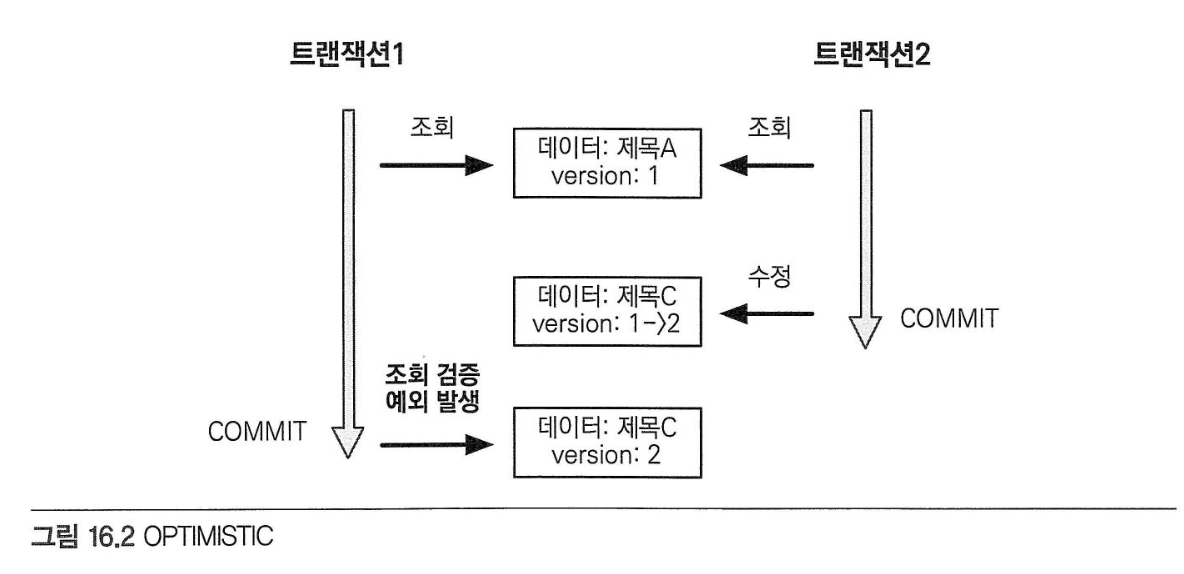
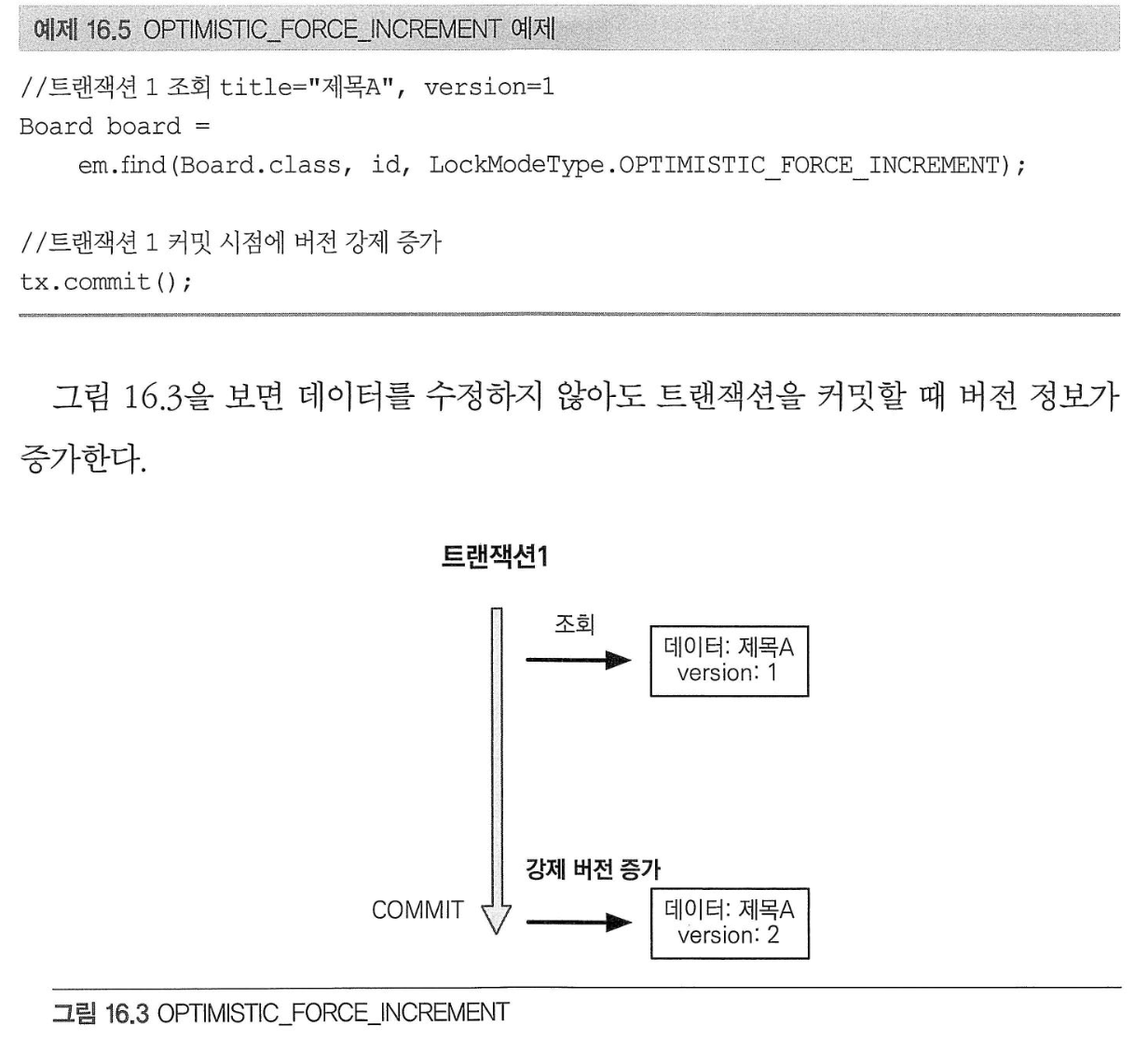
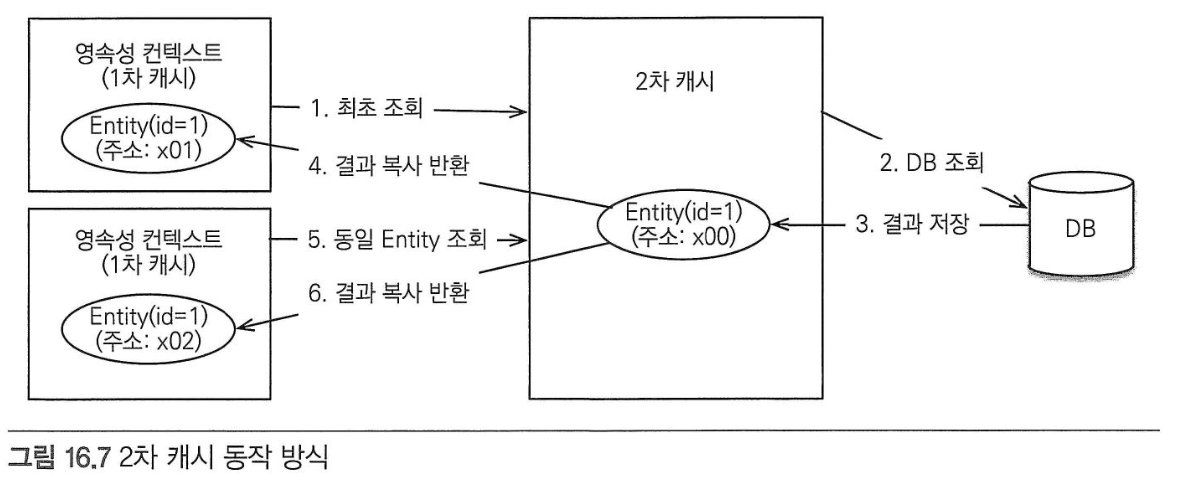
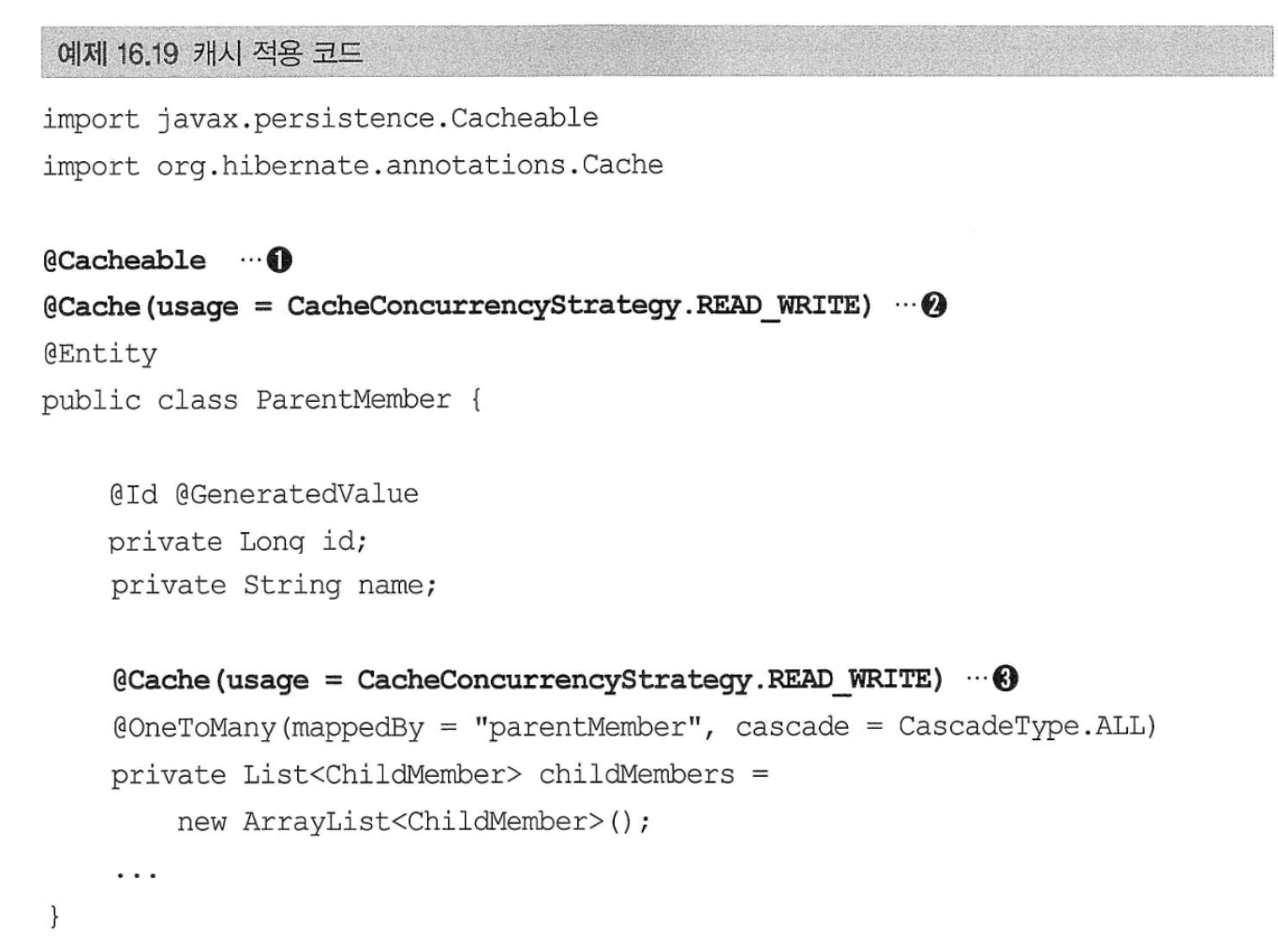
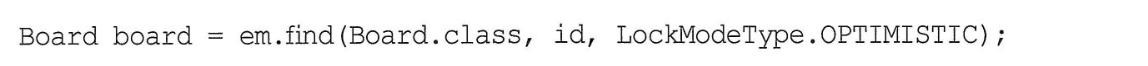트랜잭션과 락# 트랜잭션과 격리 수준# 트랜잭션 특성원자성: 트랜잭션 내에 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공하든가 모두 실패해야 한다. 일관성: 모든 트랜잭션은 일관성 있는 데이터베이스 상태를 유지해야 한다. 격리성: 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리한다. 지속성: 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 한다. 트랜잭션은 원자성, 일관성, 지속성을 보장한다. 문제는 격리성인데 트랜잭션 간에 격리성을 완벽히 보장하려면 트랜잭션을 거의 차례대로 실행해야 한다.이렇게하면 동시성 처리 성능이 매우 나빠진다. 이러한 문제로 인해 ANSI 표준은 트랜잭션의 격리 수준을 4단계로 나누어 정의했다. 낙관적 락과 비관적 락 기초# JPA의 영속성 컨텍스트(1차 캐시)를 적절히 활용하면 데이터베이스 트랜잭션이 READ COMMITED 격리 수준이어도 애플리케이션 레벨에서 REPEATABLE READ가 가능하다. JPA는 데이터베이스 트랜잭션 격리 수준을 READ COMMITED 정도로 가정한다. 일부 로직에서 더 높은 격리 수준을 필요하면 낙관적 락과 비관적 락 중 하나를 사용하면 된다.낙관적 락: 트랜잭션 대부분은 충돌이 발생하지 않는다고 낙관적으로 가정하는 방법.이것은 데이터베이스가 제공하는 락을 사용하는 것이 아니라 JPA가 제공하는 버전관리 기능을 사용한다. 낙관적 락은 트랜잭션을 커밋하기 전까지는 트랜잭션의 충돌을 알 수 없는 특징이 있다. 비관적 락: 트랜잭션의 충돌이 발생한다고 가정하고 우선 락을 걸고 보는 방법.데이터베이스가 제공한느 락 기능을 사용한다. 대표적으로 select for update 구문이 있다. 여기서 추가로 데이터베이스 트랜잭션 범위를 넘어서는 문제도 있다.두 번의 갱신 분실 문제: 사용자 A와 B가 동시에 제목이 같은 공지사항을 수정하는 경우 두 번의 갱신 분실 문제는 3가지 선택 방법이 있다.마지막 커밋만 인정하기 최초 커밋만 인정하기 충돌하는 갱신 내용 병합하기: 애플리케이션 개발자가 직접 사용자를 위해 병합 방법을 제공해야 한다. @Version# @Version 적용 가능 타입: Long(long), Integer(int), Short(short), Timestamp엔티티를 수정할 때 마다 버전이 하나씩 자동으로 증가한다. 엔티티를 수정할 때 조회 시점의 버전과 수정 시점의 버전이 다르면 예외가 발생하여 최초 커밋만 인정하기가 적용된다. 버전을 사용하는 엔티티면 UPDATE 쿼리에 엔티티의 버전 정보를 추가한다.값 타입인 임베디드 타입과 값 타임 컬렉션은 논리적인 개념상 해당 엔티티의 값이므로 수정하면 엔티티의 버전이 증가한다. 연관관계 필드는 외래 키를 관리하는 연관관계의 주인 필드를 수정할 때만 버전이 증가한다. @Version으로 추가한 버전 관리 필드는 JPA가 직접 관리하므로 개발자가 임의로 수정하면 안 된다.벌크 연산은 버전을 증가시키지 않아 버전 필드를 강제로 증가시켜야 한다. JPA 락 사용# JPA를 사용할 떄 추천하는 전략은 READ COMMITED 트랜잭션 격리 수준 + 낙관적 버전 관리다. 락은 다음 위치에 전용할 수 있다.EntityManager.lock(), EntityManager.find(), EntityManager.refresh()Query.setLockMode()@NameQuery JPA가 제공하는 락 옵션은 아래와 같이 정의되어 있다. JPA 낙관적 락# 낙관적 락은 버전을 사용한다. 낙관적 락에서 발생하는 예외는 다음과 같다.OptimisticLockException(JPA 예외)StaleObjectStateException(하이버네이트 예외)ObjectOptimisticLockingFailureException(스프링 예외 추상화) 락 옵션없이 @Version만 있어도 낙관적 락이 적용되지만, 락 옵션을 사용하면 더 세밀하게 제어할 수 있다. NONE 옵션해당 옵션을 걸어도(락을 걸지 않아도) @Version이 적용된 필드만 있으면 낙관적 락이 적용된다. 용도: 조회 시점부터 수정 시점까지 보장이 필요한 경우 동작: 엔티티를 수정할 때 버전을 체크하면서 버전을 중가한다(UPDATE 쿼리 사용). 이때 데이터베이스의 버전 값이 현재 버전이 아니면 예외가 발생한다. 이점: 두 번의 갱신 분실 문제를 예방한다. OPTISMIC 옵션용도: 조회한 엔티티는 트랜잭션이 끝날 때까지 다른 트랜잭션에 의해 변경되지 않아야 한다. 조회 시점부터 트랜잭션이 끝날 때까지 다른 트랜잭션에 의해 변경되지 않음을 보장한다. 동작: 트랜잭션을 커밋할 때 버전 정보를 조회해서 현재 엔티티의 버전과 같은지 검증한다. 만약 같지 않으면 예외가 발생한다. 이점: OPTIMISTIC 옵션은 DIRTY READ와 NONE-REPEATABLE READ를 방지한다. OPTIISTIC_FOR_INCREMENT 옵션용도: 논리적인 단위의 엔티티 묶음을 관리할 수 있다. 예를 들어 게시물과 첨부파일이 일대다, 다대일 양방향 연관관계이고 첨부파일이 연관관계 준인이다. 게시물을 수정하는 데 단순히 첨부파일만 추가하면 게시물의 버전은 증가하지 않는다. 해당 게시물은 물리적으로는 변경되지 않지만, 논리적으로는 변경되었다. 이때 게시물의 버전도 강제로 증가하려면 OPTIMISTIC_FORCE_INCRENMENT를 사용하면 된다. 동작: 엔티티를 수정하지 않아도 트랜잭션을 커밋할 때 UPDATE 쿼리를 사용해서 버전의 정보를 강제로 증가시킨다. 이떄 데이터베이스의 버전이 엔티티의 버전과 다르면 예외가 발생한다. 추가로 엔티티를 수정하면 숮어 시 버전 UPDATE가 발생한다. 따라서 총 2번의 버전 증가가 나탄라 수 있다. 이점: 강제로 버전을 증가해서 논리적인 단위의 엔티티 묶음의 버전 관리할 수 있다. Aggregate Root에 사용할 수 있다. 예를 들어 Aggregate Root는 수정하지 않았지만 Aggregate Root가 관리하는 엔티티를 수정했을 때 Aggregate Root의 버전을 강제로 증가시킬 수 있다. JPA 비관적 락# 비관적 락은 데이터베이스 트랜잭션 락 메커니즘에 의존하는 방법이다.주로 SQL 쿼리에 select for update 구문을 사용함녀서 시작하고 버전 정보는 사용하지 않는다. 비관적 락은 주로 PESSIMISTIC_WRITE 모드를 사용한다. 비관적 락은 다음과 같은 특징이 있다.엔티티가 아닌 스칼라 타입을 조회할 때도 사용할 수 있다. 데이터를 수정하는 즉시 트랜잭션 충돌을 감지할 수 있다. 비관적 락에서 발생하는 예외는 다음과 같다.PessimisticLockException (JPA 예외)PessimisticLockingFailureException (스프링 예외 추상화) PERSSIMISTIC_WRITE 옵션비관적 락이라 하면 일반적으로 이 옵션을 뜻한다. 용도: 데이터베이스에 쓰기 락을 건다. 동작: 데이터베이스 select for update를 사용해서 락을 건다. 이점: NON-REPEATABLE READ를 방지한다. 락이 걸린 로우는 다른 트랜잭션이 수정할 수 없다. PESSIMISTIC_READ데이터를 반복 읽기만 하고 수정하지 않는 용도로 락을 걸 때 사용한다. 일반적으로 잘 사용하지 않는다. PESSIMISTIC_FORCE_INCREMENT비관적 락중 유일하게 버전 정보를 사용한다. 비관적 락이지만 버전 정보를 강제로 증가시킨다. 비관적 락과 탕미아웃# 비관적 락을 사용함녀 락을 획득할 때까지 트랜잭션이 대기한다. 무한정 기다릴 수 없으므로 타임아웃 시간을 줄 수 있다. 다음 예제는 10초간 대기해서 응답이 없으면 LockTimeoutException 예외가 발생한다. 2차 캐시# 1차 캐시와 2차 캐시# 조회한 데이터를 메모리에 캐시해서 데이터베이스 접근 횟수를 줄이면 애플리케이션 성능을 획기적으로 개선할 수 있다. 1차캐시는 트랜잭션을 시작하고 종료할 때까지만 유효하다. 하이버네이트를 포함한 대부분의 JPA 구현체들은 애플리케이션 범위의 캐시를 지원하는데 이것을 공유 캐시 또는 2차 캐시라 한다. 1차 캐시 특징같은 엔티티가 있음녀 엔티티를 그대로 반환한다. 따라서 1차 캐시는 객체 동일성을 보장한다. 기본적으로 영속성 컨텍스트 범위의 캐시다. 2차 캐시는 애프리케이션 범위의 캐시다. 따라서 애플리케이션을 종료할 때까지 캐시를 유지된다. 분산 캐시나 클러스터 환경의 캐시는 애플리케이션보다 더 오래 유지될 수도 있다. 2차 캐시는 동시성을 극대화하려고 캐시한 객체를 직접 반환하지 않고 복사본을 만들어서 반환한다.만약 캐시한 객체를 그대로 반환하면 여러 곳에서 같은 객체를 동시에 수정하는 문제가 발생할 수 있다. 이 문제를 해결하기 위해 락을 사용해서 도잇성을 떨어뜨리는 대신, 객체를 복사해서 반환한다. 2차 캐시의 특징은 다음과 같다.영속성 유닛 범위의 캐시다. 조회한 객체는 그대로 반환하는 것이 아니라 복사본을 만들어서 반환한다. 데이터베이스 기본 키를 기준으로 캐시하지만 영속성 컨텍스트가 다르면 객체 동일성을 보장하지 않는다. JPA 2차 캐시 기능# 2차 캐시를 사용하려면 @Cacheable 어노테이션을 사용함녀된다.@Cacheable(false)를 설정할 수 있는데 기본값은 true다. 애플리케이션 전체에 캐시를 어떻게 적용할지 옵션(스프링 기준) 캐시 조회, 저장 방식 설정캐시를 무시하고 데이터베이스를 직접 조회하거나 캐시를 갱신하려면 캐시 조회 모드와 캐시 보관 모드를 사용하면 된다. 캐시 조회 모드나 보관 모드에 따라 사용할 프로퍼티와 옵션이 다르다. Entitymanager.setProperty()로 엔티티 매니저 단위로 설정하거나 더 세밀하게 EntityManger.find(), Entitymanager.refresh()에 설정할 수 있다.예시: JPA는 캐시를 관리하기 위한 Cache 인터페이스를 제공한다. 하이버네이트와 EHCACHE 적용# 하이버네이트가 지원하는 캐시는 3가지가 있다.엔티티 캐시: 엔티티 단위로 캐시한다. 식별자로 엔티티를 조회하거나 컬렉션이 아닌 연관된 엔티티를 로딩할 때 사용한다. 컬렉션 캐시: 엔티티와 연관된 컬렉션을 캐시한다. 컬렉션이 엔티티를 담고 있음녀 식별자 값만 캐시한다. 쿼리 캐시: 쿼리와 파라미터 정보를 키로 사용해서 캐시한다. 결과가 엔티티면 식별자 값만 캐시한다. @Cache세밀한 캐시 설정이 가능하다. region: 기본값으로 [패키지 명 + 클래스 명]을 사용하고, 컬렉션 캐시 영역은 엔키키 캐시 영역 이름에 캐시한 컬렉션 필드명이 추가된다.필요하다면 @Cache(region = "customRegion", ...) 처럼 캐시 영역을 직접 지정할 수 있다. 쿼리 캐시를 적용하려면 영속성 유닛을 설정에 hibernate.cache.use_query_cache 옵션을 꼭 true로 설정해야 한다. 쿼리 캐시를 활성화 하면 두 캐시 영역이 추가 된다.org.hibernate.cache.internal.StandardQueryCache: 쿼리 캐시를 저장하는 영역이다. 이곳에는 쿼리 ,쿼리 결과 집합, 쿼리를 실행한 시점의 타임스탬프를 보관한다.org.hibernate.cache.spi.UpdateTimestampsCache: 쿼리 캐시가 유요한지 확인하기 우해 쿼리 대상 테이블의 가장 최근 변경 시간을 저장하는 여역이다. 이곳에는 테이블 명과 해당 테이블의 최근 변경된 타임스탬프를 보관한다.쿼리 캐시는 캐시한 데이터 집합을 최신 데이터로 유지하려고 쿼리 캐시를 실행하는 시간과 쿼리 캐시가 사용하는 테이블들이 가장 최근에 변경된 시간을 비교한다. 쿼리 캐시를 적용한고 난 후에 쿼리 캐시가 사용하는 테이블에 조금이라도 변경이 잇음녀 데이터베이스에서 데이터를 일겅와서 쿼리 결과를 다시 캐시한다. 쿼리 캐시를 잘 활용하면 극적인 성능 향상이 잇지만 빈번하게 변경이 있는 테이블에 사용하면 오히려 성능이 더 저하된다. 쿼리 캐시와 컬렉션 캐시의 주의점쿼리 캐시와 컬렉션 캐시는 결과 집합의 식별자 값만 캐시한다. 쿼리 캐시나 컬렉션 캐시만 사용하고 대상 엔티티에 엔티티 캐시를 적용하지 않으면 성능상 심각한 문제가 발생할 수 있다. 따라서 쿼리 캐시나 컬렉션 캐시를 사용하면 결과 대상 엔티티에는 꼭 엔티티 캐시를 적용해야 한다. Please enable JavaScript to view the comments powered by Disqus. comments powered by