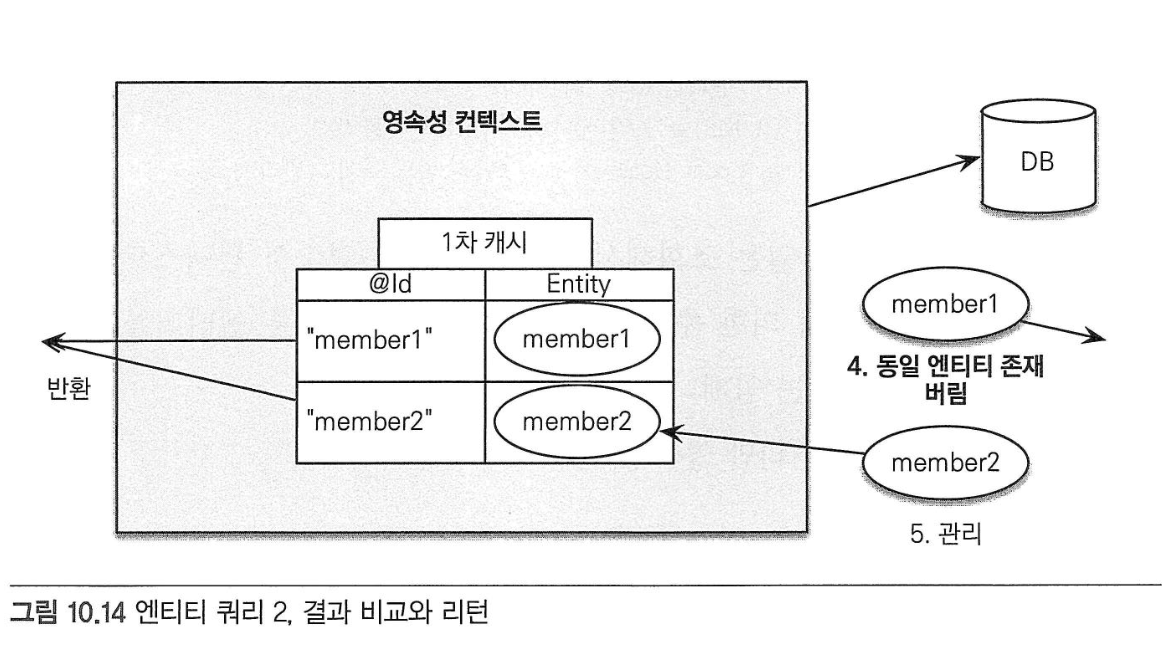
JPQL과 플러시 모드
- 플러시 모드
- 플러시 모드가 AUTO일 때는, JPQL을 호출하면 영속성 컨텍스트가 플러시가 된다.
- 플러시를 하지 않으면 영속성 컨텍스트에는 있지만 아직 데이터베이스에 반영하지 않은 데이터를 조회할 수 없다.
- 이런 상황은 데이터 무결성에 피해를 줄수 있지만, 플러시 횟수를 줄여러 성능을 최적화할 수 있다는 장점도 있다.
