- 컬럼의 데이터 타입과 길이를 선정할 때 가장 주의할 사항은 다음과 같다.
- 저장되는 값의 성격에 맞는 최적의 타입을 선정
- 가변 길이 컬럼은 최적의 길이를 지정
- 조인 조건으로 사용되는 컬럼은 똑같은 데이터 타입으로 선정
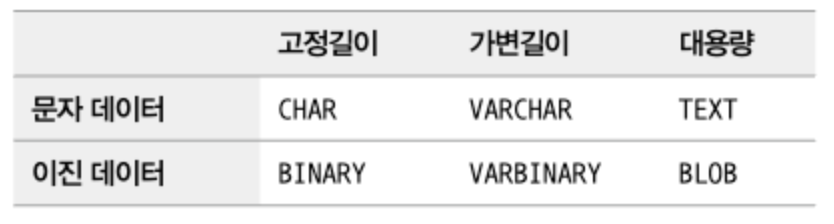
문자열(CHAR와 VARCHAR)
저장 공간
- CHAR와 VARCHAR의 공통점은 문자열을 저장할 수 있는 데이터 타입이라는 점이고, 가장 큰 차이는 고정 길이냐 가변 길이냐다.
- CHAR(1)과 VARCHAR(1) 타입을 사용할 때 사용되는 저장 공간의 크기
- 두 문자열 타입 모두 한 글자를 저장할 때 사용하는 문자 집합에 따라 실제 저장 공간은 1~4바이트까지 사용된다.
- 하지만 VARCHAR 타입은 저장할 때 문자열 길이를 관리하기 위한 1~2바이트의 공간을 추가로 더 사용한다.
- VARCHAR 타입의 길이가 255바이트 이하이면 1바이트만 사용하고, 256바이트 이상이면 2바이트를 사용한다.
- VARCHAR 타입의 길이 표현은 2바이트보다 클 수 없기 때문에, VARHCAR 타입의 최대길이는 65,536 바이트 이상으로 설정할 수 없다.
- CHAR 타입과 VARCHAR 타입을 결정할 때 중요한 판단 기준
- 저장되는 문자열의 길이가 대개 비슷한가?
- 컬럼의 값이 자주 변경되는가?

- 위 상황에서는 아래와 같이 저장된다.
- VARCHAR 타입을 사용한다면 아래와 같이 저장된다.
- 여기서 fd2 컬럼의 값을 “ABCDE"로 수정한다고하면,
- CHAR 타입은 공간이 10바이트 준비되어 있으므로 그냥 컬럼의 값을 업데이트만 하면 된다.
- VARCHAR 타입은 길이가 더 큰 값으로 변경될 때 레코드 자체를 다른 공간으로 옮겨서(Row migration) 저장해야 한다.
- 위 상황에서는 아래와 같이 저장된다.
- 값의 길이가 고정적일 때는 당연히 CHAR 타입을 사용하고, 값이 2~3바이트씩 차이가 나더라도 자주 변경될 수 있는 값은 CHAR 타입을 사용하는 것이 좋다.
- 다른 DBMS와 달리 MySQL은 CHAR(10) 또는 VARCHAR(10)으로 컬럼을 정의하면 이 컬럼은 10바이트를 저장할 수 있는게 아니라, 10글자를 저장할 수 있는 공간을 의미한다.


저장 공간과 스키마 변경(Online DDL)
- MySQL 서버에서는 데이터가 변경되는 도중에도 스키마를 변경할 수 있도록 Online DDL 이라는 기능을 제공한다.
- 하지만 변경 작업의 특성에 따라 SELECT는 가능하지만 INSERT나 UPDATE 같은 데이터 변경은 허용되지 않을 수도 있다.
- VARCHAR 데이터 타입을 사용하는 컬럼의 길이를 늘리는 작업은 utf8mb4 기준 길이가 60(240 바이트)에서 64(256바이트)로 늘리는 경우 COPY 알고리즘을 사용하고 SHARED 잠금을 사용하여 데이터를 변경하지 못하도록 막고 테이블의 레코드를 복사하는 방식으로 처리한다.
- 문자열 길이를 저장하는 공간의 크기를 2바이트로 바꿔야하기 때문이다.
문자 집합(캐릭터 셋)
- MySQL 서버에서 각 테이블의 컬럼은 모두 서로 다른 문자 집합을 사용해 문자열 값을 사용할 수 있다.
- 한글 기반 서비스에서는 euckr 또는 utf8mb4 문자 집합을 사용하며, 일본어인 경우에는 cp932 또는 utf8mb4를 적용하는 것이 일반적이다.
- 최근의 웹 서비스나 스마트폰 애플리케이션은 여러 나라의 언어를 동시에 지원하기 위해 기본적으로 utf8mb4를 사용하는 추세다.
- MySQL 서버에서 사용 가능한 문자 집합은
SHOW CHARACTER SET명령으로 확인해 볼 수 있다.- latin 계열의 문자 집합은 알파벳이나 숫자, 그리고 키보드의 특수 문자로만 구성된 문자열만 저장해도 될 때 저장 공간을 절약하면서 사용할 수 있는 문자 집합이다.
- euckr은 한국어 전용으로 사용되는 문자 집합이며, 모든 글자는 1~2바이트를 사용한다.
- utf8mb4은 다국어 문자를 포함할 수 있는 컬럼에 사용하기에 적합하다. 컬럼의 문자 집합이 utf8mb4로 생성되면 일반적으로 디스크에 저장할 때는 한 글자를 저장하기 위해 1~4바이트까지 사용한다. 하지만 utf8mb4 문자 집합을 사용하는 문자열 값이 메모리에 기록될 때는 실제 문자열의 길이와 관계없이 문자당 4바이트로 공간이 할당되는 경우도 있다.
- utf8은 utf8mb4의 부분 집합인데, MySQL 서버에서 utf8mb4가 도입되기 전에 주로 사용됐다. utf8 문자 집합은 한 글자를 저장하기 위해 1~3바이트까지 사용한다. 한 글자를 저장하기 위한 공간이 최대 3바이트이기 때문에 utf8mb4보다는 저장할 수 있는 문자의 범위가 좁다.
SHOW CHARACTER SETㅁ여령의 결과에서 “Default collation” 컬럼에는 해당 문자 집합의 기본 콜레이션이 무엇인지 표시해준다.
클라이언트로부터 쿼리를 요청했을 때의 문자 집합 변환
- MySQL 서버는 클라이언트로부터 받은 메시지가
character_set_client에 지정된 문자 집합으로 인코딩돼 있다고 판단하고, 받은 문자열 데이터를character_set_connection에 정의된 문자 집합으로 변환한다. 
- 첫 번째 쿼리에서 “Matt” 문자열은
character_set_connection으로 문자 집합이 변환된 이후 처리될 것이다. - 두 번째 쿼리는 인트로듀서(
_latin1)가 사용됐으므로 “Matt” 문자열은character_set_connection이 아니라latin1문자 집합으로first_name컬럼의 값과 비교가 실행된다.
- 첫 번째 쿼리에서 “Matt” 문자열은
처리 결과를 클라이언트로 전송할 때의 문자 집합 변환
character_set_connection에 정의된 문자 집합으로 변환해 SQL을 실행한 다음, MySQL 서버는 쿼리의 결과를character_set_results변수에 설정된 문자 집합으로 변환해 클라이언트로 전송한다.- 변환 전 문자 집합과 변환해야 할 문자 집합이 똑같다면 별도의 문자 집합 변환 작업은 모두 생략한다.
- 예시1:
character_set_client와character_set_connection의 문자 집합이 똑같은 경우 - 예시2:
character_set_connection과character_set_results의 문자 집합이 똑같은 경우
- 예시1:
character_set_client,character_set_connection,character_set_results이라는 3개의 시스템 설정 변수는 동적 변수이다.

콜레이션(Collation)
- 콜레이션: 문자열 비교나 정렬 작업에서 영문 대소문자를 같은 것으로 처리할지, 아니면 더 크거나 작은 것으로 판단할지에 대한 규칙을 정의하는 것이다.
- 문자열 컬럼의 값을 비교하거나 정렬할 때는 항상 문자 집합뿐 아니라 콜레이션의 칠치 여부에 따라 겨로가가 달라지면, 쿼리의 성능 또한 상당한 영향을 받는다.
콜레이션 이해
- 테이블이나 컬럼에 문자 집합만 지정하면 해당 문자 집합의 디폴트 콜레이션이 해당 컬럼의 콜레이션으로 지정된다.
- 반대로 컬럼의 문자 집합은 지정하지 않고 콜레이션만 지정하면 해당 콜레이션이 소속된 문자 집합이 묵시적으로 그 컬럼의 문자 집합으로 사용된다.
SHOW COLLATION명령을 이용해 MySQL 서버에서 사용 가능한 콜레이션 목록을 확인할 수 있다.- 콜레이션 이름은 2개 또는 3개의 파트로 구분돼 있으며, 각 파트는 다음과 같은 의미로 사용된다.
- 3개의 파트로 구성된 콜레이션 이름(예:
utf8mb4_general_ci)- 첫 번째 파트는 문자 집합의 이름이다.
- 두 번째 파트는 해당 문자 집합의 하위 분류를 나타낸다.
- 세 번째 파트는 대문자나 소문자의 구분 여부를 나타낸다. “ci"이면 대소문자를 구분하지 않는 콜레이션(Case Insensitive)을 의미하며, “cs"이면 대소문자를 별도의 문자로 구분하는 콜레이션(Case Sensitive)이다.
- 2개의 파트로 구성된 콜레이션 이름(
utf8mb4_bin)- 첫 번째 파트는 문자 집합의 이름이다.
- 두 번째 파트는 항상 “bin"이라는 키워드를 가진다. 여기서 “bin"은 이진 데이터를 의미하며, 이진 데이터로 관리되는 문자열 컬럼은 별도의 콜레이션을 가지지 않는다. 따라서 비교 및 정렬은 실제 문자 데이터의 바이트 값을 기준으로 수행한다.
- 일반적으로 각 국가의 언어는 그 나라의 국멘에게 익숙한 순서대로 문자 코드 값이 부여돼 있으므로 대소문자를 구분할 때는 “bin” 계열의 콜레이션을 적용해도 특별히 문제되지는 않는다.
- 3개의 파트로 구성된 콜레이션 이름(예:
- 문자열 컬럼에서 문자 집합과 콜레이션이 모두 일치해야만 조인이나 WHERE 조건이 인덱스를 효율적으로 사용할 수 있다.
- 문자 집합이나 콜레이션이 다르다면 비교 작업에서 콜레이션 변환이 필요하기 때문에 인덱스를 효율적으로 이용하지 못할 때가 많으므로 주의해야 한다.
- “_ci” 콜레이션의 정렬 순서
- 대소문자 구분 없이 정렬된다.
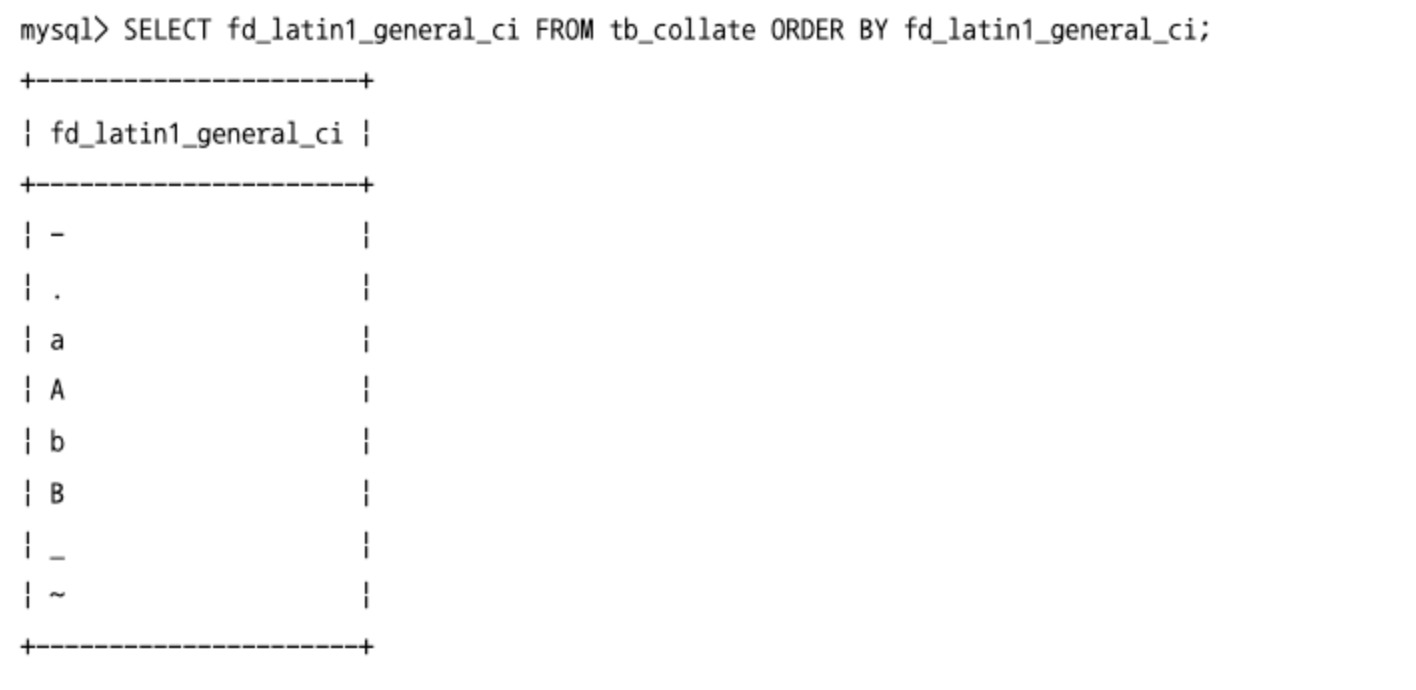
- “_cs” 콜레이션의 정렬 순서
- 대문자 ‘A’와 소문자 ‘a’는 모두 대문자 ‘B’보다 먼저 정렬된다.
- 같은 알파벳에서는 대문자가 소문자보다 먼저 정렬된다.

- “_bin” 콜레이션의 정렬 순서
- 대문자만 먼저 정렬되고 그당므으로 소문자가 정렬된다.

- latin1이 아니라 latin7 문자셋을 사용하면 특수문자가 알파벳보다 먼저 정렬된다.

utf8mb4 문자 집합의 콜레이션
- 다음 4개의 콜레이션은 utf8mb4 문자 집합의 콜레이션 중 하나다.
- UCA: Unicode Collation Algorithm. 유니코드 문자열 비교 알고리즘.

- 콜레이션의 이름에 locale이 포함돼 있는지 여부로 언어에 종속적은 콜레이션과 언어에 비종속적인 콜레이션으로 구분할 수 있다.
- UCA 9.0.0 버전의 콜레이션은 이전 버전보다 빠르다고 MySQL 매뉴얼에 소개되고 있지만, 실제로 테스트해보면 그렇지 않다. 성능 영향은 없는 것으로 보인다.
- UCA 9.0.0 콜레이션은 최신 정렬 순서를 반영하고 있으므로 새로운 서비스를 개발하고 있다면 이를 사용할 것을 권장한다.
- 하지만 MySQL 8.0 이전 버전에서 MySQL 8.0으로 업그레이드하는 경우 UCA 9.0.0 사용을 주의해야 한다.
- MySQL 5.7 버전에서는 utf8mb4 기본 콜레이션이 “utf8mb4_general_ci” 였는데 MySQL 8.0 버전부터는 utf8mb4 문자 집합의 기본 콜레이션이 “utf8mb4_0900_ai_ci"로 변경됐다.
- 서로 다른 버전에서 생성한 테이블을 조인할 때는 콜레이션이 달라서 에러가 발생하거나 성능이 심각하게 떨어질 수 있다.
default_collation_for_utf8mb4시스템 변수로 기본 콜레이션을 변경할 수 있다.- 또한 JDBC 드라이버의 연결 문자열에서 connectionCollation 파라미터를 설정할 수도 있다.


비교 방식
CHAR와VARCHAR타입 둘 다 대부분의 콜레이션에서 문자열을 비교할 때, 문자열 뒤에 공백 문자를 붙여서 두 문자열의 길이를 동일하게 만든 후 비교를 수행한다.- 하지만
utf8mb4문자 집합에서 UCA 버전 9.0.0 부터는 공백이 비교 결과에 영향을 미친다.utfmb4_bin콜레이션은 문자열 뒤 공백이 비교에 영향을 주지 않지만,utf8mb4_0900_bin은 영향을 준다.
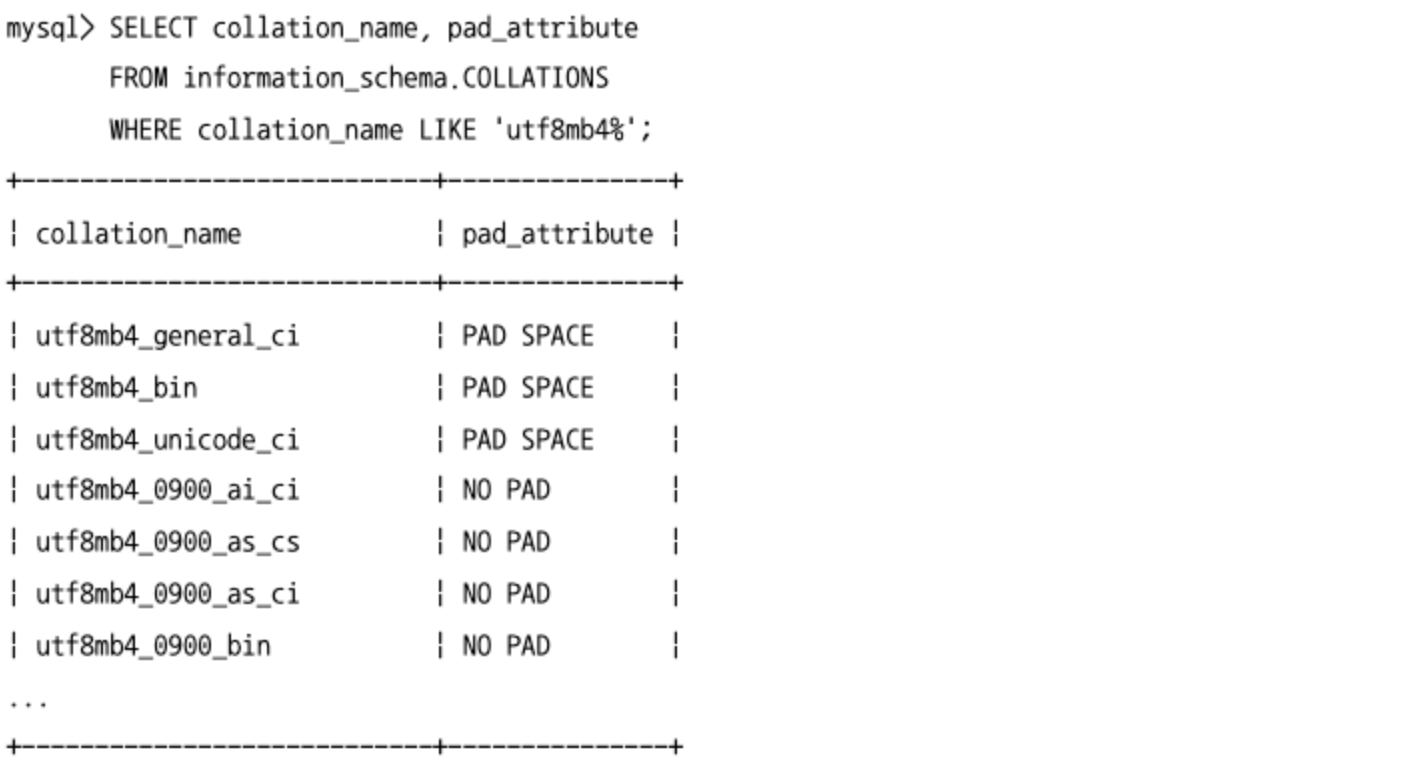
- 해당 콜레이션이 문자열 뒤 공백의 영향을 받는지 확인해야된다면
information_schema데이터베이스의COLLATIONS뷰에서PAD_ATTRIBUTE컬럼으로 판단할 수 있다. LIKE를 이용한 문자열 패턴 비교에서는 공백 문자는 항상 유효 문자로 취급 된다.


문자열 이스케이프 처리
- 마지막의 “\%“와 “\_“는 LIKE를 사용하는 패턴 검색 쿼리의 검색에서만 사용할 수 있다.
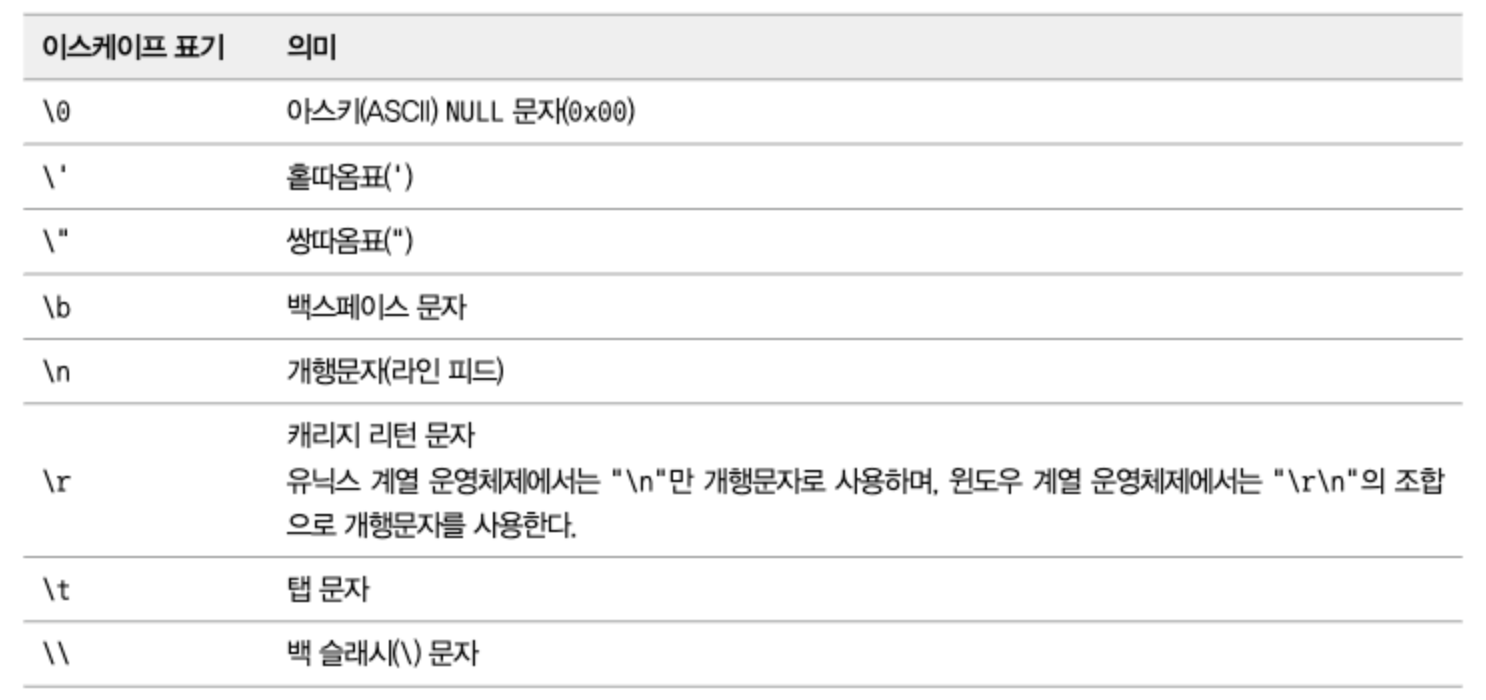
- MySQL에서는 홑따옴표나 쌍따옴표를 두 번 연속으로 표기해 이스케이프 처리할 수도 있다.

숫자
- 숫자를 저장하는 타입은 값의 정확도에 따라 크게 참값(exact value)과 근삿값 타입으로 나눌 수 있다.
- 참값: 소수점 이하 값의 유무와 관계없이 정확히 그 값을 그대로 유지하는 것을 의미한다. 참값을 관리하는 데이터 타입으로는 INTEGER를 포함해 INT로 끝나는 타입과 DECIMAL이 있다.
- 근삿값: 부동 소수점이라고 불리는 값을 의미한다. FLOAT와 DOUBLE이 있다.
- 저장되는 포맷에 따라 십진 표기법과 이진 표기법으로 나눌 수 있다.
- 이진 표기법: 흔히 프로그래밍 언어에서 사용하는 정수나 실수 타입. INTEGER나 BIGINT 등의 대부분 숫자 타입은 모두 이진 표기법을 사용한다.
- 십진 표기법: 숫자 값의 각 자리값을 표현하기 위해서 4비트나 한 바이트를 사용해서 표기하는 방법. MySQL에서 십진 표기법을 사용하는 타입은 DECIMAL 뿐이며, DECIMAL 타입은 금액처럼 정확하게 소수점꺼지 관리돼야 하는 값을 저장할 때 사용한다. 또한 DCIMAL 타입은 65자리 숫자까지 표현할 수 있으므로 BIGINT로도 저장할 수 없는 값을 저장할 때 사용한다.
- 근삿값을 저장할 때와 조회할 때의 값이 정확히 일치하지 않기 때문에, STATEMENT 포맷을 사용하는 복제에서는 소스 서버와 레플리카 서버 간 데이터 차이가 발생할 수도 있다.
- 십진 표기법을 사용하는 DECIMAL 타입은 이진 표기법을 사용하는 타입보다 2배의 저장 공간이 필요하다.
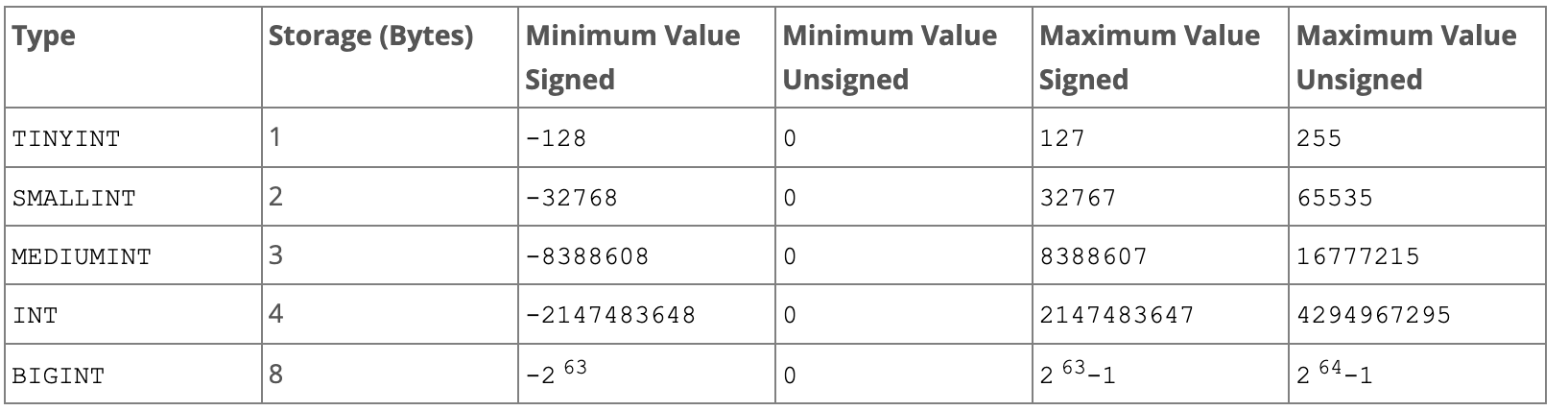
정수
- 정수 값을 위한 타입은 저장 가능한 숫자 값의 범위만 다를 뿐 다른 차이는 없다.
- UNSIGNED 옵션은 조인할 때 인덱스의 사용 여부까지 영향을 미치지 않는다.
- 하지만 서로 저장되는 값의 범위가 다르므로 외래 키로 사용하는 컬럼이나 조인의 조건이 되는 컬럼은 SIGNED나 UNSIGNED 옵션을 일치시키는 것이 좋다.
부동 소수점
- 부동 소수점은 근삿값을 저장하는 방식이라서 동등 비교는 사용할 수 없다.
- 이 밖에도 MySQL 매뉴얼을 살펴보면 부동 소수점을 사용할 때 주의할 내용이 많이 있으므로 사용하기 전에 반드시 참조할 것을 권장한다.

- FLOAT는 일반적으로 정밀도를 표시하지 않으면 4바이트를 사용해 유효 자리수를 8개까지 유지하며, 정밀도가 명시된 경우 최대 8바이트까지 저장 공간을 사용할 수 있다.
- DOUBLE의 경우 8바이트의 저장 공간을 필요로 하며 최대 유효 자릿수를 16개까지 유지할 수 있다.
- 부동 소수점 값을 저장해야 한다면 유효 소수점의 자릿수만큼 10을 곱해서 정수로 만들어 그 값을 정수 타입의 컬럼에 저장하는 방법도 생각해볼 수 있다.
DECIMAL
- 고정 소수점 타입을 위해 DECIMAL 타입을 사용할 수 있다.
- 소수점 이하의 값까지 정확하기 관리하기 위해 사용한다.
- DECIMAL 타입은 (숫자의 자릿수)/2 만큼의 바이트 수가 필요하다.
- 곱하는 연산은 DECIMAL보다는 BIGINT 타입이 더 빠르다.
- 결론적으로 단순히 정수를 관리하고자 한다면 INTEGER나 BIGINT를 사용하는 것이 좋다.
정수 타입의 컬럼을 생성할 때의 주의사항
DECIMAL(20, 5): 정수부를 15자리까지, 소수부를 5자리까지 저장할 수 있는 DECIMALDECIMAL(20): 정수부만 20자리까지 저장- FLOAT나 DOUBLE은 정밀도를 저장해도 저장 공간의 크기가 바뀌지는 않지만, DECIMAL의 정밀도는 저장 공간의 크기에 영향을 준다.
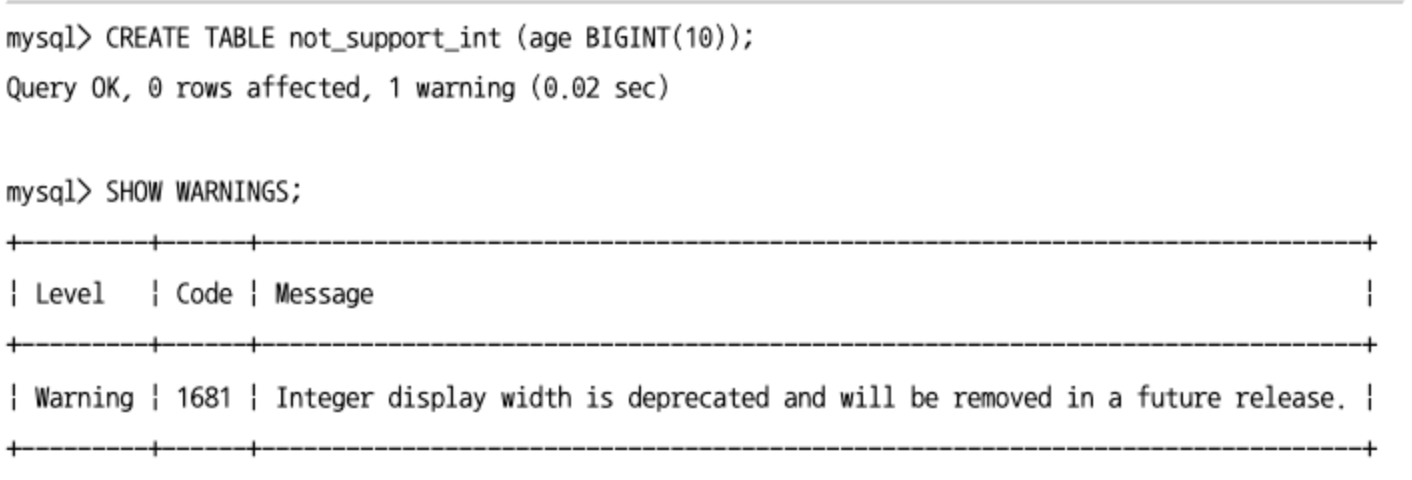
BIGINT(10)과 같이 정수 타입 뒤에 명시되는 괄호는 화면에 표시할 자릿수를 의미할 뿐 저장 가능한 값을 제한하는 용도가 아니다.- MySQL 8.0부터는 이런 오해를 없애기 위해서 정수 타입에 괄호를 deprecated되어 무시한다.
자동 증가(AUTO_INCREMENT) 옵션 사용
auto_increment_increment와auto_increment_offset시스템 설정을 이용해 자동 증가값 설정을 변경할 수 잇다.auto_increment_offset을 5로,auto_increment_increment를 10으로 변경하면 자동 생성되는 값을 5, 15, 25, 35, … 와 같이 증가한다.
AUTO_INCREMENT옵션을 사용한 컬럼은 반드시 그 테이블에서 프라이머리 키나 유니크의 일부로 정의해야 한다.- 그런데 프라이머리 키나 유니크 키가 여러 개의 컬럼으로 구성되면, InnoDB 스토리지 엔진 기준으로
AUTO_INCREMENT컬럼을 프라이머리 키나 유니크 키의 시작에 존재하도록 생성해야 된다. 
- 그런데 프라이머리 키나 유니크 키가 여러 개의 컬럼으로 구성되면, InnoDB 스토리지 엔진 기준으로
- AUTO INCREMENT 컬럼의 현재 증가 값은 테이블의 메타 정보에 저장돼 있는데, 다음 증가 값이 얼마인지는
SHOW CREATE TABLE명령으로 조회할 수 있다.
날짜와 시간
날짜만 저장하거나 시간만 따로 저장할 수도 있으며, 날짜와 시간을 합쳐서 하나의 칼럼에 저장할 수 있게 여러 가지 타입을 지원한다.
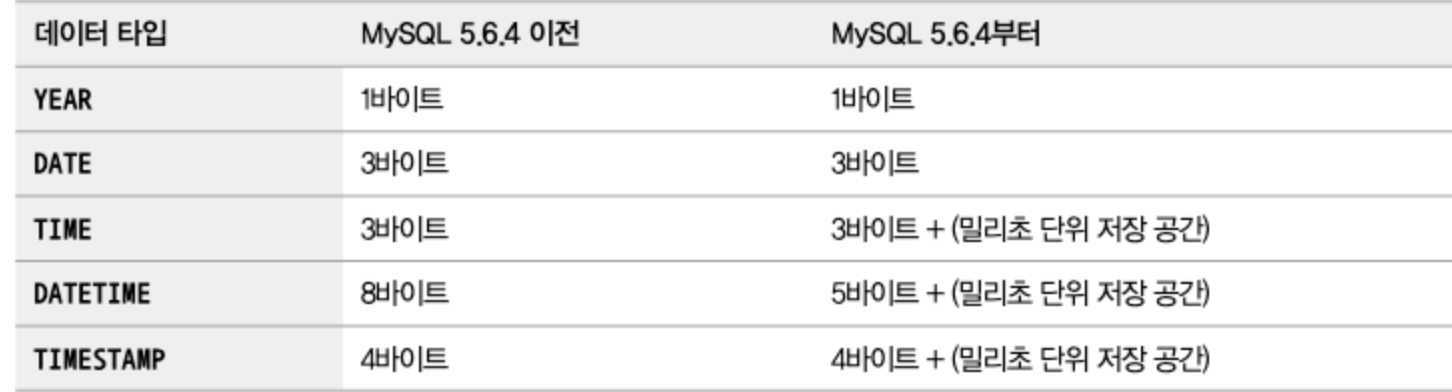
MySQL 5.6버전부터는 TIME 타입과 DATETIME, TIMESTAMP 타입은 밀리초 단위의 데이터를 저장할 수 있게 됐다.
- 밀리초 단위는 2자리당 1바이트씩 공간이 더 필요하다.
MySQL 8.0에서는 마이크로초 까지 저장가능한 DATETIME(6) 타입은 8바이트(5바이트 + 3바이트)를 사용한다.
밀리초 단위로 데이터를 저장하기 위해서는 DATETIME이나 TIME, TIMESTAMP 타입 뒤에 괄호와 함께 숫자를 표기하면 된다.
NOW()함수를 이용해 현재 시간을 가져올 때도NOW(6)또는NOW(3)과 같이 가져올 밀리초의 자리수를 명시해야 한다.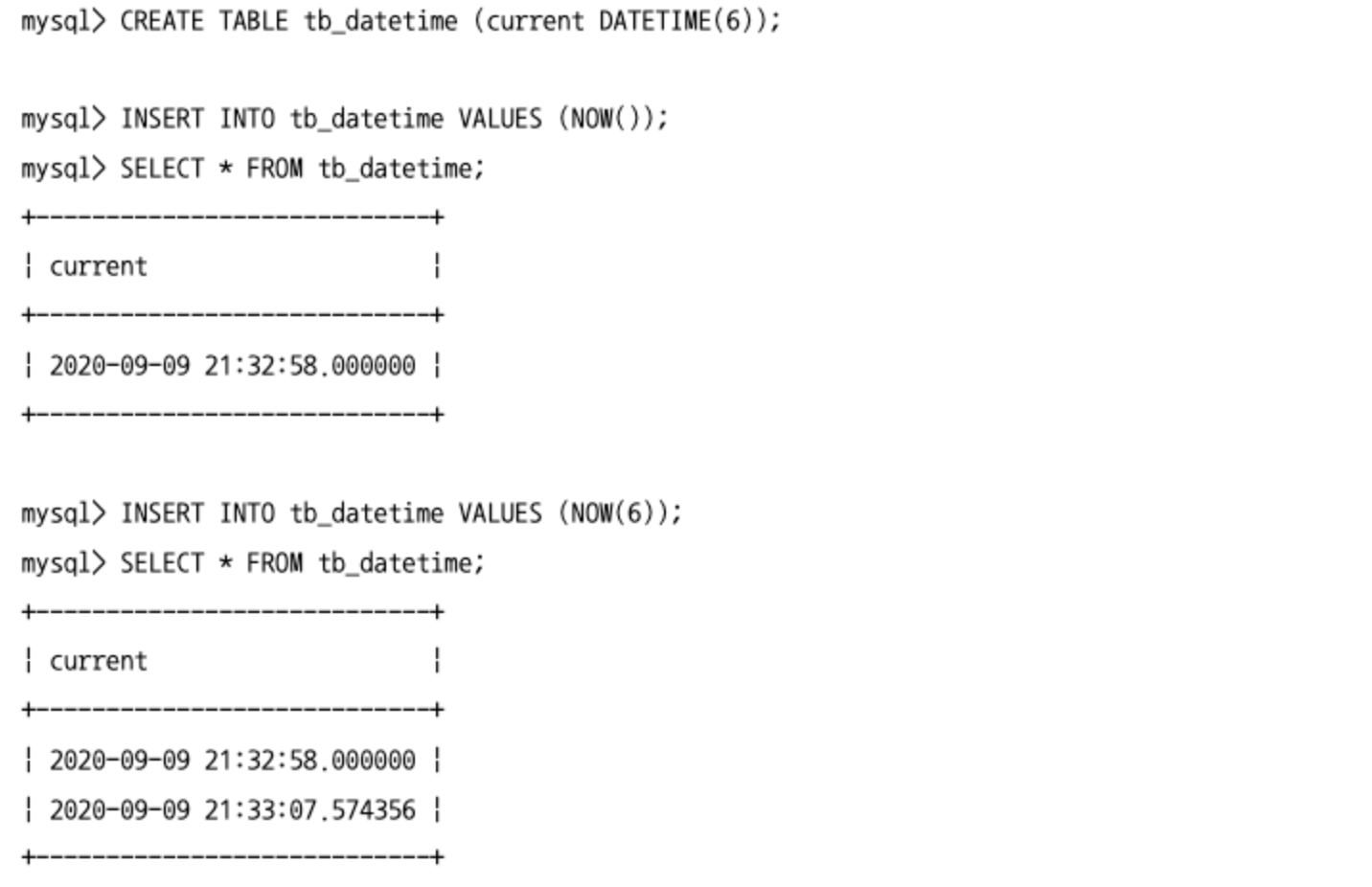
DATETIME이나 DATE 타입은 현재 DBMS 커넥션의 타임존과 관계없이 클라이언트로부터 입력된 값을 그대로 저장하고 조회할 때도 변환 없이 그대로 출력한다.
하지만 TIMESTAMP는 항상 UTC 타임존으로 저장되므로 타임존이 달라져도 값이 자동으로 보정된다.
- TIMESTAMP 컬럼의 값은 현재 클라이언트의 타임존에 맞게 변환되지만, DATETIME에 저장된 날짜와 시간 정보는 클라이언트의 타임존을 변경해도 차이가 생기지 않는다.
- TIMESTAMP는 항상 UTC로 저장되고, 출력할 때 클라이언트의 타임존에 맞게 변환한다.

MySQL 서버의 기본 타임존 시스템 변수
system_time_zone: MySQL 서버의 타임존을 의미하며, 일반적으로 이 값은 운영체제의 타임존을 그대로 상속받는다.time_zone: MySQL 서버로 연결하는 모든 클라이언트 커넥션의 기본 타임존. 아무 것도 설정하지 않으면 “SYSTEM"으로 설정되고 이는system_time_zone시스템 변수 값을 그대로 사용한다는 의미다.NOW()함수 등은time_zone시스템 변수의 영향을 받는다.

자동 업데이트
- 테이블에 레코드가
INSERT,UPDATE가 실행될 때마다 해당 시점으로 자동 업데이트 해주는 옵션이 존재한다.DEFAULT CURRENT_TIMESTAMP: INSERT 될 때의 시점을 자동으로 업데이트ON DUPATE CURRENT_TIMESTAMP: UPDATE 될 때의 시점을 자동으로 업데이트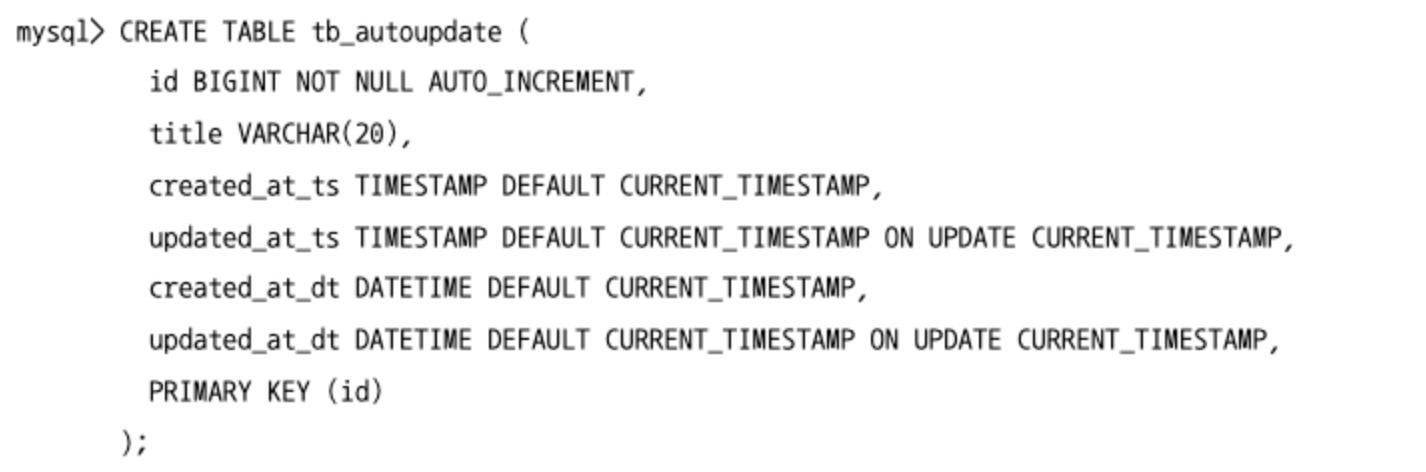
- MySQL 5.6 이전 버전까지는 TIMESTAMP 타입만 위 옵션들을 지원했는데, MySQL 5.6 버전부터는 DATETIME 도 지원한다.
ENUM과 SET
ENUM
- ENUM 타입은 테이블의 구조(메타 데이터)에 나열된 목록 중 하나의 값을 가질 수 있다.
- ENUM 타입은 INSERT나 UPDATE, SELECT 등의 쿼리에서 CHAR나 VARCHAR 문자열처럼 비교하거나 저장할 수 있다.
- 하지만 MySQL 서버가 실제로 값을 디스크나 메모리에 저장할 때는 사용자로부터 요청된 무낮열이 아니라 그 값에 매핑된 정숫값을 사용한다.


- ENUM 타입에 사용할 수 있는 최대 아이템 개수는 63,535개이며, 아이템의 개수가 255개 미만임녀 ENUM 타입은 저장 공간으로 1바이트를 사용하고, 그 이상인 경우에는 2바이트까지 사용한다.
- ENUM 타입을 사용할 때 특정 문자열이 어떤 정숫값으로 매핑됐는지 알 필요가 없지만, 필요하다면 1을 곱한다거나 0을 더하는 산술 연산으로 확인할 수 있다.
- ENUM 타입에 맾이되는 정숫값은 일반적으로 테이블 정의에 나열된 문자열 순서대로 1부터 할당되며, 빈 문자열(”")은 항상 0으로 매핑된다.

- ENUM 타입의 가장 큰 단점은 컬럼에 저장되는 문자열 값이 메타 정보가 되면서 ENUM 타입에 새로운 값을 추가해야 한다면 테이블의 구조를 변경해야 한다.
- MySQL 5.6 버전 이후 기준으로는 ENUM 타입의 제일 마지막에 추가하는 작업은 INSTANT 알고리즘으로 메타데이터 변경만으로 완료가 된다.
- MySQL 5.6 버전 이후 기준으로는 ENUM 타입의 중간에 새로운 아이템을 추가하는 작업은 COPY 알고리즘에 읽기 잠금까지 필요하다.
- ENUM 타입은 정렬할 때 매핑된 코드 값 기준으로 정렬된다.
- 만약 문자열 값을 기준으로 정렬하고 싶다면,
CAST()함수를 이용해야되지만, 인덱스를 이용할 수는 없으므로 주의해야 한다. 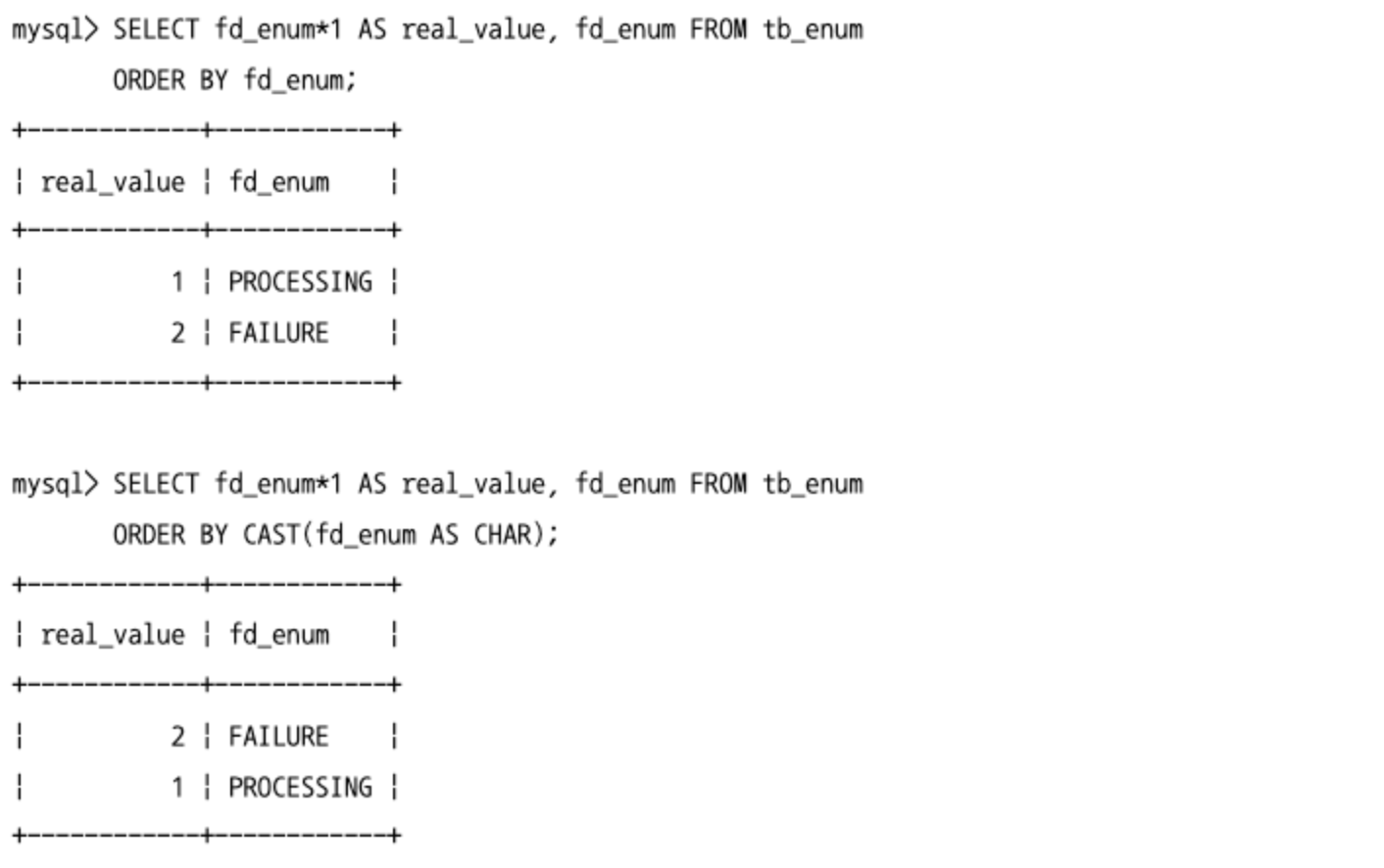
- 만약 문자열 값을 기준으로 정렬하고 싶다면,
- ENUM 타입의 가장 큰 장점은 데이터베이스 서버의 디스크 저장 공간의 크기를 줄여준다.
SET
- SET 타입도 테이블의 구조에 정의된 아이템을 정숫값으로 매핑해서 저장하는 방식이다.
- SET은 하나의 컬럼에 1개 이상의 값을 저장할 수 있다.
- 내부적으로 BIT-OR 연산을 거쳐 1개 이상의 값을 저장할 수 있다.
- SET 타입의 아이템 값의 멤버 수가 8개 이하이면 1바이트의 저장 공간을 사용하며, 9개에서 16개 이하이면 2바이트를 사용하고 똑같은 방식으로 최대 8바이트까지 저장 공간을 사용한다.
- 특정 문자열 멤버를 가진 레코드를 검색하려면
FIND_IN_SET()함수나LIKE검색을 이용할 수 있다.- 하지만 이는 인덱스를 사용할 수 없다. 인덱스를 사용해야된다면
SET을 사용하지않고 테이블 정규화로 자식 테이블을 생성하는 것이 좋다. 
- 하지만 이는 인덱스를 사용할 수 없다. 인덱스를 사용해야된다면
- 동등 비교를 수행하려면 컬럼에 저장된 순서대로 문자열을 나열해야만 검색할 수 있다.
- 동등 비교는 인덱스를 사용할 수 있다.

- ENUM과 마찬가지로 SET 타입 또한 아이템 중간에 새로운 아이템을 추가하는 경우 테이블의 읽기 잠금과 리빌드 작업이 필요하다.
- 마지막에 새로운 아이템을 추가하는 작업은 INSTANT 알고리즘으로 메타 정보만 변경하고 즉시 완료된다.
- SET 타입의 아이템 개수가 8개를 넘어서 9개로 바뀔 때는 읽기 잠금과 테이블 리빌드 작업이 필요하다. 저장 공간이 1바이트에서 2바이트로 변경돼야 하기 때문이다.

TEXT와 BLOB
- 대량의 데이터를 저장하려면 TEXT나 BLOB 타입을 사용해야 한다.
- TEXT타입은 문자열을 저장하는 대용량 컬럼이라서 문자 집합이나 콜레이션을 가진다는 것이고, BLOB 타입은 이진 데이터 타입이라서 별도의 문자 집합이나 콜레이션을 가지지 않는다는 것이다.
- MySQL 버전에 따라 조금씩 차이는 있지만 일반적으로 하나의 레코드는 전체 크기가 64KB를 넘어설 수 없다. 레코드의 전체 크기가 64KB를 넘어서서 더 큰 컬럼을 추가할 수 없다면 일부 컬럼을 TEXT나 BLOB 타입으로 전환해야 한다.
- MySQL에서 인덱스 레코드의 모든 컬럼은 최대 제한 크기를 가지고 있다. 최대 제한 크기를 넘어서는 인덱스는 생성할 수 없다.
- COMPACT 로우 포맷(InnoDB): 767바이트
- DYNAMIC 또는 COMPRESSED 로우 포맷(InnoDB): 3072바이트
- 쿼리 특성에 따라 임시 테이블을 생성할 때가 있는데, 임시 테입르은 메모리에 저장될 수도 있고 디스크에 저장될 수도 있다.
- 임시 테이블을 메모리에 저장할 때는
internal_tmp_mem_storage_engine시스템 변수에 따라 MEMORY 스토리지 엔진이나 TempTable 스토리지 엔진 중 하나를 사용한다. - MySQL 8.0 버전부터 TempTable은 TEXT나 BLOB 타입을 지원하지만 MEMORY 스토리지 엔진은 TEXT나 BLOB을 지원하지 않는다.
- 가능하면
internal_tmp_mem_storage_engine은 “TempTable"로 설정해서 BLOB 타입이나 TEXT 타입을 포함하는 결과도 메모리를 사용할 수 있게 하는 것이 좋다.
- 임시 테이블을 메모리에 저장할 때는
- BLOB이나 TEXT 타입의 컬럼이 포함된 테이블에 INSERT나 UPDATE 할 때는 쿼리가 매우 길어질 수 있는데,
max_allowed_packet시스템 변수에 설정된 값보다 큰 쿼리는 MySQL 서버로 전송되지 못하고 오류가 발생할 수 있다. 해당 시스템 변수를 충분히 늘려서 사용해야 한다. - TEXT와 BLOB 타입이 실제로 저장되는 방식은
ROW_FORMAT옵션에 결정된다.- 별도로 지정하지 않으면
innodb_default_row_format시스템 변수에 설정된 값을 사용하고 5.7 버전부터는 기본으로DYNAMIC이 설정되어 있다. - 사용 가능한 ROW_FORMAT:
REDUNDANT,COMPACT,DYNAMIC,COMPRESSED COMPACT포맷은 나머지 모든 ROW_FORMAT의 바탕이 된다.
- 별도로 지정하지 않으면
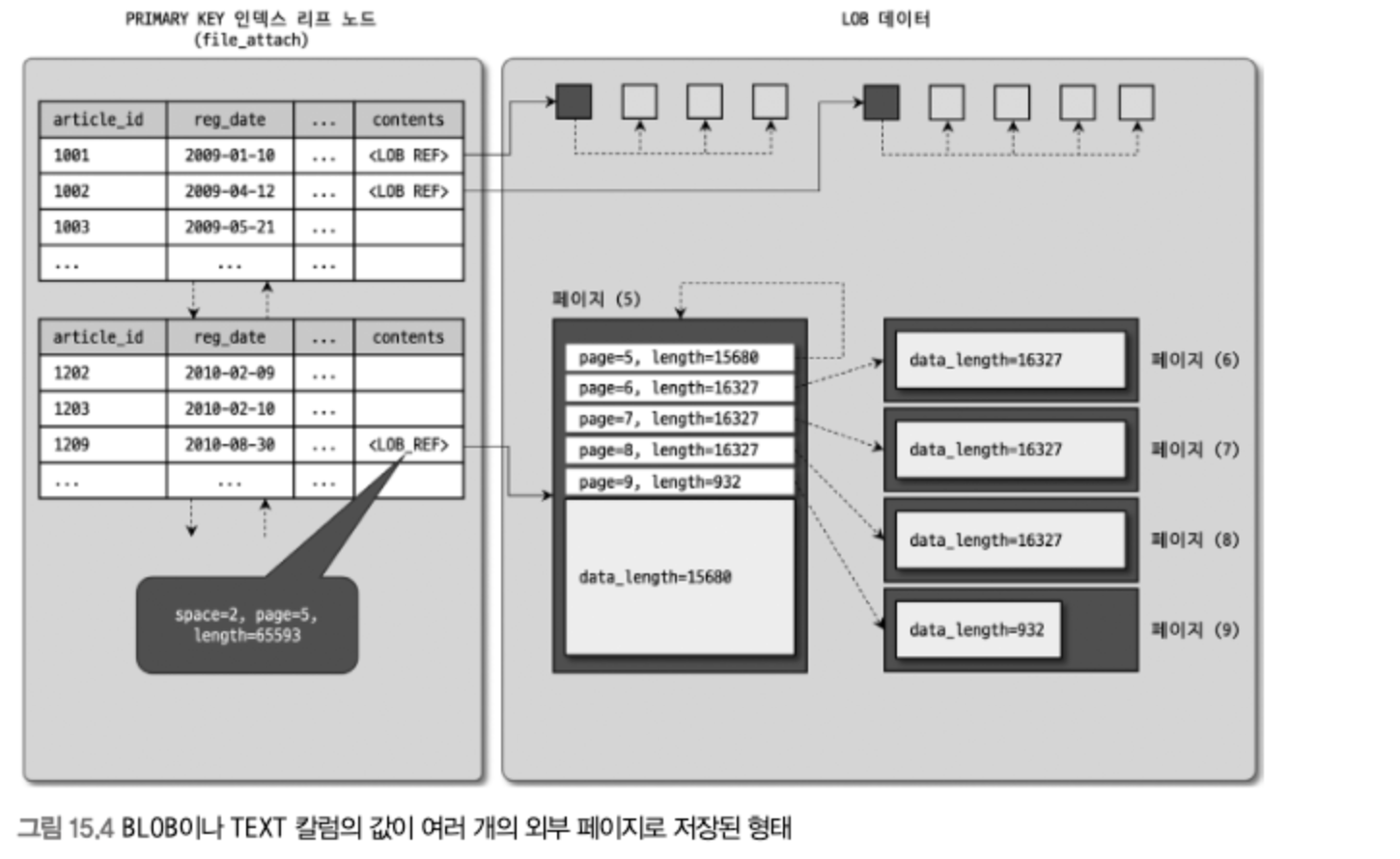
COMPACT포맷의 저장 방식COMPACT포맷에서 저장할 수 있는 레코드 하나의 최대 길이는 데이터 최대 길이는 8126바이트다.- BLOB이나 TEXT 타입의 컬럼은 가능한 레코드에 같이 저장하려고 하고, 8126바이트를 넘어선다면 큰 컬럼 순서대로 외부 페이지로 옮기면서 레코드의 크기를 8126바이트 이하로 맞추려고 한다.

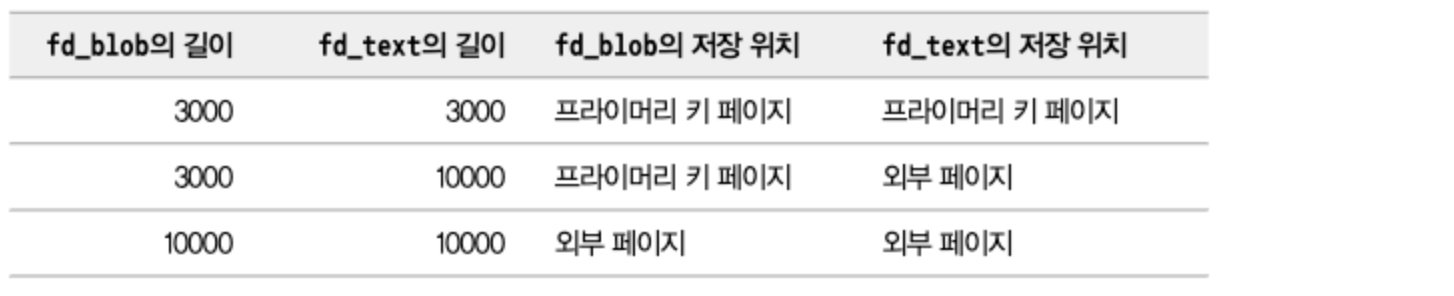
- 외부 페이지에 저장될 때 길이가 16KB를 넘는 경우 MySQL 서버는 값을 잘라서 여러 개의 외부 페이지에 저장하고 체인으로 연결한다.
COMPACT와REDUNDANT레코드 포맷을 사용하는 테이블에서는 외부 페이지로 저장된 TEXT나 BLOB 컬럼의 앞쪽 768바이트(BLOB 프리픽스)만 잘라서 프라이머리 키 페이지에 같이 저장한다.DYNAMIC이나COMPRESSED레코드 포맷에서는 프라이머리 키 페이지에 이런 BLOB 프리픽스를 저장하지 않는다.- BLOB 프리픽스는 인덱스를 생성할 때 도움이 되기도 하지만 테이블의 저장 효율을 낮추게 될 수 있다.
- 프라이머리 키 페이지에 저장할 수 있는 레코드의 건수를 줄인다.
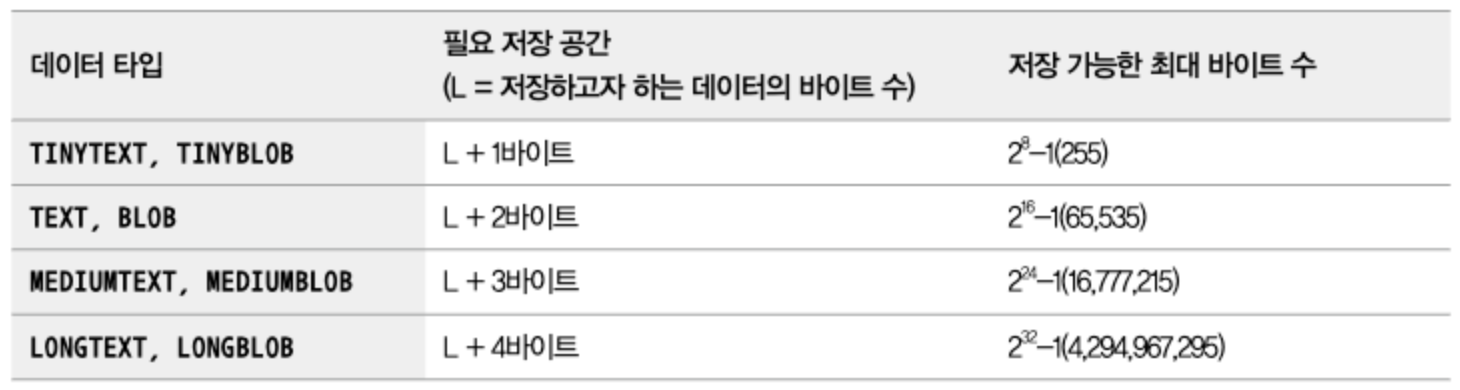
가상 컬럼(파생 컬럼)
- MySQL 파생 컬럼은 가상 컬럼(Virtual Column)과 스토어드 컬럼(Stored Column)으로 구분할 수 있다.
- 가상 컬럼과 스토어드 컬럼 모두 컬럼 뒤에 “AS” 절로 계산식을 정의한다.
VIRTUAL이나STORED키워드가 정의되지 않으면 기본 모드인VIRTUAL로 컬럼을 생성한다.
- 파생 컬럼은 입력이 동일함녀 시점과 관계 없이 결과가 항상 동일한(DETERMINISTIC) 표현식만 사용할 수 있다.
- 가상 컬럼(Virtual Column)
- 컬럼의 값이 디스크에 저장되지 않음
- 컬럼의 구조 변경은 테이블 리빌드를 필요로 하지 않음
- 컬럼의 값은 레코드가 읽히기 전 또는 BEFORE 트리거 실행 직후에 계산되어 만들어짐
- 스토어드 컬럼(Stored Column)
- 컬럼의 값이 물리적으로 디스크에 저장됨
- 컬럼의 구조 변경은 다른 일반 테이블과 같이 필요 시 테이블 리빌드 방식으로 처리됨
- INSERT와 UPDATE 시점에만 컬럼의 값이 계산됨
- 예외적으로, 가상 컬럼에 인덱스를 생성하게 되면 인덱스에 계산된 값이 저장된다.
- MySQL 8.0 버전부터 도입된 함수 기반의 인덱스도 가상 컬럼에 인덱스를 생성하는 방식으로 동작한다.
- 이 경우에는 테이블 조회시 가상 컬럼이 결과에 포함되지는 않는다.
- MySQL 8.0 버전부터 도입된 함수 기반의 인덱스도 가상 컬럼에 인덱스를 생성하는 방식으로 동작한다.
- CPU 사용량을 높여서 디스크 부하를 낮추고 싶다면 가상 컬럼을, 디스크 사용량을 높여서 CPU 사용량을 낮추고 싶다면 스토어드 컬럼을 사용하는 것이 좋다.
- 가상 컬럼은 조회 시점에 매번 계산되기 때문이다.