성능 향상과 관련 없는 딴짓#
- 레드헤링(Red Herring): 목표로부터 주의를 딴 데로 돌리는 상황
- MySQL 성능을 향상하기 위한 방법을 찾을 때 일반적으로 두 가지 레드헤링이 있다.
더 좋고 빠른 하드웨어!#
- MySQL 성능이 만족스럽지 않을 때 성능 향상에 도움이 되는지 확인하기 위해 스케일업부터 시작하지 말라.
- 이 경우가 합리적인 2가지 상황
- 하드웨어 성능 부족으로 명백하게 느린 경우
- 예) 500GB의 데이터에 1GB의 메모리를 사용하는 경우
- 애플리케이션의 사용량이 급증하고 있으며, 하드웨어 스케일업이 애플리케이션 실행에 있어 안정성을 담보하기 위한 임시 방편인 경우
- 단순 스케일업은 아무것도 배우지 못하며, 고사양의 하드웨어 구매로 문제를 대강 뭉개는 데 익숙해질 것이다.
- 하드웨어 확장은 지속 가능한 접근 방법이 아니다.
- 물리적인 하드웨어 업그레이드는 간단하지 않다.
- 스케일업에 따라 더 커다란 비용을 지불해야 한다.
MySQL 튜닝#
- 튜닝: 연구개발을 목적으로 MySQL 시스템 변수를 조정하는 행위로 구체적인 목표와 기준이 있는 실험실 수준의 작업
- 구성: 시스템 변수를 하드웨어와 환경에 적합한 값으로 설정하는 행위로 목표는 변경해야 하는 몇 가지 기본값을 가장 적합한 값으로 구성하는 것
- 단위가 달라질 정도로 데이터 규모가 대량으로 증가했을 때 재구성이 필요하다.
- 최적화: 워크로드를 줄이거나 효율성을 높여 MySQL 성능을 향상시키는 행위
- 튜닝이 헤드헤링인 이유
- MySQL 성능은 복잡하므로 튜닝 결과가 의심될 수 있다.
- MySQL은 이미 고도로 최적화 되었으므로 튜닝의 결과는 기대보다 성능에 큰 영향을 미치지 않는다.
- 재구성이 무의미한 이유
- MySQL 8.0에서는
innodb_dedicated_server 매개변수를 활성화하여 자동으로 서버를 구성한다. 직접 재구성이 무의미하다.
MySQL 인덱스: 시각적 소개#
- 아래 내용은 InnoDB 테이블의 표준 인덱스(
PRIMARY KEY, [UNIQUE] INDEX)에만 적용된다. - 아래 내용에서 사용할 테이블
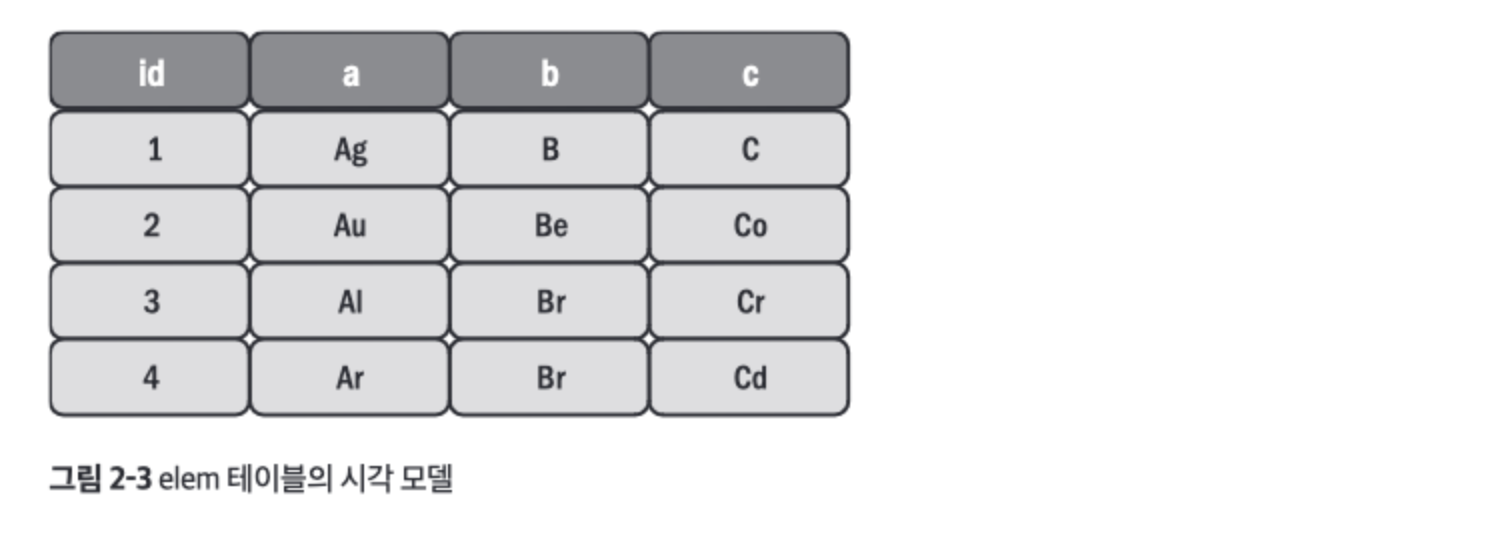
- 프라이머리 키를 가진
id 열 a, b 열로 구성된 비고유 세컨더리 인덱스
CREATE TABLE `elem`(
`id` int unsigned NOT NULL,
`a` char(2) NOT NULL,
`b` char(2) NOT NULL,
`c` char(2) NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_a_b` (`a`, `b`)
) ENGINE=InnoDB;

InnoDB 테이블은 인덱스다#
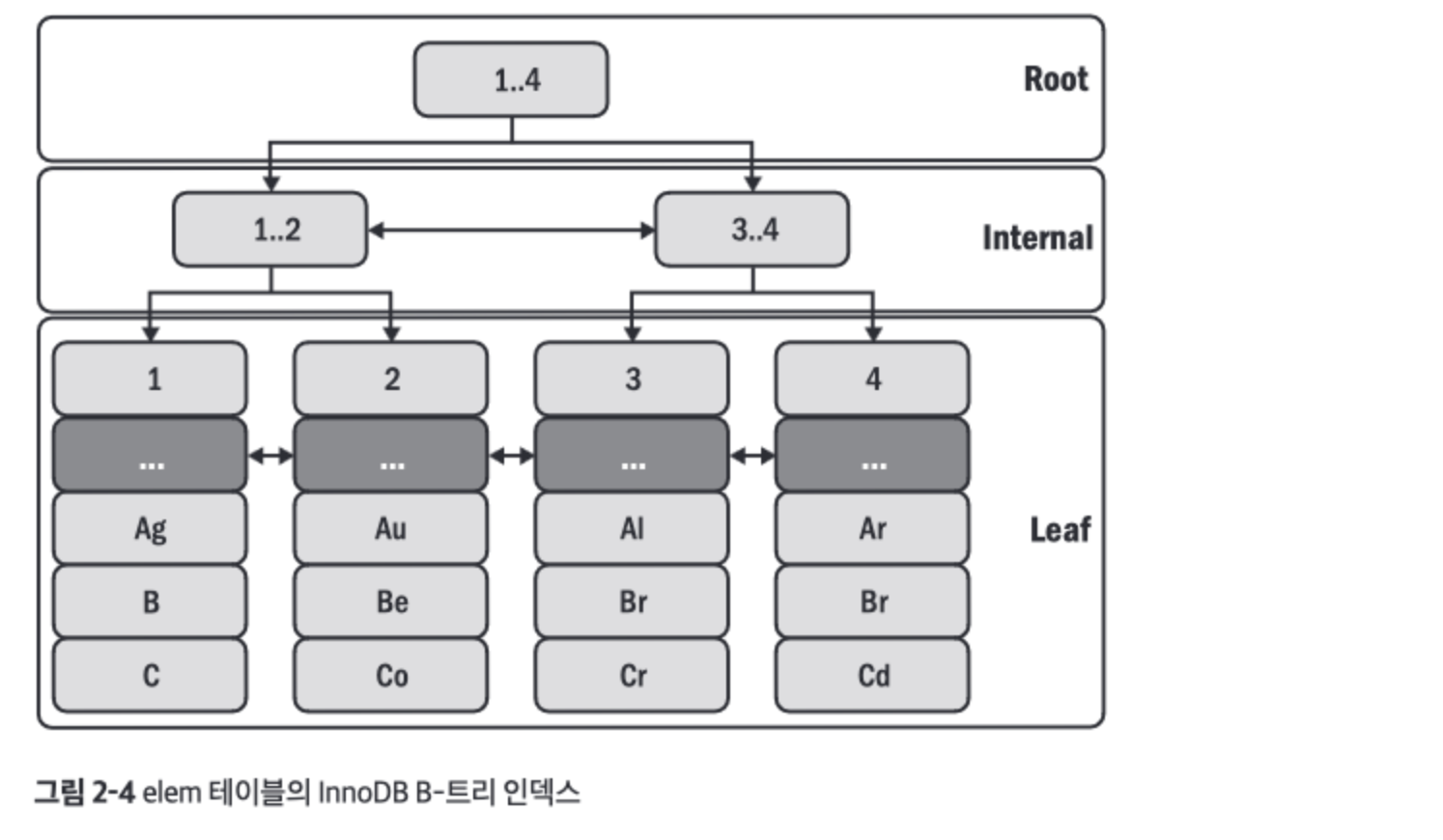
- 위 테이블의 프라이머리 키로 구성된 B-트리 인덱스는 아래와 같다.
- 테이블의 행은 인덱스 구조에서 리프 노드에 저장된 인덱스 레코드가 된다.
- 각 인덱스 레코드에는 로우 락, 트랜잭션 격리 등에서 사용되는 메타데이터(
...로 표시됨)가 포함되어 있다. - 프라이머리 키 조회는 매우 빠르고 효율적이다.
- 프라이머리 키는 MySQL 성능에 핵심적인 역할을 한다.
- MySQL의 세계에서 모든 것은 프라이머리 키를 중심으로 돌아간다.
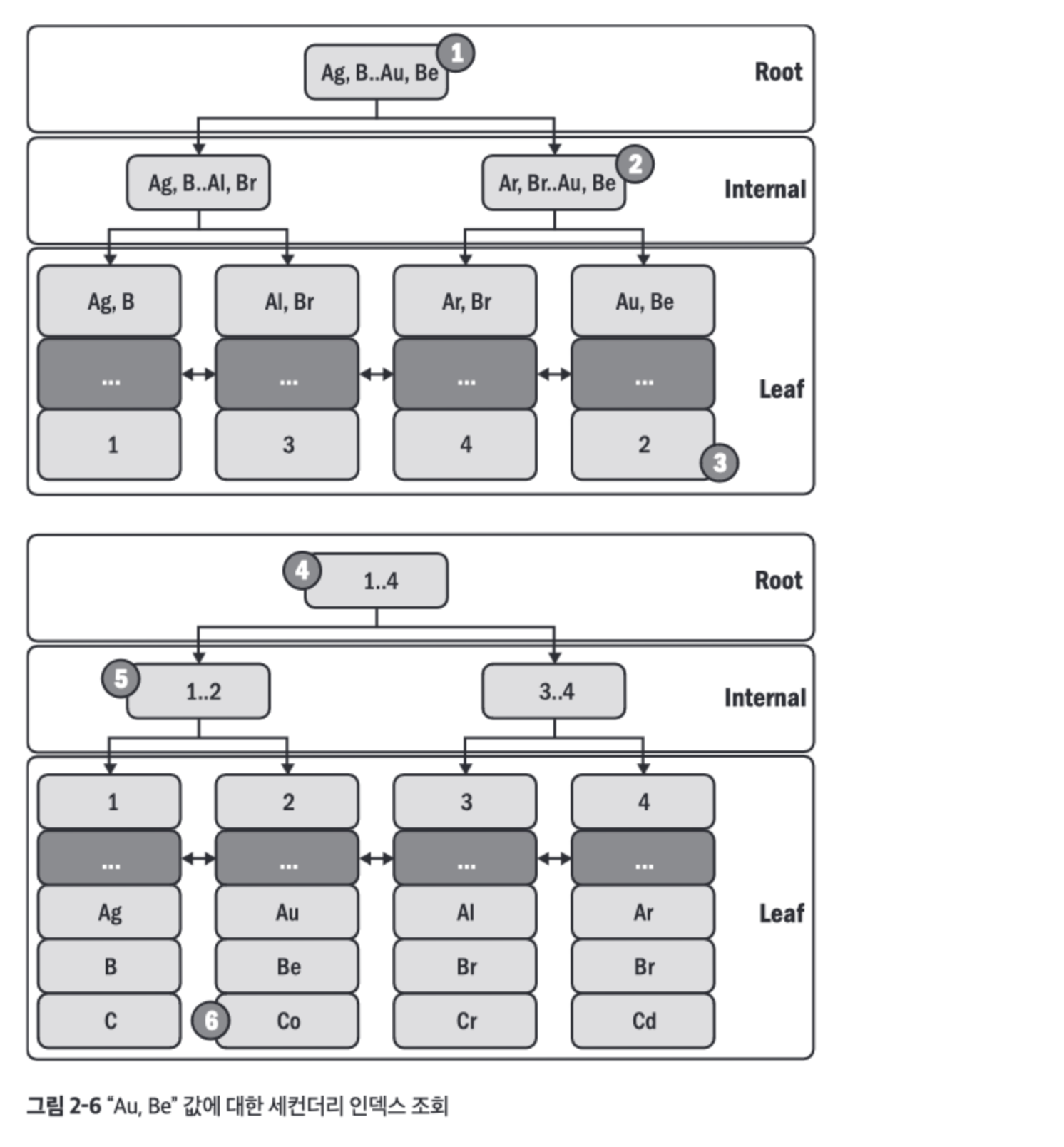
- 위 테이블의 세컨더리 인덱스는 아래와 같다.
- 세컨더리 인덱스도 B-트리 인덱스지만 리프 노드는 프라이머리 키값을 저장한다.
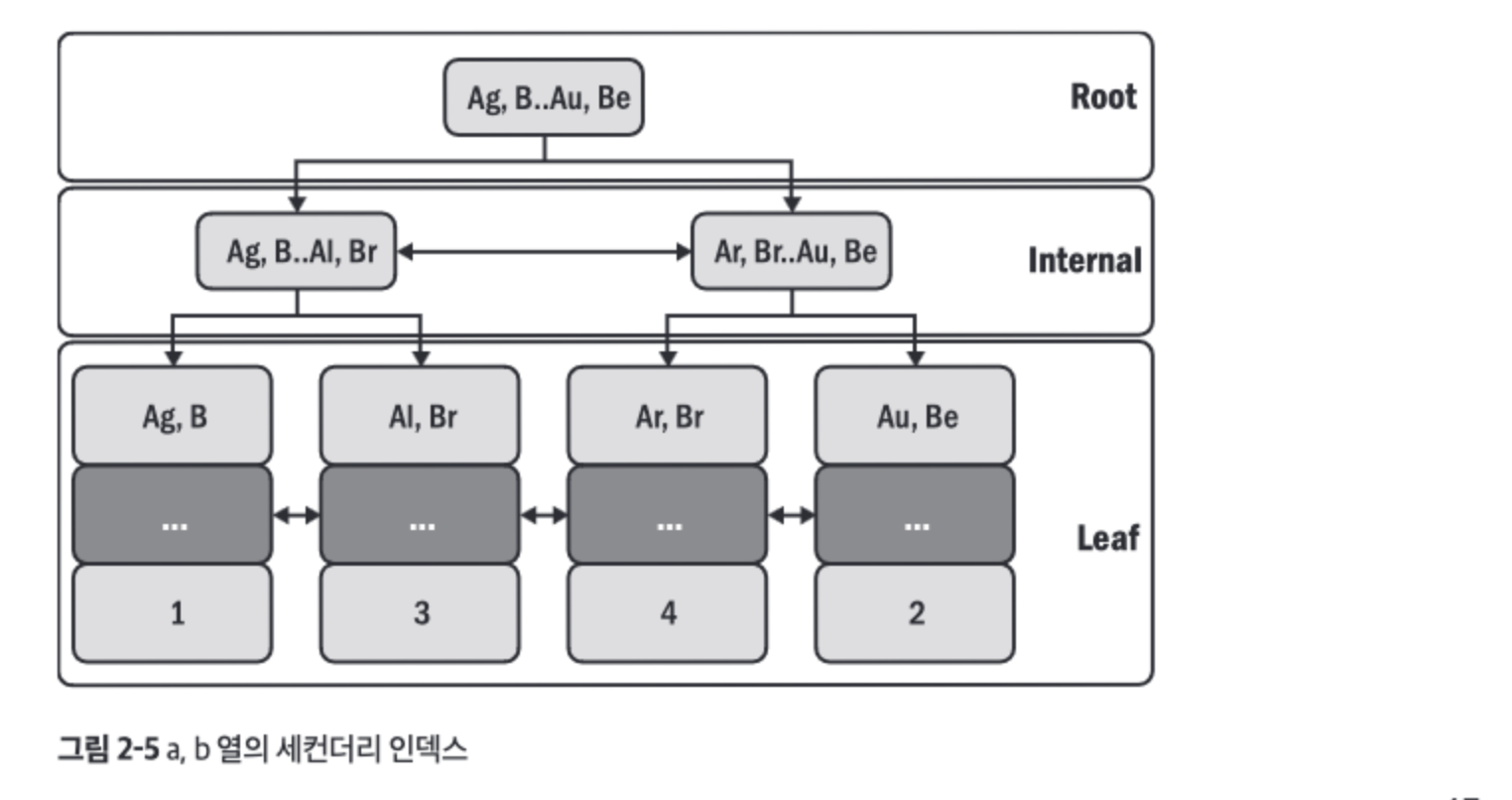
- 아래 그림은
SELECT * FROM elem WHERE a='Au' AND b='Be' 쿼리에 대한 세컨더리 인덱스 조회 상황이다.
테이블 접근 방법#
- 세 가지 테이블 접근 방법
- 성능을 발휘하기 위해서는 인덱스 스캔과 테이블 스캔은 피해야 한다.
- 인덱스 조회
- 인덱스의 정렬된 구조와 접근 알고리즘을 활용하여 특정 행이나 행 범위를 찾는다.
- 대량의 데이터를 대상으로 한 빠르고 효율적인 접근
- 인덱스 스캔
- 인덱스 조회가 불가능할 때 MySQL은 전체 데이터 순차 찾기 같은 억지 기법으로 행을 찾아야 한다. 즉, 행을 읽고 일치하는 않는 행을 필터링한다.
- 유일한 대안이 풀 데이블 스캔이 아닌 이상 인덱스 스캔으로 최적화 하면 안된다.
- 인덱스 스캔의 2가지 유형
- 풀 인덱스 스캔
- 인덱스 순서대로 모든 행을 읽는다.
- 모든 행을 읽는 것은 일반적으로 성능에 매우 불리하지만 인덱스 순서가
ORDER BY 쿼리와 일치할 때 행 정렬을 피할 수 있다. - 아래는
SELECT * FROM elem FORCE INDEX (a) ORDER BY a, b 쿼리에 대한 상황이다.FORCE INDEX 하는 이유: 테이블 크기가 작아서 테이블 풀 스캔이 될 수 있기 때문에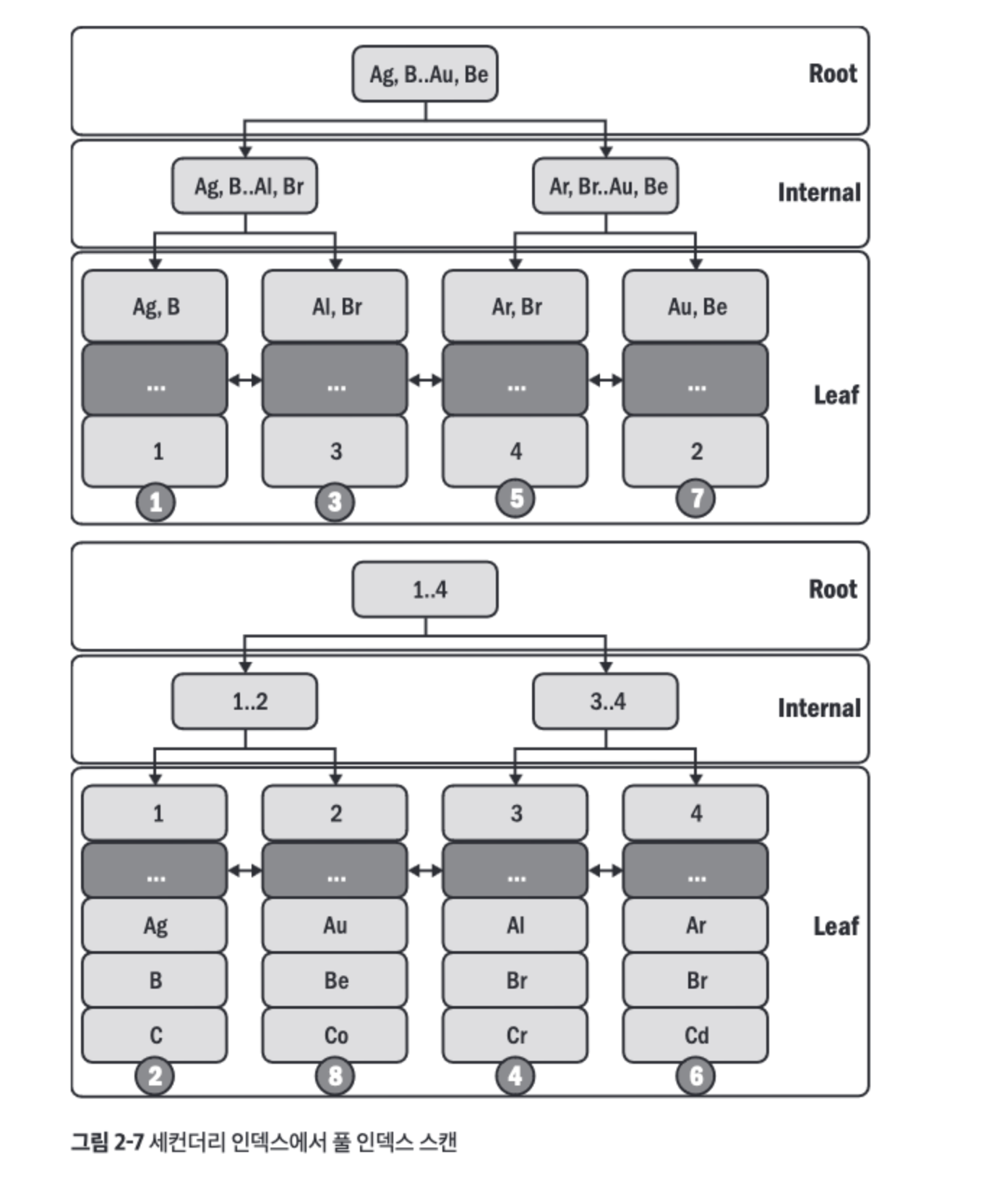
- 인덱스 전용 스캔(index-only scan)
- 인덱스에서 열 값을 읽는다.
- 이를 위해서는 커버링 인덱스가 필요하다.
- 전체 행을 읽기 위해서 프라이머리 키 조회를 해야 하는 상황이 아니므로 풀 인덱스 스캔보다 빠르다.
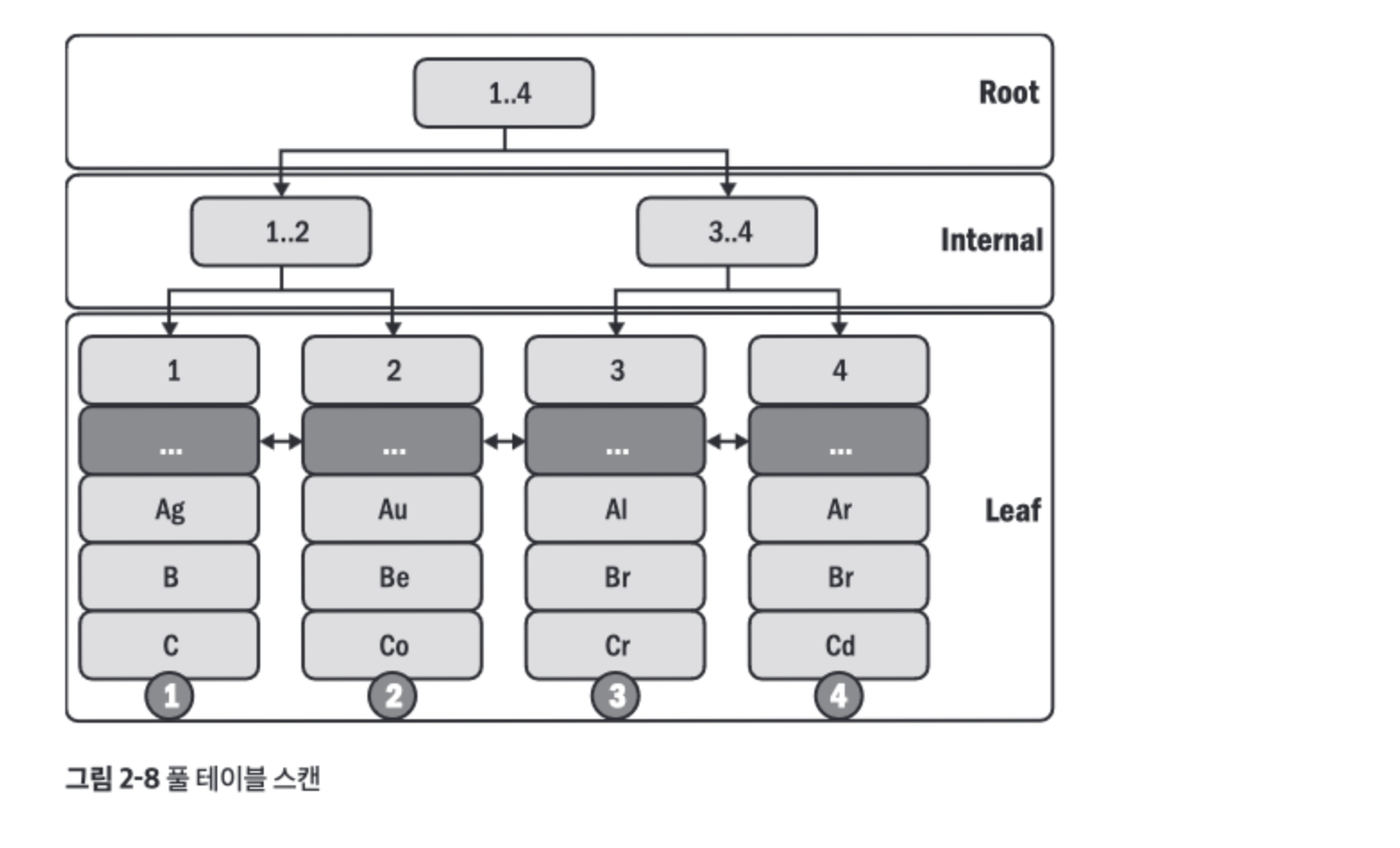
- 풀 테이블 스캔
- 프라이머리 키 순서로 모든 행을 읽는다.
- 테이블 전체를 스캔하기 때문에 피하는게 최선이다.
- 테이블 스캔이 허용하거나 괜찮은 경우
- 테이블이 작고 접근 빈도가 낮을 때
- 테이블 선택도가 매우 낮을 때(2.4 절에서 설명)
맨 왼쪽 접두사(leftmost prefix) 요구사항#
- 기본적인 인덱스 구조는 인덱스 열 순서에 따라 정렬되므로, 인덱스를 사용하려면 맨 왼쪽 인덱스 열로 시작하는 열을 순서대로 사용해야 한다.
- 인덱스
(a, b)와 (b, a)는 서로 다르다. (a)와 (a, b) 대신 (a, b, c)를 사용할 가능성이 크다.- 모든 세컨더리 인덱스의 끝에는 프라이머리 키가 숨겨져 있다.
(a, b) 세컨더리 인덱스는 사실상 (a, b, id)
EXPLAIN: 쿼리 실행 계획#
EXPLAIN 명령은 쿼리 실행 계획을 보여준다.


table: 테이블이나 참조된 서브 쿼리. 쿼리에 보여지는 순서가 아니라 MySQL이 결정한 조인 순서로 나열된다.type: 테이블 접근 방법이나 인덱스 조회의 접근 유형ALL: 테이블 풀 스캔index: 인덱스 스캔const, ref, range 등의 다른 값: 인덱스 조회의 접근 유형
possible_keys: 맨 왼쪽 접두사 요구사항에 충족되어 MySQL이 사용할 수 있는 인덱스key: MySQL이 사용할 인덱스의 이름이거나 인덱스를 사용할 수 없을 때에는 NULL이다.ref: 행을 조회하는 데 사용되는 값의 소스를 나열한다.- 단일 테이블 쿼리나 조인의 첫 번째 테이블에서는 상수 조건을 나타내는
const - 여러 테이블을 조인하는 쿼리에서 조인 순서상 이전 테이블의 열 참조
rows: MySQL이 일치하는 행을 찾기 위해 조회할 예상하는 행의 수Extras: 쿼리 실행 계획에 대한 부가 정보를 제공한다.- MySQL이 적용할 수 있는 쿼리 최적화를 나타내므로 중요하다.
WHERE#
EXPLAIN SELECT * FROM elem WHERE 1d = 1key: PRIMARY 인덱스 조회로 프라이머리 키를 사용함type: const 프라이머리 키 조회로 조회ref: const 프라이머리 키나 유니크 세컨더리 인덱스의 모든 인덱스 열에 상수 조건이 있을 때만 발생한다.- const 접근 유형의 결과는 상수 행이다.
- 상수 행: 오직 하나만 일치하거나 또는 없는 행
EXTRA: NULL MySQL이 행과 일치시켜볼 필요가 없음을 의미한다.
EXPLAIN SELECT * FROM eme WHERE id > 3 AND id < 6 AND c = 'Cd'type: range 범위 스캔ref: NULL id 열의 조건이 상수가 아니므로rows: 2 2개 행을 조회할 것으로 추정한다.Extra: Using where: MySQL이 WHERE 조건을 사용하여 일치하는 행을 찾는다는 의미다.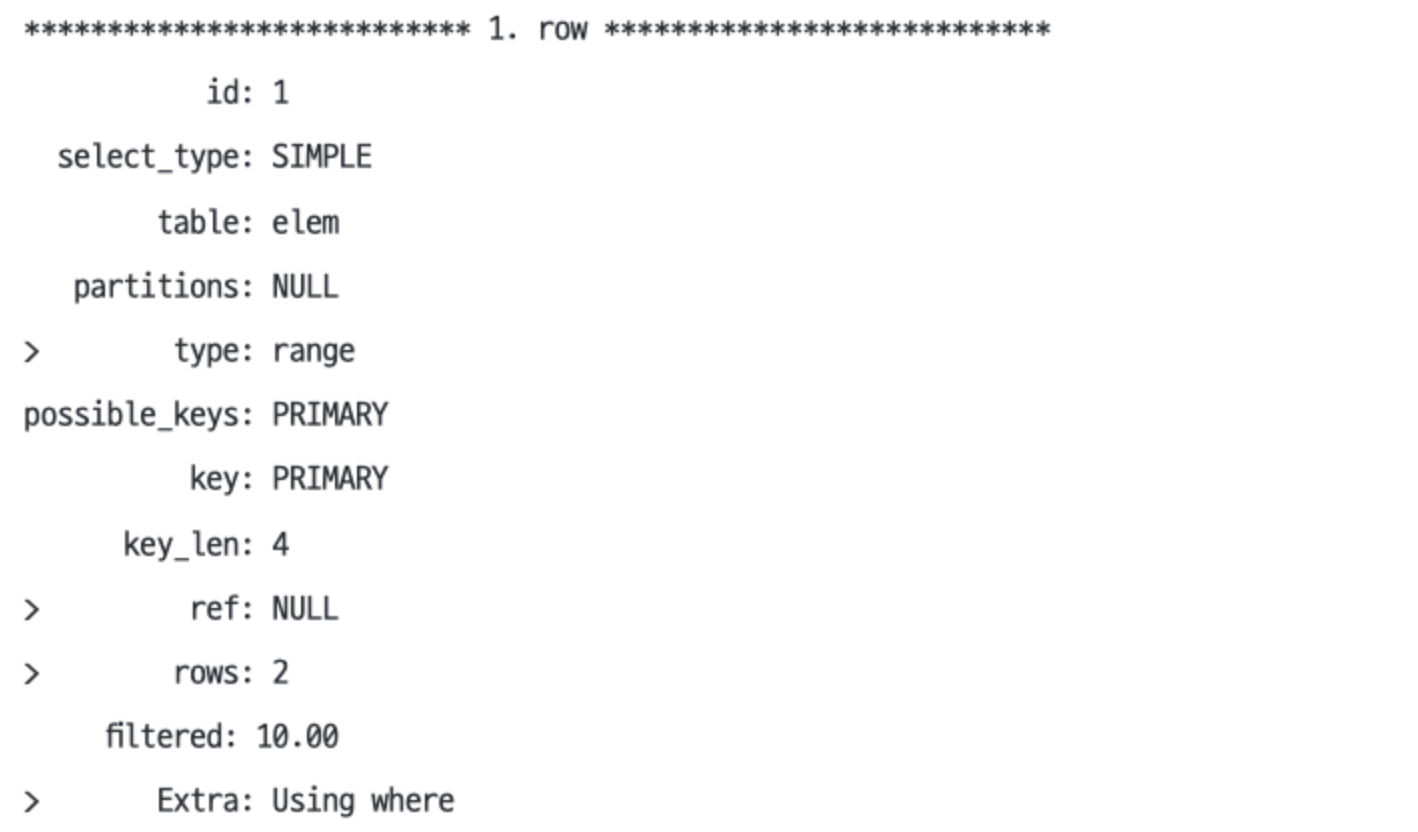
EXPLAIN SELECT * FROM elem WHERE a = 'Au'- 인덱스 a만 사용한다.
type: ref 인덱스의 맨 왼쪽 접두사에 대한 동등 조회를 나타내는 접근 유형- ref 접근은 조회할 예상 행의 수가 적절하다면 매우 빠르다.
- 인덱스가 비고유라 조회가 하나 이상의 행과 일치할 수 있기 때문에 const 접근 유형은 불가능하다.
Extra: NULL 인덱스만 사용하여 일치하는 행을 찾을 수 있다.
EXPLAIN SELECT * FROM elem WEHRE a = 'Au' AND b = 'Be'- a, b 열의 두 인덱스 부분을 사용한다.
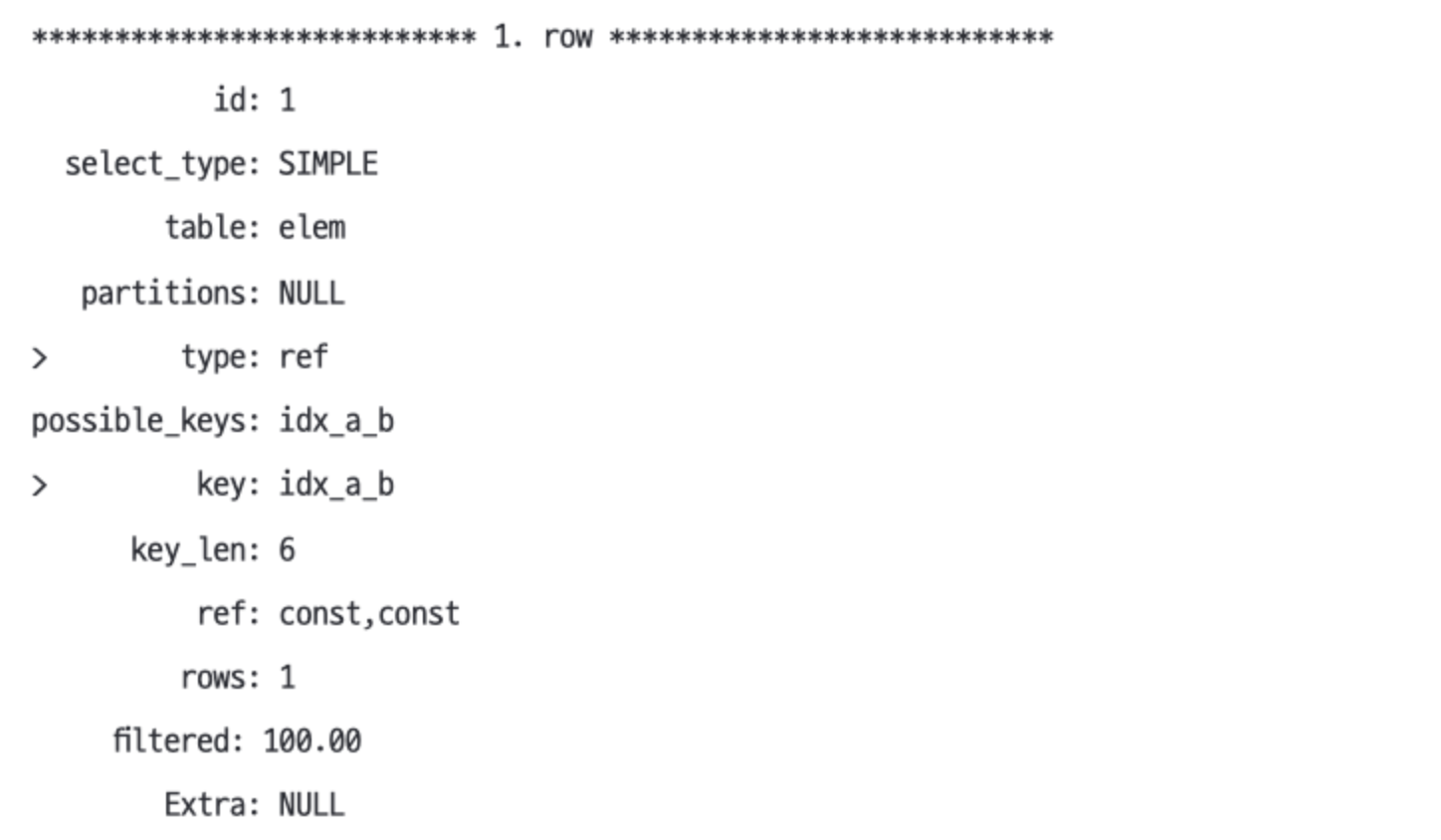
EXPLAIN SELECT * FROM elem WHERE a = 'Al' AND c = 'Co'- a 열의 인덱스 부분을 사용한다.
Extra: Using where c 열의 조건과 일치하는 행을 찾는다.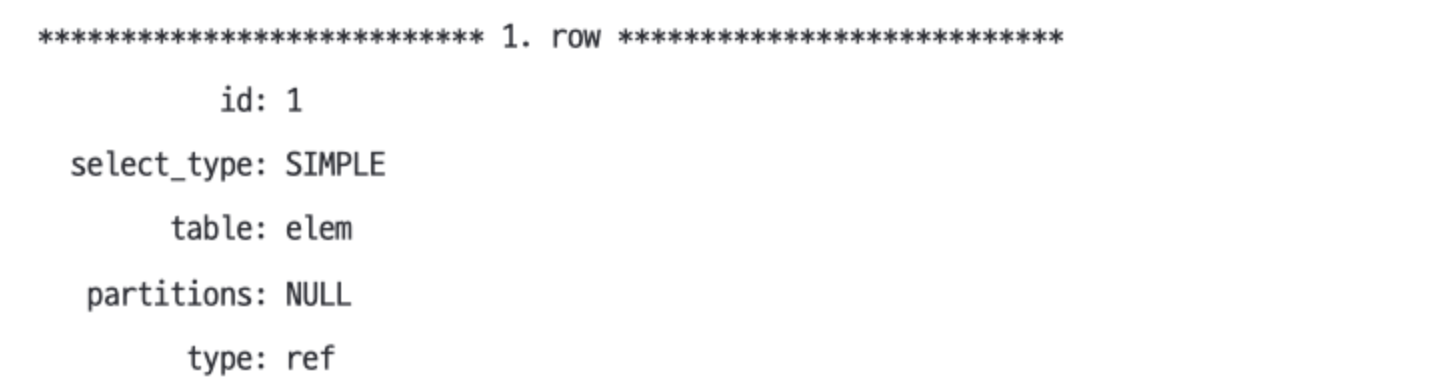

EXPLAIN SELECT * FROM elem WHERE b= 'Be'type: ALL 인덱스를 사용할 수 없어 풀 테이블 스캔을 수행해야 한다.possible_keys: NULLkey: NULLrows: 10
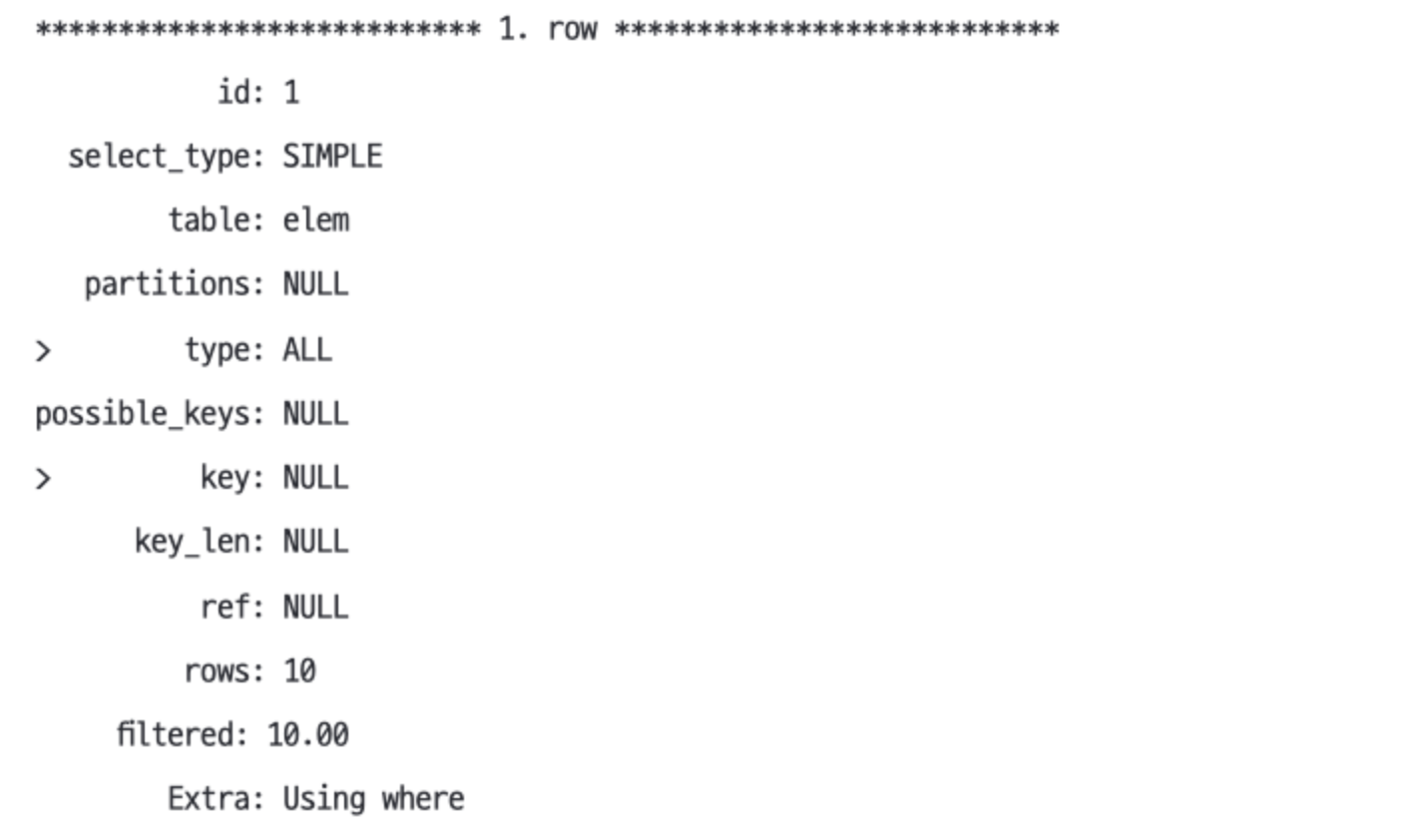
GROUP BY#
- MySQL은 값이 인덱스 순서에 따라 암문적으로 그룹화되므로
GROUP BY를 최적화하기 위해 인덱스를 사용할 수 있다. EXPLAIN SELECT a, COUNT(1) FROM elem GROUP BY a- 인덱스가 정렬되어 있으므로 a 열을 읽다가 값이 바뀌면 새로운 그룹인 것으로 처리한다.
Extra: Using index MySQL이 인덱스에서 오직 a 열의 값만 읽고 프라이머리 키에서 전체 행을 읽지 않음을 나타낸다. (커버링 인덱스)type: index 인덱스 스캔
EXPLAIN SELECT a, COUNT(a) FROM elem WHERE a != 'Ar' GROUP BY aExtra: Using where: WHERE a != 'Ar'을 나타낸다.type: range 인덱스 조회 중 범위 조회. a != Ar은 a < 'Ar' OR a > 'Ar'와 같기 때문이다.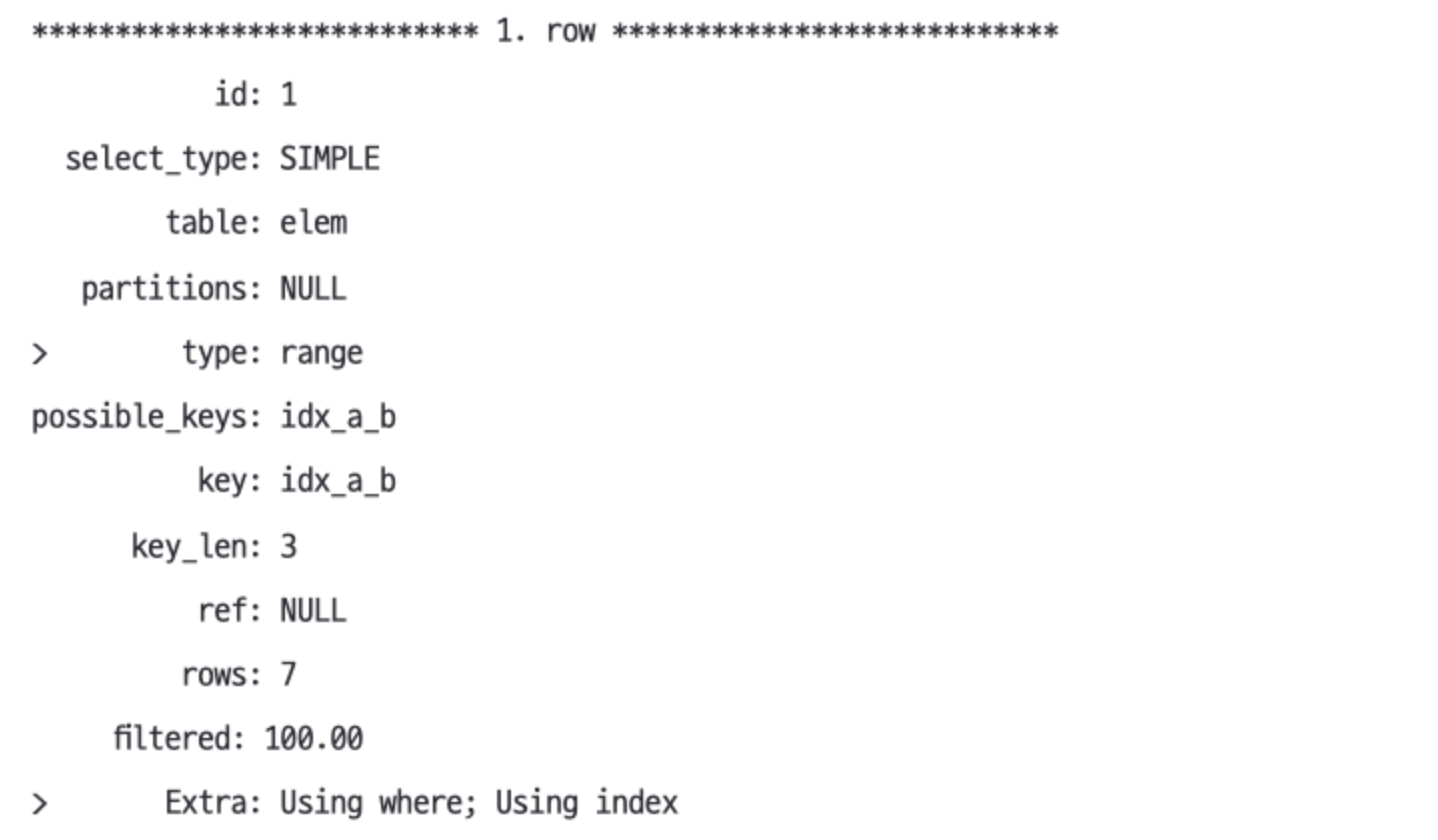
EXPLAIN SELECT a, b FROM elem WHERE b = 'B' GROUP BY a- WHERE 절의 b 열에 대한 조건은 다른 SQL 절에 있더라도 맨 왼쪽 접수다에 대한 요구 사항을 충족하므로 인덱스를 여전히 사용할 수 있다.
Extra: Using index for group-by WHERE 절의 b 열에 대한 동일 조건과 SELECT 절에서 a와 b 열 선택이라는 세부 정보 때문에 특별한 최적화가 활성화된다.

EXPLAIN SELECT b, COUNT(*) FROM elem GROUP BY b- 특이사항: a 열에 조건이 없음에도 인덱스를 사용한다.
- 인덱스 스캔(
type: index)을 하면서 a = a와 같이 항상 참인 a열 조건이 있다고 볼 수 있다. GROUP BY C인 경우에는 a열에 대해서 계속 인덱스 스캔을 하지 않고 풀 테이블 스캔을 한다.
Extra: Using Temporary 맨 왼쪽 접두사 조건이라는 엄격한 세트를 가지지 않은 것에 대한 부작용이다.- MySQL은 인덱스에서 a 열값을 읽을 때 임시 테이블(메모리)에서 b 열값을 수집한다.
- a 열의 모든 값을 읽은 후
COUNT(*)에 의해 그룹화되고 집계된 임시 테이블에 대해 테이블 스캔한다.


ORDER BY#
ORDER BY를 최적화하기 위해 정렬된 인덱스를 사용할 수 있다.- 이런 최적화가 없다면, EXPLAIN 계획의
Extra 필드에 “Using filesort"를 출력한다. - 대체로 행 정렬이 느린 응답 시간의 근본 원인은 아니다.
- 인덱스를 사용하여
ORDER BY를 최적화하는 방법 3가지ORDER BY 절에 인덱스의 맨 왼쪽 접두사를 사용하는 것: ORDER BY id- 인덱스 상수로 맨 왼쪽 부분을 유지하고 다음에 인덱스 열을 기준으로 정렬하는 것:
WHERE a = 'Ar' ORDER BY b - secondary inex의 숨겨진 컬럼(PK)를 활용하는 방법:
WHERE a = 'Al' AND b = 'B' ORDER BY id
- 인덱스 컨디션 푸시다운
- Extra 필드에
Using index condition 이 나오는 경우 - 스토리지 엔진이 인덱스를 사용하여
WHERE 조건과 일치하는 행을 찾는다는 의미- 일반적으로 스토리지 엔진이 행을 읽고, MySQL은 일치하는 행을 찾는 로직을 처리핟나.
- 스토리지 엔진이 조건과 일치하는 행을 찾는다면 시간이 절약된다.
- ORDER BY에서 컬럼은 모두 한 반향(ASC 또는 DESC)으로만 작동해야 인덱스를 사용할 수 있다.
EXPLAIN ANALYZE 를 통해 성능을 측정하면 행을 정렬하는 과정은 크게 느리게 만들지 않는다.- 많은 행을 읽는 작업은 인덱스를 순회하고 트랜잭션을 관리해야 하는 과정이 더 많은 부하가 된다.
- 파일 정렬이 발생하면 스토리지에 임시 파일을 사용하여 정렬을 하지만, 이는 회전하는 디스크가 일반적이었던 수십 년 전에 특히 느렸고, 오늘날에는 SSD가 표준이며 이 스토리지는 아주 빠르다.
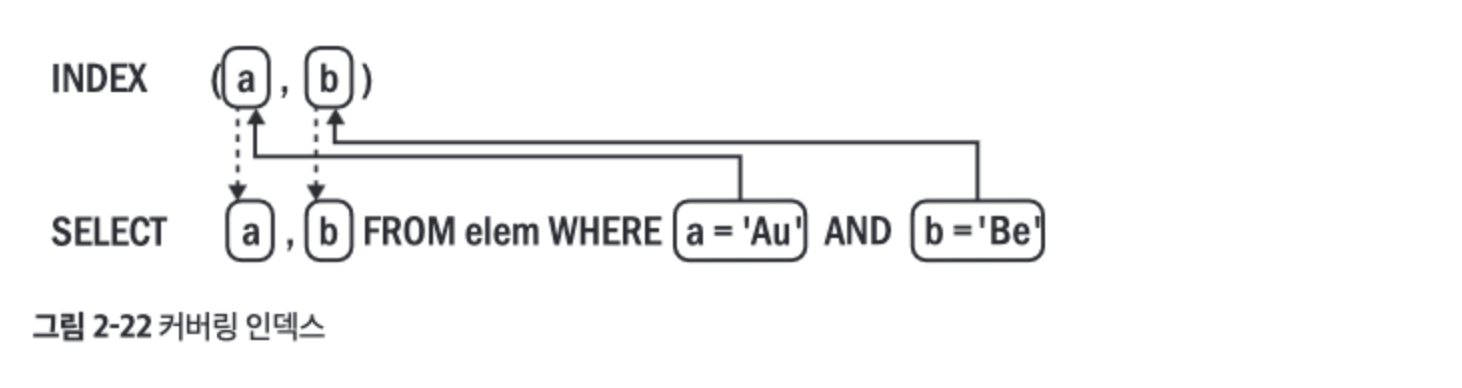
커버링 인덱스#
- 쿼리가 참조하는 모든 열이 인덱스에 포함되는 경우
- 커버링 인덱스를 사용하면 MySQL은 프라이머리 키를 읽지않고, 인덱스에서 열값만 읽을 수 있다.
- 커버링 인덱스를 사용하면 EXPLAIN은
Extra 필드에 “Using index"로 보고한다. - 커버링 인덱스는 매력적이지만 실제로 작성되는 쿼리에서는 인덱스 하나만으로는 커버링되지 않는 많은 열과 조건이 있어서 자주 사용되지는 않는다.
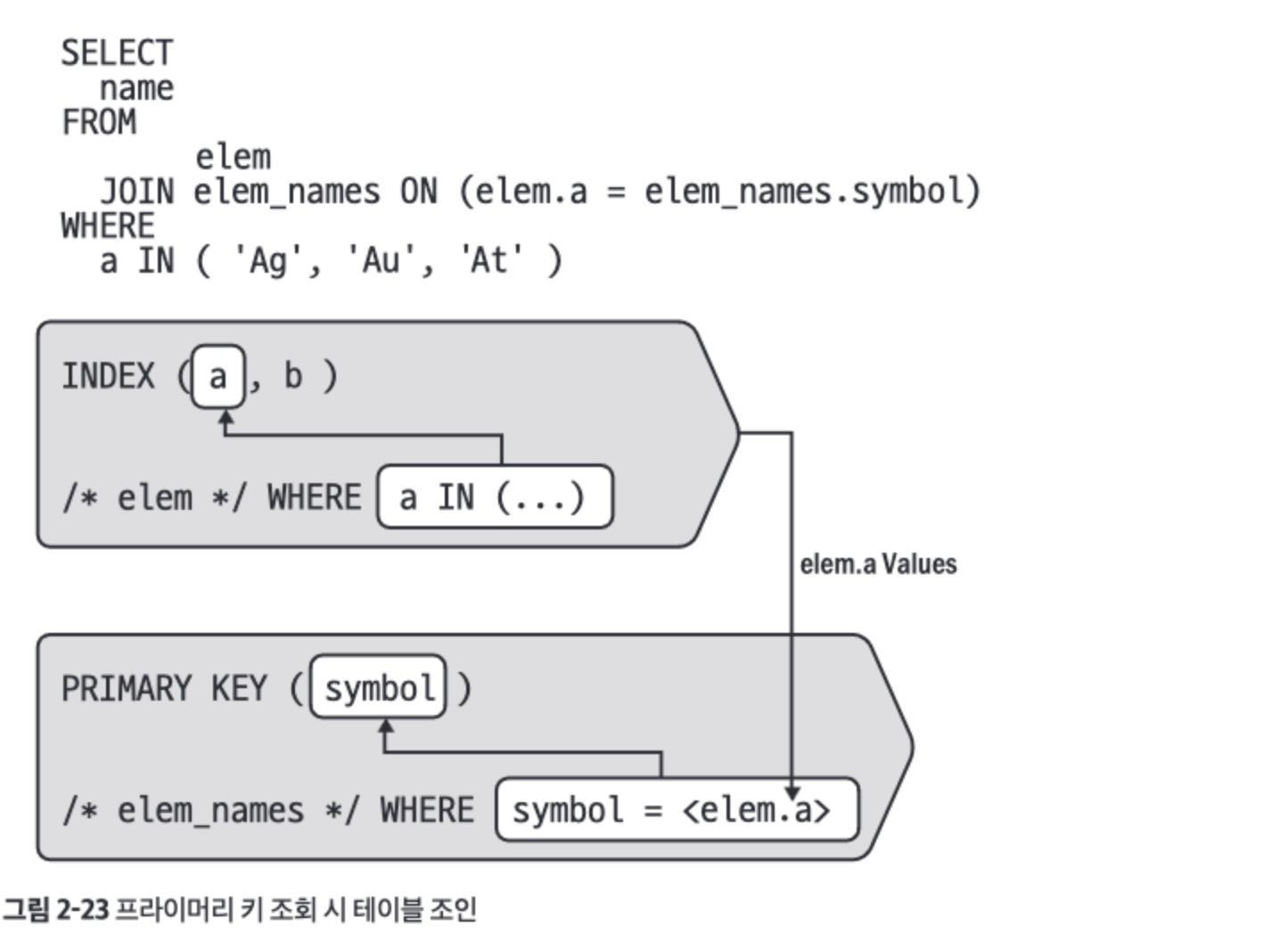
테이블 조인#
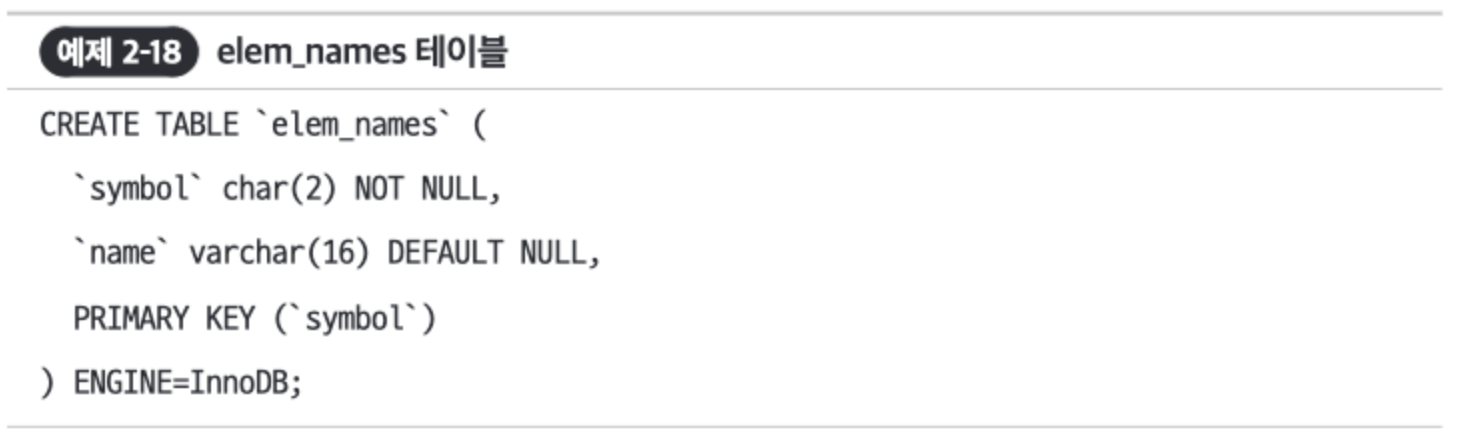
- 예제에서 사용할 또다른 테이블
elem_names - 테이블 조인에 인덱스를 사용하며, 사용법은 다른 것에 인덱스를 사용하는 것과 기본적으로 같다.
- 접근 유형
eq_ref: 프라이머리 키나 유니크 not-null 세컨더리 인덱스를 사용하는 단일 행 조회를 의미한다.const vs eq_refconst는 주로 단일 테이블에서 상수 값을 사용하여 단일 행을 찾을 때 적용된다.eq_ref는 두 테이블 간의 조인 조건이 프라이머리 키 또는 not-null 고유 인덱스를 기준으로 일치할 때 적용된다.
eq_ref는 단일 행만 일치하기 때문에 빠르다.eq_ref의 조건- 프라이머리 키나 유니크 not-null 세컨더리 인덱스
- 모든 인덱스 열의 동일 조건

SHOW WARNINGS 명령어를 사용하면 MySQL이 재작성한 쿼리를 볼 수 있다.EXPLAIN은 조인 순서에 따라 위에서 아래로 테이블을 출력한다.- 조인 순서는 작은 쿼리 수정으로도 상당히 크게 변한다.
IN 절에 “At"라는 값이 제건되었는데, elem_names가 인덱스 범위 조회로 먼저 조회되는 것을 확인할 수 있다.
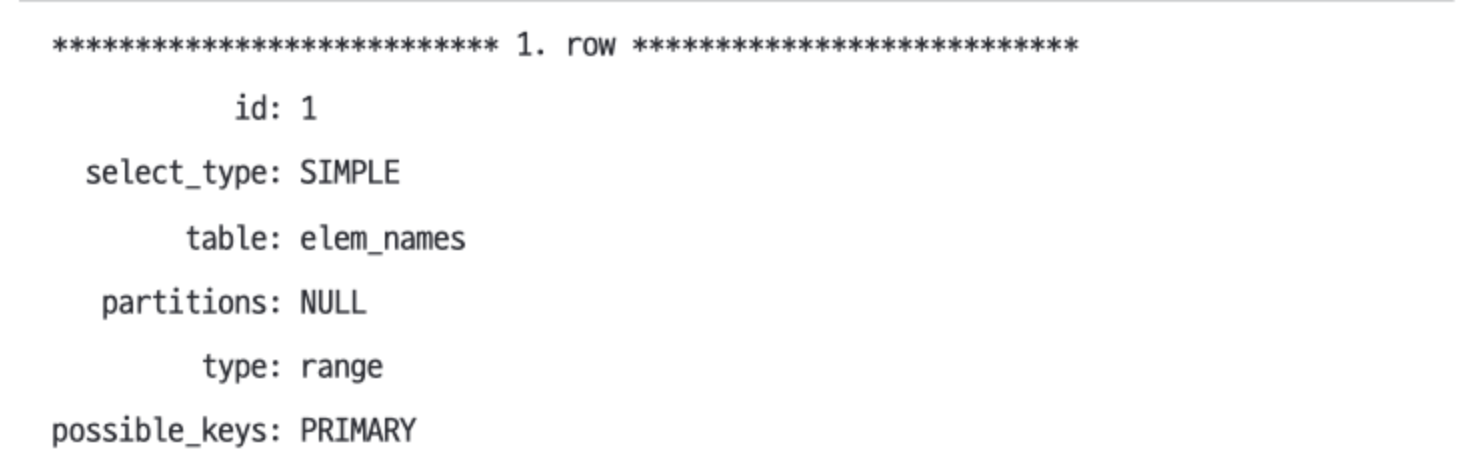

- 아래는
SHOW WARNINGS 명령에 대해 요약된 출력 내용이다.- 원래 쿼리에 작성된
elem.a 대신 elem_names.symbols에 대한 값으로 IN() 목록을 재작성했다. 
- 풀 조인: 인덱스 없이 테이블 조인
- 최악의 작업
- 조인된 테이블에
type: ALL인 경우에 해당한다. - Extra필드의 “Using join buffer (hash join)“은 MySQL 8.0.18에 새롭게 도입된 해시 조인 알고리즘을 나타낸다.
- 메모리 내 해싯값 테이블을 만들고 반복되는 테이블 스캔을 수행하는 대신 이 해시 테이블을 사용해 행을 조회한다.


인덱싱: MySQL처럼 생각하는 방법#
- 엔지니어들이 인덱싱에 어려움을 겪는 이유는 자신이 쿼리에 대해 생각하는 방식이 MySQL이 쿼리에 대해 생각하는 방식과 혼동하기 때문이다.
- 엔지니어는 애플리케이션 맥락에서 쿼리를 생각한다.
쿼리 알기#
- MySQL처럼 생각하는 첫 번쨰 단계는 최적화하련느 쿼리의 기본 정보를 파악하는 것이다.
- 테이블의 메타데이터 수집
- SHOW CREATE TABLE(테이블 생성 정보 보기 명령어)
- SHOW TABLE STATUS(테이블 상태 정보 보기 명령어)
- SHOW INDEXES(인덱스 정보 보기 명령어)
- 쿼리가 이미 프로덕션에서 수행 중이라면 쿼리 보고서를 보고 메트릭과 현재 값에 익숙해져야 한다.
- 쿼리
- 쿼리는 몇 개의 행에 접근해야 합니까?
- 쿼리는 몇 개의 행을 반환해야 합니까?
- 어떤 열이 반환됩니까?
- GROUP BY, ORDER BY, LIMIT 절은 무엇입니까?
- 서브쿼리가 있습니까?
- 테이블 접근
- 테이블 조건은 무엇입니까?
- 쿼리는 어떤 인덱슬르 사용해야 합니까?
- 쿼리가 사용할 수 있는 다른 인덱스는 무엇입니까?
- 각 인덱스의 카디널리티는 무엇입니까?
- 테이블의 크기는 얼마입니까?
EXPLAIN으로 이해하기#
- 두 번째 단계는
EXPLAIN에서 보고한 현재 쿼리 실행 계획을 이해하는 것이다.key 필드로부터 인덱스와 관련된 각 테이블과 해당 조건을 고려한다.possible_keys 필드에 다른 인덱스가 나열되었으면, 항상 맨 왼쪽 접두사에 대한 요구사하을 염두해두고 MySQL이 해당 인덱스를 사용하여 행에 접근하는 방법을 생각한다.
쿼리 최적화#
- 세 번째 단계는 직접 쿼리 최적화로 쿼리, 인덱스 또는 둘 모두를 변경한다.
- 다르게 실행되지만 같은 결과를 반환하는 쿼리는 여러 가지 방법으로 작성할 수 있다.
SELECT col FROM tbl WHERE id = 1처럼 쿼리가 매우 단순하면서 다시 작성할 방법이 없는데 느린 경우는, 쿼리가 아닌 인덱스를 변경해야 할 가능성이 크다.- 인덱스 변경으로 문제가 해결되지 않으면 간접 쿼리 최적화로 여정을 옮겨야 된다.
배포와 검증#
- 마지막 단계는 변경 사항을 배포하고 응답 시간이 개선되는지 검증하는 것이다.
- 먼저 변경 사항으로 인해 의도하지 않은 부작용이 발생할 경우 롤백할 방법을 확인하고 준비해야 한다.
- 준비 단계와 프로더견 단계의 데이터가 크게 다른 경우 부작용이 발생할 수 있다.
- 배포 후에는 쿼리메트릭과 MySQL 서버 메트릭으로 변경 사항을 검증한다.
좋은 인덱스였는데…#
- 데이터베이스의 무언가가 변하면 좋은 인덱스를 나쁘게 만들고 성능을 떨어뜨린다.
- 성능 저하의 일반적인 원인을 알아본다.
쿼리 변경#
- 쿼리가 변경될 때 왼쪽 접두사에 대한 요구사항이 손실되어, 풀 테이블 스캔이나 다른 안좋은 인덱스를 사용하게 된다.
- 쿼리 분서과 EXPLAIN 계획을 확인해주고, 가능하다면 새로 변경한 쿼리에 대해 인덱스를 다시 만든다.
과도하고 중복되며 사용되지 않음#
- 과도한 인덱스: 중복된 인덱스가 하나 더 있는 경우
- 과도한 인덱스의 문제점
- 더 많은 메모리를 사용하므로 각 인덱스에 사용할 수 있는 메모리가 줄어든다.
- MySQL이 데이터를 작성할 때 모든 인덱스를 확인하여 갱신하므로, 쓰기 성능이 떨어진다.
SHOW WARNINGS를 실행하면 인덱스를 만들 때 중복 인덱스 경고를 알려준다.- 아래 쿼리로 사용되지 않는 인덱스를 나열할 수 있다.
SELECT * FROM sys.schema_unused_indexes WHERE object_schema NOT IN ('performance_schema');- 해당 쿼리는 MySQL의 sys 스키마를 사용하는데, 정렬된 모든 종류의 정보를 반환하는 미리 만들어진 뷰의 모음이다.
- 인덱스를 삭제할 때 MySQL 8.0부터 인비저블 인덱스를 사용하면, 삭제 전에 인덱스가 사용되지 않거나 필요하지 않은지 확인할 수 있다.
- 인덱스를 보이지 않게 하고 성능에 영향을 미치지 않는지 확인한 다음 인덱스를 삭제하는 방법이다.
- 실수가 있을 때 인비저블 인덱스는 바로 다시 보이게 하면되지만, 이미 삭제해버린 인덱스를 다시 추가하는 것은 대형 테이블에서 몇 분 또는 몇 시간이 걸릴 수 있다.
최고의 선택도#
- 카디널리티: 인덱스의 고유값 수
- 선택도: 카디널리티를 테이블의 행 수로 나눈 값
- 선택도는 0에서 1까지
- 1에 가까울 수록 좋은 인덱스이다.
- 선택도가 매우 높은 인덱스는 과도하게 활용될 수 있다.
- 비고유 세컨더리 인덱스의 선택도가 1에 가까워지면 인덱스가 고유해야 하는지, 아니면 프라이머리 키를 사용하도록 쿼리를 다시 작성할 수 있는지 의문이 생기기 시작한다.
- 이때 엘락스틱 서치가 MySQL보다 접근 패턴을 더 잘 지원할 수 있다는 판단도 할 수 있다.
- 예) 다양한 기준으로 검색하는 제품 인벤토리가 있는 테이블
- 각 기준에 따라 맨 왼쪽 접두사 요구사항을 충족하는 인덱스를 만들어야 된다.
- 차라리 엘라스틱 서치를 사용하는게 좋다.
이것은 함정이다! - MySQL이 다른 인덱스를 선택할 때#
- 매우 드물지만 MySQL이 인덱스를 잘못 선택하기도 한다.
- 인덱스 통계: 인덱스에서 값이 어떻게 분포되어 있는지에 대한 추정치
- MySQL이 샘플 페이지에 대한 인덱스를 무작위로 탐색한다.
- 인덱스 통계 갱신 조건
- 테이블이 처음으로 열릴 때
- ANALYZE TABLE 명령이 실행되었을 때
- 마지막 업데이트 이후 테이블의 1/16이 수정되었을 때
- innodb_stats_on_metadata가 활성화되고 다음 중 한 경우일 때
- SHOW INDEX나 SHOW TABLE STATUS 명령어가 실행될 때
- INFORMATION_SCHEMA.TABLES나 INFORMATION_SCHEMA>STQATISTICS가 조회되었을 때
- 많은 수의 행이 갱신될 때 갱신된 행의 수가 인덱스 통계의 자동 갱신을 유발하기에 조금 모자란 경우에 잘못된 인덱스를 선택할 수 있다.
테이블 조인 알고리즘#
- 기본 테이블 조인 알고리즘은 중첩 반복 조인이라고 하며 코드에서 사용하는 중첩 foreach 반복문처럼 작동한다.

- 중첩 반복 조인 알고리즘의 문제점
- 가장 안쪽 테이블에 상당히 자주 접근하고 풀 조인을 하면 접근 속도가 매우 느려진다.
- t3에는 t1과 t2에 일치하는 행의 개수만큼 접근한다.
- 이 문제점을 해결하기 위해서 블록 중첨 반복 조인 알고리즘을 사용한다.
- t1과 t2에서 일치하는 행의 조인 열값을 조인 버퍼에 저장한다.
- 조인 버퍼가 가득 차면 t3을 스캔하고 조인 버퍼의 조인 열과 일치하는 각 t3 행을 조인한다.
- 조인 버퍼의 크기는 시스템 변수
join_buffer_size에 설정된다. - 조인 버퍼는 메모리에 있어 빠르고, 중첩 중복 조인 알고리즘보다 접근 수가 적어진다.
- MySQL 8.0.20부터 해시 조인 알고리즘이 블록 중첩 반복 조인 알고리즘을 대체한다.
- t3 같은 조인 테이블을 메모리 내에 해시 테이블로 생성한다.
- MySQL은 해시 테이블을 사용하여 조인 테이블의 행을 조회하는데, 해시 테이블 조회는 사웃 시간 연산이기 때문에 매우 빠르다.
- 참고 사진