예외 처리#
JPA 표준 예외 정리#
- JPA 표준 예외들은
PersistenceException의 자식 클래스다.- 그리고 이 예외 클래스는
RuntimeException의 자식이므로 JPA 예외는 모두 언체크 예외다.
- JPA 표준 예외는 2가지로 나눌 수 있다.
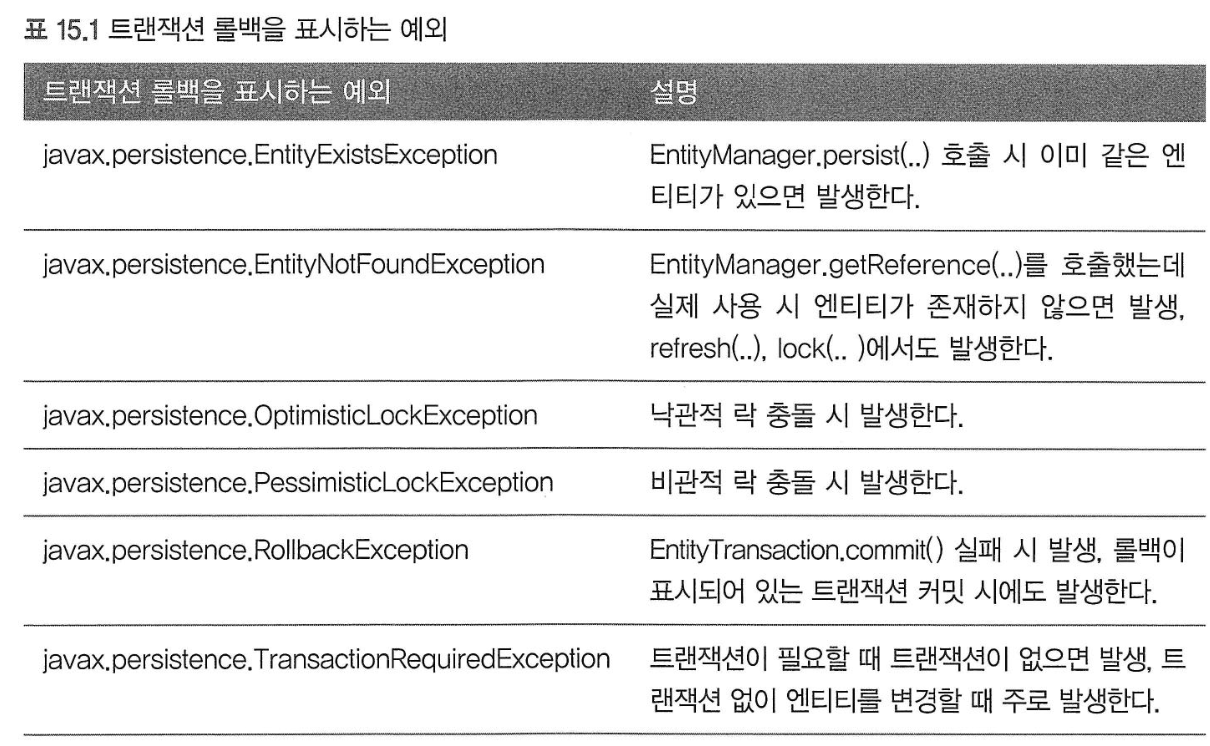
- 트랜잭션 롤백을 표시하는 예외:
- 심각한 예외이므로 복구해선 안 된다.
- 트랜잭션을 강제로 커밋해도 트랜잭션이 커밋되지 않고 대신
RollbackException이 발생한다.
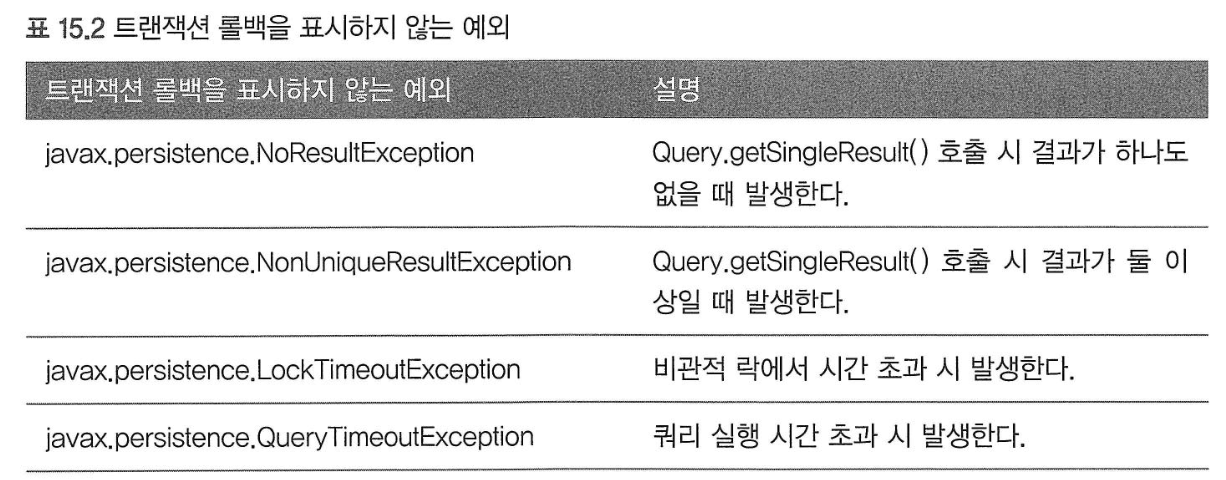
- 트랜잭션 롤백을 표시하지 않는 예외
스프링 프레임워크의 JPA 예외 변환#
- 서비스 계층에서 데이터 접근 계층의 구현 기술에 직접 의존하는 것은 좋은 설계라 할 수 없다.
- 스프링 프레임워크는 이런 문제를 해결하려고 데이터 접근 계층에 대한 예외를 추상화해서 개발자에게 제공한다.
- 예)
javax.persistence.NoResultException -> org.springframework.dao.EmptyResultDataAccessException
스프링 프레임워크에 JPA 예외 변환기 적용#
- JPA 예외를 스프링 프레임워크가 제공하는 추상화된 예외로 변경하려면
PersistenceExceptionTranslationPostProcessor를 빈으로 등록하면 된다. - 이것은
@Repository 어노테이션을 사용한 곳에 예외 변환 AOP를 적용해서 JPA 예외를 스프링 프레임워크가 추상화한 예외로 변환해준다.
트랜잭션 롤백 시 주의사항#
- 트랜잭션을 롤백하는 것은 데이터베이스의 반영사항만 롤백하는 것이지 수정한 자바 객체까지 원상태로 복구해주지는 않는다.
- 따라서 트랜잭션이 롤백된 영속성 컨텍스트를 그대로 사용하는 것은 위험하다.
- 스프링 기본 전략인 트랜잭션당 영속성 컨텍스트 전략은 문제가 발생하면 트랜잭션 AOP 종료 시점에 트랜잭션을 롤백하면서 영속성 컨텍스트도 함께 종료하므로 문제가 발생하지 않는다.
- OSIV처럼 영속성 컨텍스트의 범위를 트랜잭션 범위보다 넓게 사용해서 여러 트랜잭션이 하나의 영속성 컨텍스트를 사용할 때 문제가 발생한다.
엔티티 비교#
- 영속성 컨텍스트의 1차 캐시의 가장 큰 장점은 애플리케이션 수준의 repeatable read를 제공해준다는 것이다.
- 같은 영속성 컨텍스트에서 엔티티를 조회하면 항상 같은 엔티티 인스턴스를 반환한다.
- 이것은 단순히 동등성 비교 수준이 아니라 정말 주소값이 같은 인스턴스를 반환한다.
- 같은 영속성 컨텍스트의 관리를 받는 영속 상태의 엔티티는 항상 동등성 비교를 성공한다.
- 하지만 서로 다른 영속성 컨텍스트에서 관리를 받는 엔티티는 동등성 비교에 실패한다.
equals()를 사용한 동등성 비교할 때, 비즈니스 키를 활용한 동등성 비교를 권장한다.
프록시 심화 주제#
- 프록시를 사용하는 방식의 기술적인 한계로 예상하지 못한 문제가 발생할 수 있다.
영속성 컨텍스트와 프록시#

- 영속성 컨텍스트는 프록시로 조회된 엔티티에 대해서 같은 엔티티를 찾는 요청이 오면 원본 엔티티가 아닌 처음 조회된 프록시를 반환한다.

- 원본 엔티티를 먼저 조회하면 영속성 컨텍스트는
em.getReference()를 호출해도 프록시가 아닌 원본을 반환한다.
프록시 타입 비교#
- 프록시는 원본 엔티티를 상속 받아서 만들어지므로 프록시로 조회한 엔티티의 타입을 비교할 때는
== 비교를 하면 안 되고 대신에 instanceof를 사용해야 한다. 
프록시 동등성 비교#
- IDE나 외부 라이브러리를 사용해서 구현한
equals() 메소드로 엔티티를 비교할 때, 비교 대상이 원본 엔티티면 문제가 없지만 프록시면 문제가 될 수 있다. 
- 프록시는 원본을 상속받은 자식 타입이므로 프록시의 타입을 비교할 때는
== 비교가 아닌 instanceof를 사용해야 한다. - 프록시는 실제 데이터를 가지고 있지 않다. 따라서 멤버변수에 직접 접근하면 아무값도 조회할 수 없다. 멤버변수를 직접 접근하지 않고 접근자를 사용해서 해결해야 된다.

상속관계와 프록시#
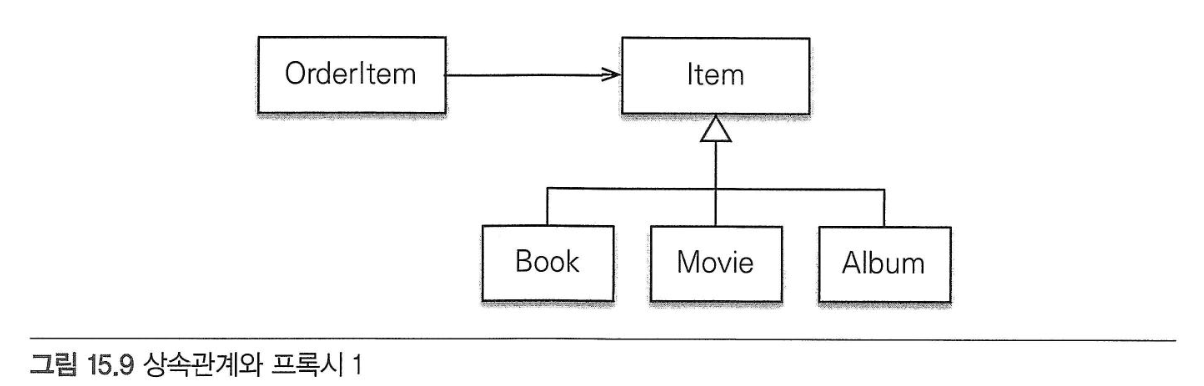
- 프록시를 부모 타입으로 조회하면 문제가 발생한다.
- 아래와 같은 상속 관계가 되기 때문에
proxyItem instanceof Book 은 false가 된다. - 또한 하위 타입으로 다운캐스팅을 할 수 없다.
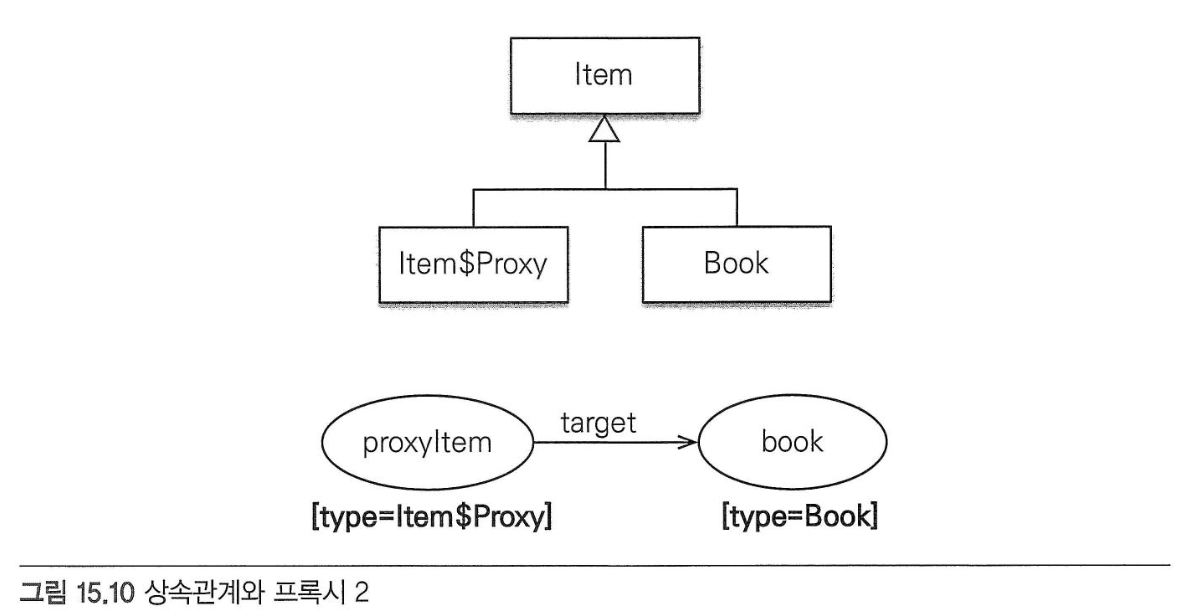
- 해결 방법1: JPQL로 대상 직접 조회

- 단점1: 이 방법을 사용하면 다형성을 활용할 수 없다.
- 해결 방법2: 프록시 벗기기

- 하이버네이트가 제공하는 기능을 사용하면 프록시에서 원본 엔티티를 가져올 수 있다.
- 단점1: 이 방법을 사용하면 프록시 객체와 원본 엔티티의 동일성 비교가 실패한다.
- 해결 방법3: 기능을 위한 별도의 인터페이스 제공
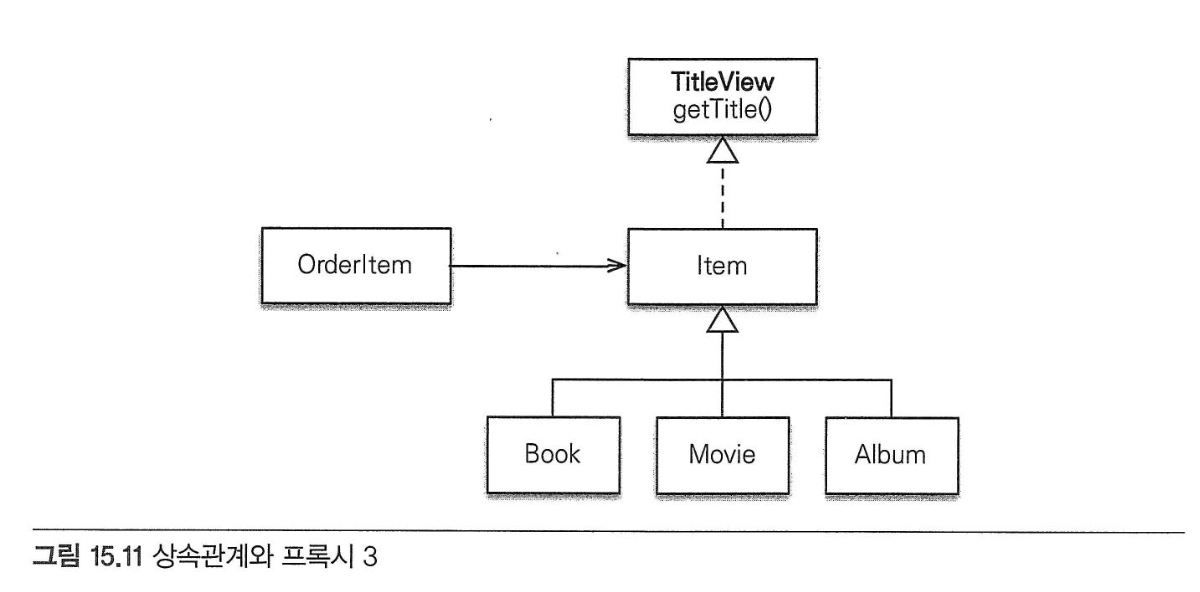
- 인터페이스를 제공하고 각각의 클래스가 자신에게 맞는 기능을 구현하는 것은 다형성을 활용하는 좋은 방법이다.
- 장점1: 다양한 상품 타입이 추가되어도
Item을 사용하는 OrderItem의 코드는 수정하지 않아도 된다. - 장점2: 클라이언트 입장에서는 대상 객체가 프록시인지 아닌지를 고민하지 않아도 된다.
- 단점1: 이 방법을 사용할 때는 프록시의 특징 때문에 프록시의 대상이 되는 타입에 인터페이스를 적용해야 된다.
- 해결 방법4: 비지터 패턴 사용
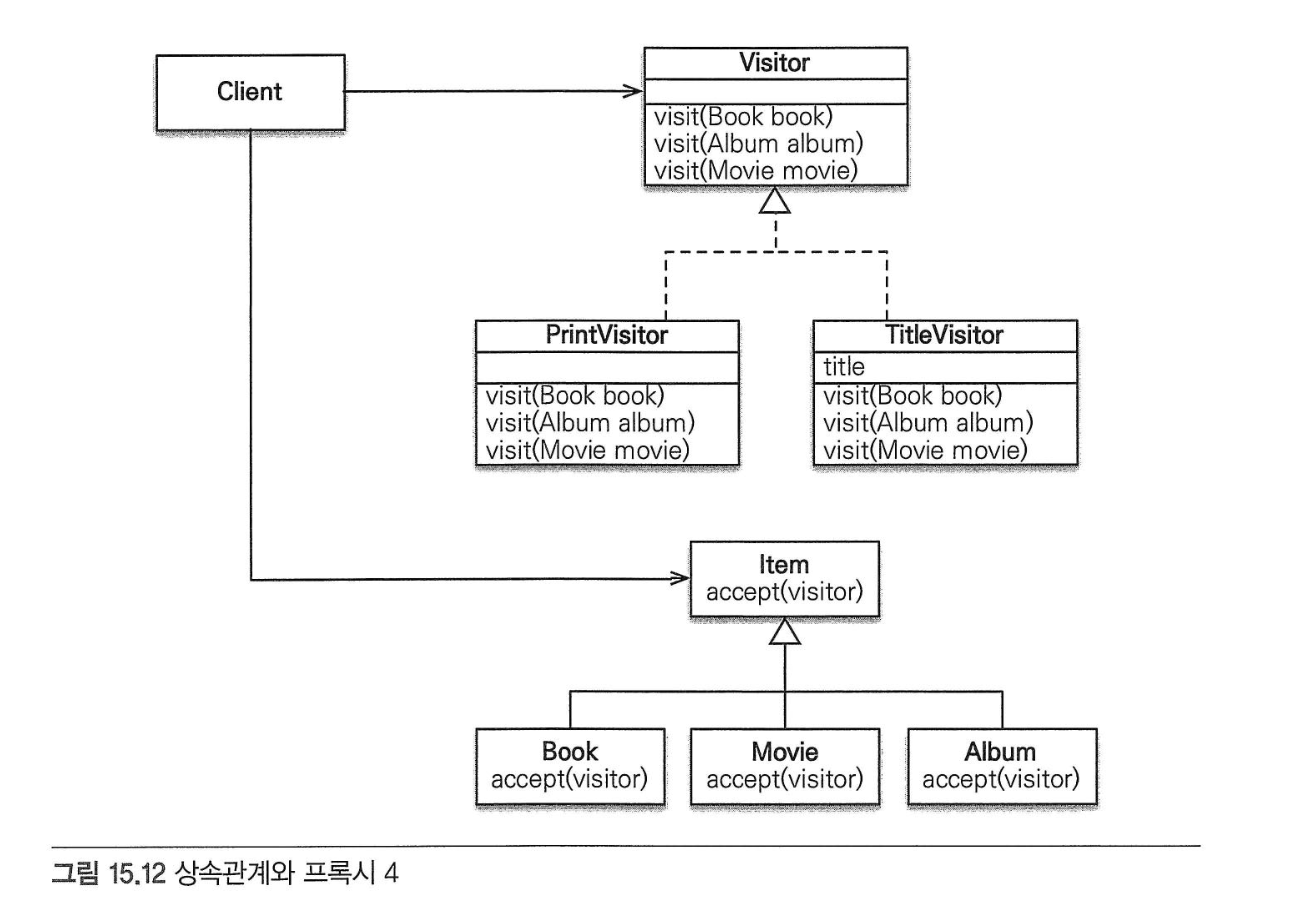

- 장점1: 프록시에 대한 걱정 없이 안전하게 원본 엔티티에 접근할 수 있다.
- 장점2:
instanceof와 타입캐스팅 없이 코드를 구현할 수 있다. - 장점3: 알고리즘과 객체 구조를 분리해서 구조를 수정하지 않고 새로운 동작을 추가할 수 있다.
- 단점1: 너무 복잡하고 더블 디스패치를 사용하기 때문에 이해하기 어렵다.
- 단점2: 객체 구조가 변경되면 모든 Visitor를 수정해야 한다.
성능 최적화#
N+1 문제#

- 즉시 로딩과 지연 로딩 중 추천하는 방법은 즉시 로딩은 사용하지 말고 지연 로딩만 사용하는 것이다.
- 즉시 로딩 전략은 그럴듯해 보이지만 N+1 문제는 물론이고 비즈니스 로직에 따라 필요하지 않는 엔티티를 로딩해야 하는 상황이 자주 발생한다.
em.find() 메서드로 조회시 즉시 로딩으로 설정하면 조인을 사용해서 한 번의 SQL로 조회된다.- 하지만 JPQL 을 사용해 조회할 때는 N+1 문제가 발생할 수 있다.
- 모두 지연 로딩으로 설정하고 N+1 문제 해결이 필요한 곳에는 JPQL 페치 조인 등을 사용하자.
- 지연 로딩은 연관된 컬렉션을 직접 사용할 때 N+1 문제가 발생한다.
- N+1 문제 해결 방법
- 페치 조인 사용:
- 하이버네이트 @BatchSize
- 연관된 엔티티를 조회할 때 지정한 size 만큼 SQL의 IN 절을 사용해서 조회한다.
- 지연 로딩인 경우에도 지연된 엔티티를 최초 사용하는 시점에 다음 SQL을 실행해서 5건의 데이터를 미리 로딩해둔다.
- 하이버네이트 @Fetch(FetchMode.SUBSELECT)
- 해당 어노테이션을 사용하면 연관된 데이터를 조회할 때 서브 쿼리를 사용해서 N+1 문제를 해결한다.
- 즉시 로딩으로 설정하면 조회 시점에, 지연 로딩으로 설정하면 지연 로딩된 엔티티를 사용하는 시점에 다음 SQL이 실행된다.

읽기 전용 쿼리의 성능 최적화#
- 읽기 전용으로 엔티티를 조회하면 메모리 사용량을 최적화할 수 있다.
- 방법1: 스칼라 타입으로 조회
- 스칼라 타입은 영속성 컨텍스트가 결과를 관리하지 않는다.

- 방법2: 읽기 전용 쿼리 힌트 사용
- 하이버네이트 전용 힌트를 사용하여 읽기 전용으로 사용하면, 영속성 컨텍스트는 스냅샷을 보관하지 않아 메모리 사용량을 최적화할 수 있다.
- 스냅샷이 없으므로 엔티티를 수정해도 데이터베이스에 반영되지 않는다.

- 방법3: 읽기 전용 트랜잭션 사용
- 스프링 프레임워크를 사용하면 트랜잭션을 읽기 전용 모드로 설정할 수 있다. (
@Transactional(readOnly = true)) - 읽기 전용 모드 트랜잭션이면 스프링 프레임워크가 하이버네이트 세션의 플러시 모드를 MANUAL로 설정한다.
- 이렇게 하면 강제로 플러시를 호출하지 않는 한 플러시가 일어나지 않는다.
- 플러시할 때 일어나는 스냅샷 비교와 같은 무거운 로직들을 수행하지 않으므로 성능이 향상된다.
- 물론 트랜잭션을 시작했으므로 트랜잭션 시작, 로직수행, 트랜잭션 커밋의 과정은 이루어진다.
- 방법4: 트랜잭션 밖에서 읽기
- 트랜잭션 없이 엔티티를 조회한다는 뜻이다.
- 스프링 프레임워크를 사용하면 다음처럼 설정하면 된다.
- 트랜잭션을 사용하지 않으면 플러시가 일어나지 않으므로 조회 성능이 향상된다.
- 플러시 모드는 AUTO로 설정되어 있지만 트랜잭션 자체가 존재하지 않으므로 트랜잭션을 커밋할 일이 없는 것이다. 그리고 JPQL 쿼리도 트랜잭션 없이 실행하면 플러시를 호출하지 않는다.
- 아래와 같이 읽기 전용 트랜잭션(또는 트랜잭션 밖에서 읽기)과 읽기 전용 쿼리 힌트(또는 스칼라 타입으로 조회)를 동시에 사용하는 것이 효과적이다.
배치 처리#
- 수천에서 수만 건 이상의 엔티티를 한 번에 등록할 때 주의할 점은 영속성 컨텍스트에 엔티티가 계속 쌓이지 않도록 일정 단위마다 영속성 컨텍스트의 엔티티를 데이터베이스에 플러시하고 영속성 컨텍스트를 초기화해야 한다.
- 배치 처리에서 아주 많은 데이터를 조회해서 수정한다면, 수많은 데이터를 한 번에 메모리에 올려둘 수 없어서 2가지 방법을 주로 사용한다.
- 페이징 처리: 데이터 페이징 기능을 사용한다.
- 커서: 데이터베이스가 지원하는 커서 기능을 사용한다.
- 커서 사용 예시
- 하이버네이트는 무상태 세션이라는 기능을 제공한다.
- 영속성 컨텍스트를 만들지 않고 2차 캐시도 사용하지 않는다.
- 엔티티를 수정하려면 무상태 세션이 제공하는
update() 메소드를 직접 호출해야 한다. 
SQL 쿼리 힌트 사용#
- JPA는 데이터베이스 SQL 힌트 기능을 제공하지 않는다.
- SQL 힌트를 사용하려면 하이버네이트를 직접 사용해야 한다.

트랜잭션을 지원하는 쓰기 지연과 성능 최적화#
- SQL을 직접 다루면 5번의 INSERT SQL과 1번의 커밋으로 총 6번 데이터베이스와 통신한다.
- 이것을 최적화하려면 5번의 INSERT SQL을 모아서 한 번에 데이터베이스로 보내면 된다.

- JDBC가 제공하는 SQL 배치 기능을 사용하면 SQL을 모아서 한번에 보낼 수 있지만 코드의 많은 부분을 수정해야 한다.
- JPA는 플러시 기능이 있으므로 SQL 배치 기능을 효과적으로 사용할 수 있다.
hibernate.jdbc.batch_size 속성의 값을 50으로 주면 최대 50건씩 모아서 SQL 배치를 실행한다.- 대신 중간에 다른 SQL가 들어가면 SQL 배치를 다시 시작한다.
- 아래는 1, 2, 3, 4를 모아서 하나의 SQL 배치를 실행하고 5를 한 번 실행하고 6, 7을 모아서 실행한다. 총 3번의 SQL 배치를 실행한다.

- IDENTITY 식별자 생성 전략을 사용할 때는 엔티티를 데이터베이스에 저장해야 식별자를 구할 수 있으므로
em.persist()를 호출하는 즉시 INSERT SQL이 데이터베이스에 전달된다. 따라서 쓰기 지연을 활용한 성능 최적화를 할 수 없다. - 트랜잭션을 지원하는 쓰기 지연은 데이터베이스 테이블 로우에 락이 걸리는 시간을 최소화한다는 장점도 존재한다.
- JPA는 커밋을 해야 플러시를 호출하고 데이터베이스에 수정 쿼리를 보내기 때문에 데이터베이스에 락이 걸리는 시간을 최소화 한다.









