지표 기초#
- 자바 애플리케이션 모니터링의 기본적인 사항들과 모니터링, 경보 설정의 모범사례를 살펴보도록 하자.
지표는 어디에 있는가?#
- 모든 지표의 출처가 카프카인 것은 아니다.
- 지푯값은 출처에 따라 다섯 종류로 나눌 수 있다.
- 애플리케이션 지표: 카프카 그 자체의 JMX 인터페이스에서 나온 지표
- 로그: 카프카 자체에서 나온 또 다른 타입의 모니터링 데이터. 숫자가 아니라 텍스트 내지 구조화된 데이터이기 때문에 추가 처리를 좀 더 해야 한다.
- 인프라스크럭처 지표: 카프카의 앞단, 요청이 들어오는 길목에 설치되어 있으며 내가 제어할 수 있는 시스템에서 발생하는 지표(예: 로드 밸런서)
- 특수 클라이언트 지표: 카프카 외부의 툴에서 나온 데이터.일단은 클라이언트 지표지만, 직접적으로 제어가 가능한 것으로서 아래의 일반적인 카프카 클라이언트와는 조금 다르게 작동한다. 카프카 모니터와 같은 외부 모니터링 툴이 여기에 들어간다.
- 일반 클라이언트 지표: 카프카 클러스터에 접속한 클라이언트로부터 나온 지표
어떤 지표가 필요한가?#
경보냐 디버깅이냐?#
- 경보를 보내기 위한 지표
- 짧은 시간 간격인 지표일 때 유용하다.
- 이러한 지표는 문제에 대응하는 자동화 시스템이 사용할 수도 있고, 아직 자동화 시스템이 구축되지 않은 경우 운영자가 사용할 수도 있다.
- 디버깅이 주 목적인 지표
- 시간 간격이 긴 경향이 있다.
- 이유: 일정 시간 동안 존재하는 문제의 원인을 진단하거나, 복잡한 문제여서 깊이 들여다보아야 하기 때문이다.
- 이러한 데이터는 수집한 뒤 꼭 모니터링 시스템으로 보낼 필요가 없다. 필요할 때만 사용 가능한 것만으로도 충분하다.
자동화가 목적인지, 사람이 볼 것인지?#
- 자동화가 목적인 지표
- 어차피 컴퓨터가 처리할 것이기 때문에, 댜링의 메트릭을 사용해서 아주 세세한 부분까지 대량의 데이터를 수집해도 상관없다.
- 사람이 봐야 할 지표
- 대량으로 수집하면, 문제가 얼마나 심각한지 알 길이 없어서 많은 정보를 무시하는 ‘경보 피로감’에 빠지기 쉽다.
- 지표별로 경보가 나갈 문턱값을 적절히 정의하고 항상 최신으로 유지하는 것 역시 쉽지 않은 일이다.
애플리케이션 상태 검사#
- 카프카로부터 어떠한 지표를 수집하던 간에 간단한 health check를 통해 애플리케이션 프로세스가 살아있는지 여부를 모니터링할 수 있어야 한다.
- 방법1: 브로커가 살아있는지 여부를 알려주는 외부 프로세스를 사용한다.
- 방법2: 카프카 브로커에서 들어와야 하는 지표가 들어오지 않을 때 경보를 보낸다.
- 이 방법은 브로커에 장애가 발생한 것인지, 아니면 모니터링 시스템 그 자체에 장애가 발생한 것인지를 구분하기 어려울 수 있다.
서비스 수준 목표#
서비스 수준 정의#
- 서비스 수준 지표(SLI): 서비스 신뢰성의 여러 측면 중 하나를 가리키는 지표이다.
- 이것은 클라이언트 경험과 크게 연관성이 있기 때문에 대체로 여기에 속하는 지표들이 더 목표 지향적일수록 좋다.
- 예시: 웹 서버에서 2xx, 3xx, 혹은 4xx 응답을 받는 요청의 비율 같은 것이 있다.
- 서비스 수준 목표(SLO) 또는 서비스 수준 한계(SLT): SLI에 목표값을 결합한 것이다.
- 예시: 7일간 웹 서버에 대한 요청 중에 99%가 2xx, 3xx 혹은 4xx 응답을 받아야 한다.
- 서비스 수준 협약(SLA): 서비스 제공자와 클라이언트 사이의 계약으로, 대개 측정 방식, 보고 방식, 지원을 받을 수 있는 방법 그리고 SLA를 준수하지 못했을 때 서비스 제공자가 져야 하는 책임이 명시된 여러 개의 SLO를 포함한다.
- 예시: 만약 서비스 제공자가 SLO 수준의 작동을 제공하지 못할 경우 해당 기간에 대한 모든 비용을 환불해 준다.
좋은 서비스 수준 지표를 위해서는 어떠한 지푯값을 써야 하는가?#
- SLI에 연관된 지표는 카프카 브로커 외부에 있는 어딘가에서 수집되어야 한다.
- 이상적으로, 각 이벤트는 SLO 문턱값 아래에있는지 개별적으로 확인할 수 있어야 한다.
경보에 SLO를 사용하기#
- SLO는 주된 경보로 설정되어 있어야 한다.
- 이유: SLO는 사용자의 관점에서 문제를 기술하는 것이고, 운영하는 사람 입장에서 가장 먼저 고려해야 하기 때문에 그렇다.
- 문제는 SLO를 직접적인 경보 기준으로 사용하는 것이 어렵다.
- 조기에 경고가 가도록 뭔가 파생된 값을 사용하는 경우도 있지만, SLO를 경보에 사용하는 가장 좋은 방법은 소진율을 보는 것이다.
카프카 브로커 지표#
클러스터 문제 진단하기#
- 카프카 클러스터에 문제가 있을 경우, 크게 3가지 종류가 있다.
- 단일 브로커에 발생하는 문제
- 과적재된 클러스터에 발생하는 문제
- 컨트롤러 문제
- 단일 브로커에서 발생하는 문제
- 원인1: 대체로 고장난 저장 장치난 시스템 내의 다른 애플리케이션 으로 인한 자원 제한으로 인해 발생하는 문제
- 탐지 방법: 각각의 서버에 대한 가용성뿐만 아니라 저장 장치, 운영체제 사용률 역시 모니터링해야 한다.
- 원인2: 하드웨어나 운영체제 수준에서 발생하는 문제를 제외한다면, 대부분의 문제는 카프카 클러스터 안에서 한 쪽에만 요청이 몰려서 발생한다.
- 해결 방법: 외부 툴을 사용해서 클러트서틔 균형을 항상 유지하는 것을 강력히 권장한다.
- 과적재된 클러스터에 발생하는 문제
- 탐지 방법: 만약 클러스터에 균형이 잡혀 있는데도 다수의 브로커가 요청에 대해 높은 지연을 가지거나 요청 핸들러 풀의 유휴 비율이 높다면, 브로커가 처리할 수 있는 트래픽의 한계에 다다른 것이다.
- 해결 방법: 클러스터에 걸리는 부하를 줄이든지, 브로커 수를 늘리든지 둘 중 하나다.
- 컨트롤러 문제
- 증상: 브로커 메타데이터 동기화가 끊어진다든가, 브로커는 멀쩡해 보이는데 레플리카는 오프라인 상태라던가, 토픽 생성과 같은 기능이 제대로 작동하지 않는다든가.
- 탐지 방법: 탐지하는 방법이 어렵다. 활성 컨트롤러 수나 컨트롤러 큐 크기와 같은 지표를 모니터링함으로써 뭔가 문제가 발생했을 때 알아차릴 수 있다.
불완전 복제 파티션 다루기#
- 불완전 복제 파티션: 브로커 단위로 집계되고, 해당 브로커가 리더 레플리카를 잡고 있는 파티션 중 팔로워 레플리카가 따라오지 못하고 있는 파티션의 수를 나타낸다.
- 자주 쓰이는 지표인 이유: 브로커 정지에서부터 자원 고갈에 이르기까지, 카프카 클러스터에서 발생하는 많은 문제에 대한 통찰력을 준다.
- JMX MBean:
kafka.server:type=ReplicaManager,name=UnderReplicatedPartitions
- 증상1: 다수의 브로커가 일정한 수의 불완전한 복제 파티션을 가지고 있다.
- 원인: 보통 클러스터의 브로커 중 하나가 내려가 있는 경우가 많다.
- 해결 방법: 브로커에서 무슨 일이 벌어졌는지를 살펴본 뒤 해결해야 한다. 하드웨어 장애인 경우가 많지만, 운영체제 혹은 자바 이슈 때문일 수도 있다.
- 증상2: 불완전 복제 파티션의 수가 오르락내리락 하거나, 수는 일정한데 내려간 브로커가 없다.
- 원인: 대개 클러스터의 성능 문제가 원인이다.
- 해결 방법: 가장 먼저 해야 할 일은 문제가 단일 브로커에 국하노딘 것인지 아니면 클러스터 전체에 연결된 것인지 확인하는 것이다.
- 만약 불완전 복제 파티션들이 한 브로커에 몰려 있다면 해당 브로커가 문제일 가능성이 높다.
- 만약 불완전 복제 파티션이 여러 브로커에 걸쳐 나타난다면 그건 클러스터 문제일 수도 있지만, 여전히 특정 브로커 때문일 가능성이 있다.
- 이 경우, 특정 브로커가 다른 브로커로부터 메시지를 복제하는데 문제가 있을 수 있는데, 그렇다면 어느 브로커가 문제인지 찾아내야 한다.
- 만약 공통으로 나타나는 브로커가 없다면, 클러스터 수준의 문제일 가능성이 높다.
- 클러스터 수준 문제: 둘 중 하나의 유형에 속한다.
- 부하 불균형
- 문제 진단을 위한 메트릭: 파티션의 개수, 리더 파티션 수, 전 토픽에 있어서의 초당 들어오는 메시지, 전 토픽에 있어서의 초당 들어오는 바이트, 전 토픽에 있어서의 초당 나가는 바이트
- 자원 고갈
- 문제 진단을 위한 메트릭: CPU 사용률, 인바운드 네트워크 속도, 아웃바운드 네트워크 속도, 평균 디스크 대기 시간, 디스크 평균 활용률
- 호스트 수준 문제: 카프카 성능 문제가 클러스터 전체가 아닌 한두 개의 브로커에 국한되어 있다면, 해당 서버가 나머지 서버와 무엇이 다른지 살펴봐야 한다.
- 이러한 문제에는 몇 가지 유형이 있다.
- 하드웨어 장애
- 네트워킹
- 다른 프로세스와의 충돌
- 로컬 구성의 차이
브로커 지표#
활성 컨트롤러 수#
- JMX MBean:
kafka.controller:type=KafkaControlller,name=ActiveControllerCount - 값 범위: 0 또는 1(1이면, 현재 브로커가 컨트롤러)
- 임의의 클러스터에는 언제나 딱 하나의 컨트롤러가 있어야 한다.
- 문제 상황1: 두 개의 브로커가 서로 자기가 컨트롤러라고 하고 있음
- 원인: 종료되었어야 할 컨트롤러 스레드에 뭔가 문제가 생겨서 어딘가에서 멈춘 것이다.
- 해결 방법: 최소 두 브로커를 모두 재시작해야 하낟.
- 문제 상황2: 클러스터 안에 컨트롤러 브로커가 없을 경우
- 해결 방법: 컨트롤러 스레드가 제대로 작동하지 않는 이유를 찾아야 한다. 예를 들어서, 주키퍼 클러스터와 네트워크 연결이 단절되었을 경우 이러한 문제가 발생할 수 있다.
- 문제가 해결되었다면, 컨트롤러 스레드 상태를 초기화하기 위해 클러스터 안의 모든 브로커를 재시작해주는 것이 좋다.
컨트롤러 큐 크기#
- JMX MBean:
kafka.controller:type=ControllerEventManager,name=EventQueueSize - 값 범위: 0 이상 Integer
- 현재 컨트롤러에서 브로커의 처리를 기다리고 있는 요청의 수를 가리킨다.
- 이 값이 순간적으로 튈 수는 있지만, 게속해서 증가하거나 높아진 상태로 유지되고 있으면 그건 컨트롤러에 뭔가 문제가 발생한 것이다.
- 해결방법: 현재 컨트롤러 역할을 하고 있는 브로커를 끔으로써 컬트롤러를 다른 브로커로 옮겨야 한다.
요청 핸들러의 유휴 비율#
- JMX MBean:
kafka.controller:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent - 값 범위: 0 이상 1 이하 Float
- 경험적으로는 이 값이 20% 이하로 내려간다는 것은 잠재적인 문제가 있다는 것이고 10% 이하로 내려가면 대개 성능 문젝 ㅏ현재 진행형임을 가리킨다.
- 핸들러 스레드 풀 사용률이 높아지는 두 가지 이유
- 이유1: 스레드 수가 충분하지 않는 경우다. 일반적으로, 요청 핸들러 스레드의 수는 시스템의 프로세서 수와 같게 설정해야 한다(하이퍼스레딩 기능이 있는 프로세서 포함)
- 이유2: 스레드들이 요청별로 쓸데없는 작업을 할 경우다.
- 0.10부터 메시지 배치에 상대적인 오프셋을 할당할 수 있도록 하는 새로운 메시지 형식이 도입되어서, 브로커는 메시지 배치를 재압축 하는 단계를 생략할 수 있게 되었다.
- 만약 사용중인 프로듀서와 컨슈머 모두가 0.10 메시지 형식을 지원할 경우, 가장 큰 성능 향상을 가져올 수 있는 방법 중 하나는 브로커의 메시지 형식을 0.10으로 바꿔 주는 것이다.
전 토픽 바이트 인입#
- JMX MBean:
kafka.controller:type=BrokerTopicMetrics,name=BytesInPerSec - 값 범위: 초당 인입률은 Double, 개수는 Integer
- 사용할 수 있는 상황
- 클러스터를 언제 확장해야 하는지 결정할 때
- 트래픽이 어떻게 증가함에 따라 필요한 다른 작업을 언제 해야하는지 결정할 때
- 클러스터의 어느 브로커가 다른 브로커보다 더 많은 트래픽을 받고 있는지 측정할 때
- 속도 지표이다.
- 속도 지표는 7개의 속성을 가진다.
EventType: 모든 지표의 단위. 여기서는 바이트RateUnit: 속도 지표의 시간적 기준, 여기서는 초OneMinuteRate: 지난 1분간의 평균FiveMinuteRate: 지난 5분간의 평균FifteenMinuteRate: 지난 15분간의 평균MeanRate: 브로커가 시작된 이후의 평균Count: 브로커가 시작된 시점부터 지속적으로 증가하는 값
전 토픽 바이트 유출#
- JMX MBean:
kafka.controller:type=BrokerTopicMetrics,name=BytesOutPerSec - 값 범위: 초당 유출률은 Double, 개수는 Integer
- 카프카는 다수의 컨슈머를 쉽게 처리하기 때문에 유출 속도는 인입 속도와는 다르게 오를 수 있다.
- 유출 속도가 인입 속도의 여섯 배인 경우도 흔하다.
전 토픽 메시지 인입#
- JMX MBean:
kafka.controller:type=BrokerTopicMetrics,name=MessagesInPerSec - 값 범위: 초당 개수은 Double, 개수는 Integer
- 사용할 수 있는 상황
- 평균 메시지 크기 측정할 때
- 브로커 간의 불균형을 볼 때
파티션 수#
- JMX MBean:
kafka.controller:type=ReplicaManager,name=PartitionCount - 값 범위: 0 이상 Integer
- 이 값은 브로커에 저장된 모든 레플리카(파티션의 리더건 팔로워건 상관없이)를 포함한다.
리더 수#
- JMX MBean: `kafka.controller:type=ReplicaManager,name=LeaderCount
- 값 범위: 0 이상 Integer
- 이 지푯값은 클러스터 안의 모든 브로커에 걸쳐 균등해야 한다.
- 이 지표는 정기적으로 확인하고 가능하면 경보도 걸어 놓는 것이 좋다.
- 해당 브로커가 리더 역할을 맡고 있는 파티션의 수를 전체 파티션으로 나눠서 백분율 비율의 형태로 보여주는 것이 이 지표를 활용하는 요령이다.
오프라인 파티션#
- JMX MBean: `kafka.controller:type=KafkaController,name=OfflinePartitionsCount
- 값 범위: 0 이상 Integer
- 이 측정값은 클러스터 컨트롤러 역할을 맡고 있는 브로커에게만 제고오디는데, 현재 리더가 없는 파티션의 개수를 보여준다.
- 리더가 없는 파티션은 크게 두 가지 이유로 발생할 수 있다.
- 레플리카를 보유하고 있는 모든 브로커가 다운되었을 때
- (언클린 리더 선출 기능이 꺼져 있는 상태에서) 저장된 메시지의 개수가 모자란 탓에 리더 역할을 맡을 수 있는 인-싱크 레플리카가 없을 때
- 프로덕션 환경에서의 카프카 클러스터에서 오프라인 파티션은 프로듀서 클라이언트에 메시지 유실이나 애플리케이션에서의 백프레셔와 같은 문제를 야기할 수 있다.
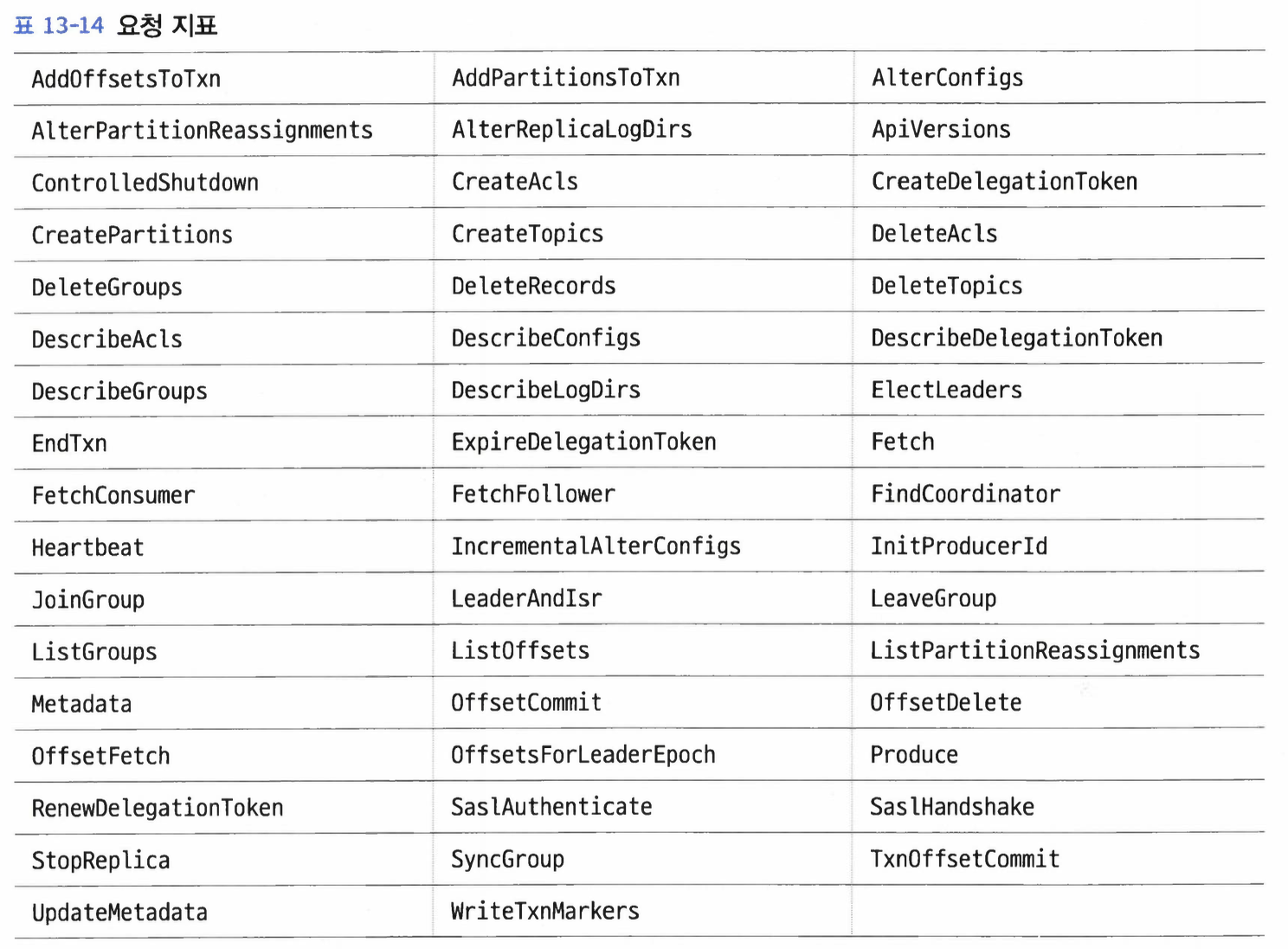
요청 지표#
- 버전 2.5.0 기준으로 지표가 제공되고 있는 요청은 다음과 같다.
- 각각의 요청에 대해 8개의 지표가 제공된다.
- 전체 시간: 브로커에 요청이 수신되어 응답이 전송될 때까지 걸린 전체 시간.
- 요청 큐 시간: 요청이 수신되어 처리가 시간되기 전까지 큐에서 대기한 시간.
- 로컬 시간: 파티션 리더가 요청을 처리하는 데 걸린 시간. 디스크에 전달하는 시간을 포함한다.
- 원격 시간: 요청 처리가 완전히 끄나기 전 팔로워를 기다린 시간.
- 스로틀 시간: 클라이언트 쿼터 설정을 만족시키기 위해 응답을 내보내지 않고 붙잡아 놓은 시간.
- 응답 큐 시간: 요청에 대한 응답이 요청자에게 리턴됙 전 큐에서 대기하는 시간.
- 응답 전송 시간: 응답을 보내는 데 소요되는 시간.
- 각각의 지표에 대해 제공되는 속성
- Count: 프로세스가 시작된 후의 요청 개수.
- Min: 전체 요청 중 최저값.
- Max: 전체 요청 중 최대값.
- Mean: 전체 요청의 평균값.
- StdDev: 요청이 들어온 시각에 측정된 측정값의 표준 편차.
- Percentiles: 50thPercentile, 75thPercentile, 95thPercentile, 98thPercentile, 99thPercentile, 999thPercentile
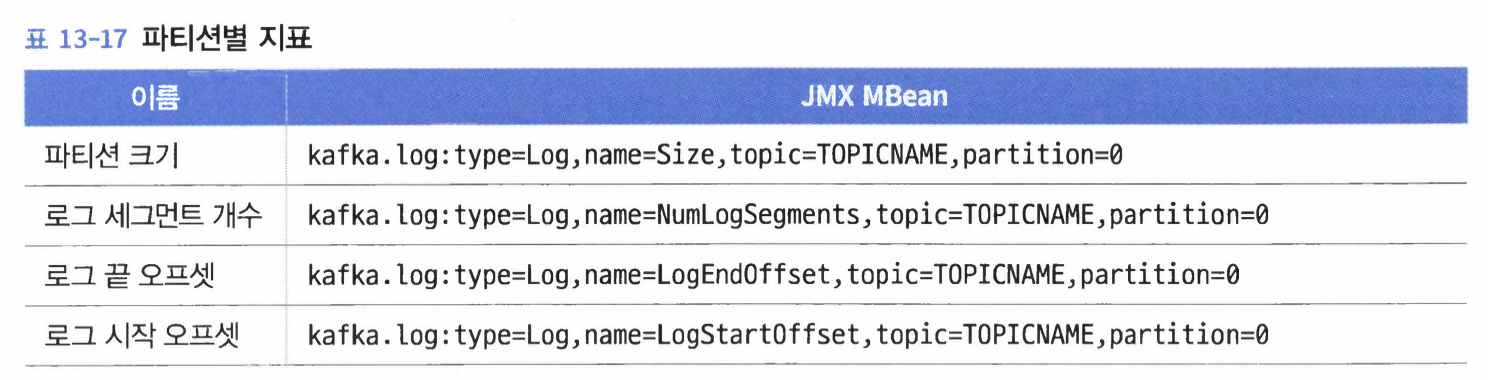
토픽과 파티션별 지표#
토픽별 지표#

파티션별 지표#
JVM 모니터링#
가비지 수집#
- 모니터링하기 위해 살펴봐야하는 구체적인 빈은 사용중인 자바 런타임 환경과 가비지 수집기에 따라 달라진다.
- 속성
CollectionCount: JVM이 시작된 이래 GC 사이클 수CollectionTime: JVM이 시작된 이래 GC 사이클에 소요된 시간의 밀리초 단위
- 각 지표는
LastGcInfo 속성도 갖는다.- 마지막 GC 사이클에 대한 정보이다.
- 그 중
duration 이라는 값은 마지막 GC 사이클이 얼마나 오래 걸리는지를 밀리초 단위로 알려준다.
자바 운영체제 모니터링#
- JVM의
java.lang:type=OperatingSystem 빈을 통해서 운영체제에 대한 일부 정보를 얻을 수 있다. MaxFileDescriptorCount: JVM이 열 수 있는 최대 파일 디스크립터의 수OpenFileDescriptorCount: 현재 열려있는 FD의 수=
운영체제 모니터링#
- 눈여겨봐야 할 메트릭은 CPU 사용, 메모리 사용, 디스크 사용, 디스크 I/O 그리고 네트워크 사용이다.
- CPU 사용에 대해서는 시스템 부하 평균 정도는 살펴봐야 한다.
- 시스템 부하 평균(load average): 실행은 할 수 있지만 실행을 위해 프로세서를 기다리고 있는 프로세스의 수이다. 리눅스의 경우 디스크 입출력을 기다리는 것처럼 인터럽트가 불가능한 스레드 수 역시 포함한다.
- 전체 메모리와 프리 스왑 메모리 용량을 모니터링 하여 스왑 메모리가 사용되지 않도록 해야 한다.
- 디스크가 효율적으로 사용되고 있는지 초당 읽기 및 쓰기, 읽기 및 쓰기 큐의 평균 크기, 평균 대기 시간, 디스크 사용률을 모니터링해야 한다.
- 초당 비트 단위로 나타내어지는 인입, 유출 네트워크 트래픽 양을 보면 된다.
- 로그 파일이 좀 더 깔끔하게 떨어지게 하려면 몇 개의 로거는 분리하는 것이 좋다.
- 별도의 디스크 파일로 떨어지는 게 나은 로거1:
kafka.controller 로거- 클러스터 컨트롤러에 대한 메시지를 제공하기 위해 사용된다.
- 언제가 되었든 하나의 브로커만이 컨트롤러가 될 수 있으므로, 이 로거를 쓰는 브로커 역시 하나뿐이다.
- 여기에는 토픽의 생성과 변경 외에도 선호 레플리카 선출이나 파티션 이동 등과 같은 클러스터 작업에 대한 정보가 포함된다.
- 별도의 디스크 파일러 떨어지는 게 나은 로거2:
kafka.server.ClientQuotaManager- 프로듀서 혹은 컨슈머 쿼터 작업에 관련된 메시지를 보여주기 위해 사용된다.
- 로그 압착 스레드 상태에 관한 정보를 로깅하는 것 역시 도움이 된다.
- 이유: 이 스레드의 작동 상태를 가리키는 지표가 없기 때문에, 파티션 하나를 압착하다 실패가 남으로써 전체 로그 압착 스레드가 소리없이 멈출 수도 있다.
kafka.log.LogCleaner, kafka.log.Cleaner, kafka.log.LogCleanerManger 로거를 DEBUG 레벨로 활성화함으로써 이 스레드에 대한 상태 정보가 찍히게 할 수 있다.
kafka.request.logger: DEBUG 또는 TRACE 레벨로 켜면 브로커로 들어오는 모든 요청에 대한 정보를 기록한다.
클라이언트 모니터링#
프로듀서 지표#
- 모든 프로듀서 지표는 빈 이름에 프로듀서 클라이언트의 클라이언트 ID를 갖는다.
프로듀서 종합 지표#
record-error-rate- 설명: 프로듀서는 백오프를 해 가면서 사전 설정된 수만큼 재시도를 하게 되어있는데, 만약 재시도 수가 고갈되면 메시지가 폐기된다. 폐기된 메시지의 수다.
- 경보 설정 해 놓아야 한다.
- 언제나 0이어야 하며, 만약 그보다 크다면 프로듀서가 브로커로 메시지를 보내는 와중에 누수가 발생하고 있음을 의미한다.
request-latency-avg- 설명: 브로커가 쓰기 요청을 받을 때까지 걸린 평균 시간
- 경보 설정 해 놓아야 한다.
- 정상 작동 상태에서 이 지표의 기준값을 찾은 뒤 이 기준값보다 큰 값으로 경보 문턱값을 설정하면 된다.
- 지연이 발생하면 네트워크 문제일 수도 있지만, 브로커에 뭔가 문제가 발생했을 수도 있다.
- 프로듀서가 전송한느 메시지 트래픽에 대한 지표
outgoing-byte-rate: 전송되는 메시지의 절대 코기를 초당 바이트 형태로 나타낸다.record-send-rate: 초당 전송되는 메시지 수의 크기request-rate: 브로커로 전달되는 쓰기 요청의 수를 초 단위로 나타낸다.- 설명: 하나의 요청은 하나 이상의 배치를 포함할 수 있으며, 하나의 배치는 1개 이상의 메시지를 포함할 수 있다.
request-size-avg: 브로커로 보내지는 쓰기 요청의 평균 크기를 바이트 단위로 나타낸다.batch-size-avg: 메시지 배치의 평균 크기를 바이트 단위로 나타낸다.record-size-avg: 레코드의 평균 크기를 바이트 단위로 나타낸다.record-queue-time-avg- 설명: 애플리케이션이 메시지를 전송한 뒤 실제로 카프카에 쓰여지기 전까지 프로듀서에서 대기하는 평균 시간(ms)이다.
- 프로듀서는 다음 두 개의 조건 중 하나가 만족될 때까지 기다린다.
batch.size 설정에 지정된 크기를 갖는 배치가 메시지로 채워질 때- 마지막 배치가 전송된 이래
linger.ms 설정에 지정된 시간이 경과될 때
브로커별, 토피별 지표#
- 프로듀서 종합 지표 빈의 속성과 동일하고 의미도 동일하다.
- 브로커별 프로듀서 지표에서 중요한 지표
request-latency-avg: 거의 변화가 없지만, 특정 브로커로의 연결에 문제가 있을 경우 알 수 있다.outging-byte-rate, request-latency-avg: 브로커가 리더를 맡고 있는 파티션이 무엇이냐에 따라 달라지는 경향이 있다.
- 토픽별 지표는 프로듀서가 2개 이상의 토픽에 쓰고 있는 경우에만 유용하다.
- 토픽별 지표는 특정한 문제의 원인을 찾는데 가장 많이 사용된다.
- 예시:
record-send-rate, record-error-rate 속성의 경우 어느 토픽에서 메시지 누수가 발생했는지 찾아내거나 전체 토픽에 대해 누수된 메시지가 있는지 검증할 때 사용할 수 있다. - 예시2:
byte-rate 지표는 주어진 토픽에 대해 초당 몇 바이트의 메시지가 전송되고 있는지를 보여준다.
컨슈머 지표#

읽기 매니저 지표#
fecth-latency-avg- 설명: 브로커로 읽기 요청을 보내는 데 보내는 시간.
- 경보 설정을 걸어놓는 것은 문제가 있는데, 지연은 컨슈머 설정 중
fetch.min.bytes와 fetch.max.wait.ms의 영향을 받기 때문이다.- 어떨 때는 메시지가 준비되어 있어서 빨리 응답을 내놓지만 어떨 때는 메시지가 준비되질 않아서
fetch.max.wait.ms만큼 기다리다 리턴하는 식이다 보니 느린 토픽은 지연이 일정하지 않다.
bytes-consumed-rate: 읽기 트래픽의 초당 바이트 수records-consumed-rate: 읽기 트래픽의 초당 메시지 수fetch-rate: 컨슈머가 보내는 초당 읽기 요청 수fetch-size-avg: 읽기 요청의 평균 크기의 바이트 수records-per-request-avg: 읽기 요청의 결과로 주어진 메시지의 수의 평균
브로커별, 토픽별 지표#
- 프로듀서 클라이언트와 마찬가지로, 컨슈머 클라이언트 역시 브로커 연결이나 읽는 토픽에 각각에 대한 지표를 제공한다.
- 이 지표는 메시지 읽기 과정에서 발생하는 문제점을 디버깅하는 데 유용하겠지만, 매일 살펴볼 필요는 없을 것이다.
- 컨슈머 클라이언트가 제공하는 토픽별 지표는 1개 이상의 토픽에서 읽어오고 있을 때 유용하다.
컨슈머 코디네이터 지표#
- 코디네이터 관련 작업으로 인해 컨슈머에게 생길 수 있는 가장 큰 문제는 컨슈머 그룹 동기화 때문에 읽기 작업이 일시 중지될 수 있다는 점이다.
sync-time-avg: 동기화 작업에 들어간 평균 시간을 밀리초 단위로 보여준다.sync-rate: 초당 그룹 동기화 수- 컨슈머 그룹이 안정적일 경우 이 값은 대부분 시간 동안 0이다.
commit-latency-avg: 오프셋 커밋에 걸리는 평균 시간- 이 지표의 기대값을 기준으로 해서 경보 문턱값으로 사용하면 될 것이다.
assigned-partitions: 특정 컨슈머 클라이언트에게 할당된 파티션의 개수- 같은 그룹의 다른 컨슈머 클라이언트와 비교했을 때 컨슈머 그룹 전체에서 부하가 고르게 분배되었는지를 확인할 수 있게 해주기 때문에 유용하다.
- 아파치 카프카는 하나의 클라이언트가 전체 클러스터를 독차지하는 것을방지하기 위해 클라이언트 요청을 스로틀링 하는 기능을 가지고 있다.
- 이는 프로듀서와 컨슈머 양쪽다 설정 가능하다.
- 각 클라이언트 ID에서 부터 각 브로커까지 허용된 트래픽 형대로 표시된다.
- 모든 클라이언트에 적용되는 기본값으 브로커 설정에 따르지만, 클라이언트별로 동적으로 재정의가 가능하다.
- 브로커가 판단하기에 클라이언트가 주어진 쿼터를 초과했다면, 클라이언트로 갈 응답을 사용량이 쿼터 아래로 내려가기에 충분한 시간 동안 늦춤으로써 클라이언트 속도를 감속시킨다.
- 카프카 브로커는 클라이언트에게 응답을 보낼 때 스로틀링되고 있다는 걸 알려 주는 에러 코드를 쓰거나 하지 않는다.
- 즉, 애플리케이션이 현재 스로틀링되고 있는지의 여부를 알고 싶다면 클라이언트 스토를링 시간을 보여주는 지표를 모니터링 해야 한다.

- 카프카 브로커에 쿼터 기능은 기본적으로 활성화되어 있지 않다. 하지만 지금 쿼터를 사용하고 있는지의 여부와는 상관없이 이 지표들을 모니터링하는 것이 안전하다.
랙 모니터링#
- 컨슈머 랙: 프로듀서가 특정 파티션에 마지막으로 쓴 메시지와 컨슈머가 마지막으로 읽고 처리한 메시지 사이의 차이
- 컨슈머 클라이언트의
records-lag-max 지표의 문제점들- 가장 지연이 심한 하나의 파티션만 나타내기 때문에 컨슈머가 얼마만큼 뒤처져 있는지 정확하게 보여주지 않는다.
- 만약 컨슈머에 문제가 생기거나 오프라인 상태가 되면 지표가 부정확하거나, 아예 사용 불능이 될 수도 있다.
- 컨슈머 랙을 모니터링할 때 선호되는 방법: 브로커의 파티션 상태와 컨슈머 상태를 둘 다 지켜봄으로써 마지막으로 쓰여진 메시지 오프셋과 컨슈머 그룹이 파티션에 대해 마지막으로 커밋한 오프셋을 추적하는 외부 프로세스를 두는 것이다.
- 명령줄 유틸리티로 모니터링하는 방법이 문제가 되는 이유들
- 각 파티션에 대해 어느 정도가 적당한수준의 랙인지 알아야 한다.
- 만약 10만 개의 파티션을 가진 1500개의 토픽을 읽는 컨슈머 그룹에 대해 이 작업을 한다면, 만만치 않을 것이다.
- 컨슈머 그룹을 모니터링할 때 이러한 복잡성을 줄이는 방법 중 하나는 버로우(Burrow)를 사용하는 것이다.
- 링크드인에서 개발된 컨슈머 상태 모니터링용 오픈소스 애플리케이션이다.
- 클러스터 내 모든 컨슈머 그룹의 랙 정보를 가져온 뒤 각 그룹이 제대로 작동하고 잇느지, 뒤쳐지고 있는지, 아니면 일시 중지ㅈ되거나 완전히 중지되었는지를 계산해서 보여준다.
종단 모니터링#
- 카프카 클러스터의 작동 상태에 대한 클라이언트의 관점을 제공하는 종단 모니터링 시스템이 있다.
- 필요한 이유: 컨슈머와 프로듀서 클라이언트는 카프카 클러스터에 뭔가 문제가 있음을 나타낼 수 있는 지표글 가지고 있지만, 이것은 지연의 증가 원인이 무엇인지, 즉 클라이언트 탓인지, 네트워크 탓인지, 아니면 카프카 자체의 문제 때문인지는 알려 주지는 않는다.
- Xinfra Monitor
- 링크드인 카프카 팀에서 공개한 오프소스 툴
- 클러스터의 모든 브로커에 걸쳐 있는 토픽에 계속해서 데이터를 쓰고 읽음으로써 브로커별 모니터링을 수행하는 것이다.
- 이것은 읽기와 쓰기 기능 작동 여부를 판단할 수 있을 뿐이 아니라 메시지를 쓴 후 읽어오기까지의 지연까지도 측정할 수 있다.