쿼리 작성과 연관된 시스템 변수
SQL 모드
- MySQL 서버의
sql_mode라는 시스템 설정에는 여러 개의 값이 동시에 설정될 수 있다.sql_mode를 설정할 때는 구분자(,)를 이용해 키워드를 동시에 여러 개 설정할 수 있다.
- MySQL 서버의
sql_mode시스템 변수에 설정된 값들은 SQL 문장 작성 규칙뿐만 아니라 MySQL 서버 내부적으로 자동 실행되는 데이터 타입 변환 및 기본값 제어 등과 관련된 옵션도 가지고 있다.- 그래서 일단 MySQL 서버에 사용자 테이블을 생성하고 데이터를 저장하기 시작했담녀 가능한 한
sql_mode시스템 변수의 내용은 변경하지 않는 것이 좋다.
- 그래서 일단 MySQL 서버에 사용자 테이블을 생성하고 데이터를 저장하기 시작했담녀 가능한 한
- 명시 가능한 시스템 변수
STRICT_ALL_TABLES,STRICT_TRANS_TABLESANSI_QUATESONLY_FULL_GROUP_BYPIPE_AS_CONCATPAD_CHAR_TO_FULL_LENGTHNO_BACKSLASH_ESCAPESIGNORE_SPACEREAL_AS_FLOATNO_ZERO_IN_DATE,NO_ZERO_DATEANSITRADITIONAL
영문 대소문자 구분
- MySQL 서버는 설치된 운영체제에 따라 테이블명의 대소문자를 구분한다.
- 이는 MySQL의 DB나 테이블이 디스크의 디렉터리나 파일로 매핑되기 때문이다.
- 윈도우에 설치된 MySQL에서는 대소문자를 구분하지 않지만 유닉스 계열의 운영체제에서는 대소문자를 구분한다.
- MySQL 서버가 운영체제와 관계없이 대소문자 구분의 영향을 받지 않게할면 MySLQ 서버 설정 파일에
lower_case_table_names시스템 변수를 설정하면 된다.- 1로 설정하면 모두 소문자로만 저장되고, MySQL 서버가 대소문자를 구분하지 않는다.
- 기본값인 0은, DB나 테이블명에 대해 대소문자를 구분한다.
- 윈도우와 macOS에서는 2를 설정할 수 있는데, 이 경우에는 저장은 대소문자를 구분해서 하지만 MySQL의 쿼리에서는 대소문자를 구분하지 않게 해준다.
- 이러한 설정 자체를 떠나서 가능함녀 초기 DB나 테이블을 생성할 때 대문자 또는 소문자만으로 통일해서 사용하는 편이 좋다.
MySQL 예약어
- 생성하는 데이터베이스나 테이블, 컬럼의 이름을 예약어와 같은 키워드로 생성하면 해당 컬럼이나 테이블을 SQL에서 사용하기 위해 항상 역따옴표(`)나 쌍따옴표로 감싸야 한다.
- 예약어를 모두 구분해서 기억하기란 쉽지 않기 때문에, 테이블을 생성할 때 역따옴표로 테이블을 명이나 컬럼명을 둘러싸지 않고 생성해보는 것이 좋다.
- 예약어가 존재한다면 에러가 발생할 것이다.
MySQL 연산자와 내장 함수
- MySQL에서만 사용되는 연산자나 표기법이 있다.
- 이번 절에서는 MySQL에서만 사용 가능한 연산자도 함께 살펴보겟지만, 가능하면 SQL의 가독성을 높이기 위해 ANSI 표준 형태의 연산자를 사용하기를 권장한다.
리터럴 표기법 문자열
문자열
- SQL 표준에서는 항상 홀따옴표(’)를 사용해서 표시한다.
- 하지만 MySQL에서는 다음과 같이 쌍따옴표를 사용해 문자열을 표기할 수도 있다.
- SQL 표준에서는 문자열 값에 홀땅모표가 포함돼 있을 때 홀따옴표를 두번 연속해서 입력하면 된다.
- 하지만 MySQL에서는 쌍따옴표와 홀따옴표를 혼합해서 이러한 문제를 피해 가기도 한다.
- SQL에서는 사용되는 식별자가 키워드와 충돌할 때 오라클이나 PostgreSQL에서는 쌍따옴표나 대괄호로 감싸서 충돌을 피한다.
- MySQL에서는 역따옴표(`)를 감싸서 사용하면 예약어와의 충돌을 피할 수 있다.




숫자
- 숫자 값을 상수로 사용할 때는 따옴표(’ 또는 “) 없이 숫자 값을 입력하면 된다.
- MySQL은 숫자 타입과 문자열 타입 간의 비교에서 숫자 타입을 우선시하므로 문자열 값을 숫자 값으로 변환한 후 비교를 수행한다.
- 첫 번째 쿼리는 주어진 상숫값을 숫자로 변환하는데, 이때는 상숫값 하나만 변환하므로 성능과 관련된 문제가 발생하지 않는다.
- 두 번째 쿼리는
string_column컬럼의 모든 문자열 값을 숫자로 변환해 비교하므로 인덱스가 있더라도 이를 이용하지 못한다. 
날짜
- 다른 DBMS에서 날짜 타입을 비교하거나 INSERT 하려면 문자열을 DATE 타입으로 변환하는 코드가 필요하다.
- 하지만 MySQL에서는 정해진 형태의 날짜 포맷으로 표기하면 MySQL 서버가 자동으로 DATE나 DATETIME 값으로 변환한다.
- 아래 두 쿼리는 MySQL에서 동작에 차이가 없다.

불리언
- BOOL 이나 BOOLEAN이라는 타입이 있지만 사실 이것은 TINYINT 타입에 대한 동의어일 뿐이다.
- MySQL에서는 FALSE가 정숫값이 0이 되지만 TRUE는 C/C++ 언어와 달리 1만을 의미한다는 점에 주의해야한다.
- 그래서 숫자 값이 저장된 컬럼을 TRUE나 FALSE로 조회하려면 0이나 1이외의 숫자 값은 조회되지 않는다.

MySQL 연산자
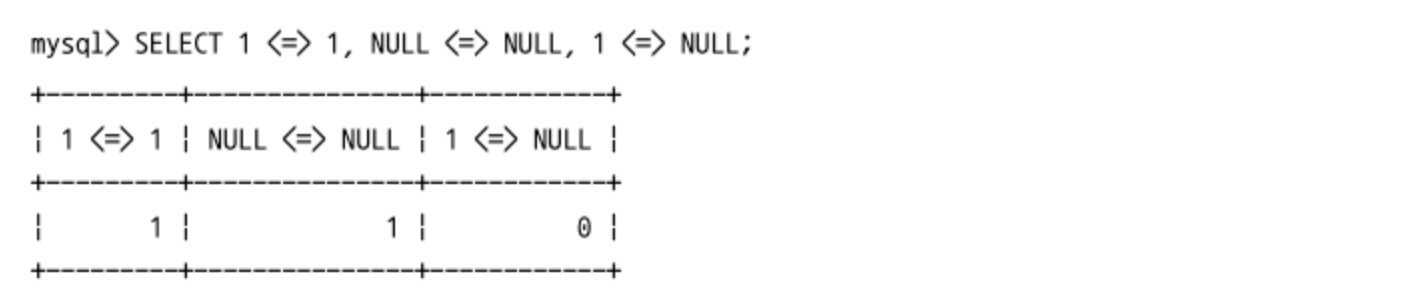
동등(Equal) 비교(=, <=>)
- 동등 비교는 “=” 기호를 사용해 비교를 수행하면된다.
- MySQL에서는 추가로 NULL-Safe 동등 비교를 위해 “<=>” 연산자도 제공한다.

부정(Not-Equal) 비교(<>, !=)
- 일반적으로 “<>“를 많이 사용한다.
- “!=” 도 사용 가능한데, SQL 문장에서 혼용되면 가독성이 떨어지므로 통일해서 사용하는 방법을 권장한다.
NOT 연산자(!)
- TRUE 또는 FALSE 연산의 겨로갈르 반대로 만드는 연산자로 “NOT"을 사용한다.
- 불리언 값뿐만 아니라 숫자나 문자열 표현식에서도 사용할 수 잇지만 부정의 결괏값을 정확히 예측할 수 없는 경우에는 사용을 자제하는 것이 좋다.


AND(&&)와 OR(||) 연산자
- MySQL에서는 AND와 OR 뿐만 아니라 “&&“dhk “||“의 사용도 허용한다.
- 오라클에서는 “||“를 불리언 표현식의 결합 연산자가 아니라 문자열을 결합하는 연산자로 사용한다.
- sql_mode 시스템 변수값에
PIPE_AS_CONCAT을 설정하면 MySQL에서도 “||“를 문자열을 결합하는 연산자로 사용할 수 있다. - SQL의 가독성을 높이기 위해 다른 용도로 사용될 수 있는 “&&” 연산자와 “||” 연산자는 사용ㅇ르 자제하는 것이 좋다.

나누기(/, DV)와 나머지(%, MOD) 연산자
- 일반적인 나누기 연산자 “/”
- 나눈 곲의 정수 부분만 가져오려면 DIV
- 나눈 결과의 나머지를 가져오는 연산자로는 “%” 또는 MOD 연산자

REGEXP 연산자
- 비교 대상 문자열 값 또는 문자열 컬럼을 정규 표현식을 사용해서 검증할 때
RLIKE또는REGEXP를 사용할 수 있다. REGEXP조건의 비교는 인덱스 레인지 스캔을 사용할 수 없기때문에, WHERE 조건절에REGEXP연산자를 단독으로 사용하는 것은 성능상 좋지 않고 데이터 조회 범위를 주일 수 있는 조건과 함께 사용하길 권장한다.

LIKE 연산자
LIKE는 단순한 문자열 패턴 비교 연산자이지만,REGEXP연산자보다 훨씬 더 많ㅇ ㅣ사용한다.LIKE연산자는 인덱스를 이용해 처리할 수도 있다.- 와일드카드 문자인 ‘%‘나 ‘_‘문자 자체를 비교한다면
ESCAPE절을LIKE조건 뒤에 추가해 이스케이프 문자를 설정할 수 있다. - 와일드 카드문자인 (%, _)가 검색어 뒤쪽에 이싸면 인덱스 레인지 스캔으로 상요할수 있지만, 검색어의 앞쪽에 있다면 Left-most 특성으로 인덱스 레인지 스캔을 사용하지 못한다.

BETWEEN 연산자
- “크거나 같다"와 “작거나 같다"라는 두 개의 연산자를 하나로 합친 연산자다.
BETWEEN연산자는 다른 비교 조건과 결합해 하나의 인덱스를 사용할 때 주의해야할 점이 있다.BETWEEN연산자는 범위를 읽어야 하는 연산자라dept_no가 ‘d003’이상 ‘d005’ 이하인 모든 인덱스의 범위를 검색해야만 한다.IN연산자는 여러 개의 동등 비교를 하나로 묶는 것과 같은 연산자라서IN과 동등 비교 연산자는 같은 형태로 인덱스를 사용한다.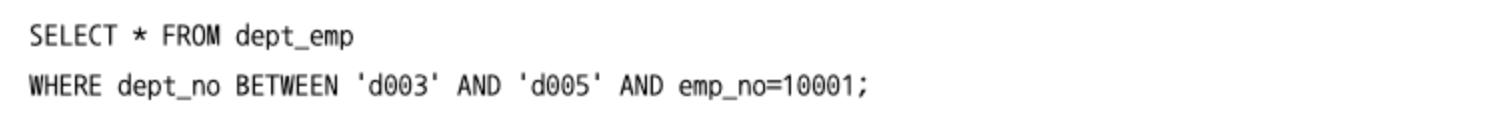

IN 연산자
- 여러 개의 값에 대해 동등 비교 연산을 수행하는 연산자
- 여러 개의 값이 비교되지만 범위로 검색하는 것이 아니라 여러 번의 동등 비교로 실행하기 때뭉네 일반적으로 빠르게 처리된다.
- IN 연산자는 두 형태를 구분해서 생각해볼 필요가 있다.
- 상수가 사용된 경우:
IN (?, ?, ?) - 서브쿼리가 사용된 경우:
IN (SELECT ... FROM ...)
- 상수가 사용된 경우:
- 상수가 사용된 경우는 동등 비교와 동일하기 작동하기 때문에 매우 빠르게 처리될 수 있다.
- IN 절에 튜플을 사용한 경우 MySQL 8.0 이전 버전 까지는 항상 풀 테이블 스캔이었지만, MySQL 8.0 부터는 인덱스를 최적으로 사용할 수 있다.

- 서브쿼리가 사용된 경우는 최적화가 까다로운데, MySQL 8.0 이전 버전까지만 해도 최적화가 상당히 불안했다. 하지만, MySQL8.0 부터는 최적화가 많이 안정화됐다.
NOT IN은 부정형 비교여서 인덱스를 이용해 처리 범위를 줄이는 조건으로는 사용할 수 없다.
MySQL 내장 함수
- MySQL의 함수는 MySQL에서 기본으로 제공하는 내장 함수와 사용자가 직접 작성해서 추가할 수 있는 사용자 정의 함수(UDF, User Defined Function)로 구분된다.
- MySQL에서는 제공하는 C/C++ API를 이요해 사요앚가 원하는 기능을 직접 함수로 만들어 추가할 수 있는데 ,이를 사용자 정의 함수라고 한다.
NULL 값 비교 및 대체(IFNULL, ISNULL)
IFNULL()은 두 개의 인자를 전달하는데, 첫 번째 인자는 NULL인지 아닌지 비교하려는 컬럼이나 표현식을, 두 번째 인자로는 첫 번째 인자의 값이 NULL 일 경우 대체할 값이나 컬럼을 설정한다.- 첫 번째 인자가 NULL이 아니면 첫 번째 인자의 값을, 첫 번째 인자의 값이 NULL이면 두 번째 인자의 값을 반환한다.
ISNULL()함수는 이름 그대로 인자를 전달한 표현식이나 컬럼의 값이 NULL이면 TRUE(1), 아니면 FALSE(0)을 반환한다.
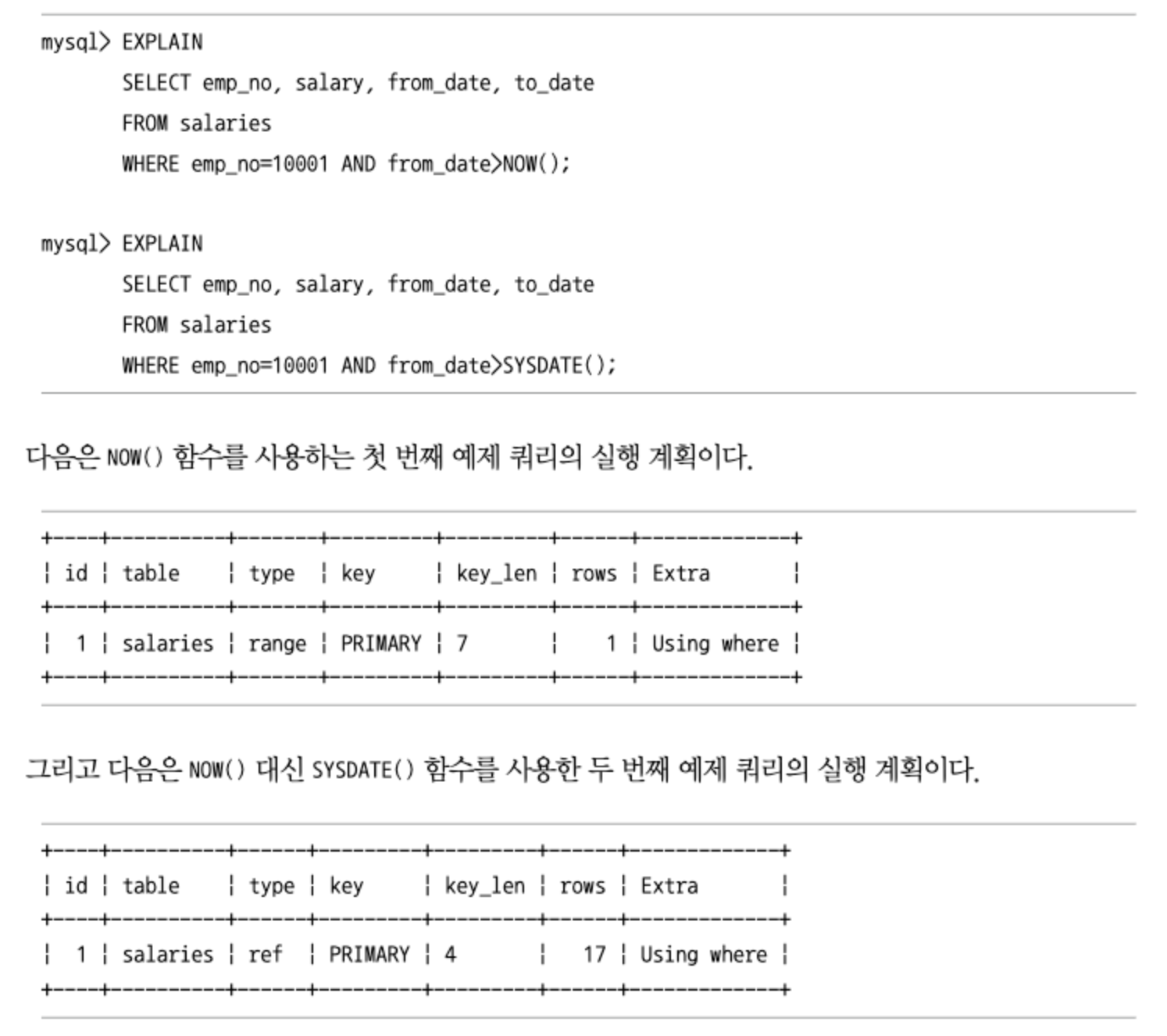
현재 시각 조회(NOW, SYSDATE)
- 하나의 SQL에서 모든
NOW()함수는 같은 값을 가지지만SYSDATE()함수는 하나의 SQL 내에서도 호출되는 시점에 따라 결괏값이 달라진다. SYSDATE()함수는 이러한 특성 탓에 두 가지 큰 잠재적인 문제가 있다.SYSDATE()함수가 사용된 SQL은 레플리카 서버에서 안정적으로 복제되지 못한다.SYSDATE()함수와 비교되는 컬럼은 인덱스를 효율적으로 사용하지 못한다.
- 아래와 같이
SYSDATE()함수와 비교된 컬럼은 인덱스를 사용하지 못하고 있다.

날짜와 시간의 포맷(DATE_FORMAT, STR_TO_DATE)
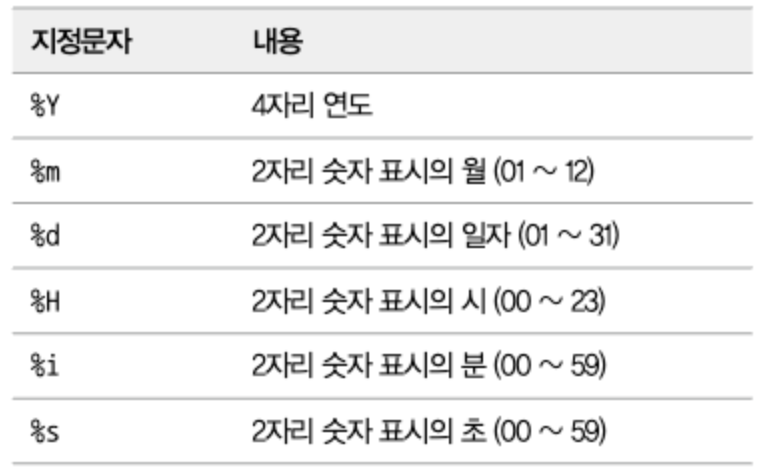
DATE_FORMAT()함수:DATETIME타입의 컬럼이나 값을 원하는 형태의 문자열로 변환STR_TO_DATE함수: 문자열을DATETIME으로 변환- 아래는 대표적인 지정자만 나열했으며, 나머지 더 자세한 사항은 매뉴얼을 참조하자.
날짜와 시간의 연산(DATE_ADD, DATE_SUB)
- 특정 날짜에서 연도나 월일 또는 시간 등을 더하거나 뺄 때는
DATE_ADD()함수나DATE_SUB()함수를 사용한다. - 두 번째 인자는
INTERVAL n [YEAR< MONTH< DAY, HOUR, MINUTE, SECOND, ...]형태로 입력해야 한다. 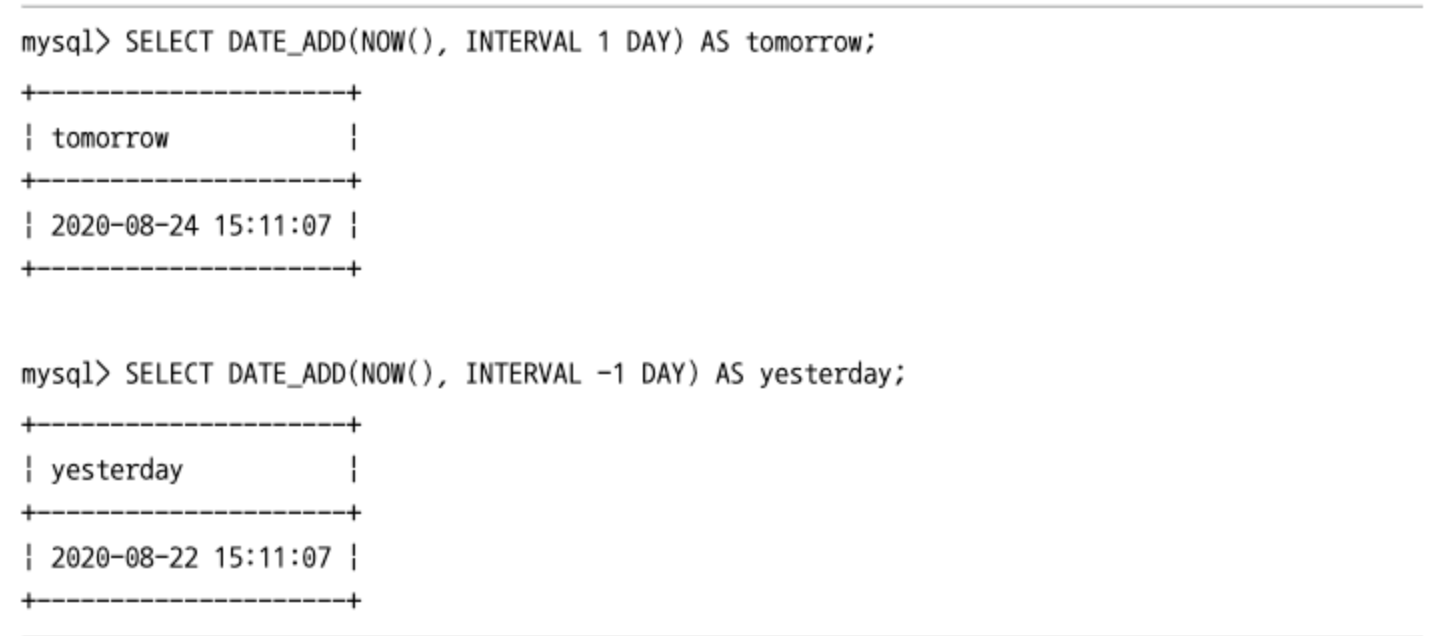
타임스탬프 연산(UNIX_TIMESTAMP, FROM_UNIXTIME)
TIMESTAMP는 ‘1970-01-01 00:00:00’으로부터 경과된 초의 수를 말한다.UNIX_TIMESTAMP()함수: 인자가 없으면 현재 날짜와 시간의 타임스탬프 값을, 인자로 특정 날짜를 전달하면 그 날짜와 시간의 타임스탬프를 반환한다.FROM_UNIXTIME()함수: 인자로 전달한 타임스탬프 값을DATETIME타입으로 변환하는 함수다.- MySQL의
TIMESTAMP타입은 4바이트 숫자 타입으로 저장되기 때문에 실제로 가질 수 있는 값의 범위는 ‘1970-01-01 00:00:00’~‘2038-01-09 03:14:07’까지의 날짜 값만 가능하다.
문자열 처리(RPAD, LPAD / RTRIM, LTRIM, TRIM)
RPAD()와LPAD()함수는 문자열의 좌측 또는 우측에 문자를 덧붙여서 지정된 길이의 문자열로 만다는 함수다.- 3개의 인자가 필요하다.
- 패딩 처리를 할 문자열
- 패딩 적용 후 결과로 반환될 문자열의 최대 길이
- 패딩할 문자
- 3개의 인자가 필요하다.
RTRIM()와LTRIM()함수는 문자열의 우측 또는 좌측에 연속된 공백 문자(Space, NewLine, Tab 문자)를 제거하는 함수다.TRIM()함수는LTRIM()과RTRIM()을 동시에 수행하는 함수다.
문자열 결합(CONCAT)
CONCAT(): 여러 개의 문자열을 연결해서 하나의 문자열로 반환하는 함수로, 인자의 개수는 제한이 없다.CONCAT_WS(): 각 문자열을 연결할 때 구분자를 넣어준다.


GROUP BY 문자열 결합(GORUP_CONCAT)
COUNT(),MAX()등과 같은 그룹 함수 중 하나다.- 주로
GROUP BY와 함께 사용하며,GROUP BY가 없는 SQL에서 사용하면 하나의 결과값만 만들어낸다. - 아래 예시는
dept_emp테이블에서emp_no를 역순으로 정렬해서,dept_no컬럼의 값을 연결해서 가져오는 쿼리다. 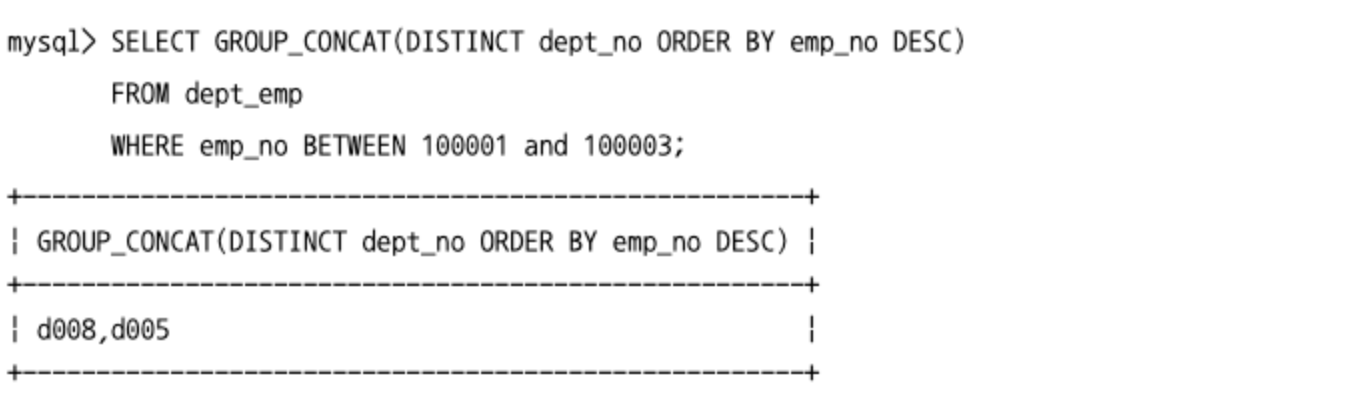
GROUP_CONCAT()함수는 지정한 컬럼의 값들을 연결하기 위해 제한적인 메모리 버퍼 공간을 사용한다.- 어떤 쿼리에서
GROUP_CONCAT()함수의 겨로가가 시스템 변수(group_concat_max_len)에 지정된 크기를 초과하면 경고 메시지가 발생한다. - 하지만 JDBC로 실행될 때는 경고가 아니라 에러로 취급되어 쿼리가 실패한다.
- 어떤 쿼리에서
값의 비교와 대체(CASE WHEN … THEN … END)
- 2가지 방법으로 사용할 수 있다.
- 동등 비교하는 연산
- 표현식으로 비교하는 방식
CASE WHEN구문에서 한 가지 중요한 사실은CASE WHEN절이 일치하는 경우에만THEN이하의 표현식이 실행된다는 점이다.


타입의 변환(CAST, CONVERT)
CAST()CONVERT()함수는 타입을 변환하는 용도 뿐만아니라 문자 집합을 변환하는 용도로도 사용할 수 있다.


이진값과 16진수 문자열(Hex String) 변환(HEX, UNHEX)
HEX(): 이진값을 사람이 읽을 수 있는 형태의 16진수의 문자열로 변환하는 함수UNHEX(): 16진수 문자열을 이진값(BINARY)으로 변환하는 함수다.
암호화 및 해시 함수(MD5, SHA, SHA2)
SHA(): SHA-1 암호화 알고리즘을 사용하며, 결과로 160비트(20바이트) 해시 값을 반환한다.SHA2(): SHA-2 암호화 알고리즘을 사용하며, 더 강력한 224비트부터 512비트 암호화 알고리즘을 사용해 생성된 해시 값을 반환한다.MD5(): 메시지 다이제스트 알고리즘을 사용해 128비트(16바이트) 해시 값을 반환한다.- 해시 함수들은 사용자의 비밀번호와 같은 암호화가 필요한 정보를 인코딩하는 데 사용된다.
- 위 함수들은 16진수 문자열 형태로 반환되기 때문에 저장하려면 해시 값 사이즈의 2배가 필요하다.
- 저장 공간을 원래 사이즈로 줄이고 싶다면
CHAR나VARCHAR가아닌BINARY또는VARBINARY형태의 타입에 저장하면된다. 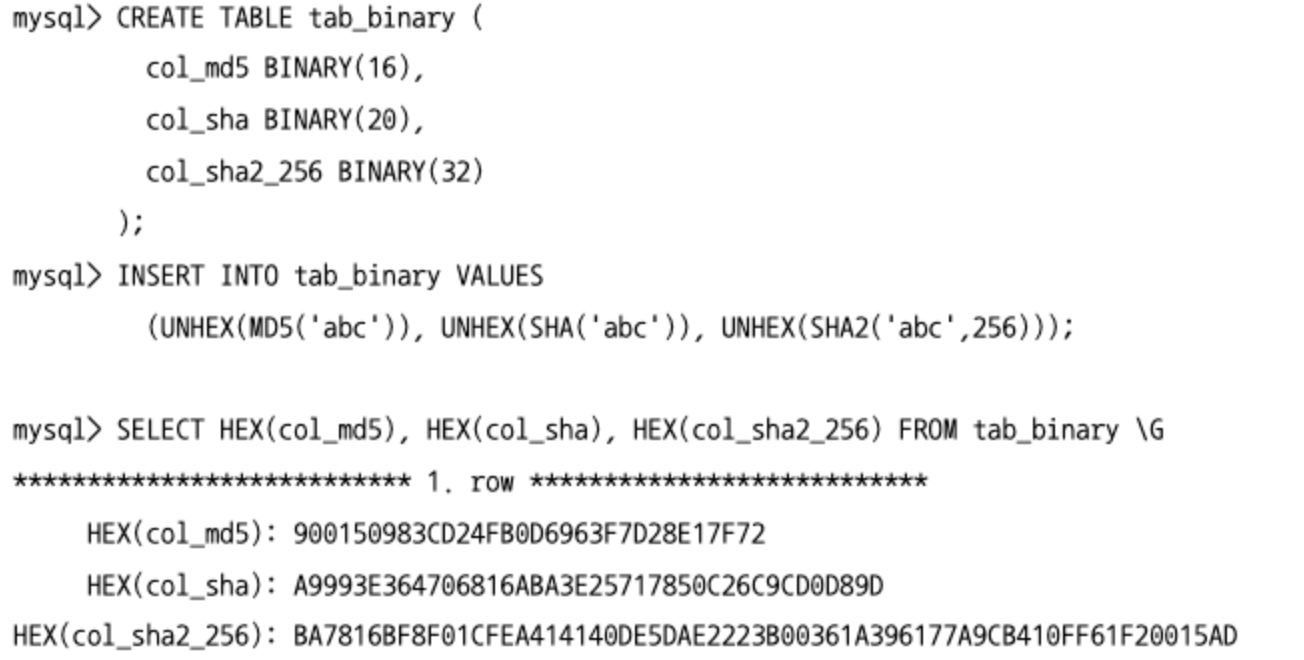
- 저장 공간을 원래 사이즈로 줄이고 싶다면
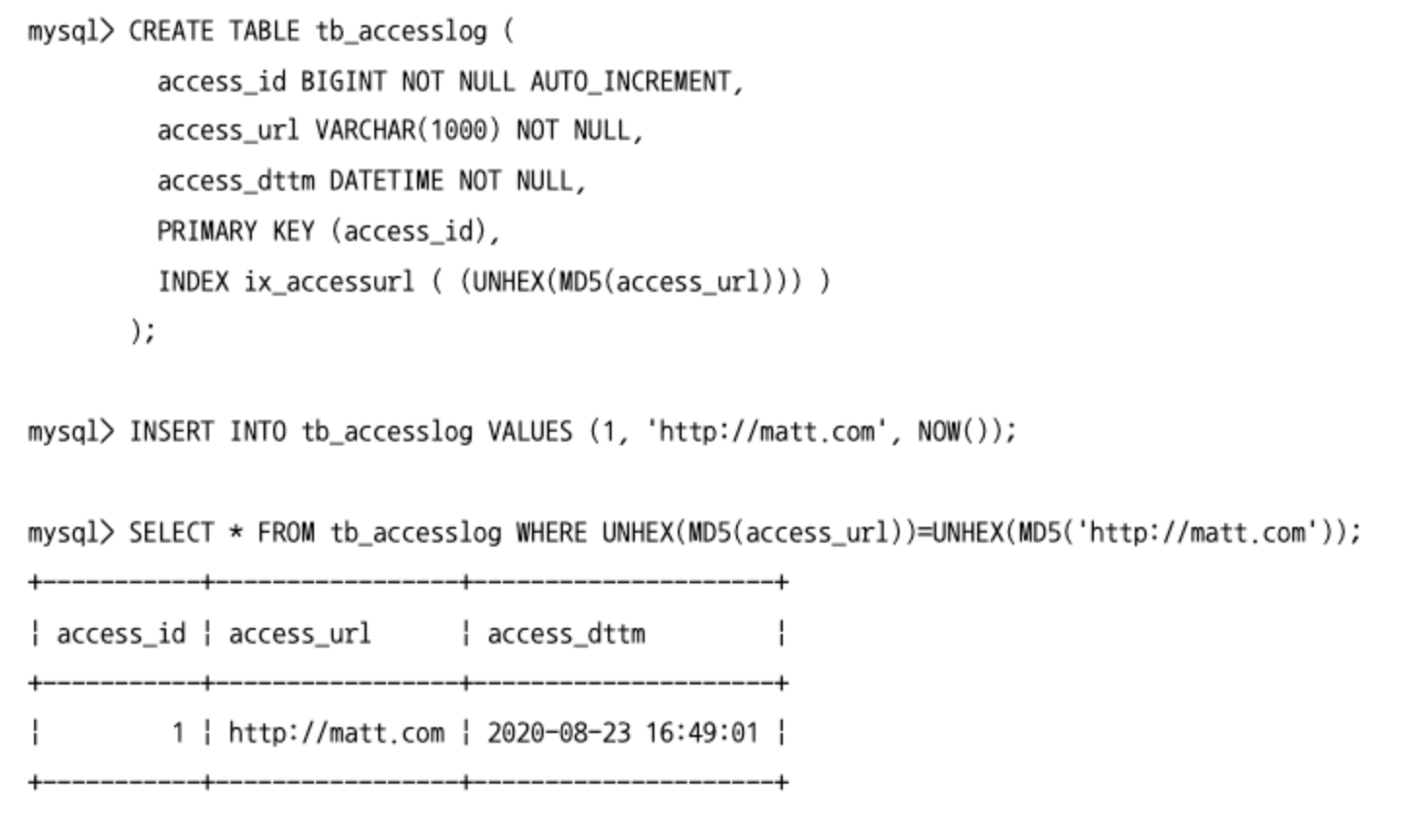
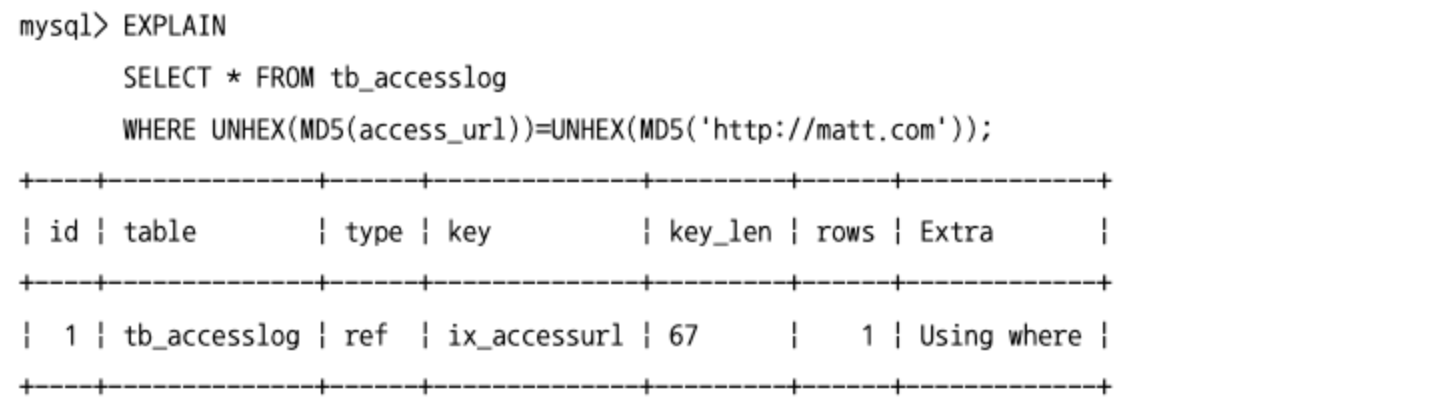
- 해시 결괏값은 중복 가능성이 매우 낮기 때문에 길이가 url 같이 긴 데이터의 크기를 줄여서 인덱싱하는 용도로도 사용된다.
- MySQL 8.0 버전부터는 함수 기반의 인덱스를 생성하면 별도 컬럼을 추가하지 않고도 해시를 기준으로 인덱스를 만들 수 있다.
처리 대기(SLEEP)
- 디버깅 용으로 주로 사용한다.
- 쿼리 실행 도중 멈춰서 대기하는 기능이다.

벤치마크(BENCHMARK)
- 디버깅이나 간단한 함수의 성능 테스트용으로 사용하는 함수다.
- 첫 번째 인자는 반복해서 수행할 횟수이며, 두 번째 인자로는 반복해서 실행할 표현식을 입력하면 된다.
- 두 번째 인자의 표현식은 반드시 스칼라값을 반화하는 표현식이어야 한다.

- 주의할 점은
SELECT BENCHMARK(10, expr)와SELECT expr을 10번 직접 실행하는 것과는 차이가 있다.- 전자는 쿼리 네트워크, 쿼리 파싱 및 최적화 비용이 한 번 밖에 소요되지 않지만, 후자는 10번 소요된다.
- 전자는 expr 표현식이 할당받은 메모리 자원을 공유하기 때문에 메모리 할당에 소요되는 비용도 1/10밖에 일어나지 않는다.
- 그래서 전자가 후자보다 짧은 시간에 완료된다.
IP 주소 변환(INET_ATON, INET_NTOA)
- IP 주소는 4바이트의 부호없는 정수이다.
- MySQL에서는
INET_ATON()함수와INET_NTOA()함수를 이용해 IPv4 주소를 문자열이 아닌 부호 없는 정수 타입에 저장할 수 있게 제공한다.INET_ATON(): 문자열로 구성된 IPv4 주소를 정수형으로 변환INET_NTOA(): 정수형의 IPv4 주소를 사람이 읽을 수 있는 형태의 ‘.‘으로 구분된 문자열로 변환

JSON 포맷(JSON_PRETTY)
JSON_PRETTY()함수를 이용하면 JSON 컬럼의 값을 읽기 쉬운 포맷으로 변환해준다.
JSON 필드 크기(JSON_STORAGE_SIZE)
- JSON 데이터는 텍스트 기반이지만 MySQL 서버는 디스크의 저장 공간을 절약하기 위해 JSON 데이터를 실제 디스크에 저장할 때 BSON(Binary JSON) 포맷을 사용한다.
JSON_STORAGE_SIZE()함수를 이용해서 실제로 저장 곤간의 크기를 확인할 수 있다.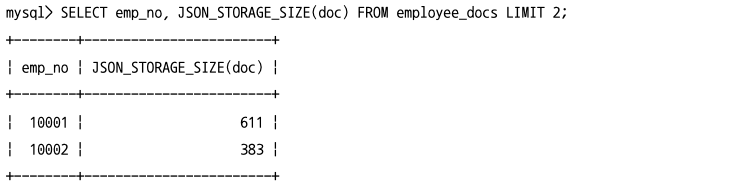
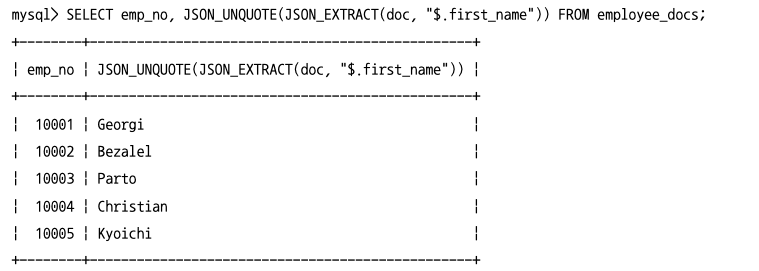
JSON 필드 추출(JSON_EXTRACT)
- JSON 도큐먼트에서 특정 필드의 값을 가져오는 가장 일반적인 방법은
JSON_EXTRACT()함수를 사용하는 것이다. JSON_EXTRACT()함수의 결과는 따옴표가 붙은 상태인데,JSON_UNQUOTE()함수를 사용하면 따옴표 없이 값만 가져올 수 있다.- 사용자 편의성을 위해 MySQL 서버는 다음과 같이 JSON 연산자를 제공한다.
->연산자는JSON_EXTRACT()함수와 동일->>연산자는JSON_UNQUOTE()홤수와JSON_EXTRACT()함수를 조합한 것과 동일한 기능이다.


JSON 오브젝트 포함 여부 확인(JSON_CONTAINS)
- JSON 도큐먼트 또는 지정된 JSON 경로에 JSON 필드를 가지고 있는지 확인하는 함수다.

JSON 오브젝트 생성(JSON_OBJECT)
- RDBMS 컬럼의 값을 이용해 JSON 오브젝트를 생성하는 함수다.

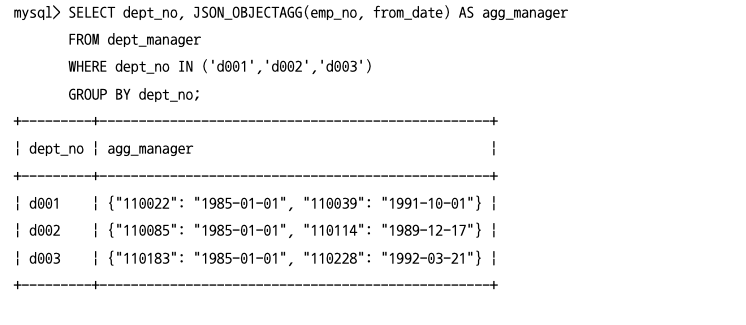
JSON 컬럼으로 집계(JSON_OBJECTAGG & JSON_ARRAYAGG)
JSON_OBJECTAGG()와JSON_ARRAYAGG()함수는GROUP BY절과 함께 사용되는 집계 함수로서, RDMBS 컬럼의 값들을 모아 JSON 배열 또는 도큐먼트를 생성하는 함수다.JSON_OBJECTAGG()의 첫번째 인자는 키, 두번째 인자는 값에 해당한다.JSON_ARRAYAGG()의 하나의 인자로 배열을 만든다.

JSON 데이터를 테이블로 변환(JSON_TABLE)
- JSON 데이터의 값들을 모아서 RDBMS 테이블을 만들어 반환한다.
JSON_TABLE()함수는 항상 내부 임시 테이블을 이용하기 때문에 임시 테이블에 레코드가 많이 저장되지 않게 주의해야된다.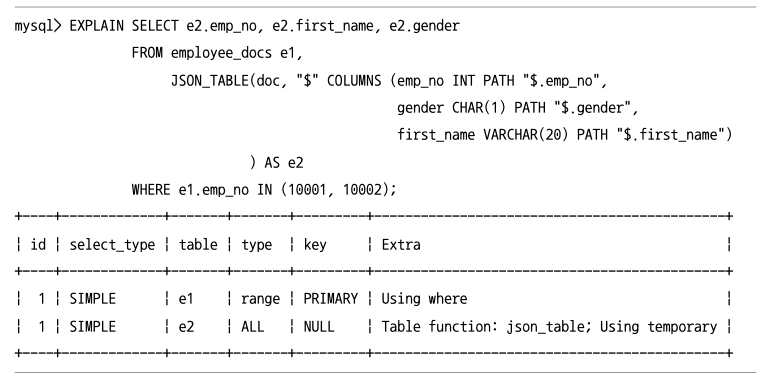
SELECT
- 웹 서비스 같이 일반적인 온라인 트랜잭션 처리 환경의 데이터베이스의 SELECT는 여러 개의 테이블로부터 데이터를 조합해서 빠르게 가져와야 하기 때문에 여러 개의 테이블을 어떻게 읽을 것인가에 많은 주의를 기울여야 한다.
SELECT 절의 처리 순서
- SELECT 문장의 처리 순서
- CTE와 윈도우 함수를 사용할 때를 제외하고는 아래 순서가 바뀌는 경우가 거의 없다.
- ORDER BY나 GROUP BY 절이 있더라도 인덱스를 이용해 처리할 때는 그 단계 자체를 생략한다.
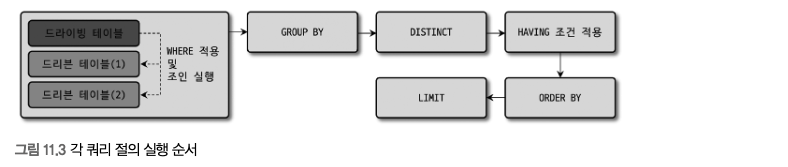
- 예외적으로 GROUP BY 절이 없이 ORDER BY만 사용된 쿼리에서는 아래와 같은 순서로 사용될 수도 있다.
- 첫 번째 테이블만 읽어서 정렬을 수행한 뒤에 나머지 테이블을 읽는 것이다.
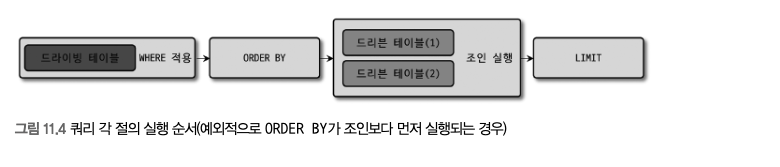
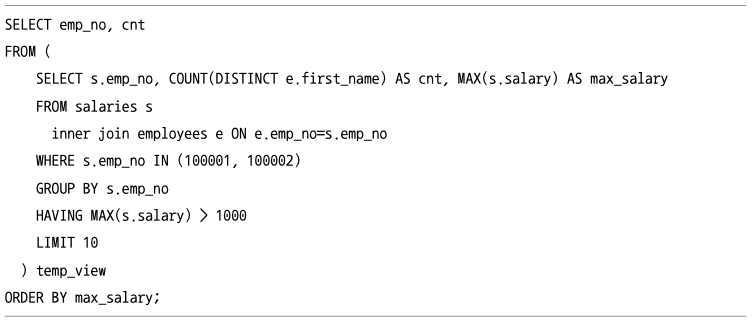
- 위에서 소개한 실행 순서를 벗어난 쿼리가 필요하다면 서브쿼리로 작성된 인라인 뷰를 사용해야된다.
- 인라인 뷰가 사용되면 임시 테이블이 사용되기 때문에 주의해야한다.
WHERE 절과 GROUP BY 절, ORDER BY 절의 인덱스 사용
인덱스를 사용하기 위한 기본 규칙
- 기본적으로 인덱스된 컬럼의 값 자체를 변환하지 않고 그대로 사용한다는 조건을 만족해야 한다.
- 인덱스는 컬럼의 값을 아무런 변환 없이 B-Tree에 정렬해서 저장하기 때문이다.
- 비교 조건에서 연산자 양쪽의 두 비교 대상 값은 데이터 타입이 일치해야 한다.
- 복잡한 연산을 수행한다거나
MD5()함수와 같이 해시 값을 만들어서 비교해야 하는 경우라면 미리 계산된 값을 저장하도록 MySQL의 가상 컬럼을 추가하고 그 컬럼에 인덱스를 생성하거나 함수 기반의 인덱스를 사용하면 된다.
WHERE 절의 인덱스 사용
- WHERE 조건이 인덱스를 사용하는 방법은 크게 작업 범위 결정 조건과 체크 조건 두 가지 방식으로 구분할 수 있다.
- 작업 범위 결정 조건: WHERE 절에서 동등 비교 조건이나 IN으로 구성된 조건에 사용된 컬럼들이 인덱스의 컬럼 구성과 좌측에서부터 비교했을 때 얼마나 일치하는가에 따라 달라진다.
- 체크 조건: 인덱스의 컬럼이 작업 범위 결정 조건으로 사용되지 못하는 경우를 말한다.
GROUP BY 절의 인덱스 사용
- GROUP BY가 인덱스를 사용할 수 있는 조건
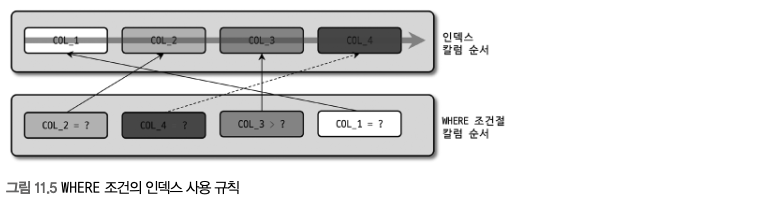
- GROUP BY 절에 명시된 컬럼이 인덱스 컬럼의 순서와 위치가 같아야 한다.
- 인덱스를 구성하는 컬럼 중에서 뒤쪽에 있는 컬럼은 GROUP BY 절에 명시되지 않아도 인덱스를 사용할 수 있지만, 인덱스의 앞쪽에 있는 컬럼이 GROUP BY 절에 명시되지 않으면 인덱스를 사용할 수 없다.
- WHERE 조건절과 달리 GROUP BY 절에 명시된 컬럼이 하나라도 인덱스에 없으면 GROUP BY 절은 전혀 인덱스를 이용하지 못한다.
- (COL_1, COL_2, COL_3, COL_4) 로 만들어진 인덱스가 있을 때
- 아래는 인덱스를 사용하지 못한다.
- 아래는 인덱스를 사용할 수 있다.
- WHERE 절과 GROUP BY 절이 혼용된 쿼리의 경우는 WHERE 조건절에 동등 비교 조건으로 사용된 컬럼을 GROUP BY 절로 옮겨보면 된다.
- 아래는 인덱스를 사용하지 못한다.



ORDER BY 절의 인덱스 사용
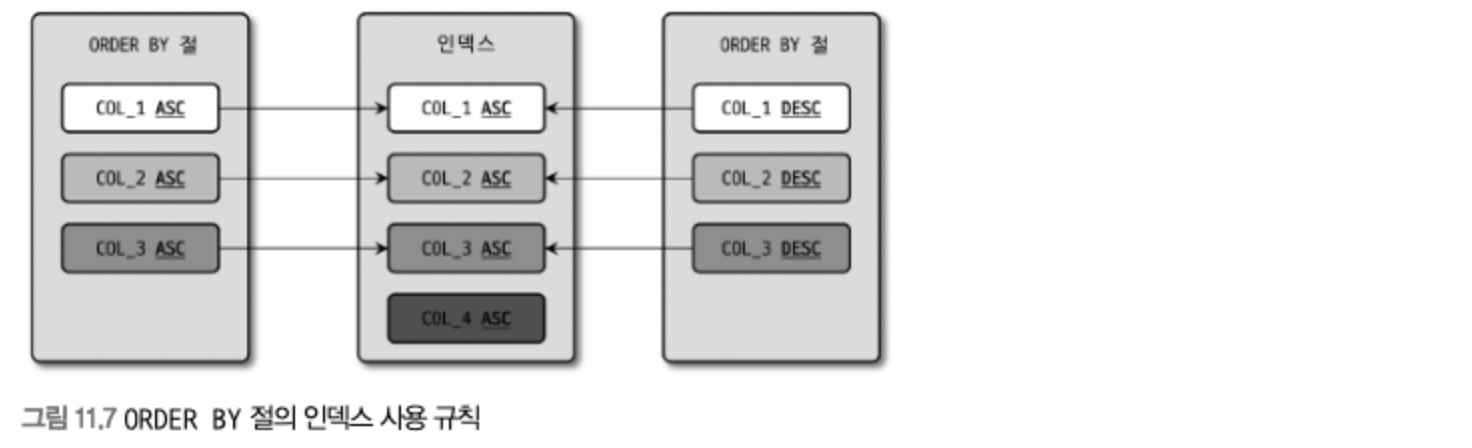
- GROUP BY의 요건과 거의 흡사 하지만, 조건이 하나 더 있다.
- 정렬되는 각 컬럼의 오름차순 및 내림차순 옵션이 인덱스와 같거나 정반대인 경우에만 사용할 수 있다.
WHERE 조건과 ORDER BY(또는 GROUP BY) 절의 인덱스 사용
- WHERE 절과 ORDER BY 절이 같이 사용된 하나의 쿼리 문장은 다음 3가지 중 한 가지 방법으로만 인덱스를 이용한다.
- WHERE 절과 ORDER BY 절이 동시에 같은 인덱스를 이용: 나머지 2가지 방식보다 훨씬 빠른 성능
- WHERE 절만 인덱스를 이용: 인덱스를 통해 검색된결과 레코드를 별도의 정렬 처리 과정(Using Filesort)를 거쳐 정렬을 수행한다. 이 방법은 WHERE 절의 조건에 일치하는 레코드의 건수가 많지 않을 때 효율적인 방식이다.
- ORDER BY 절만 인덱스를 이용: ORDER BY 절의 순서대로 인덱스를 읽으면서 레코드를 한 건씩 WHERE 절의 조건에 일치하는지 비교하고, 일치하지 않을 때는 버리는 형태로 처리한다. 주로 아주 많은 레코드를 조회해서 정렬해야 할 때는 이런 형태로 튜닝하기도 한다.
- ORDER BY 절에 해당 컬럼이 사용되고 있다면 WHERE 절에 동등 비교 이외의 연산자로 비교돼도 WHERE 조건과 ORDER BY 조건이 모두 인덱스를 이용할 수 있다.
- WHERE 조건에 있는 동등 비교를 ORDER BY 절에 이동시켜 동시에 인덱스를 이용할 수 있는지 쉽게 판단할 수 있다.
- 첫 번째 쿼리는 COL_1이 범위 조건이지만 ORDER BY에서 COL_1이 사용되고 있어서 WHERE과 ORDER BY절에서 모두 인덱스를 사용할 수 있다.
- 두 번째 쿼리는 ORDER BY절에 COL_1을 명시하지 않았기 때문에 정렬할 때는 인덱스를 사용할 수 없다.
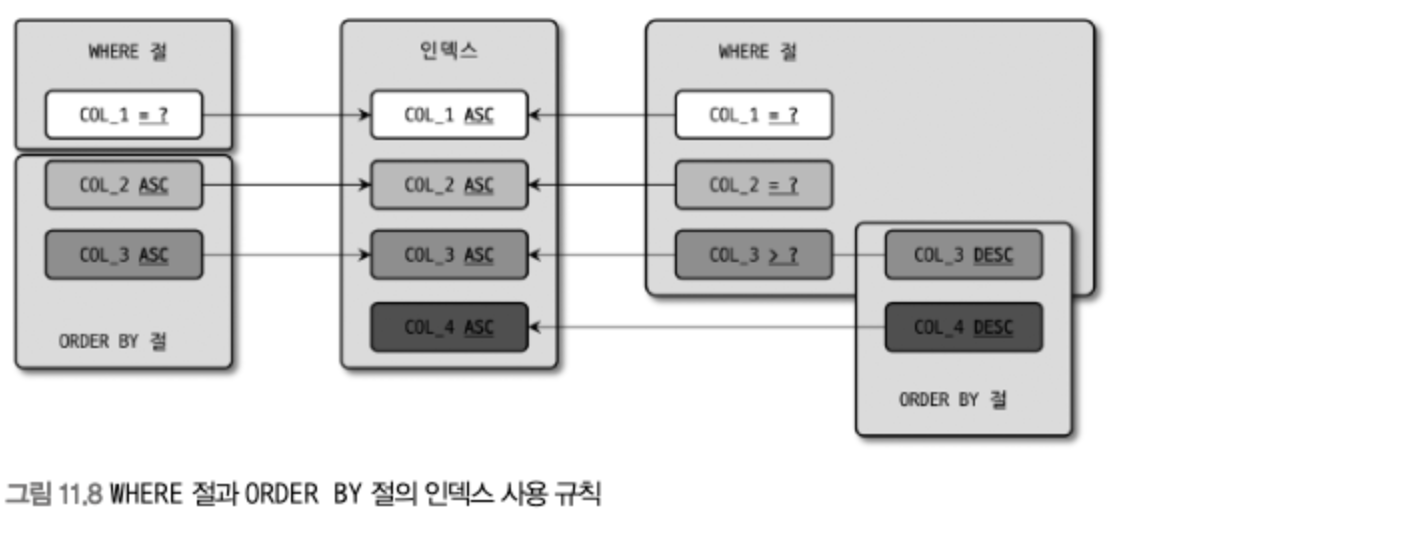



GROUP BY 절과 ORDER BY 절의 인덱스 사용
- GROUP BY와 ORDER BY 절이 동시에 사용된 쿼리에서 두 절이 모두 하나의 인덱스를 사용해서 처리되려면 GROPU BY 절에 명시된 컬럼과 ORDER BY에 명시된 컬럼이ㅡ 순서와 내용이 모두 같아야 한다.
- GROUP BY와 ORDER BY가 같이 사용된 쿼리에서는 둘 중 하나라도 인덱스를 사용할 수 없을 때는 둘다 인덱스를 사용하지 못한다.
- MySQL 5.7 버전까지는 GROUP BY는 GROUP BY 컬럼에 대한 정렬까지 함께 수행하는 것이 기본 작동 방식이었다.
- 하지만 MySQL 8.0 부터는 GROUP BY 절이 컬럼의 정렬까지는 보장하지 않는 형태로 바뀌었다.
- 그래서 MySQL 8.0 부터는 GROUP BY 컬럼으로 그루핑과 정렬을 모두 수행하기 이ㅜ해서는 GROPU BY 절과 ORDER BY 절을 모두 명시해야 한다.
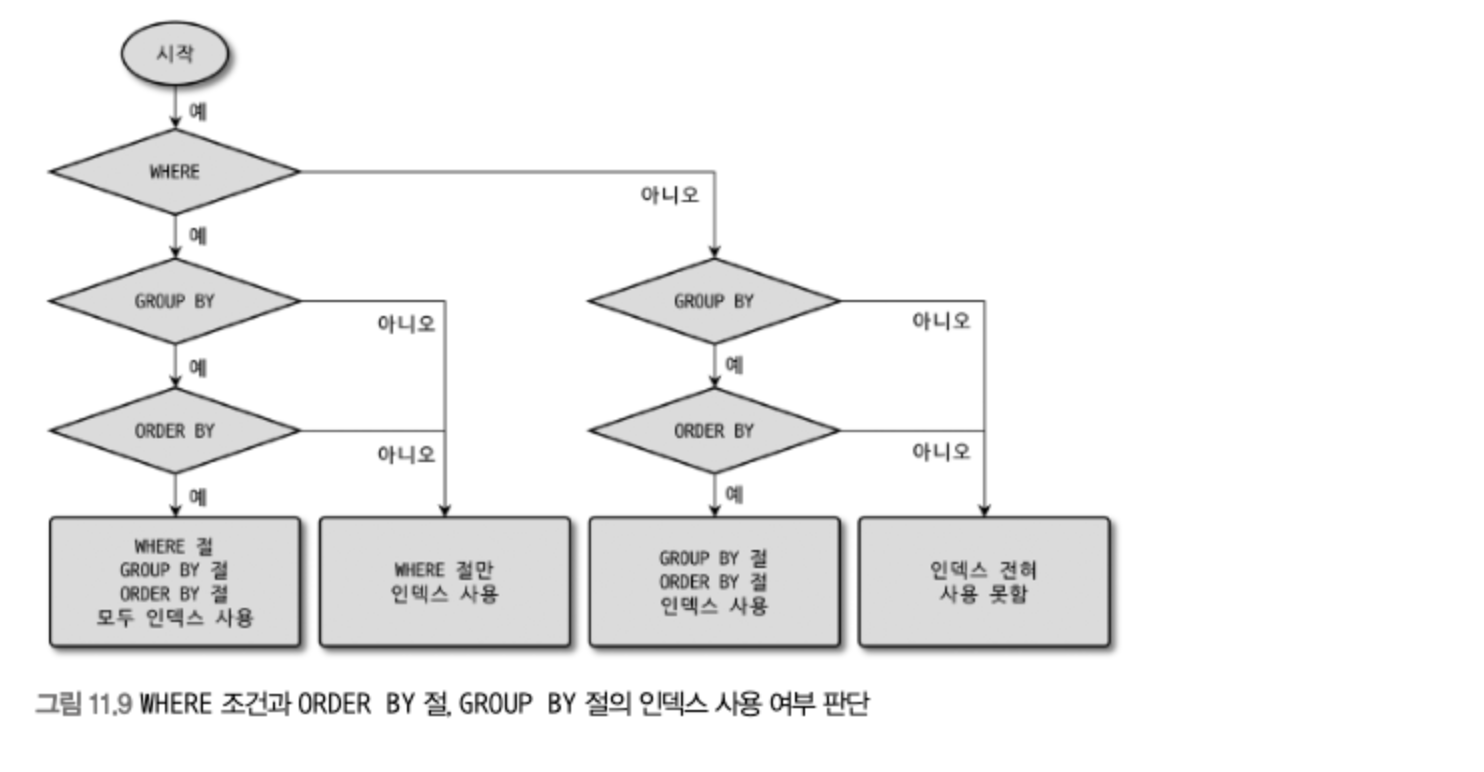
WHERE 조건과 ORDER BY 절, GROPU BY 절의 인덱스 사용
- 아래 3개의 질문을 기본으로해서 흐름을 적용해보면 된다.
- WHERE 절이 인덱스를 사용할 수 있는가?
- GROUP BY 절이 인덱스를 사용할 수 있는가?
- GROUP BY 절과 ORDER BY 절이 동시에 인덱스를 사용할 수 있는가?
WHERE 절의 비교 조건 사용 시 주의사항
NULL 비교
- 다른 DBMS와는 조금 다르게 MySQL에서는 NULL 값이 포함된 레코드도 인덱스로 관리된다.
- 쿼리에서 NULL인지 비교하려면
IS NULL(또는<=>)을 사용해야 인덱스를 사용할 수 있다. - 아래 예시에서 3, 4번째 쿼리는 추가적인 연산이 필요해서 인덱스를 사용할 수 없다.

문자열이나 숫자 비교
- 문자열 컬럼이나 숫자 컬럼을 비교할 때는 반드시 그 타입에 맞는 상숫값을 사용할 것을 권장한다.
날짜 비교
- DATE 또는 DATETIME과 문자열 비교
- DATE 또는 DATETIME 타입의 값과 문자열을 비교할 때는 문자열 값을 자동으로 DATETIME 타입의 값으로 변환해서 비교를 수행한다.
- 따라서 아래 두 쿼리는 동일하게 동작하고, 인덱스를 사용할 수 있다.

- 아래 첫 번째 쿼리는 컬럼을 변경하기 때문에 인덱스를 사용할 수 없고, 두 번째 쿼리는 상수를 변형하기 때문에 인덱스를 사용할 수 있다.
- DATE와 DATETIME 비교
- DATETIME 값에서 시간 부분만 떼어버리고 비교하려면
DATE()함수를 사용하면 된다. - 직접 타입 변환을 하지 않고 DATETIME과 DATE를 비교하면 MySQL 서버가 DATE 타입의 값을 DATETIME으로 변환해서 비굘르 수행한다.
- “2011-06-30"의 DATE 타입의 값을 “2011-06-30 00:00:00"으로 변환해서 비교한다.
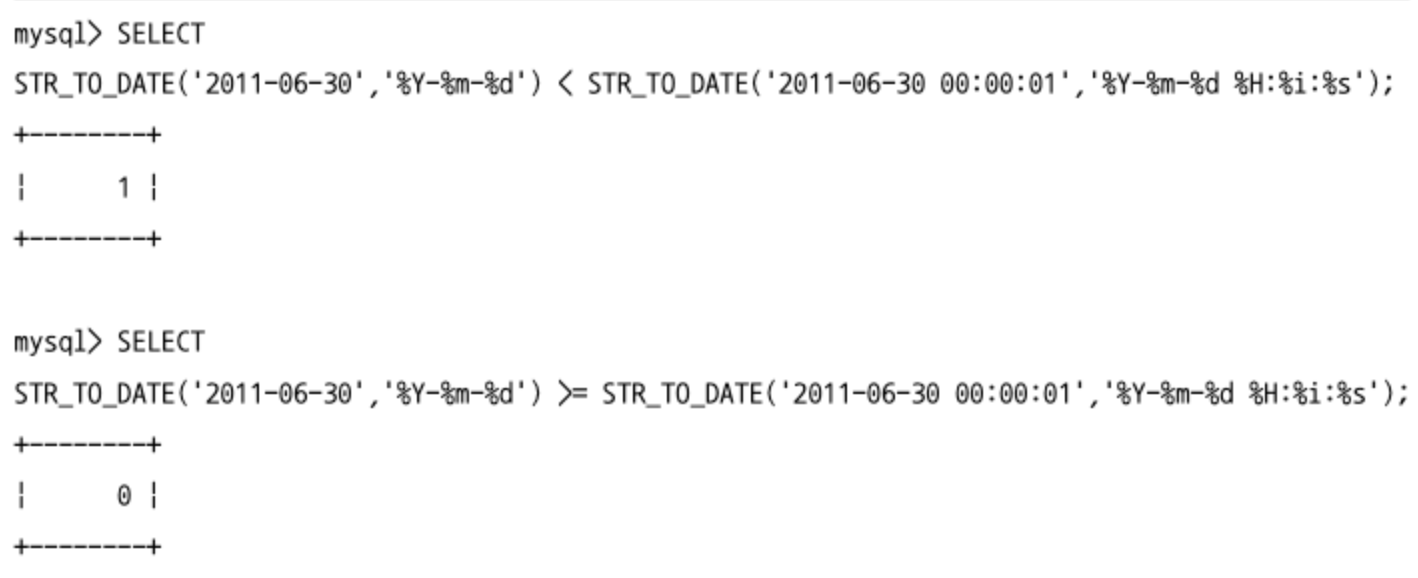
- DATETIME 값에서 시간 부분만 떼어버리고 비교하려면
- DATETIME과 TIMESTAMP의 비교
- 대상 컬럼의 타입에 맞게 변환해서 사용하는 것이 좋다.
- 컬럼이 DATETIME 타입이라면
FROM_UNIXTIME()함수를 통해 TIMESTAMP 값을 DATETIME 타입으로 만들어서 비교해야 한다. - 컬럼이 TIMESTAMP 타입이라면
UNIX_TIMESTAMP()함수를 통해 DATETIME 값을 TIMESTAMP로 타입으로 만들어서 비교해야 한다. 


Short-Circuit Evaluation
- Short-Circuit Evaluation:
a && b라는 조건이 있을 때 a가 false이면 b는 연산하지 않는다. - MySQL에서도 Short-Circuit Evaluation을 통해 최적화가 이루어질 수 있다.
- 아래 두 쿼리는 같은 결과를 내놓지만 처리 속도가 다르다.
to_date<'1985-01-01'조건을 만족하는 행이 더 적기 때문이다.CONVERT_TZ함수를 실행하기 위한 추가적인 비용이 더 들기도 한다.
- 인덱스를 사용할 수 있는 경우라면, 해당 조건은 WHERE 절 내에 순서 상관없이 먼저 처리된다.
- 아래 쿼리에서
first_name이 인덱스를 사용할 수 있다면first_name부터 인덱스를 사용해 먼저 평가되고, 그 다음엔 순서대로last_name과birdt_date가 순서대로 평가된다. 
- 아래 쿼리에서
- 아래와 같이 서브쿼리의 경우에도 Short-Circuit Evaluation으로 처리된다.

- 서브 쿼리의 비용이 더 커서 가장 나중에 비교하고 싶다면 아래와 같이 조건의 순서를 바꿔야한다.
DISTINCT
- 많은 사용자가 조인을 하는 경우 레코드가 중복해서 출력되는 것을 막기 위해
DISTINCT를 남용하는 경향이 있다. DISTINCT를 남용하는 것은 성능적인 문제도 있짐나 쿼리의 결과도 의도한 바와 달라질 수 있다.
LIMIT n
- LIMIT에서 필요한 레코드 건수만 준비되면 즉시 쿼리를 종료한다.

- 첫 번째 쿼리: LIMIT이 없다면 테이블을 처음부터 끝까지 읽는 풀 테이블 스캔을 실행할 것이다. 하지만 LIMIT 조건이 있기 때문에 풀 테이블 스캔을 실행하면서 MySQL이 스토리지 엔진으로부터 10개의 레코드를 읽어 들이는 순간 스토리지 엔진으로부터 읽기 작업은 멈춘다.
- 두 번째 쿼리: GROUP BY 처리가 완료되고 나서야 LIMIT 처리를 수행할 수 있다. 인덱스를 사용하지 못하는 GROUP BY, ORDER BY는 작업이 모두 완료돼야만 LIMIT을 수행할 수 있다. 결국 LIMIT이 GROUP BY와 함께 사용되는 경우에는 LIMIT 절이 있더라도 실질적인 서버의 작업 내용은 크게 줄여주지는 못한다.
- 세 번째 쿼리: 테이블을 읽어 들임과 동시에 DISTINCT를 위한 중복 제거 작업을 진행한다. 이 작업을 반복적으로 처리하다가 유니크한 레코드가 LIMIT 건수 만큼 채워지면 그 순간 쿼리를 멈춘다.
- ORDER BY, GROUP BY, DISTINCT가 인덱스를 이용해 처리될 수 있다면 LIMIT 절은 꼭 필요한 만큼의 레코드만 읽게 만들어주기 때문에 쿼리의 작업량을 상당히 줄여준다.
- LIMIT의 인자가 2개인 경우에 첫 번째 인자에 지정된 위치부터 두 번째 인자에 명시된 개수만큼의 레코드를 가져온다.
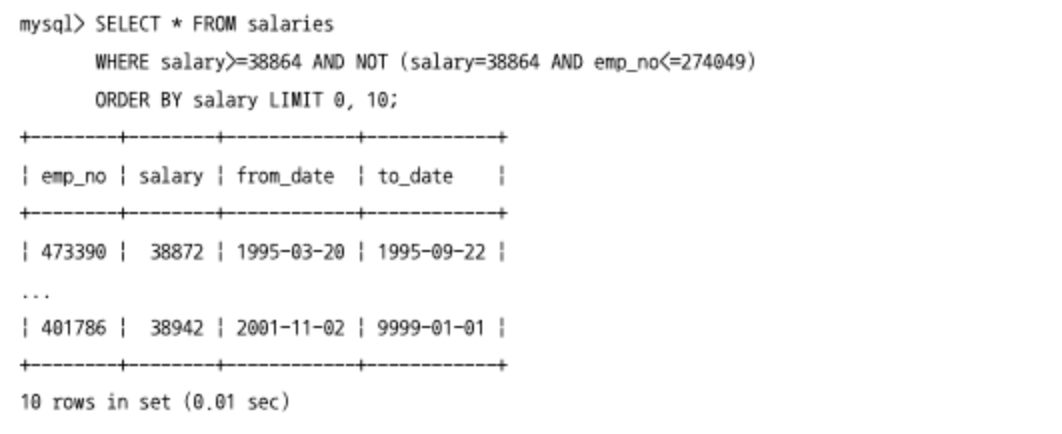
SELECT * FROM ORDER BY salary LIMIT n, m- n+m 건만큼 레코드를 읽은 후 n건을 버리기 때문에, n 값이 커지면 쿼리가 느려질 수 있다.
- 페이징이 필요하다면 WHERE 조건절로 읽어야 할 위치를 찾고 그 위치에서 m개만 읽는 형태의 쿼리를 사용하는 것이 좋다.(커서 기반 페이징)
COUNT()
COUNT(*)에서*는 SELECT 절에서 사용될 때 처럼 모든 컬럼을 가져오라는 의미가 아니라 그냥 레코드 자체를 의미하는 것이다.- 따라서
COUNT(1)과COUNT(*)는 동일한 처리 성능을 보인다.
- 따라서
- MyISAM 스토리지 엔진을 사용하는 테이블에서는 테이블의 메타 정보로 전체 레코드 건수를 사용해서,
SELECT COUNT(*) FROM tb_table과 같이 WHERE 조건이 없는 COUNT 쿼리는 빠르게 처리된다. - InnoDB 스토리지 엔진을 사용하는 테이블에서는 WHERE 조건이 없는 COUNT라도 직접 데이터나 인덱스를 읽어야만 레코드 건수를 가져올 수 있개 때문에 큰 테이블에서 COUNT() 함수를 사용하는 작업은 주의해야 한다.
COUNT(*)쿼리에서 ORDER BY 구문 같이 레코드 건수를 가져오는 것과 무관한 작업은 제거하는 것이 성능상 좋다.- MySQL8.0 부터는 옵티마이저가
SELECT(*)쿼리에 사용된 ORDER BY 절은 무시하도록 개선됐다. 하지만 여전히 간결하게 쿼리를 작성하기 위해 ORDER BY 절을 제거하는 것이 좋다.
- MySQL8.0 부터는 옵티마이저가
- 많은 사용자가 일반적으로 컬럼의 값을 SELECT하는 쿼리보다
COUNT(*)쿼리가 훨씬 빠르게 실행될 것으로 생각한다.- 하지만 인덱스를 제대로 사용하도록 튜닝되지 못한
COUNT(*)쿼리는 페이징해서 데이터를 가져오는 쿼리보다 몇 배 또는 볓십 배 더 느리게 실행될 수도 있다. - 테이블의 전체 건수를 조회하는 작업은 피하는 것이 좋은데, 서비스에 페이지가 필요하면 페이지 번호를 보여주는 방식보다는 “이전"과 “다음” 버튼만 표시하는 방식을 검토해볼 것을 권장한다.
- 하지만 인덱스를 제대로 사용하도록 튜닝되지 못한
JOIN
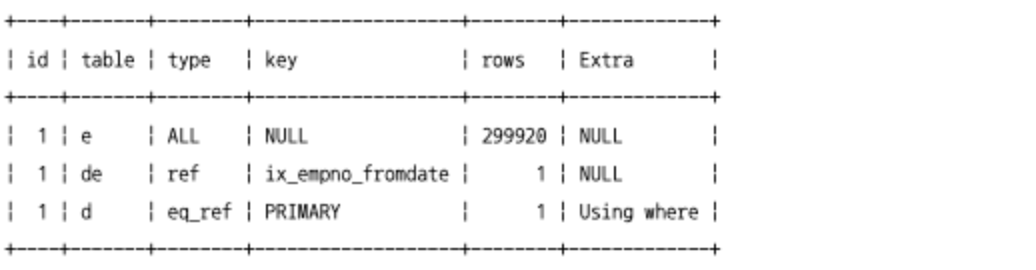
JOIN의 순서와 인덱스
- 인덱스 레인지 스캔은 인덱스 탐색, 인덱스 스캔 2가지 과정으로 구분해볼 수 있다.
- 일반적으로 인덱스를 이용해서 쿼리하는 작업을 가져오는 레코드의 건수는 소량이기 때문에 인덱스 스캔 작업은 부하가 작지만, 특정 인덱스 키를 찾는 인덱스 탐색 작업은 상대적으로 부하가 높은 편이다.
- 조인 작업에서 드라이빙 테이블을 읽을 때는 인덱스 탐색 작업을 단 한번만 수행하고, 그 이후부터는 스캔만 실행하면된다.
- 드리븐 테이블 테이블은 인덱스 탐색 작업과 스캔 작업을 드라이빙 테이블에서 읽은 레코드 건수만큼 반복한다.
- 그래서 옵티마이저는 항상 드라이빙 테이블이 아니라 드리븐 테이블을 최적으로 읽을 수 있게 실행 계획을 수립한다.

- 두 컬럼 모두 인덱스가 있는 경우: 테이블 통계 정보에 있는 레코드 건수에 따라 드라이빙 테이블을 결정한다.
employees.emp_no에만 인덱스가 있는 경우:dept_emp테이블이 테이블 풀 스캔을 피하기 위해서,dept_emp를 드라이빙 테이블로 선택할 가능성이 높다.- 두 컬럼 모두 인덱스가 없는 경우: 테이블 통계 정보에 있는 레코드 건수에 따라 드라이빙 테이블을 결정한다. MySQL 8.0.18이전 버전까지는 블록 네스티드 루프 조인을 사용했다. 하지만 MySQL 8.0.18 버전부터는 블록 네스티드 루프 조인이 없어지고 해시 조인이 도입되면서 해시 조인으로 처리된다.
JOIN 컬럼의 데이터 타입
- 테이블 조인 조건도 두 컬럼의 데이터 타입이 일치하지 않으면, 인덱스를 사용할 수 없다.
- 아래 두 타입 간의 비교에선느 인덱스를 사용할 수 있다.
CHAR타입과VARCHAR타입INT타입과BIGINT타입 또는SMALLINT타입DATE타입과DATETIME타입
- 아래의 경우에는 인덱스를 사용할 수 없다.
CHAR타입과INT타입의 비교 같이 데이터 타입의 종류가 완전히 다른 경우- 같은
CHAR타입이더라도 문자 집합이나 콜레이션이 다른 경우 - 같은
INT타입이더라도 부호(Sign)의 존재 여부가 다른 경우
OUTER JOIN의 성능과 주의사항
- 아우터로 조인되는 테이블은 절대 드라이빙 테이블로 선택하지 못하고, 풀 스캔이 필요한 테이블을 드라이빙 테이블로 선택한다.
- 아우터 조인으로 작성되면 옵티마이저가 조인 순서를 변경해 수행할 수 있는 최적화의 기회를 뻇어버리기 때문에, 꼭 필요한 경우가 아니라면 이너 조인을 사용하는 것이 업무 요건을 정확히 구현함과 동시에 쿼리의 성능도 향상시킬 수 있다.
- 아우터 조인 쿼리를 작성하면서 많이 하는 또 다른 실수는 아우터로 조인되는 테이블에 대한 조건을 WHERE 절에 함께 명시하는 것이다.
- 아래와 같이 아우터로 조인되는 테이블에 대한 조건이 WHERE 절에 있으면 INNER JOIN으로 변환해서 실행해버린다.


- 예외적으로 아우터로 조인되는 테이블에 대한 조건이 WHERE 절에 사용해야 하는 경우가 있는데, 다음과 같이 안티 조인(ANTI-JOIN) 효과를 기대하는 경우가 그렇다.


JOIN과 외래키(FOREIGN KEY)
- 외래키는 데이터 무결성을 보장하기 위해서만 필요하고, 조인과 아무런 연관이 없다.
- 데이터 모델링을 할 때는 각 테이블 간의 관계를 필수적으로 그려 넣지만, 그 데이터 모델을 데이터베이스에 생성할 때는 테이블 간의 관계를 외래키로 생성하지 않을 때가 더 많다.
지연된 조인(Delayed Join)
- 조인을 사용해서 데이터를 조회하는 쿼리에
GROUP BY또는ORDER BY를 사용할 때는 모든 조인을 실행하고 난 다음GROUP BY나ORDER BY를 처리할 것이다.- 조인의 결과를
GROUP BY나ORDER BY하면 조인을 실행하기 전에 레코드에GROUP BY나ORDER BY를 수행하는 것보다 많은 레코드를 처리해야 한다.
- 조인의 결과를
- 서브쿼리를 이용해서 조인이 실행되기 전에
GROUP BY나ORDER BY를 수행할 수 있다. - 지연된 조인은 다음과 같은 조건이 갖춰져야만 사용할 수 있다.
- LEFT (OUTER) JOIN인 경우 드라이빙 테이블과 드리븐 테이블은 1:1 또는 M:1 관계여야 한다.
- INNER JOIN인 경우 드라이빙 테이블과 드리븐 테이블은 1:1 또는 M:1의 관계임과 동시에 드라이빙 테이블에 있는 레코드는 드리븐 테이블에 모두 존재해야 한다. 드라이빙 테이블을 서브쿼리로 만들고 이 서브쿼리에 LIMIT을 추가해도 최종 결과의 건수가 변하지 않는다는 보증을 해주는 조긴이기때문에 반드시 정확히 확인한 후 적용해야 한다.


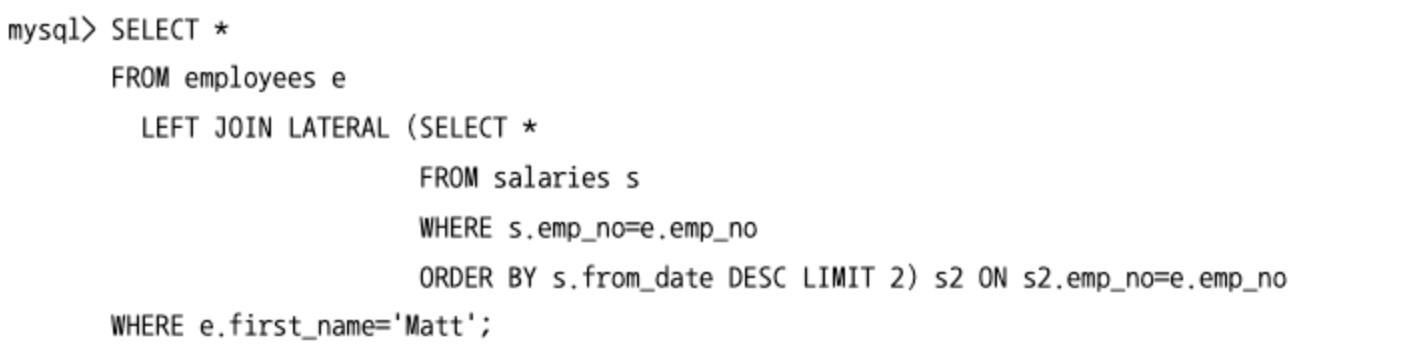
래터럴 조인(Leteral Join)
- MySQL 8.0 버전부터는 래터럴 조인이라는 기능을 이용해 특정 그룹별로 서브쿼리를 실행해서 그 결과와 조인하는 것이 가능해졌다.
- 아래 쿼리는 employees 테이블이 이름이 “Matt"인 사원에 대해 사원별로 가장 최근 급여 변경 내역을 최대 2건씩만 반환한다.
- 래터럴 조인의 특징은 FROM 절에 사용된 서브쿼리에서 외부 쿼리의 FROM 절에 정의된 테이블의 컬럼을 참조할 수 있다는 것이다.
- LATERAL 키워드를 가진 서브쿼리는 조인 순서상 후순위로 밀리고, 외부 쿼리의 레코드 단위로 임시 테이블이 생성되기 때문에 꼭 필요한 경우에만 사용해야 한다.
실행 계획으로 인한 정렬 흐트러짐
- MySQL 8.0 이전 버전까지는 네스티드-루프 방식의 조인만 가능했다.
- 네스티드-루프 조인은 알고리즘 특성상 드라이빙 테이블에서 읽은 레코드의 순서가 다른 테이블이 모두 조인돼도 그래도 유지된다.
- MySQL 8.0 버전부터는 해시 조인 방식이 도입됐다.
- 해시 조인은 드라이빙 테이블의 레코드 순서와 다르게 출력될 수 있다.
- 정렬된 결과가 필요한 경우라면 드라이빙 테이블의 순서에 의존하지 말고 ORDER BY 절을 명시적으로 사용하는 것이 좋다.
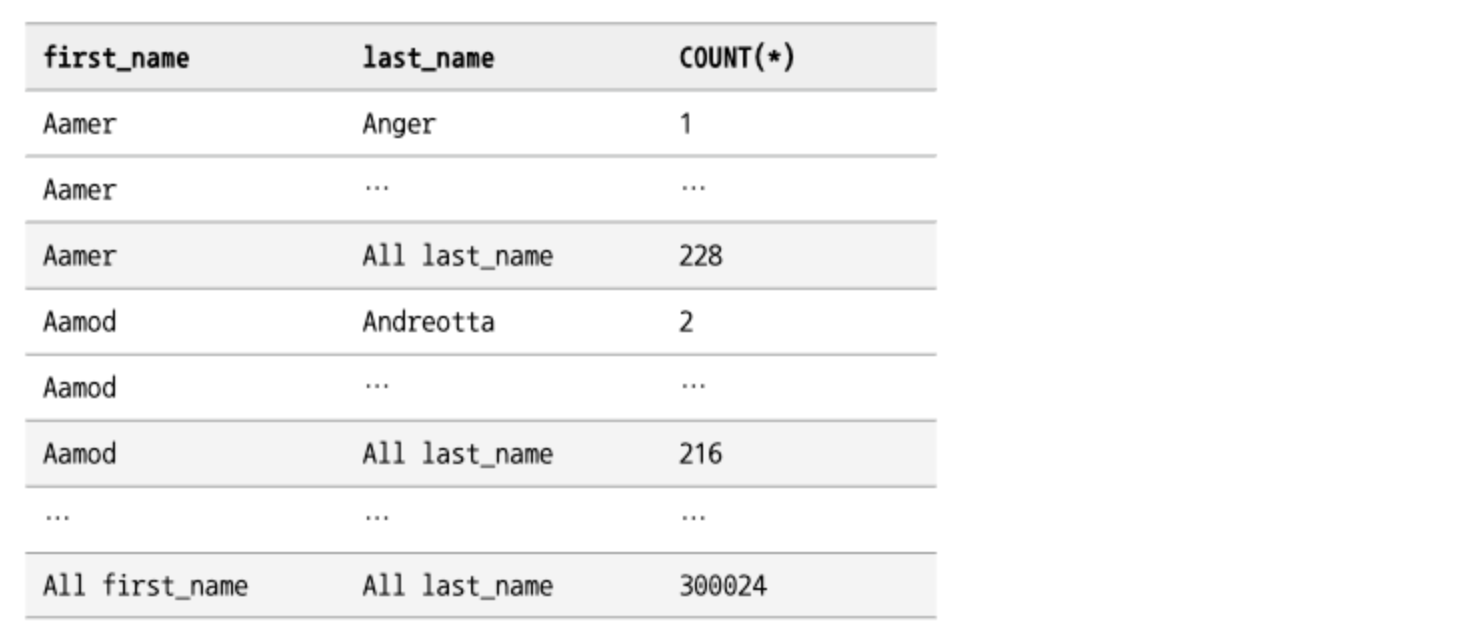
GROUP BY
WITH ROLLUP
그루핑된 그룹별로 소계를 가져올 수 있는 기능
GROUP BY에 사용된 컬럼의 개수에 따라 소계의 레벨이 달라진다.
소계 레코드의 컬럼값은 항상 NULL로 표시된다.
GROUP BY에 사용된 컬럼의 개수가 1개인 경우
GROUP BY에 사용된 컬럼의 개수가 2개인 경우
- 소계가 2단계로 표시된다.
first_name그룹별로 소계 레코드가 출력되고, 맨 마지막에 전체 총계가 출력된다. 

- 소계가 2단계로 표시된다.
MySQL 8.0 버전부터는 그룹 레코드에 표시되는 NULL을 사용자가 변경할 수 있게
GROUPING()함수를 지원한다.



레코드를 컬럼으로 변환해서 조회
- 레코드를 컬럼으로 변환
- 부서별로 사원의 수를 확인하는 쿼리

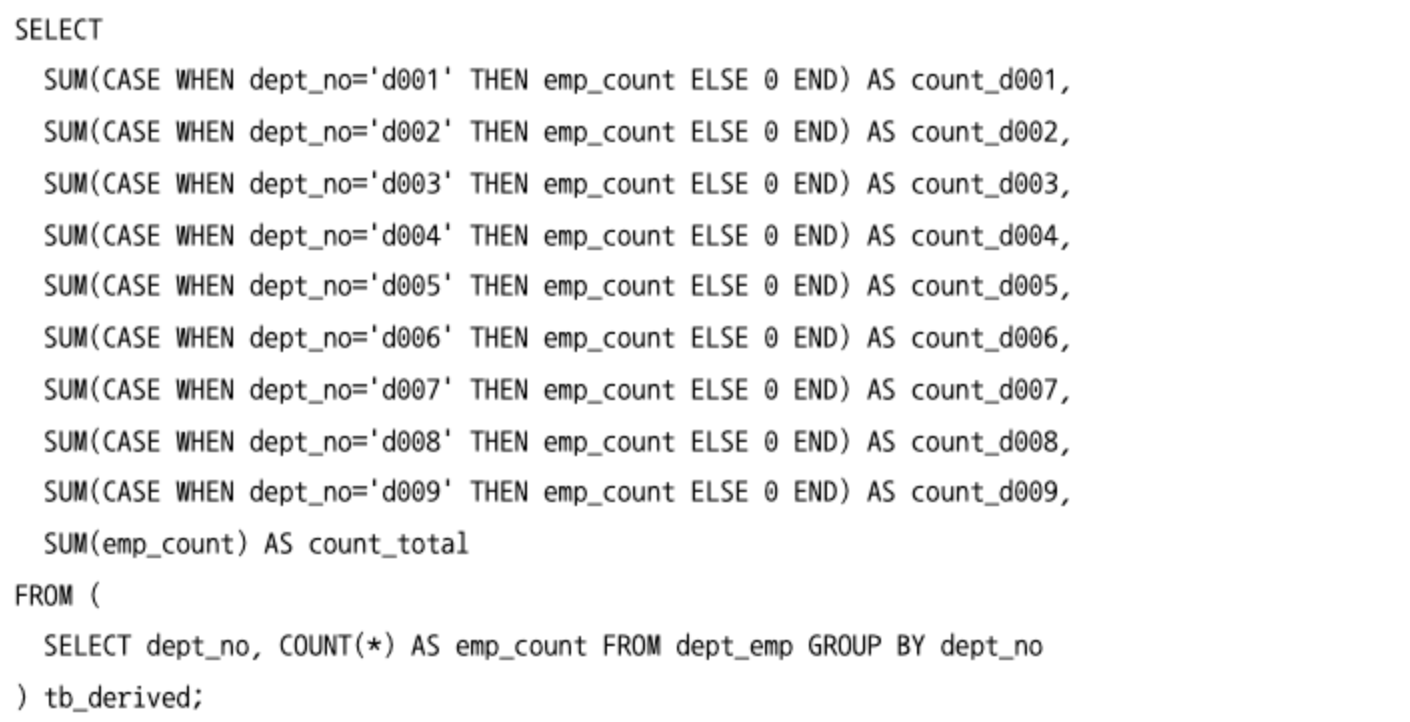

- 하나의 컬럼을 여러 컬럼으로 분리

- 부서 내 입사 연도별 사원 수

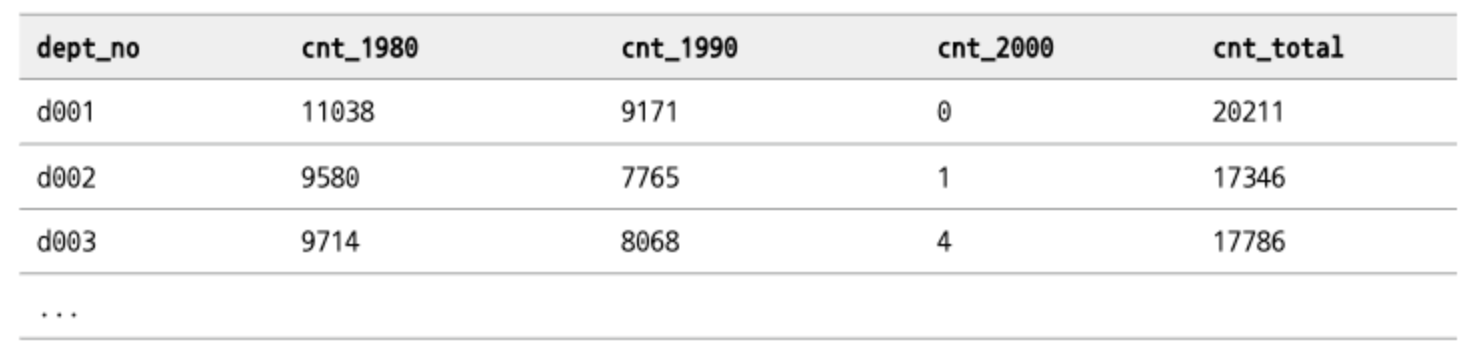
ORDER BY
- ORDER BY 절이 명시되지 않은 쿼리에 대해서는 어떠한 정렬도 보장하지 않는다.
- ORDER BY에서 인덱스를 사용하지 못할 때는 추가 정렬작업이 수행되며, 쿼리 실행 계획에 있는 Extra 컬럼에 “Using filesort"라는 코멘트가 표시된다.
- 정렬 알고리즘을 수행하기위해 메모리 또는 디스크를 사용한다.
ORDER BY 사용법 및 주의사항
- “ORDER BY 2"라고 명시하면 SELECT 되는 컬럼 중에서 2번째 컬럼으로 정렬하라는 의미가 된다.
- 아래의 두 쿼리는 동일한 정렬을 수행한다.


- 다른 DBMS에서 쌍따옴표는 컬럼 식별자를 표현하기 위해 사용되지만 MySQL에서 쌍따옴표는 문자열 리터럴을 표현하는 데 사용된다.
- ORDER BY에 문자열 리터럴이 사용하게 되면 옵티마이저가 ORDER BY를 무시하게 된다.

여러 방향으로 동시 정렬
- MySQL 8.0 버전부터 다음과 같이 오름차순과 내림차순을 혼용해서 인덱스를 생성할 수 있게 되었다.

함수나 표현식을 이용한 정렬
- MySQL 8.0 이전까지는 연산의 결과를 기준으로 정렬하기 위해서 가상 컬럼을 추가하고 인덱스를 생성하는 방법을 사용했다.
- MySQL 8.0 버전부터는 함수 기반의 인덱슬르 지원하기 시작했다.
- 그래서 아래와 같이 연산의 결괏값을 기준으로 정렬하는 작업이 인덱스를 사용하도록 튜닝하는 것이 가능해졌다.

서브쿼리
- MySQL 5.6 버전까지는 서브쿼리를 최적으로 실행하지 못할 때가 많았지만 MySQL 8.0 버전부터는 서브쿼리 처리가 많이 개선됐다.
- 서브쿼리는 SELECT 절, FROM 절, WHERE 절에 사용될 수 있다.
- 하지만 사용되는 위치에 따라 쿼리의 성능 영향도와 MySQL 서버의 최적화 방법이 달라진다.
SELECT 절에 사용된 서브쿼리
- SELECT 절에 사용된 서브 쿼리는 내부적으로 임시 테이블을 만들거나 쿼리를 비효율적으로 실행하게 만들지 않기 때문에 서브쿼리가 적절히 인덱스를 사용할 수 있다면 크게 주의할 사항은 없다.
- 일반적으로 SELECT 절에 서브쿼리를 사용하면 그 서브쿼리는 항상 컬럼과 레코드가 하나인 결과를 반환해야 한다.
- 서브 쿼리로 실행될 때보다 조인으로 처리할 때가 조금 더 빠르게 때문에 가능하다면 조인으로 쿼리를 작성하는 것이 좋다.
- 아래와 같이 SELECT 절에 동일한 서브쿼리가 여러 번 사용 되기도 한다.
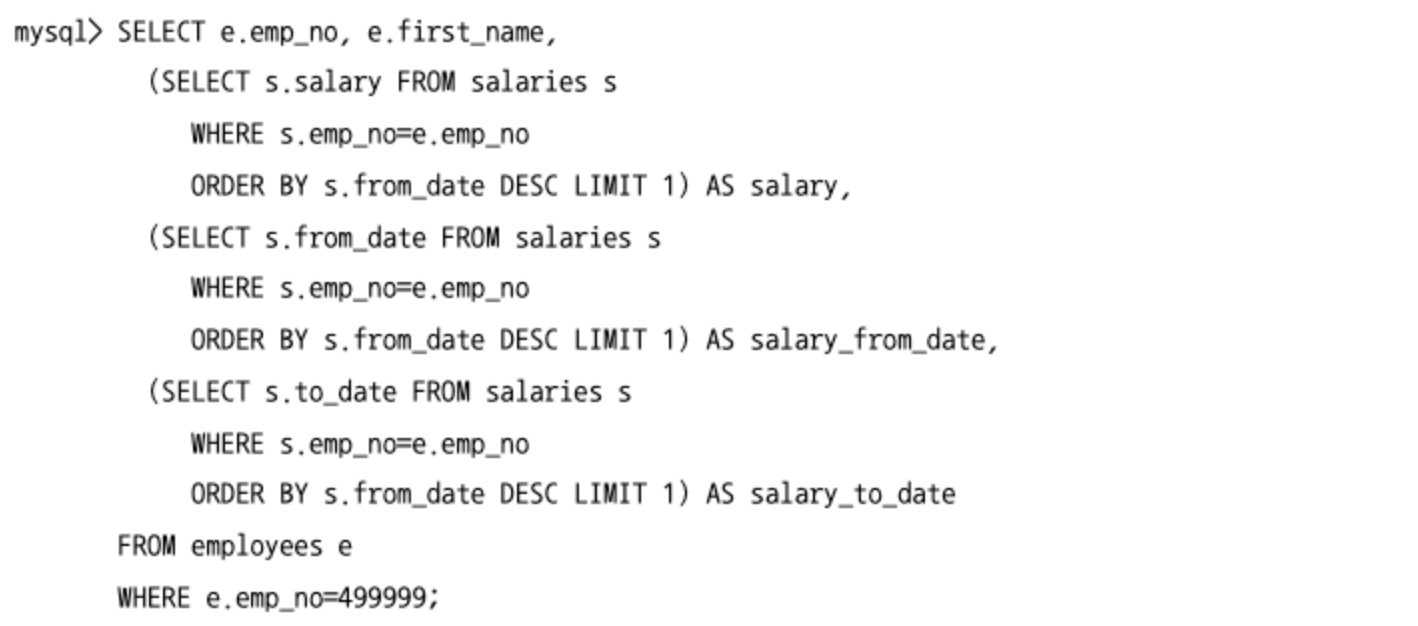
- MySQL 8.0 버전부터 도입된 래터럴 조인을 이용하면 동일한 레코드의 각 컬럼을 가져오기 위해 서브쿼리를 3번씩이나 남용하지 않아도 된다.
- 래터럴 조인을 사용하는 경우에는 임시 테이블을 생성하기 때문에 유의해야 된다.
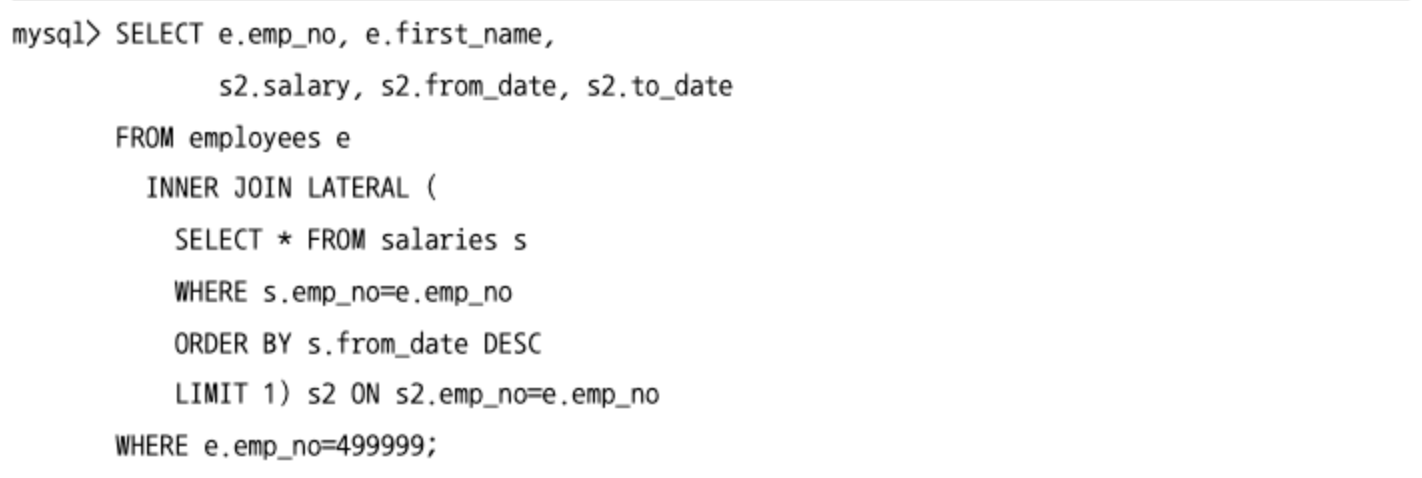
FROM 절에 사용된 서브쿼리
- MySQL 5.7 버전부터는 옵티마이저가 FROM 절의 서브쿼리를 외부 쿼리로 병합하는 최적화를 수행하도록 개선됐다.
EXPLAIN명령을 실행한 후SHOW WARNINGS명령을 실행하면 MySQL 서버가 서브쿼리를 병합해서 재작성한 쿼리의 내용을 확인할 수 있다.- 다음과 같은 기능이 서브쿼리에 사용되면 FROM 절의 서브쿼리는 외부 쿼리로 병합되지 못한다.
- 집합 함수 사용(
SUM(),MIN(),MAX(),COUNT()등) DISTINCTGROUP BY또는HAVINGLIMITUNION(UNION DISTINCT)또는UNION ALLSELECT절에 서브쿼리가 사용된 경우- 사용자 변수 사용(사용자 변수에 값이 할당되는 경우)
- 집합 함수 사용(
- 외부 쿼리되는 병합되는
FROM절의 서브쿼리가ORDER BY절을 가진 경우에는 외부 쿼리가GROUP BY나DISTINCT같은 기능을 사용하지 않는다면 서브쿼리의 정렬 조건을 외부 쿼리로 같이 병합한다. - 외부 쿼리에서
GROUP BY나DISTINCT와 같은 기능이 사용되고 있다면, 서브쿼리의 정렬 작업은 무의미하기 때문에 서브쿼리의ORDER BY절은 무시된다.

WHERE 절에 사용된 서브쿼리
- WHERE 절의 서브쿼리는 SELECT 절이나 FROM 절보다는 다양한 연산자로 사용될 수 있는데, 크게 3가지로 구분할 수 있다.
- 동등 또는 크다 작다 비교(
= (subquery)) - IN 비교(
IN (subquery)) - NOT IN 비교(
NOT IN (subquery))
- 동등 또는 크다 작다 비교(
- 동등 또는 크다 작다 비교

- MySQL 5.5 이전 버전까지는 위 쿼리의 경우
dept_emp테이블을 풀 스캔하면서 서브쿼리의 조건에 일치하는지 여부를 체크했다 - MySQL 5.5 버전부터는 서브 쿼리를 먼저 실행한 후 상수로 변환한다. 그리고 상숫값으로 서브쿼리를 대체해서 나머지 쿼리 부분을 처리한다.
- 단일 값 비교가 아닌 튜플 비교 방식이라면 MySQL 8.0 버전이라고 하더라도 풀 테이블 스캔이 발생하니 주의해서 사용해야 한다.
- IN 비교
- WHERE 절에 사용된
IN (subquery)형태의 조건을 조인의 한 방식인 세미 조인이라고 부른다. 
- MySQL 5.5 버전까지는 세미 조인의 최적화가 매우 부족해서 풀 테이블 스캔을 했다.
- MySQL 5.6 버전부터 8.0 버전까지 세미 조인의 최적화가 많이 개선되었다.
- MySQL 서버의 세미 조인 최적화는 조인 관계에 맞게 5개의 최적화 전략을 선택적으로 사용한다.
- 테이블 풀-아웃(Table Pull-out)
- 퍼스트 매치(Firstmatch)
- 루스 스캔(Loosescan)
- 구체화(Materialization)
- 중복 제거(Duplicated Weed-out)
- WHERE 절에 사용된
- NOT IN 비교
- 안티 세미 조인이라고도 부른다.
- MySQL 옵티마이저는 안티 세미 조인 쿼리가 사용되면 다음 두 가지 방법으로 최적화를 수행한다.
NOT EXISTS- 구체화(Materialization)
- 두 가지 최적화 모두 그다지 성능 향상에 도움이 되지 않기 때문에, 최대한 다른 조건을 활용해서 데이터 검색 범위를 좁힐 수 있게 하는 것이 좋다.
- WHERE 절에 단독으로 안티 세미 조인 조건만 있다면 풀 테이플 스캔을 피할 수 없으니 주의하자.
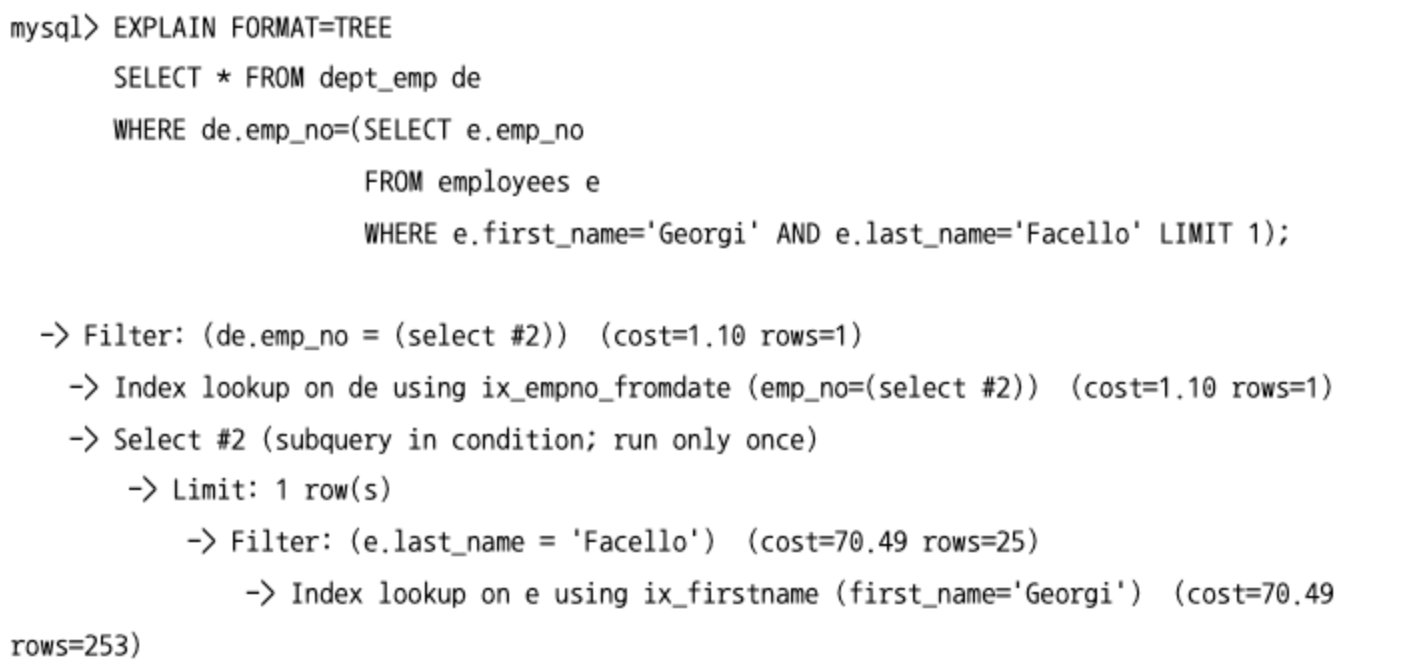
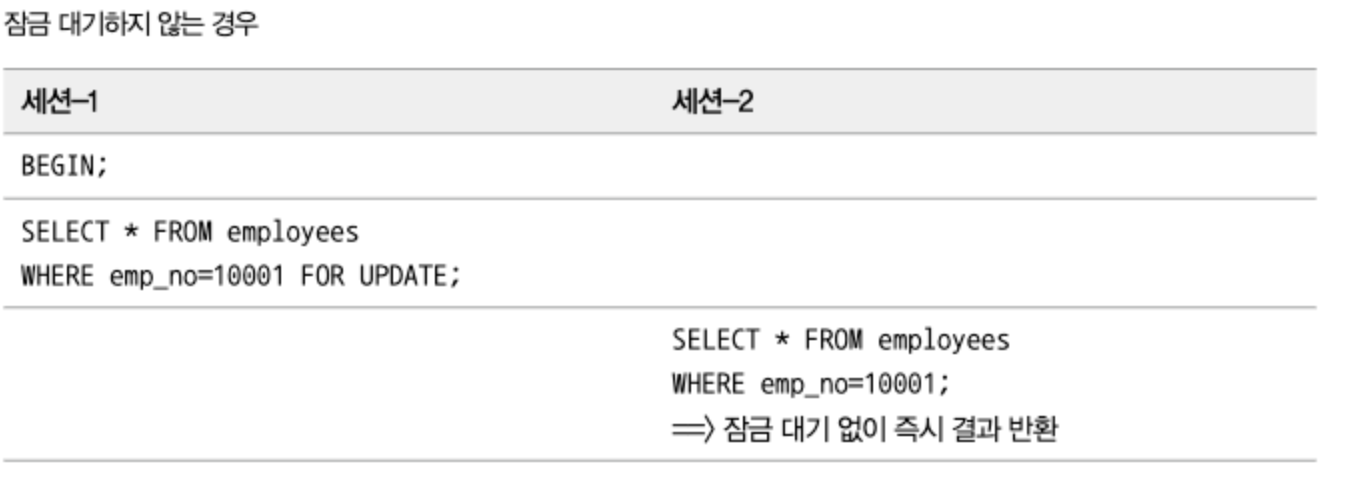
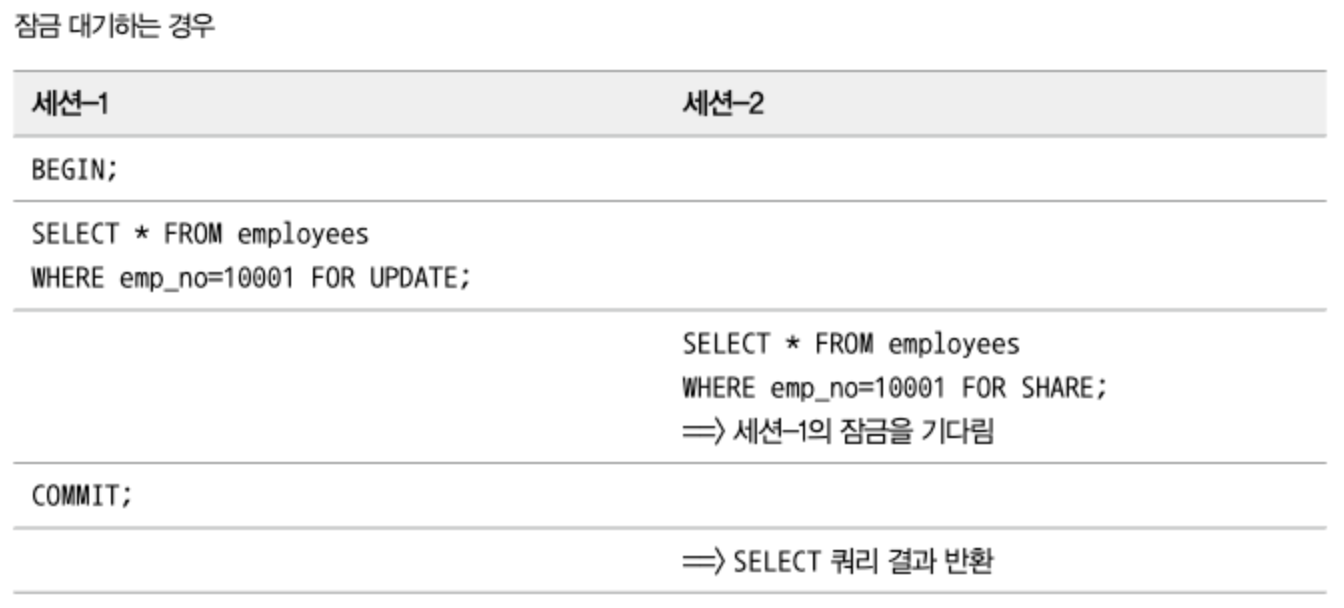
잠금을 사용하는 SELECT
- 레코드를 읽으면서 강제로 잠금을 걸어두는 옵션으로
FOR SHARE와FOR UPDATE절이 있다. - 두 가지 잠금 옵션은 모두 자동 커밋이 비활성화된 상태 또는
BEGIN명령이나START TRANSACTION명령으로 트랜잭션이 시작된 상태에서만 잠금이 유지된다.FOR SHARE: SELECT된 레코드에 대해 읽기 잠금을 설정하고 다른 세션에서 해당 레코드를 변경하지 못하게 한다. 물론 다른 세션에서 잠금이 걸린 레코드를 읽는 것은 가능하다.FOR UPDATE: 쓰기 잠금을 설정하고, 다른 트랜잭션에서는 그 레코드르 변경하는 것뿐만 아니라 읽기도 수행할 수 없다.
- 주의점:
FOR SHARE나FOR UPDATE절을 가지지 않는 SELECT는SELECT ... FOR UPDATE쿼리에 의해 잠겨진 상태라 하더라도 아무런 대기 없이 실행된다.

잠금 테이블 선택
- 조인을 한 경우 특정 테이블만 잠금을 획득하고 싶다면
FOR UPDATE뒤에 “OF 테이블” 절을 추가하면 된다.- MySQL 8.0 이전에는 불가능하다.

NOWAIT & SKIP LOCKED
- 지금까지의 MySQL 잠금은 누군가가 레코드를 잠그고 잇다면 다른 트랜잭션은 그 잠금이 해제될 때까지 기다려야 헀다.
NOWAIT옵션을 사용하면 해당 레코드가 다른 트랜잭션에 의해 잠겨진 상태인 경우, 에러를 반환하면서 즉시 종료된다.SKIP LOCKED옵션은 SELECT 하려는 레코드가 다른 트랜잭션에 의해 이미 잠겨진 상태라면 에러를 반환하지 않고 잠긴 레코드는 무시하고 잠금이 걸리지 않은 레코드만 가져온다.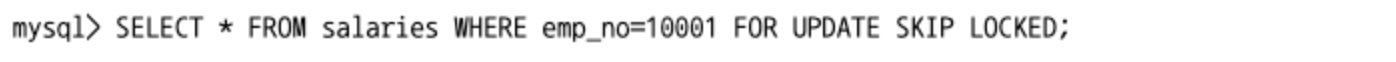
SKIP LOCKED절을 가진 SELECT 구문은 확정적이지 않은 쿼리가 되니 유의해야된다.

INSERT
- INSERT 문장이 동시에 실행되는 경우 INSERT 문장 자체보다는 테이블의 구조가 성능에 더 큰 영향을 미친다.
- 하지만 많은 경우 INSERT의 성능과 SELECT의 성능을 동시에 빠르게 만들 수 있는 테이블 구조가 없어서 어느 정도 타협하면서 테이블 구조를 설계해야 한다.
고급 옵션
INSERT IGNORE
- INSERT 문장의 IGNORE 옵션은 저장하는 레코드의 프라이머리 키나 유니크 인덱스 컬럼의 값이 이미 테이블에 존재하는 레코드와 중복되는 경우 무시하도록 해준다.
- 또한, 데이터 타입이 일치하지 않아서 INSERT를 할 수 없는 경우에 컬럼의 기본 값으로 INSERT를 하도록 만들기도 한다.

INSERT … ON DUPLICATE KEY UPDATE
- 프라이머리 키나 유니크 인덱스의 중복이 발생하면 UPDATE 문장의 역할을 수행하게 해준다.
- GROUP BY 결과인 COUNT(*)를
ON DUPLICATE KEY UPDATE에 사용하고 싶다면VALUES()함수를 사용하면 된다.VALUES()함수는 컬럼명을 인자로 사용하는데,VALUES(stat_value)라고 사용하면 MySQL 서버는 인자로 주어진stat_value에 INSERT 하려고 했던 값을 반환한다.- MySQL 8.0.20 이후 버전에서는
VALUES()함수가 Deprecated 되므로 다음과 같은 문법으로 별칭을 사용해서 사용할 것을 권장한다. 
LOAD DATA 명령 주의 사항
- RDBMS에서 데이터를 빠르게 적제할 수 있는 방법으로
LOAD DATA명령이 자주 소개된다. - MySQL에서
LOAD DATA는 MySQL 엔진과 스토리지 엔진이 호출 횟수를 최소화하고 스토리지 엔진이 직접 데이터를 적재하기 때문에 일반적인 INSERT 명령과 비교했을 때 매우 빠르다고 할 수 있다. - 하지만 MySQL 서버의
LOAD DATA명령은 다음과 같은 단점이 있다.- 단일 스테드로 실행
- 단일 트랜잭션으로 실행
- 단일 스레드, 단일 트랜잭션으로 실행되기 때문에 데이터 파일이 매우 크다면 언두 로글르 삭제하지 못해 부하가되고, 언두 로그가 많이 쌓이면 레코드를 읽는 쿼리들이 필요한 레코드를 찾는 데 더 많은 오버헤드를 만들어 내기도 한다.
- 가능하다면 여러 개의 파일로 준비해서
LOAD DATA문장을 동시에 여러 트랜잭션으로 나뉘어 실행되게 하는 것이 좋다. - 또한, 테이블 간 데이터 복사 작업은
LOAD DATA문자옵다는INSERT ... SELECT ...문장으로 데이터를 부분적으로 잘라서 INSERT 할 수 있게 해주는 것이 좋다.
성능을 위한 테이블 구조
대량 INSERT 성능
- 하나의 INSERT 문장으로 수백 건, 수천 건 레코드를 INSERT 한다면 INSERT될 레코드들을 프라이머리 키 값 기준으로 미리 정렬해서 INSERT 문장을 구성하는 것이 성능에 도움이 될 수 있다.
- 정렬되지 않은 경우: InnoDB 스토리지 엔진이 레코드를 저장할 때마다 프라이머리 키의 B-Tree에서 랜덤한 위치의 페이지를 메모리로 읽어와야 하기 때문에 처리가 더 느리다.
- 정렬된 경우: 다음에 INSERT할 레코드의 프라이머리 키값이 직전에 INSERT된 값보다 항상 크기 때문에 메모리에는 프라이머리 키의 마지막 페이지만 적제돼 있으면 새로운 페이지를 메모리로 가져오지 않아도 레코드를 저장할 위치를 찾을 수 있다.
- INSERT 발생 시 세컨더리 인덱스의 변경을 위해서 일시적으로 체인지 버퍼에 버퍼링됐다가 백그라운드 스레드에 의해 일괄 처리될 수 있다.
- 세컨더리 인덱스가 많으면 INSERT 시 백그라운드 작업의 부하를 유발하므로, 세컨더리 인덱스를 너무 남용하는 것은 성능상 좋지 않다.
프라이머리 키 선정
- 프라이머리 키는 INSERT 성능을 결정하는 가장 중요한 부분이다.
- 테이블에 INSERT 되는 레코드가 프라이머리 키의 전체 범위에 대해 프라이머리 키 순서와 무관하게 아주 랜덤하게 저장된다면 MySQL 서버는 레코드를 INSERT 할 때마다 저장될 위치를 찾아야 한다.
- 프라이머리 키 선정은 INSERT 성능과 SELECT 성능의 대립되는 두 가지 요소 중에 하나를 선택해야 한다.
- SELECT는 거의 실행되지 않고 INSERT가 매우 많이 실행되는 테이블(로그성 데이터)이라면 프라이머리 키를 단조 증가 또는 단조 감소하는 패턴의 값을 선택하는 것이 좋다.
- 쓰기에 비해 읽기 비율이 압도적으로 높은 테이블에 대해서는 INSERT보다는 SELECT 쿼리를 빠르게 하는 방항으로, 빈번하게 실행되는 SELECT 쿼리 조건을 기준으로 프라이머리 키를 선택하는 것이 좋다.
- 또한 SELECT는 많지 않고 INSERT가 많은 테이블에 대해서는 인덱스의 개수를 최소화하는 것이 좋다.
Auto-Increment 컬럼
- SELECT보다는 INSERT에 최적화된 테이블을 생성하기 위해서는 다음 두 가지 요소를 갖춰 테이블을 준비하면 된다.
- 단조 증가 또는 단조 감소되는 값으로 프라이머리 키 선정
- 세컨더리 인덱스 최소화
- 자동 증가 값을 프라이머리 키로 해서 테이블을 생성하는 것은 MySQL 서버에서 가장 빠른 INSERT를 보장하는 방법이다.
- InnoDB 스토리지 엔진의 잠금 에서 자동 증가 락을 다룬 적이 있다.
UPDATE 와 DELETE
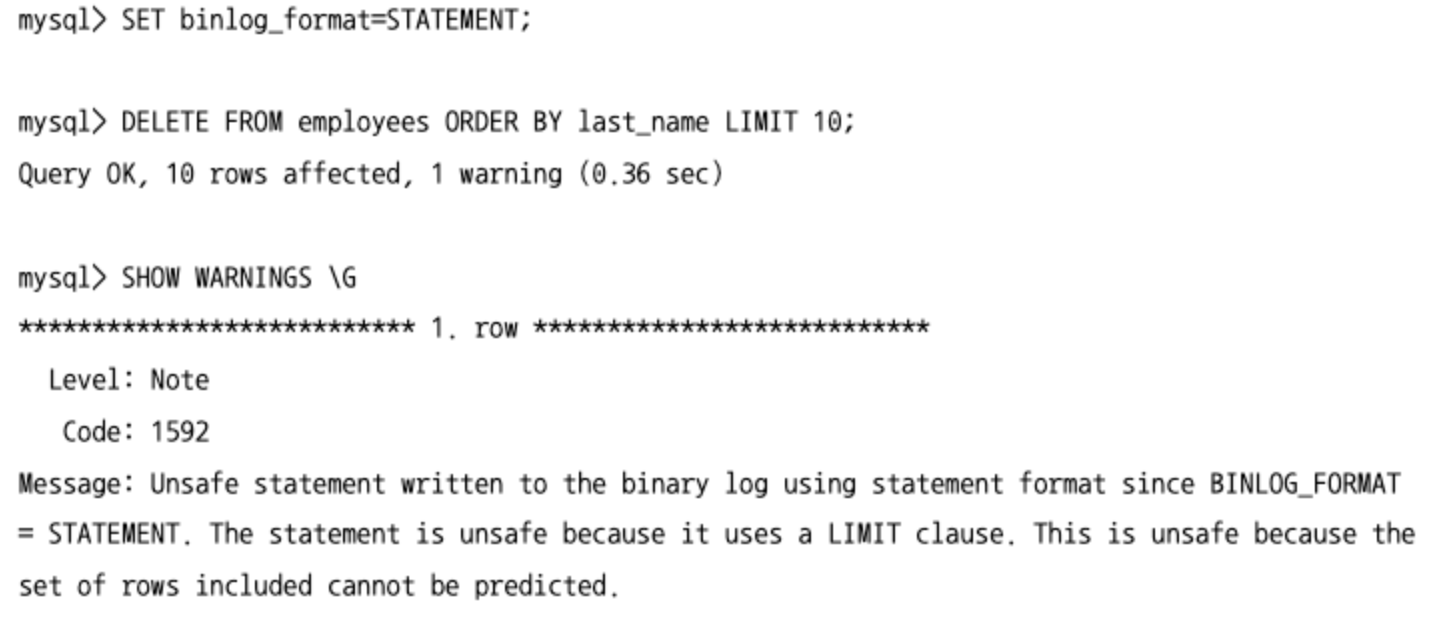
UPDATE … ORDER BY … LIMIT n
- UPDATE나 DELETE 문장에 ORDER BY 절과 LIMIT 절을 동시에 사용해 특정 컬럼으로 정렬해서 상위 몇 건만 변경 및 삭제하는 것이 가능하다.
- 하지만 STATEMENT 기반의 복제에서 소스 서버에서
ORDER BY ... LIMIT이 포함된 UPDATE나 DELETE 문장을 실행하면 레플리카 서버에서 달라질 수 있기 때문에 경고 메시지가 발생한다.
JOIN UPDATE
- 두 개 이상의 테이블을 조인해 조인될 결과 레코드를 변경 및 삭제하는 쿼리를 JOIN UPDATE라고 한다.
- JOIN UPDATE는 조인되는 모든 테이블에 대해 읽기 참조만 되는 테이블은 읽기 잠금이 걸리고, 컬럼이 변경되는 테이블은 쓰기 잠금이 걸린다. 그래서 JOIN UPDATE 문장이 웹 서비스 같은 OLTP 환경에서 데드락을 유발할 가능성이 높으므로 빈번하게 사용하는 것은 피하는 것이 좋다.

- JOIN UPDATE에서는 GROUP BY나 OERDER BY 절을 상요할 수 없기 때문에 서브쿼리를 이용해 작성해야 한다.
- 임시 테이블을 드라이빙 테이블이 되도록 옵티마이저에 알려주고 싶다면,
STARIGHT JOIN키워드를 사용하거나JOIN_ORDER옵티마이저 힌트를 사용할 수 있다.- 일반적으로 임시 테이블이 드라이빙 테이블이 되는 것이 빠른 성능을 보여준다.
STRAIGHT_JOIN은 INNER JOIN과 다르게 조인 순서도 결정한다.

여러 레코드 UPDATE
- MySQL 8.0 이전에는 하나의 UPDATE 문장으로 여러 개의 레코드를 업데이트하는 경우 다음 예제와 같이 모든 레코드를 동일한 값으로만 업데이트할 수 있었다.
- MySQL 8.0 부터는 레코드 생성 문법을 이용해 레코드별로 서로 다른 값을 업데이트할 수 있게 됐다.
VALUES ROW(...), ROW(...), ...문법을 사용하면 SQL 문장 내에서 임시 테이블을 생성하는 효과를 낼 수 있다.- 아래 예제는 2건의 레코드를 가지는 임시 테이블 “new_user_level"을 생성하고, new_user_level 임시 테이블과 user_level 테이블을 조인해서 업데이트를 수행하는 JOIN UPDATE 문장의 효과를 낼 수 있다.


JOIN DELETE
- JOIN DELETE는
DELETE와FROM절 사이에 삭제할 테이블을 명시해야 한다. - 아래 예시는 조인이 성공한 레코드에 대해
employees테이블 레코드만 삭제하는 쿼리다. - JOIN DELETE 문장으로 여러 개의 테이블을 동시에 삭제할 수도 있다.


스키마 조작(DDL)
테이블 변경
테이블 생성
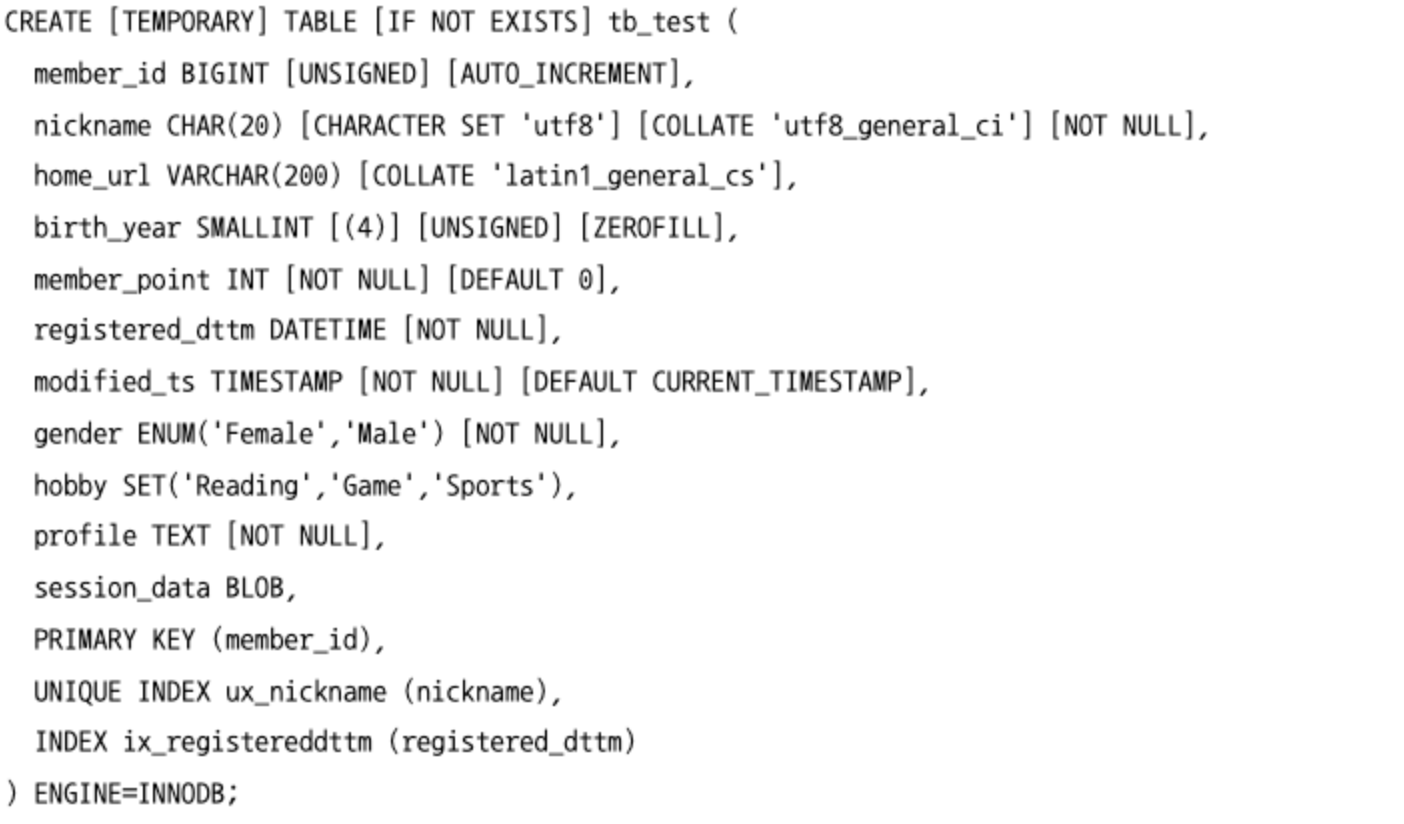
TEMPORARY: 해당 데이터베이스 커넥션에서만 사용 가능한 임시 테이블을 생성한다.IF NOT EXISTS: 같은 이름을 가진 테이블이 있으면 무시한다.ENGINE=INNODB: 테이블이 사용할 스토리지 엔진을 설정한다. MySQL 8.0 이후로는 따로 정의하지않으면 InnoDB 스토리지 엔진이 기본으로 사용한다.- 모든 컬럼은 공통적으로 컬럼의 초기값을 설정하는
DEFAULT절과 NULL을 가질 수 있는지 여부를 설정하기 위해NULL또는NOT NULL제약을 명시할 수 있다. - 문자열 타입 뒤에는 반드시 컬럼에 최대한 저장할 수 잇는 문자 수를 명시해야 한다.
CHARACTER SET: 저장되는 문자열 값이 어떤 문자 집합을 사용할지 결정COLLATE: 문자열 비교나 정렬 규칙을 나타내기 위한 콜레이션
- 숫자 타입은 선택적으로 길이를 가질 수 있지만, 이는 실제 컬럼에 저장될 값의 길이를 의미하는 것이 아니라 단순히 값을 표시할 때 보여줄 길이를 지정하는 것이다.
UNSIGNED: 양수만 가진다는 의미SIGNED: 음수와 양수 모두 저장할 수 있고, 기본 값이다.ZEROFILL: 숫자 값의 왼쪽에 0을 패딩할지 결정하는 옵션
- MySQL 5.5 버전까지는
DATE나DATETIME타입은 기본 값을 명시할 수 없었지만, MySQL 5.6 버전부터는DATE와DATETIME타입 그리고 TIMESTAMP 타입 모두 값이 자동으로 현재 시간으로 업데이트되도록 기본 값을 명시할 수 있다. ENUM또는SET타입은 타입의 이름 뒤에 해당 컬럼이 가질 수 있는 값을 괄호로 정의해야 한다.
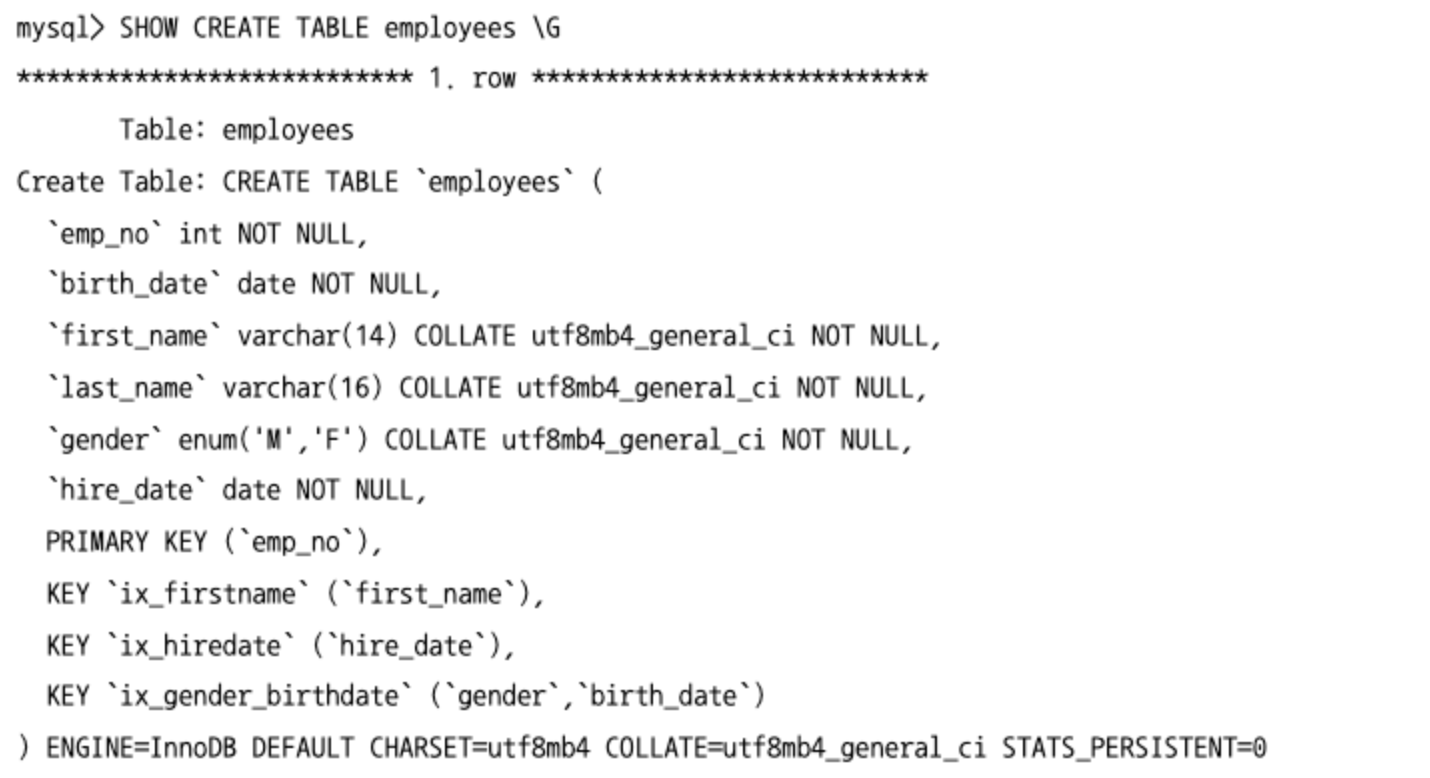
테이블 구조 조회
SHOW CREATE TABLE: 테이블의CREATE TABLE문장을 표시해준다.DESC: 테이블의 컬럼 정보를 보기 편한 표 형태로 표시해준다.- 하지만 인덱스 컬럼의 순서나 외래키, 테이블 자체의 속성을 보여주지 않으므로 테이블의 전체 구조를 한 번에 확인하기는 어렵다.

테이블 구조 변경
ALTER TABLE명령은 테이블 자체의 속석을 변경할 수 있을뿐만 아니라 인덱스의 추가 삭제나 컬럼을 추가/삭제하는 용도로도 사용된다.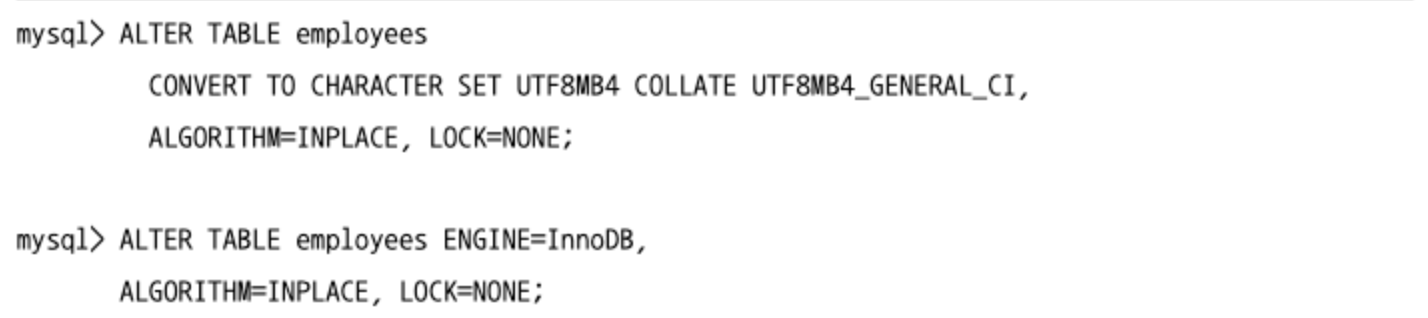
- 첫번째 쿼리는 테이블의 기본 문자 집합과 콜레이션을 변경하는 명령이다.
- 두 번째 쿼리는 테이블의 스토리지 엔진을 변경하는 명령이다.
- 내부적인 테이블의 저장소를 변경하는 것이라서 항상 테이블의 모든 레코드를 복사하는 작업이 필요하므로 주의해야 한다.
- 이 명령은 실제 테이블의 스토리지 엔진을 변경하는 목적으로도 사용하지만 테이블 데이터를 리빌드하는 목적으로도 사용한다.
- 테이블 리빌드 작업: 레코드의 삭제가 자주 발생하는 테이블에서 데이터가 저장되지 않는 빈 공간(프래그멘테이션, fragmentation)을 제거해 디스크 사용 공간을 줄이는 작업
테이블 명 변경

- 첫 번째 명령은 동일 데이터베이스 내 테이블의 이름만 변경하는 단순히 메타 정보 변경이기 때문에 매우 빠르게 처리된다.
- 두 번째 명령은 메타 정보뿐만 아니라 테이블이 저장된 파일까지 다른 디렉터리로 이동한다.
- 테이블의 이름을 서로 교체할 때 아래와 같이 한다면
batch테이블이 없어지는 시점이 발생한다. - 아래와 같이
RENAME명령을 하나의 문장으로 묶으면 MySQL 서버는 명시된 모든 테이블에 대해 잠금을 걸고 테이블의 이름 변경 작업을 실행하게 된다.- 애플리케이션 입장에서는 잠금이 걸려 잠깐 대기가 발생하고, 테이블이 존재하지 않는다는 에러는 방지할 수 있다.


테이블 상태 조회
SHOW TABLE STATUS와LIKE패턴을 사용해서 특정 테이블의 만들어진 시각, 대략적인 레코드 건수, 데이터 파일의 크기 등의 정보를 확인할 수 있다.- 레코드 건수나 레코드 평균 크기는 MySQL 서버가 예측하고 있는 값이기 때문에 테이블이 너무 작거나 너무 크면 오차가 더 커질 수도 있다.
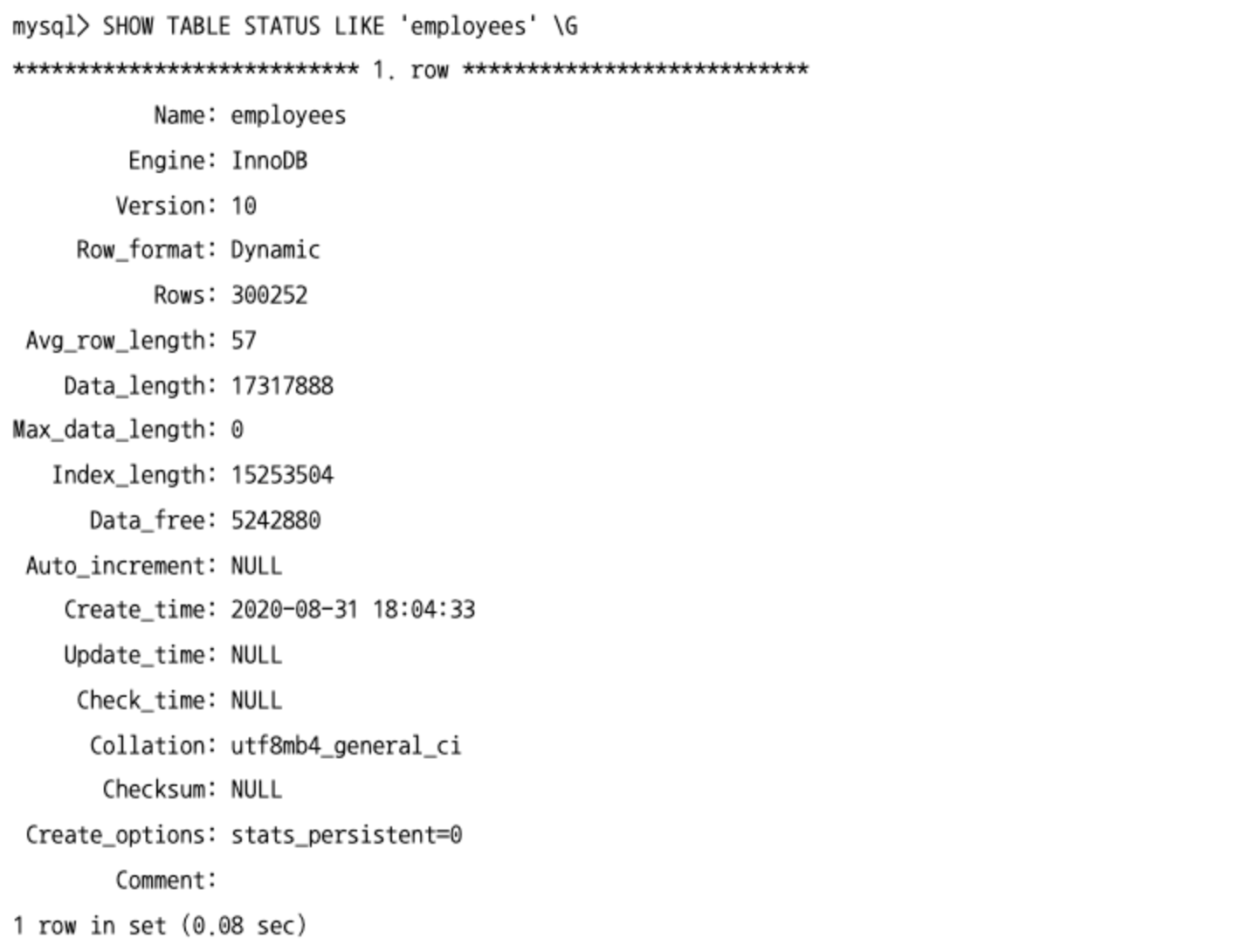
information_schema데이터베이스에서는 MySQL 서버가 가진 스키마들에 대한 메타 정보를 가진 딕셔녀리 테이블을 관리한다.

테이블 구조 복사
CREATE TABLE ... LIKE을 사용하면 컬럼과 인덱스가 같은 테이블을 생성할 수 있다.CREATE TABLE temp_employees LIKE employees
- 데이터까지 복사하려면
INSERT ... SELECT명령을 실행하면 된다.INSERT INTO temp_employees SELECT * FROM employees
테이블 삭제
DROP TABLE [ IF EXISTS ] table1- MySQL 8.0 버전에서는 특정 테이블을 삭제하는 작업이 다른 테이블의 DML이나 쿼리를 직접 방해하지 않는다.
- 하지만 용량이 큰 테이블을 살제하는 작업은 상당히 부하가 큰 작업에 속한다.
- 삭제하려는 테이블이 사용하던 데이터 파일을 삭제해야 하는데, 이 파일이 매우 크고 디스크에서 파일의 조각이 너무 분산되어 저장돼 있다면 많은 디스크 읽기/쓰기 작업이 필요하다.
- 디스크 읽기/쓰기 부하가 높아지면 다른 커넥션의 쿼리 처리 성능에 간접적으로 영향을 미칠 수 있다.
- 또한, 어댑티브 해시 인덱스가 활성화돼 있는 경우 테이블이 삭제되면 어댑티브 해시 인덱스 삭제 작업으로 인해 다른 쿼리에 간접적으로 영향을 줄 수 있다.
- 어댑티브 해시 인덱스: InnoDB 버퍼 풀의 각 페이지가 가진 레코드에 대한 해시 인덱스 기능으로 자주 사용되는 테이블에 대핵서만 해시 인덱스가 빌드된다.
컬럼 변경
컬럼 추가

테이블의 마지막에 새로운 컬럼을 추가할 때는 INSTANT 알고리즘으로 처리되기 때문에 즉시 추가가 가능하다.
테이블의 기존 컬럼 중간에 컬럼을 새로 추가하는 경우는 테이블의 리빌드가 필요하다. 그래서 INPLACE 알고리즘으로 처리돼야 한다.
스키마 변경 알고리즘
- INSTANT: 테이블의 데이터는 전혀 변경하지 않고, 메타데이터만 변경하고 작업을 완료함. 테이블이 가진 레코드 건수와 무관하게 작업 시간은 매우 짧음. 스키마 변경 도중 테이블의 읽고 쓰기는 대기하게 되지만 스키마 변경 시간이 매우 짧기 때문에 다른 커넥션의 쿼리 처리에는 크게 영향을 미치지 않음.
- INPLACE: 임시 테이블로 데이터를 복사하지 않고 스키마 변경을 실행. 하지만 내부적으로는 테이블의 리빌드를 실행할 수도 있음. 레코드의 복사 작업은 없지만 테이블의 모든 레코드를 리빌드해야 하기 때문에 테이블의 크기에 따라 많은 시간이 소요될 수 있음. 하지만 스키마 변경 중에도 테이블의 읽기와 쓰기 모두 가능. INPLACE 알고리즘으로 스키마가 변경되는 경우에도 최초 시작 시점과 마지막 종료 시점에는 테이블의 읽고 쓰기가 불가함. 하지만 이 시간은 매우 짧기 때문에 다른 커넥션의 쿼리 처리에 대한 영향도는 높지 않음.
- COPY: 변경된 스키마를 적용한 임시 테이블을 생성하고, 테이블의 레코드를 모두 임시 테이블로 복사한 후 최종적으로 임시 테이블을 RENAME해서 스키마 변경을 완료. 이 방법은 테이블 읽기만 가능하고 DML은 실행할 수 없음.
컬럼 삭제
- 컬럼을 삭제하는 작업은 항상 테이블의 리빌드가 필요하기 때문에 INSTANT 알고리즘을 사용할 수 없고 항상 INPLACE 알고리즘으로만 컬럼 삭제가 가능하다.

컬럼 이름 및 컬럼 타입 변경

- 컬럼의 이름 변경: 실제 데이터 리빌드 작업이 필요하지 않다.
- INT 컬럼을 VARCHAR 타입으로 변경: 데이터 타입이 변경되는 경우 COPY 알고리즘이 필요하다.
- VARCHAR 타입의 길이 확장:
- VARCHAR나 VARBINARY 타입의 실제 컬럼이 가지는 값의 길이는 레코드의 컬럼 헤더에 저장된다.
- 컬럼값의 길이 저장용 공간은 컬럼의 값이 최대 가질 수 있는 바이트 수가 255 이하인 경우 1바이트만 사용하며, 256 이상인 경우 2바이트를 사용한다.
- INPLACAE 알고리즘으로 VARCHAR(10)에서 VARCHAR(20)으로 변경하는 경우라면 둘다 255바이트 이하이므로 테이블 리빌드가 필요없다.
- 하지만 UTF8MB4 문자 셋을 사용할 경우 VARCHAR(10)에서 VHARCHAR(64)로 변경하는 경우 한 글자가 최대 4바이트를 사용할 수 있기 때문에 최대 256 바이트를 사용할 수 있어서, 리빌드를 해야된다.
- VARCHAR 타입의 길이 축소: COPY 알고리즘을 사용해야 한다. 스키마를 변경하는 중에 해당 테이블의 데이터 변경은 허용하지 않으므로 LOCK은 SHARED로 사용돼야 한다.
인덱스 변경
인덱스 추가
- 전문 검색 인덱스와 공간 검색 인덱스를 제외하면 나머지는 B-Tree 자료 구조를 사용한다.
- B-Tree 자료 구조를 사용하는 인덱스의 추가는 프라이머리 키라고 하더라도 INPLACE 알고리즘나 잠금 없이 인덱스 생성이 가능하다.
인덱스 조회
- 인덱스의 목록 조회는
SHOW INDEXES명령을 사용하거나SHOW CREATE TABLE명령으로 표시되는 테이블 생성 명령을 참조하면 된다. 
SHOW INDEXES명령은 테이블이ㅡ 인덱스만 표시하는데, 인덱스 컬럼별로 한 줄씩 표시해준다.Key_name: 인덱스의 이름Seq_in_index: 인덱스에서 해당 컬럼의 위치Cardinality: 인덱스에서 해당 컬럼까지 유니크한 값의 개수
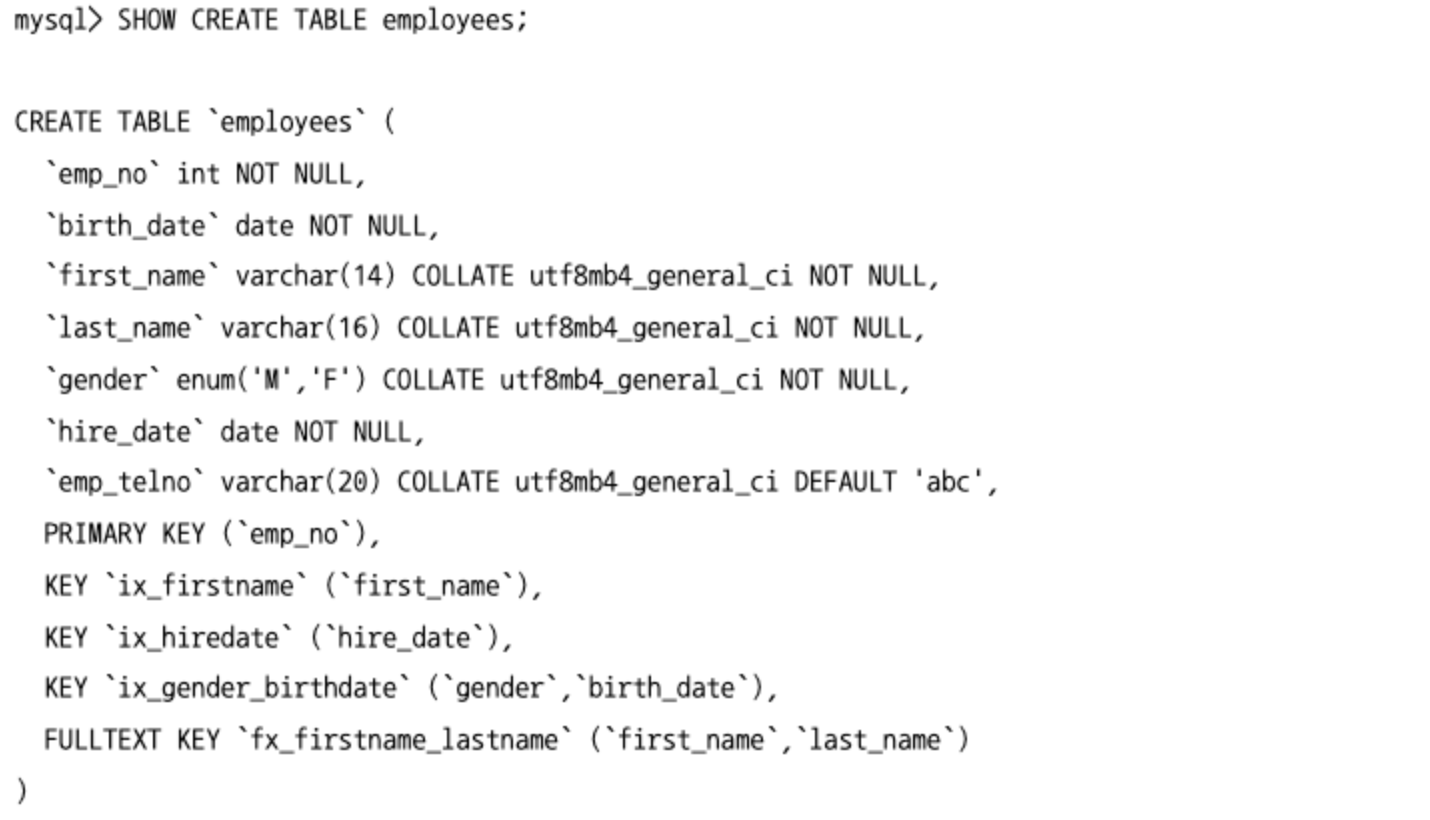
SHOW CREATE TABLE명령은 테이블의 생성 구문을 그대로 보여준다.- 인덱스와 함께 테이블의 모든 컬럼까지 표시하기 때문에 장황해 보일 수 있지만, 인덱스별로 한 줄로 표시하기 때문에 인덱스에 어떤 컬럼이 어떤 순서로 구성돼 있는지 파악하기 쉽다.
인덱스 이름 변경
- MySQL 5.6 버전까지는 인덱스의 이름을 변경할 수 있는 방법이 없다.
- 아래는
employees테이블이 이미 가지고 있던 “ix_firstname(first_name)“를 대신해서 “ix_firstname (first_name, last_name)” 인덱스를 교체하는 작업 방식을 보여준다. 
인덱스 가시성 변경
- MySQL 8.0 버전부터 인덱스의 가시성을 제어할 수 있는 기능이 도입됐다
- 인덱스를 삭제했을 때 어떻게 동작할 지, 인덱스 삭제 없이 확인해볼 수 있다.
- 인덱스를 삭제했다가 다시 생성한다면 매우 많은 시간이 걸릴 수도 있다.
- 옵티마이저는 INVISIBLE 상태의 인덱스는 없는 것으로 간주하고 실행 계획을 수립한다.
ALTER TABLE employees ALTER INDEX ix_firstname INVISIBLE
- 인덱스를 다시 사용할 수 있게 하려면 VISIBLE 옵션을 명시하면 된다.
ALTER TABLE employees ALTER INDEX ix_firstname VISIBLE
- 인덱스를 최초 생성할 때도 가시성을 설정할 수 있다.

인덱스 삭제
- 세컨더리 인덱스 삭제 작업은 INPLACE 알고리즘을 사용하지만 실제 테이블 리빌드를 필요하지는 않는다.
- 프라이머리 키의 삭제 작업은 모든 세컨더리 인덱스의 리프 노드에 저장된 프라이머리 키 값을 삭제해야 하기 때문에 임시 테이블로 레코드를 복사해서 테이블을 재구축해야 한다.
- COPY 알고리즘을 사용하며, SHARED 모드의 잠금이 필요하다.

쿼리 성능 테스트
- 쿼리의 성능을 판단해보기 위해서는 어떠한 부분을 고려해야 하고, 어떤 영향 요소가 있는지 살펴본다.
쿼리의 성능에 영향을 미치는 요소
운영체제의 캐시
- MySQL 서버는 운영체제의 파일 시스템 관련 기능을 이용해 데이터 파일을 읽어온다.
- 그런데 일반적으로 운영체제는 한 번 읽은 데이터는 운영체제가 관리하는 별도의 캐시 영역에 보관해 뒀다가 다시 해당 데이터가 요청되면 디스크를 읽지 않고 캐시의 내용을 바로 MySQL 서버로 반환한다.
- InnoDB 스토리지 엔진은 일반적으로 파일 시스템의 캐시나 버퍼를 거치지 않는 Direct I/O를 사용하므로 운영체제의 캐시가 그다지 큰 영향을 미치지 않는다.
- 하지만 MyISAM 스토리지 안젠은 운영체제의 캐시에 대한 의존도가 높기 때문에 운영체제의 캐시에 따라 성능의 차이가 큰편이다.
- 운영체제가 가지고 있는 캐시나 버퍼가 전혀 없는 상태에서 쿼리의 성능을 테스트하려면 아래와 같은 방법을 사용할 수 있다.(Linux 기준)

MySQL 서버의 버퍼 풀(InnoDB 버퍼 풀과 MyISAM 키 캐시)
- 운영체제의 버퍼나 캐시와 마찬가지로 MySQL 서버에서도 데이터 파일의 내용을 페이지 단위로 캐시하는 기능을 제공한다.
- InnoDB 스토리지 엔진이 관리하는 캐시를 버퍼 풀이라고 하며, 인덱스 페이지와 데이터 페이지를 캐시한다.
- 쓰기 작업을 위한 버퍼링 작업까지 버퍼 풀에서 처리한다.
- MyISAM 스토리지 엔진이 관리하는 캐시는 키 캐시라고 하며, 인덱스 데이터에 대해서만 캐시 기능을 제공한다.
- InnoDB 버퍼 풀과 MyISAM 키 캐시의 내용을 강제로 퍼지(Purge, 삭제)할 수 있는 방법은 없다.
- 특히 InnoDB의 버퍼 풀은 MySQL 서버가 종료될 때 자동으로 덤프됐다가 다시 시작될 때 자동으로 적재된다.
- InnoDB의 버퍼 풀이 자동으로 덤프되고 적재되지 않게
innodb_buffer_pool_load_at_startup과innodb_buffer_pool_dump_at_shutdown시스템 변수를 OFF로 변경하고 다시 시작하면 된다. 
독립된 MySQL 서버
- MySQL 서버가 기동 중인 장비에 웹 서버나 다른 배치용 프로그램이 실행되고 있다면 테스트하려는 쿼리의 성능이 영향을 받게 될 것이다.
쿼리 테스트 횟수
- 실제 쿼리의 성능 테스트를 MySQL 서버의 상태가 워밍업된 상태(캐시나 버퍼가 필요한 데이터로 준비된 상태)에서 진행할지 아니면 콜드 상태(캐시나 버퍼가 모두 초기화된 상태)에서 진행할지도 고려해야 한다.
- 일반적으로 쿼리의 성능 테스트는 콜드 상태에서 워밍업 상태로 전환하는데 그다지 오래 걸리지 않기 때문에, 워밍업 상태를 가정하고 테스트하는 편이다.
- 운영체제의 캐시나 MySQL의 버퍼 풀, 키 캐시는 그 크기가 제한적이라서 쿼리에서 필요로 하는 데이터나 인덱스 페이지보다 크기가 작으면 플러시 작업과 캐시 작업이 반복해서 발생하므로 쿼리를 한 번 실행해서 나온 결괄르 그대로 신뢰해서는 안된다.
- 테스트하려는 쿼리를 번갈아 가면서 6~7번 정도 실행한 후, 처음 한두 번의 결과를 버리고 나머지 결과의 평균값을 기준으로 비교하는 것이 좋다.