지역 및 중앙 클러스터: 하나의 기업이 지리적으로 분산된 지역, 도시, 대룩 간에 하나 이상의 데이터센터를 가지고 있을 수 있으며, 각각의 데이터센터에 카프카 클러스터가 설치되어 있는 경우
고가용성와 재해 복구: 첫 번째 클러스터의 모든 데이터를 보유하는 여분의 두 번째 클러스터를 준비해 뒀다가 만약의 사태가 발생했을 때 애플리케이션을 두 번째 클러스터를 사용해서 작동함으로써 평상시처럼 작업을 계속하게 할 수 있다.
규제: 여러 나라에서 사업을 운영하는 회사의 경우 국가별로 다른 법적, 규제적 요구 조건을 따르기 위해 나라마다 있는 카프카 클러스터별로 서로 다른 설정과 정책을 시행해야 할 수 있다.
예시: 어떤 데이터는 엄격한 접근 설정과 함께 서로 분리된 클러스터데 저장한 뒤 그중 일부는 보다 개방적인 접근 설정이 되어 있는 클러스터로 복제하는 식이다.
클라우드 마이그레이션: 요즘 많은 회사들은 사내 데이터센터와 클라우드 공급자 모두를 사용해서 비즈니스를 운영한다. 이에 따라 애플리케이션의 클라우드 공급의 여러 리전에서 실행되기도 하고, 이중화를 위해 여러 클라우드 공급자의 서비스를 사용하는 경우도 잦다.
장점: 데이터센터 간의 트래픽을 관리하고보안을 유지하는 데 도움을 줄 뿐만 아니라 비용 역시 절감할 수 있게 해준다.
엣지 클러스터로부터의 데이터 집적: 유통, 통신, 물류에서 헬스케어 이르는 여러 산업에서는 열건성이 제한된 소형 기기를 사용해 데이어를 생성한다. 가용성이 높은 집적용 클러스터를 사용한다면 많은 수의 엣지 클러스터로부터 수집된 데이터를 데이터를 분석하는 등의 용도로 사용될 수 있다.
장점: 사용할 수 있는 자원이 한정적일 수밖에 없는 엣지 클러스터의 연결성, 가용성, 지속성에 대한 요구 조건을 낮추는 데 도움이 된다.
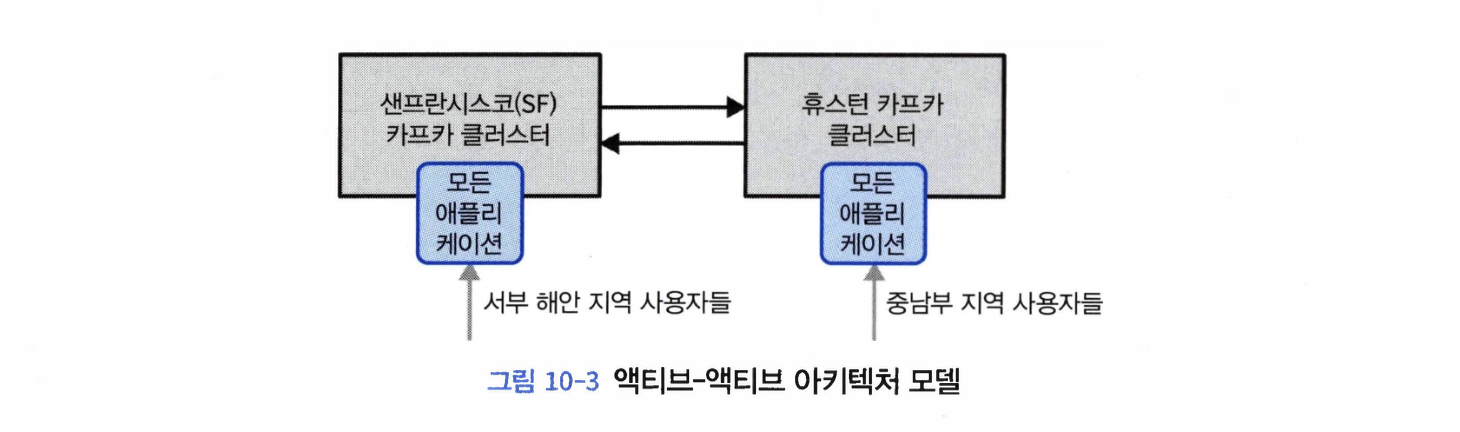
액티브-액티브 아키텍처: 2개 이상의 데이터센터가 전체 데이터의 일부 혹은 전체를 공유하면서, 각 데이터센터가 모두 읽기와 쓰기를 수행할 경우 사용된다.
장점1: 인근 데이터센터에서 사용자들의 요청을 처리할 수 있다.
장점2: 데이터 중복과 회복 탄력성이다. 모든 데이터센터가 모든 기능을 동일하게 가지기 때문에 한 데이터센터가 장애가 발생하더라도 사용자 요청을 다른 데이터센터에서 처리할 수 있다는 것이다.
단점1: 데이터를 여러 위치에서 비동기적으로 읽거나 변경할 경우 발생하는 충돌을 피하는 것이 어렵다.
예시1: 같은 이벤트가 클러스터 사이를 무한히 오가면서 반복되어 미러링되지 않을 것이라는 것을 확신할 수 있어야 된다.
예시2: 두 데이터센터 간의 데이터 일관성을 유지하는 것이 어렵다.
같은 데이터가 클러스터 사이를 오가면서 끝없이 순환 미러링되는 것을 막아야 한다.
해결방법1: 각각의 ‘논리적 토픽’에 대해 데이터센터별로 별도의 토픽을 두고, 원격 데이터센터에서 생성된 토픽의 복제를 막음으로써 가능하다.
예시: 논리적 토픽 users는 한 데이터센터에서는 SF.users 에 저장되고 또 다른 데이터센터에서는 NYC.users 토픽에 저장되게 하는 것이다. 미러링 프로세스는 SF 데이터센터의 SF.users 토픽을 NYC 데이터센터로, NYC 데이터센터의 NYC.users 토픽을 SF 데이터센터로 미러링하게 된다.
해결방법2: 카프카 0.11.0에서 추가된 레코드 헤더 기능은 각각의 이벤트에 데이터가 생성된 데이터 센터를 태그할 수 있도록한다. 헤더에 심어진 정보는 이벤트가 무한히 순환 미러링되는 것을 방지하거나 다른 데이터에서 미러링된 이벤트를 별도로 처리하는 등의 용도로도 사용될 수 있다.
상황에 따라서는 다중 클러스터에 대한 유일한 요구 조건이 특정한 상황의 재해 대비뿐일 수도 있다.
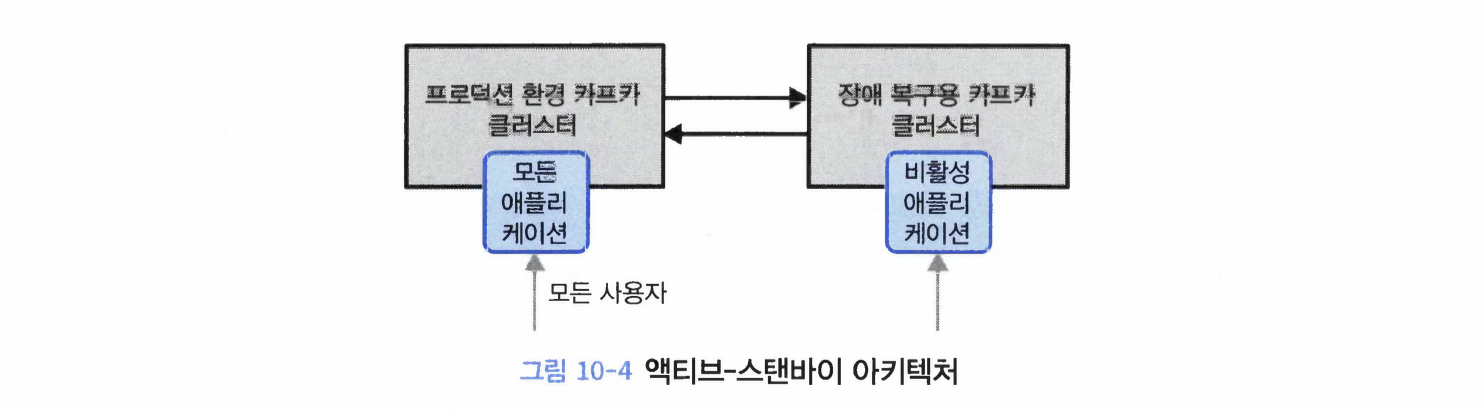
하나의 데이터센터 안에 두 개의 클러스터를 가지고 있는 경우를 생각해보자.
모든 애플리케이션이 첫 번째 클러스터를 사용할지라도 첫 번째 클러스터의 모든 데이터를 가지고 있다가 첫 번째 클러스터가 완전히 사용할 수 없게 될 경우 대신 사용할 수 있는 두 번째 클러스터가 필요할 수 있다.
장점: 간단한 설치가 가능하다. 그냥 두 번쨰 클러스터를 설치한 뒤에 첫 번째 클러스터의 모든 이벤트를 미러링하는 프로세스를 설치하기만 하면 된다.
단점1: 멀쩡한 클러스터를 놀려야 한다.
어떤 조직에서는 프로덕션 클러스터보다 DR 클러스터를 훨씬 작은 크기로 생성함으로써 이 문제를 해결하려고 하는데 이것은 위험한 생각이다. 이렇게 최소한의 크기로 설정된 클러스터가 비상시에 제대로 작동할 수 있을지 확신할 수 없기 때문이다.
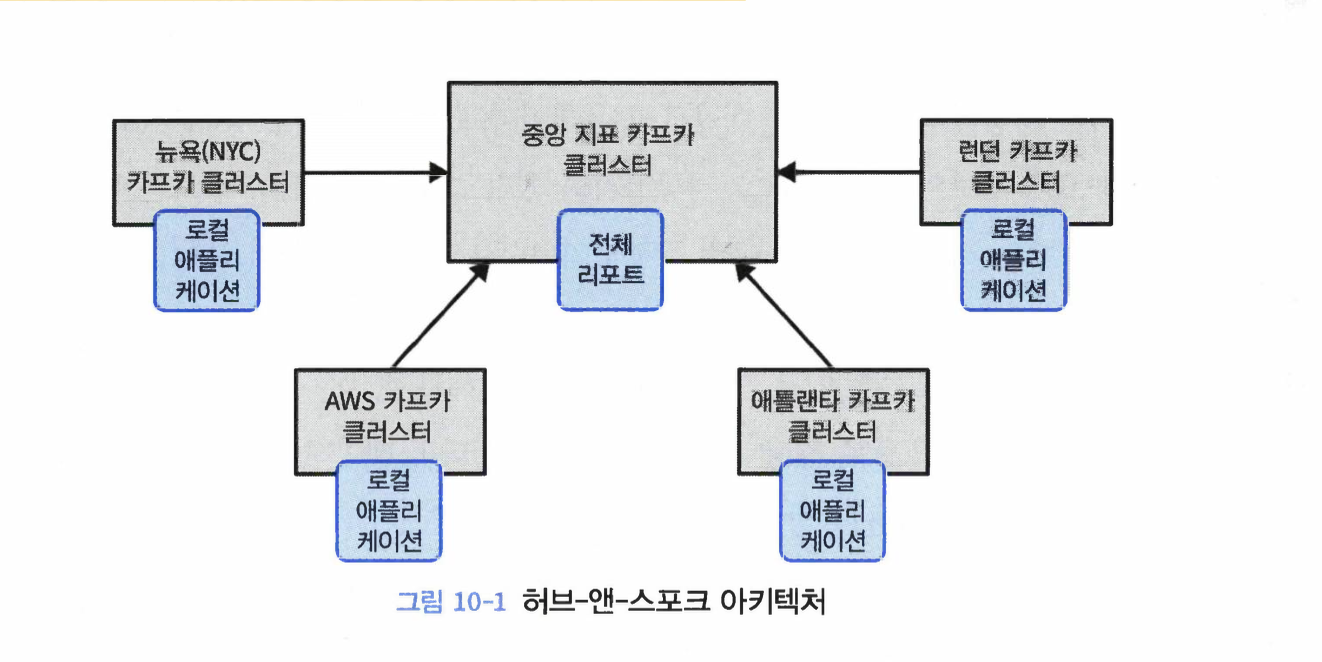
어떤 조직에서는 재해가 발생하지 않는 동안 읽기 전용 작업 일부를 DR 클러스터에 옮겨서 처리하는 방식을 선호하기도 하는데, 이것은 사실상 스포크가 하나뿐인, 허브-앤-스포크 아키텍처의 소규모 버전을 운용하는 것을 의미한다.
단점2: 카프카 클러스터 간의 장애 복구가 보기보다 훨씬 어려운 일이다.
현재로서는 일체의 데이터 유실이나 중복 없이 카프카 클러스터를 완벽하게 복구하는 것이 불가능하다.
장애 복구에 어떠한 것들이 필요한지 살펴보자.
재해 복구 계획하기: 재해 복구를 계획할 때는 두 개의 지표를 염두에 두는 것이 중요하다.
복구 시간 목표(RTO): 모든 서비스가 장애가 발생한 뒤 다시 재개할 때까지의 최대 시간
극단적으로 낮은 수준의 RTO는 자도아호된 장애 복구에서만 가능하기때문에, 수동 작업과 애플리케이션 재시작을 최소화하는 것이 가장 중요하다.
복구 지점 목표(RPO): 장애의 결과로 인해 데이터가 유실될 수 있는 최대 시간
낮은 RPO는 지연 시간이 짧은 실시간 미머링이 필요로 하며, 아예 0으로 만들려면 동기적 방식으로 미러링을 수행해야만 한다.
계획에 없던 장애 복구와 데이터 유실과 불일치
다양한 카프카 미러링 솔루션들이 모두 비동기적으로 작동하기 때문에, DR 클러스터는 주 클러스터의 가장 최신 메시지를 가지고 있지 못할 것이다.
따라서 DR 클러스터가 주 클러스터에서 얼마나 뒤처져 있는지를 항상 모니터링하고, 너무 많이 뒤처지지 않도록 신경쓸 필요가 있다.
사전에 계획된 장애 보구의 경우, 주 클러스터를 먼저 멈춘 뒤 애플리케이션을 DR 클러스터로 마이그레이션하기 전에 미러링 프로세스가 남은 메시지를 모두 미러링할 때까지 기다림으로써 유실을 방지할 수 있다.
만약 예상치 못한 장애가 발생하여 수천 개의 메시지를 유실했을 경우, 미러링 솔류션들이 현재로서는 트랜잭션을 지원하지 않는다는 걸 명심하라.
장애 복구 이후 애플리케이션의 시작 오프셋
다른 클러스터로 장애 복구를 할 때 가장 어려운 것 중 하나는 다른 클러스터로 옮겨간 애플리케이션이 데이터를 읽어오기 시작해야 하는 위치를 결정하는 것이다.
방법1: 자동 오프셋 재설정
아파치 카프카 컨슈머에는 사전에 커밋된 오프셋이 없을 경우 어떻게 작동해야 하는지를 결정하는 설정값을 갖는다.
즉, 데이터 맨 처음부터 읽기 시작해서 상당한 수의 많은 양의 데이터를 처리할 것인지, 아니면 맨 끝에서 시작해서 알려지지 않은 개수의 이벤트를 건너뛸 것인지 결정하게 된다.
방법2: 오프셋 토픽 복제
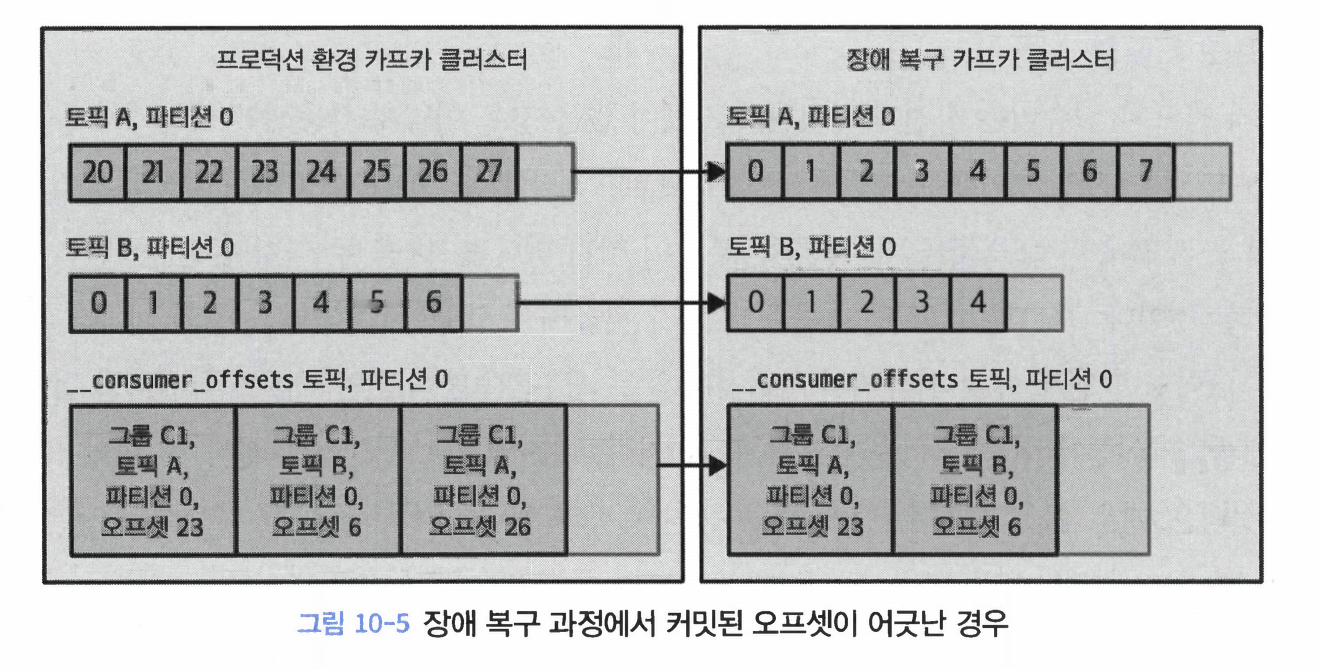
컨슈머는 자신의 오프셋을 __consumer_offsets라 불리는 특별한 토픽에 커밋한다.
만약 이 토픽을 DR 클러스터로 미러링해 준다면, DR 클러스터에서 읽기 작업을 시작하는 컨슈머는 이전에 주 클러스터에 마지막으로 커밋한 오프셋부터 작업을 재개하게 된다.
하지만, 여러 주의사항이 있다.
주 클러스터의 오프셋이 DR 클러스터의 오프셋과 일치할 것이라는 보장이 없다.
프로듀서 재시도로 인해 오프셋이 서로 달라질 수 있다.
설령 오프셋이 완벽히 보존되었다 할지라도, 주 클러스터와 DR 클러스터 사이에 랙이 존재한다는 것 그리고 현재 미러링 솔루션이 트랜잭션 기능을 지원하지 않는다는 사실 때문에, 카프카 컨슈머가 커밋한 오프셋이 해당 오프셋에 해당하는 레코드보다 먼저 혹은 늦게 도착할 수 있다.
이 방식은 다른 방식에 비해 단순하면서도 상대적으로 적은 이벤트 중복이나 유실로 생긴 장애를 복구할 수 있게 해준다.
방법3: 시간 기반 장애 복구
DR 클러스터로 장애 복구를 진행할 때 문제가 발생한 시점이 오전 4시 5분이라는 걸알 수 있다면, 컨슈머가 오전 4시 3분에 해당하는 데이터부터 처리를 재개하도록 할 수 있다.
2분가량 중복이 발생하기야 하겠지만, 다른 대안에 비해서는 더 나을 뿐더러 다른 사람들에게 상황을 설명하기도 훨씬 더 쉽다.
컨슈머가 특정 시간부터 데이터를 읽도록 처리하는 법
방법1: 애플리케이션의 시작 시간을 지정할 수 있는 사용자 설정을 추가한다.
이 값이 설정되어 있을 경우 애플리케이션은 API를 사용해서 주어진 시각에 해당하는 오프셋을 가져오고, 해당 오프셋을 이동한 뒤, 바로 그 지점에서부터 읽기 작업을 시작하면 되는 것이다.
방법2: 카프카는 타임스탬프 기준 초기화를 포함하는 다양한 오프셋 초기화을 지원한는 kafka-consumer-groups라는 툴을 제공한다.
방법4: 오프셋 변환
오프셋 토픽을 미러링할 때 가장 어려운 것은 주 클러스터와 DR 클러스터의 오프셋이 어긋날 수 있다.
과거 해결법: 아파치 카산드라와 같은 외부 데이터 저장소를 사용해서 한 클러스터에서 다른 클러스토러의 오프셋 변환을 저장하기도 했다.
최근 해결법: 미러메이커를 포함한 미러링 솔루션들이 오프셋 변환 메타데이터를 저장하기 위해 카프카 토픽을 사용한다.
장애 복구 작업을 수행하게 되면, 타임스탬프 기준으로 오프셋을 변환하는 대신 주 클러스터 오프셋에 매핑되는 DR 클러스터 오프셋을 찾아서 여기서부터 작업을 재개하게 된다.
장애 복구가 끝난 후
장애 복구가 성공적으로 마무리되면, 장애가 생겼던 주 클러스터를 이제 DR 클러스터로 역할을 변경해야 한다.
이 때 두 가지 문제를 제기한다.
어디서부터 미러링을 시작해야 하는지 어떻게 아는가? 어떠한 해법을 찾던 간에 중복이 발생하거나, 유실이 발생하거나, 심지어 둘 다 발생할 수 있다.
이전 주 클러스터는 DR 클러스터가 가지고 있지 않은 이벤트를 가지고 있을 가능성이 높다. 만약 새로운 데이터를 반대 방향으로 미러링하기 시작한다면, 이 여분의 이벤트들은 여전히 이전 주 클러스터 안에 남아있을 것이고 따라서 두 클러스터의 내용물은 서로 달라지게 된다.
이러한 이유 때문에, 일관성과 순서 보장이 극도로 중요한상황에서 가장 간단한 해법은 일단 원래 주 클러스터에 저장된 데이터와 커밋된 오프셋을 완전히 삭제한 뒤 새로운 주 클러스터에서 완전히 새것이 된 새 DR 클러스터로 미러링을 시작하는 것이다.
클러스터 디스커버리 관련
스탠바이 클러스터를 준비할 때 고려해야 할 것 중에 가장 중요한 것 하나는 장애가 발생한 상황에서 애플리케이션이 장애 복구용 클러스터와 통신을 시작하는 방법을 알 수 있게 하는 것이다.
많은 조직에서는 호스트 이름을 최대한 단순하게 정한 뒤 DNS를 써서 주 클러스터 브로커로 연결한다. 그리고 비상 상황이 닥치면, DNS 이름을 스탠바이 클러스터로 돌린다.
카프카 클라이언트는 클러스터 메타데이터를 얻어와서 다른 브로커 위치를 찾기 위해서 하나의 브로커에만 성공적으로 접근할 수 있으면 된다.
따라서, DNS가 모든 브로커에 대한 IP 주소를 가질 필요는 없고 대체로 3개의 브로커에 대한 정보만 가지고 있도록 한다.