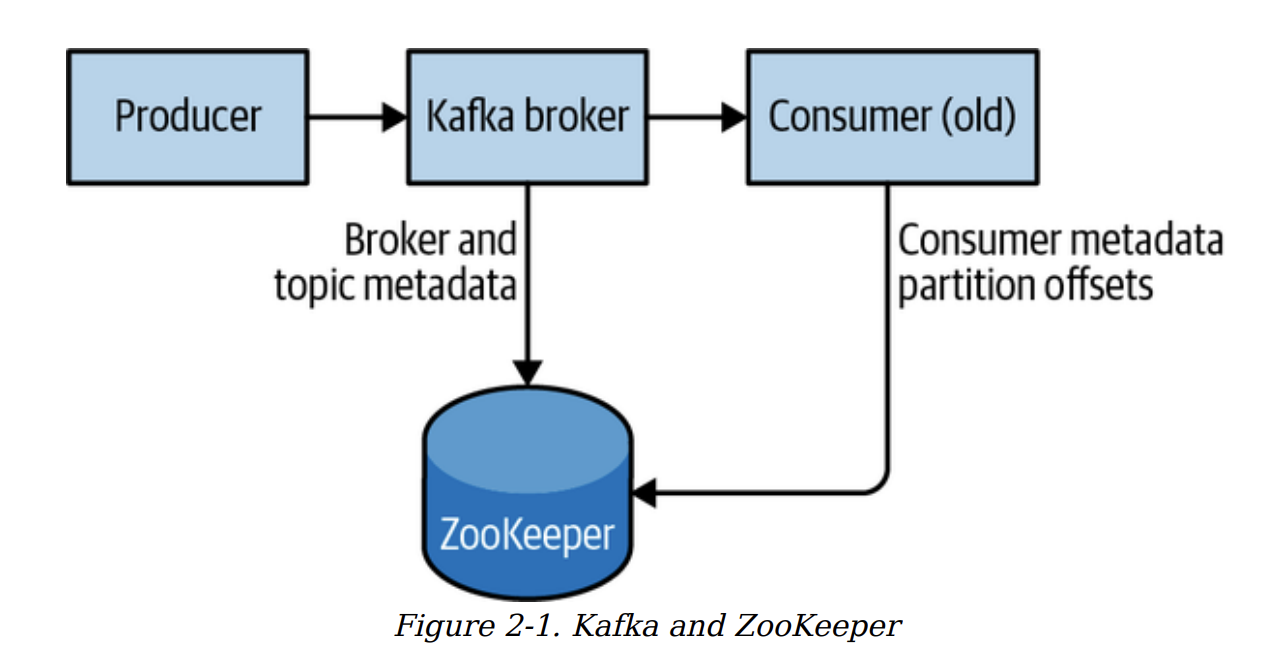
환경 설정# 운영체제 선택하기# 아파치 카프카는 다양한 운영체제에서 실행이 가능한 자바 애플리케이션이다. 카프카는 윈도우, macOS, 리눅스 등 다양한 운영체제에서 실행이 가능하지만, 대체로 리눅스가 권장된다. 주키퍼 설치하기# 아파치 카프카는 카프카 클러스터의 메타데이터와 컨슈머 클라이언트에 대한 정보를 저장하기 위해 아파치 주키퍼를 사용한다. 주키퍼는 설정 정보 관리 이름 부여, 분산 동기화, 그룹 서비스를 제공하는 중앙화된 서비스이다. 독립 실행 서버이 가능하다. 주키퍼는 고가용성을 보장하기 위해 앙상블이라 불리는 클러스터 단위로 작동하도록 설계되었다. 주키퍼가 사용하는 부하 분산 알고리즘 때문에 앙상블은 홀수 개의 서버를 가지는 것이 권장된다.주키퍼가 요청에 응답하려면 앙상블 멤버(쿼럼이라고 부른다)의 과반 이상이 작동하고 있어야 하기 때문이다. 주키퍼 앙상블을 구성할 때는 5개의 노드 크기를 고려하자.앙상블 설정을 변경할 수 있게 하려면, 한 번에 한 대의 노드를 정지시켰다가 설정을 변경한 뒤 다시 시작해야 한다. 만약 앙상블이 2대 이상의 노드 정지를 받아낼 수 없다면, 정비 작업을 수행하는 데는 위험이 따를 수밖에 없다. 그렇다고 해서 9대 이상의 노드를 사용하는 것도 권장하는 않는데,합의 프로토콜 특성상 성능이 내려가기 시작할 수 있기 때문이다. 또한, 클라이언트 연결이 너무 많아서 5대 혹은 7대의 노드가 부하를 감당하기에 모자란다는 생각이 들면 옵저버 노드를 추가함으로써 읽기 전용 트래픽을 분산시킬 수 있도록 해 보자. 주키퍼 서버를 앙상블로 구성하기 위해 필요한 2가지각 서버는 공통된 설정 파일을 사용해야 한다. 각 서버는 데이터 디렉토리에 자신의 ID 번호를 지정하는 myid 파일을 가지고 있어야 한다. 설정 파일dataDir: 데이터 디렉토리 경로. 해당 경로에 자신의 ID 번호를 지정하는 myid 파일을 가지고 있어야 한다.initLimit: 팔로워가 리더와 연결할 수 있는 최대 시간. 이 시간 동안 리더와 연결을 못 하면 초기화에 실패한다.syncLimit: 팔로워가 리더와 연결할 수 있는 최대 시간. 이 시간 동안 리더와 연결을 못 하면 동기화가 풀린다.initLimit과 syncLimit 값은 tickTime 단위로 정의되는데, 위 예시에서 초기화 제한 시간은 20*2000밀리초, 즉 40초가 된다.설정 파일에는 앙상블 안의 모든 서버 내역을 정의한다.server.{X}={hostname}:{peerPort}:{leaderPort} 꼴로 정의된다.X: 서버의 ID. 정숫값이어야 하지만, 0부터 시작할 필요도 없고 순차적으로 부여될 필요도 없다.hostname: 서버의 호스트명 또는 IP 주소peerPort: 앙상블 안의 서버들이 서로 통신할 때 사용되는 TCP 포트 번호leaderPort: 리더를 선출하는 데 사용되는 TCP 포트 번호 clientPort: 클라이언트가 앙상블에 연겨할 때 사용할 수 있는 포트 번호 카프카 브로커 설치하기# 자바와 주키퍼가 설정되었다면 아파치 카프카를 설치할 수 있다. 브로커 설정하기# 핵심 브로커 매개변수# 어떤 환경에서 카프카를 설치하던 간에 살펴봐야만 하는 브로커 설정 매개변수 broker.id카프카 브로커의 정숫값 식별자. 기본값은 0이지만, 어떤 값도 될 수 있다. 이 정숫값이 클러스터 안의 각 브로커별로 전부 달라야 한다. listeners외부와 통신할 때 어떤 주소로 열려있을지 설정한다. {프로토콜}://{호스트 이름}:{포트}의 형태로 정의된다.예시) PLAINTEXT://localhost:9092,SSL://:9091 호스트 이름을 0.0.0.0으로 잡아줄 경우 모든 네트워크 인터페이스로부터 연결을 받게되며, 이 값을 비워 주면 기본 인터페이스에 대해서만 연결을 받게 된다. 1024 미만의 포트 번호를 사용할 경우 루트 권한으로 카프카를 실행시켜야 한다. 만약 리스너 이름이 일반적인 보안 프로토콜이 아니라면, 반드시 listener.security.protocol.map 설정을 잡아주어야 한다. zookeeper.connect브로커의 메타데이터가 저장되는 주키퍼의 위치 세미콜론으로 연결된 {호스트 이름}:{포트}/{경로}의 목록 형시으로 지정할 수 있다. 호스트 이름: 주키퍼 서버의 호스트 일므이나 IP 주소포트: 주키퍼의 클라이언트 포트 번호/{경로}: 선택 사항. 카프카 클러스터의 chroot 환경으로 사용될 주키퍼 경로. 지정하지 않으면 루트 디렉토리가 사용된다.대체로 카프카 클러스터에는 chroot 경로를 지정하는 것이 좋다. 다른 애플리케이션과 충돌할 일 없이 주키퍼 앙상블을 공유해서 사용할 수 있기 때문이다. 같은 앙상블에 속하는 다수의 주키퍼 서버를 지정하는것이 좋다.특정 서버에 장애가 생기더라도 카프카 브로커가 같은 주키퍼의 달느 서버에 연결할 수 있기 때문이다. log.dirs카프카는 모든 메시지를 로그 세그먼트 단위로 묶어서 log.dir 설정에 저장된 디스크 디렉토리에 저장한다. 다수의 디렉토리를 지정하고자 할 경우, log.dirs를 사용하는 것이 좋다. log.dirs가 설정되어 있지 않을 경우, log.dir가 사용된다.log.dirs는 쉼표로 구분된 로컬 시스템 경로의 목록이다.1개 이상의 경로가 지정되었을 경우, 브로커는 가장 적은 수의 파티션이 저장된 디렉토리에 새 파티션을 저장할 것이다.같은 파티션에 속하는 로그 세그먼트는 동일한 경로에 저장된다. 사용된 디스크 용량 기준이 아닌 저장된 파티션 수 기준으로 새 파티션의 저장 위치를 배정한다는 점에서, 다수의 디렉토리에 대해 균등한 양의 데이터가 저장되지 않는다. num.recovery.threads.per.data.dir카프카는 스레드 풀을 사용해서 로그 세그먼트를 관리한다. 이 스레드 풀은 아래와 같은 작업을 수행한다.브로커가 정상적으로 시작되었을 때, 각 파티셔의 로그 세그먼트 파일을 연다. 브로커가 장애 발생 후 다시 시작되었을 때, 각 파티션의 로그 세그먼트를 검사하고 잘못된 부분은 삭제한다. 브로커가 종료할 때, 로그 세그먼트를 정상적으로 닫는다. 기본적으로, 하나의 로그 디렉토리에 대해 하나의 스레드만 사용된다. 이 스레드들은 브로커가 시작될 때와 종료될 때만 사용되기 때문에 작업을 병렬화하기 위해서는 많은 수의 스레드를 할당해주는 것이 좋다. 이 설정값을 잡아 줄 때는 log.dirs에 지정된 로그 디렉토리별 스레드 수라는 점을 명심해야 된다.예시) num.recovery.threads.per.data.dir이 8이고 log.dirs에 지정된 경로 수가 3개일 경우, 전체 스레드 수는 24개가 된다. auto.create.topics.enable카프카 기본 설정에서는 아래와 같은 상황에서 브로커가 토픽을 자동으로 생성하도록 되어 있다.프로듀서가 토픽에 메시지를 쓰기 시작할 때 컨슈머가 토픽으로부터 메시지를 읽기 시작할 때 클라이언트가 토픽에 대한 메타데이터를 요청할 때 토픽 자동 생성은 바람직하지 않은 경우가 많다.특히 카프카에 토픽을 생성하지 않고 존재 여부만 확인할 방법이 없다는 점이 그렇다. 만약 토픽 생성을 명시적으로 관리하고자 할 경우, auto.create.topics.enable 설정값을 false로 놓을 수 있다. auto.leader.rebalance.enable모든 토픽의 리더 역할이 하나의 브로커에 집중됨으로써 카프카 클러스터의 균형이 깨지는수가 있다. 이 설정을 활성화해주면 가능한 한 리더의 역할이 균등하게 분산되도록 함으로써 이러한사태를 발생하는 것을방지할 수 있다. 이 설정을 켜면 파티션의 분포 상태를 주기적으로 확인하는 백그라운드 스레드가 시작된다.이 주기는 leader.imbalance.check.interval.seconds로 설정이 가능하다. 만약 전체 파티션 중 특정 브로커에 리더 역할이 할당된 파티션 비율이 leader.imbalance.per.broker.percentage에 설정된 값을 넘어가면파티션의 선호 리더 리밸런싱이 발생한다. delete.topic.enable환경과 데이터 보존 가이드라인에 따라 클러스터의 토픽을 임의로 삭제하지 못하게끔 막아야 할 때가 있다. 이 플래그를 flase로 잡아 주면 토픽 삭제 기능이 막힌다. 토픽별 기본값# 카프카 브로커 설정은 새로 생성되는 토픽에 적용되는 설정의 기본값 역시 지정한다. num.partitions새로운 토픽이 생성될 떄 몇 개의 파티션을 갖게 되는지를 결정하며, 주로 자동 토픽생성 기능이 활성화되어 있을 때 사용된다. 기본값은 1 토픽의 파티션 개수는 늘릴 수만 있지 줄일 수는 없다. 브로커가 추가될 때 클러스터 전체에 걸쳐 메시지 부하가 고르게 분산되도록 파티션 개수를 잡아 주는 게 중요하다. 많은 사용자들은 토픽당 파티션 개수를 클러스터 내 브로커 수와 맞추거나 아니면 배수로 설정한다. 파티션은 많아야 하지만 그렇다고 해서 너무 많으면 부하가 될 수 있다.너무 많은 파티션은 브로커의 메모리와 다른 자원들을 사용할 뿐만 아니라 메타데이터 업데이트나 리더 역할 변경에 걸리는 시간 역시 증가시킨다. 만약 토픽의 목표 처리량과 컨슈머의 예상 처리량에 대해 어느 정도 추정값이 있다면 전자를 후자로 나눔으로써 필요한 파티션 수를 계산할 수 있다.예시) 주어진 토픽에 초당 1GB를 읽거나 쓰고자 하는데, 컨슈머 하나는 초당 50MB만 처리가 가능하다고 하면 최소한 20개의 파티션이 필요하다고 예측할 수 있는 것이다. 만약 상세한 정보가 없다면, 경험상 매일 디스크 안에 저장되어 있는 파티션의 용량을 6GB 미만으로 유지하는 것이 대체로 결과가 좋았다. default.replication.factor자동 토픽 생성 기능이 활성화되어 있을 경우, 이 설정은 새로 생성되는 토픽의 복제 팩터를 결정한다. 레플리카 셋 안에 일부러 정지시킨 레플리카와 예상치 않게 정지된 레플리카가 동시에 하나씩 발생해도 장애가 발생하지 않기위해, 최소한 3개의 레플리카를 가져야 한다. log.retention.ms카프카가 얼마나 오랫동안 메시지를 보존해야 하는지를 지정할 떄 가장 많이 사용되는 설정이 시간 기준 보존 주기 설정이다. 기본값은 log.retention.hours 설정을 사용하면 168시간(1주일)이다. 또 다른 단위로 log.retention.minutes나 log.retention.ms를 사용할 수도 있다. 1개 이상의 설정이 정의되었을 경우 더 작은 단위 설정값이 우선권을 가진다. log.retention.bytes메시지 만료의 또 다른 기준은 보존되는 메시지의 용량이다. 파티션 단위로 적용된다.만약 8개의 파티션을 가진 토픽에 log.retention.bytes 설정값이 1GB로 잡혀 있다면, 토픽의 최대 저장 용량은 8GB가 되는 것이다. -1로 설정하면 데이터는 영구 보존된다. log.retention.bytes 설정과 log.retention.ms 설정을 둘 다 잡아 주었다면, 두 조건 중 하나의 조건만 성립해도 메시지가 삭제될 수 있다.log.segment.bytes로그 세그먼트의 크기가 log.segment.bytes에 지정된 크기에 다다르면, 브로커는 기존 로그 세그먼트를 다고 새로운 세그먼트를 연다. 로그 세그먼트는 닫히기 전까지는 만료와 삭제의 대상이 되지 않는다. 작은 로그 세그먼트 크기는 파일을 더 자주 닫고 새로 할당한다는 것이다. 토픽에 메시지가 뜸하게 주어지는 상황에서는 로그 세그먼트의 크기를 조절해주는 것이 중요하다.예시) 토픽에 들어오는 메시지가 하루에 100MB인 상황에서 log.segment.bytes가 기본값으로 잡혀 있다면 세그먼트 하나를 채울 때까지 10일이 걸린다. 로그 세그먼트가 닫히기 전까지 메시지는 만료되지 않으므로 log.retention.ms가 1주일로 잡혀 있을 경우 닫힌 로그 세거믄터가 만료될 떄까지 실제로는 최대 17일치 메시지가 저장되어 있을 수 있다. log.roll.ms로그 세그먼트 파일이 닫히는 시점을 제어하는 또 다른 방법으로 파일이 닫혀야 할 때까지 기다리는 시간이다. log.retention.bytes와 log.roll.ms 중 하나라도 도달한 경우 세그먼트를 닫는다.min.insync.replicas데이터 지속성 위주로 클러스터를 설정할 때, min.insync.replicas를 2로 잡아주면 최소한 2개의 레플리카가 최신 상태로 프로듀서와 동기화되도록 할 수 있다. 이것은 프로듀서의 ack 설정을 ‘all’로 잡아 주는 것과 함께 사용한다.이렇게 하면 프로듀서의 쓰기 작업이 성공하기 우해 최소한 두 개의 레플리카가 응답하도록 할 수 있다. 이것은 아래와 같은 상황에서 데이터 유실을 방지할 수 있다.리더가 쓰기 작업에 응답한다. 리더에 장애가 발생한다. 리더 역할이 최근의 쓰기 작업 내역을 복제하기 전의 다른 레플리카로 옮겨진다. 지속성을 높이기 위해 이 값을 올려잡아 줄 경우 추가적인 오버헤드가 발생하면 성능이 떨어지는 부작용이 발생할 수 있다.따라서 몇 개의 메시지 유실 정도는 상관없고, 높은 처리량을 받아내야 하는 클러스터의 경우, 이 설정값을 기본값인 1에서 변경하지 않을 것을 권장한다. message.max.bytes카프카 브로커는 쓸 수 있는 메시지의 최대 크기를 제한한다. 기본값은 1MB이다. 프로듀서가 여기에 지정된 값보다 더 큰 크기의 메시지를 보내려고 시도하면 브로커는 메시지를 거부하고 에러를 리턴할 것이다. 카프카 브로커에 설정되는 메시지 크기는 컨슈머 클라이언트의 fetch.message.max.bytes 설정과 맞아야 한다. 하드웨어 선택하기# 전체적인 성능에 영향을 미칠 수 있는 요소들이 몇 개 있다. 카프카를 매우 크게 확장할 경우, 업데이트되어야 하는 메타데이터의 양 때문에 하나의 브로커가 처리할 수 있는 파티션의 수에도 제한이 생길 수 있다. 디스크 처리량# 로그 세그먼트를 저장하는 브로커 디스크의 처리량은 프로듀서 클라이언트의 성능에 가장 큰 영향을 미친다. 디스크 쓰기 속도가 빨라진다는 것은 곧 쓰기 지연이 줄어드는 것이다.카프카에 메시지를 쓸 때는 메시지는 브로커의 로컬 저장소에 커밋되어야 하며, 대부분의 프로듀서 클라이언트는 메시지 전송이 성공했다고 결론 내리기 전에 최소한 1개 이상의 브로커가 메시지가 커밋되었다고 응답을 보낼 때까지 대기하게 된다. 디스크 용량# 필요한 디스크 용량은 특정한 시점에 얼마나 많은 메시지들이 보존되어야 하는지에 따라 결정한다. 만약 브로커가 하루에 1TB의 트래픽을 받을 것으로 예상되고, 받은 메시지를 1주일간 보존해야 한다면, 브로커는 로그 세그먼트를 저장하기 위한 저장 공간이 최소한 7TB가 필요할 것이다. 메모리# 카프카 컨슈머는 프로듀서가 막 추가한 메시지를 바로 뒤에서 쫓아가는 식으로 파티션의 맨 끝에서 메시지를 읽어 오는 것이 보통이다. 이러한 상황에서, 최적의 작동은 시스템의 페이지 캐시에 저장되어 있는 메시지들을 컨슈머가 읽어오는 것이 된다. 카프카 그 자체는 JVM에 많은 힙 메모리를 필요로 하지 않는다. 시스템 메모리의 페이지 캐시로 사용되어 시스템이 사용중인 로그 세그먼트를 캐시하도록 함으로써 카프카의 성능을 향상시킬 수 있는 것이다.이것은 카프카를 하나의 시스템에 다른 애플리케이션과 함께 운영하는 것을 권장하지 않는 주된 이유다. 이 경우 페이지 캐시를 나눠서 쓰게 되기 때문이고, 이것은 카프카의 컨슈머 성능을 저하시킨다. 네트워크# 사용 가능한 네트워크 대역폭은 카프카가 처리할 수 있는 트래픽의 최대량을 결정한다.카프카 특유의 네트워크 불균형 때문에 복잡해지는데, 카프카가 다수의 컨슈머를 동시에 지원하기 때문에 인입되는 네트워크 사용량과 유출되는 네트워크 사용량 사이에 불균형이 생길 수밖에 없는 것이다. 네트워크 인터페이스가 포화상태에 빠질 경우, 클러스터 내부의 복제 작업이 밀려서 클러스터가 취약한 상태로 빠질 수 있다. 네트워크 문제가 불거져 나오는 것을 방지하기 위해서는 최소한 10GB 이상을 처리할 수 있는 네트워크 인터페이스 카드를 사용할 것을 권장한다. CPU# 카프카 클러스터를 매우 크게 확장하지 않는 한, 처리 능력은 디스크나 메모리만큼 중요하지는 않다. 하지만 브로커의 전체적인 성능에는 어느 정도 영향을 미친다.이상적으로는 네트워크와 디스크 사용량을 최적화하기 위해 클라이언트가 메시지를 압축해서 보내야 하는데, 카프카 브로커는 각 메시지의 체크섬을 확인하고 오프셋을 부여하기 위해 모든 메시지 배치의 압축을 해제해야 하기 때문이다. 브로커는 이 작업이 끝난 뒤에야 디스크에 저장하기 위해서 메시지를 다시 압축하게 된다. 카프카 클러스터 설정하기# 여러 대의 브로커를 하나의 클러스터로 구성하는 것의 장점부하를 다수의 서버로 확장할 수 있다. 복제를 사용함으로써 단일 시스템 장애에서 발생할 수 있는 데이터 유실을 방지할 수 있다. 브로커 개수를 결정하는 요소# 디스크 용량필요한 메시지를 저장하는 데 필요한 디스크 용량과 단일 브로커가 사용할 수 있는 저장소 용량이 얼마인가? 브로커당 레플리카 용량복제 팩터를 증가시킬 경우 필요한 저장 용량이 최소 100% 이상 증가하게 된다. 분산이 이상적으로 된 상황에도 레플리카가 과도하게 많다면 읽기, 쓰기, 컨트롤러 큐 전체에 걸쳐 병목 현상을 발생시킬 수 있다. 현재로서는 파티션 레플리카 개수를 브로커당 14000개, 클러스터당 100만개 이하로 유지하는 것을 권장한다. CPU 용량대개 병목 지점이 되지 않는다. 하지만 브로커 하나에 감당할 수 없는 수준의 클라이언트 연결이나 요청이 쏟아지게 되면 그렇게 될 수도 있다. 네트워크 용량네트워크 인터페이스의 전체 용량이 얼마인지? 데이터를 읽어가는 컨슈머가 여럿이거나, 데이터가 보존되는 동안 트래픽이 일정하지 않을 경우(에를 들어서, 피크 시간대에 트래픽이 집중적으로 쏟아지는 경우)에도 클라이언트 트래픽을 받아낼 수 있는지? 브로커 설정# 모든 브로커들이 동일한 zookeeper.connect 설정값을 가져야 하는 것이다. 이것은 클러스터가 메타데이터를 저장하는 주키퍼 앙상블과 경로릴 지정한다. 클러스터 안의 모든 브로커가 유일한 broker.id 설정값을 가져야 한다. 운영체제 튜닝하기# 가상 메모리메모리의 페이지가 디스크로 스와핑되는 과정에서 발생하는 비용은 카프카 성능의 모든 측면에 있어서 눈에 띄는 영향을 미칠 수 있다.스와핑을 방지하는 방법 중 하나는 아예 스왑 공간 자체를 할당하지 않는 것이다. 스왑 공간이 있으면 메모리가 부족할 때 운영체제가 실행 프로세스를 강제로 종료시키는 것을 방지할 수 있다. 이러한 이유 때문에 vm.swappiness 설정을 매우 작은 값(1이라던가)으로 잡아주는 것이 좋다.이 매개변수는 가상 메모리 서브 시스템이 페이지 캐시로 사용할 지 아니면 스왑 공간으로 사용할지에 대한 선호도를 백분율로 나타낸 것이다. 0이 아닌 이유는 0의 의미가 “어떠한 경우에도 스와핑하지 말라"이기 때문이다. 커널이 디스크로 내보내야 할 더티 페이지를 다루는 방식을 조정해주는 것에도 이점이 있다.vm.dirty_background_ratio 설정값을 기본값인 10보다 작게 잡아주면 된다.이 값은 전체 시스템 메모리에서 더티 페이지가 차지할 수 있는 비율로 나타내는 것이며, 많은 경우 5로 잡아주는게 적절하다. 하지만 0으로 설정하면 안 되는데, 리눅스 커널이 더티 페이지를 버퍼링하지 않고 계속해서 디스크로 내보내려고 하기 때문에 저장 장치 성능이 일시적으로 튀어오르는 사태가 발생하기 때문이다. 리눅스 커널이 더티 페이지를 강제로 디스크로 동기적으로 내보내기 전에 유지할 수 있는 더테 페이지의 전체 수는 vm.dirty_ratio 설정값을 올려잡아 줌으로써 증가시킬 수 있다.기본값은 20인데, 60에서 80 사이가 바람직하다. 이 설정은 아래와 같이 약간의 위험을 발생시킨다.밀린 디스크 쓰기 작업이 늘어날 수 있다. 더티 페이지를 동기적으로 내보내야 할 경우, I/O 멈춤이 길어질 수 있다. 카프카는 로그 세그먼트를 저장하고 연결을 열기 위해 파일 디스크립터를 사용한다.만약 브로커에 많은 파티션이 저장되어 있을 경우, 브로커는 최소한 아래와 같은 수의 파일 디스크립터를 필요로 한다.{파티션 수} * ({파티션 크기} / {세그먼트 크기}) + {브로커에 생성된 네트워크 연결 수} vm.max_map_count 설정값을 위 계산에 근거해서 매우 큰 값으로 올려잡아 줄 것을 권장한다. vm.overcommit_memory 설정값을 0으로 잡아 주는 것이 권장된다.기본값인 0이 아닌 값으로 잡아줄 경우 운영체제가 지나치게 많게 메모리를 차지함으로써 카프카가 최적으로 작동하기 위한 메모리가 모자라게 될 수 있다. 디스크net.core.wmem_default, net.core.rem_defaultnet.core.wmem_max, net.core.rmem_maxnet.ipv4.tcp_wmem, net.ipv4.tcp_rmemTCP 소켓의 송신, 수신 버퍼 크기 역시 별도 설정 해주어야 한다. net.ipv4.tcp_window_scaling값을 1로 잡아 줌으로써 TCP 윈도우 스케일링 기능을 활성화시키면 클라이언트가 데이터를 더 효율적으로 전달할 수 있도록 할 수 있다. net.ipv4.tcp_max_syn_backlog설정값을 기본값인 1024보다 크게 잡아줄 경우 브로커가 동시에 받을 수 있는 연결의 수를 증가시킬 수 있다. net.core.netdev_max_backlog기본값인 1000보다 더 큰 값으로 올려잡아 줌녀 커널이 처리해야 할 패킷을 더 많이 큐에 올릴 수 있게 되기 때문에 네트워크 트래픽이 급즈할 때 도움이 된다. 프로덕션 환경에서의 고려 사항# 가비지 수집기 옵션# 현재 카프카에서는 G1GC를 기본 가바지 수집기로 사용할 것이 권장된다.G1GC는 전체 힙을 한 번에 처리하는 대신 여러 개의 작은 영역으로 나눠서 처리함으로써 커다란 크기를 가진 힙 영역을 더 잘 처리한다. G1GC의 성능을 조절하기 위해 사용되는 옵션 두 가지MaxGCPauseMillis각 가비지 수집 사이클에 있어서 선호되는 중단 시간을 지정한다. 이것은 고정된 최대값이 아니며, 필요한 경우 G1GC는 여기에 지정된 시간을 넘겨서도 실행될 수 있다. 기본값은 200밀리초다. 풀어서 설명하자면 다음과 같다.가비지 수집기가 호출되는 주기를 가능한 한 200ms로 맞춘다. 단위 사이클에 걸리는 시간 역시 200ms 정도로 맞춘다. 즉, 이 시간에 맞춰서 가비지 수집이 실행되는 영역의 개수를 조절한다. InitiatingHeapOccupancyPercentG1GC가 수집 사이클을 시작하기 전까지 전체 힙에서 사용 가능한 비율을 백분율로 지정한다. 기본값은 45인데 ,이는 전체 힙의 45%가 사용되기 전까지는 G1GC가 가비지 수집 사이클을 시작하지 않는다는 의미다. 카프카 브로커는 힙 메모리를 상당히 효율적으로 사용할 뿐 아니라 가비지 수집의 대상이 되는 객체 역시 가능한 한 적게 생성하기 때문에 이 설정값들을 낮게 잡아줘도 괜찮다. 데이터센터 레이아웃# 카프카는 브로커에 새 파티션을 할당할 때 랙 위치를 고려함으로써 특정 파티션의 레플리카가 서로 다른 랙에 배치되도록 할 수 있다.이 기능을 사용하려면 각 브로커에 broker.rack 설정을 잡아주어야 한다. 카프카 클러스터는 파티션이 랙 인식 할당을 유지하고 있는지 모니터링하지 않으며, 자동으로 이를 교정하지도 않는다.랙 인식 할당을 유지함으로써 클러스터의 균형을 유지하고 싶다면, 크루즈 컨트롤과 같은 툴을 사용할 것은 권한다. 카프카 클러스터의 각 브로커가 서로 다른 랙에 설치되오록 하거나 아니면 최소한 전원이나 네트워크 같은 인프라스트럭처 서비스의 측면에서 단일 장애점이 없도록 하는 것이 모범적인 방법이다. 주키퍼 공유하기# 컨슈머 그룹 멤버나 카프카 클러스터 자체에 뭔가 변동이 있을 때만 주키퍼 쓰기가 일루어진다. 이 트래픽은 작은 것이 보통이기 때문에 굳이 하나의 주키퍼 앙상블을 하나의 카프카 클러스터에만 사용할 필요는 없다. 사실, 많은 경우 하나의 주키퍼 앙상블을 여러 대의 카프카 클러스터가 공유해서 쓰기도 한다. 설정에 따라서는 컨슈머와 주키퍼가 직접 연관될 수도 있지만, 컨슈머 애플리케이션을 개발할 때는 주키퍼에 대한 의존성 없이 카프카를 사용해서 오프셋을 커밋하는 최신 카프카 라이브러리를 사용할 것이 권장된다. 다수의 카프카 클러스터가 하나의 주키퍼 앙상블을 공유하는 경우를 제외한면, 다른 애플리케이션과 주키퍼 앙상블을 공유하는 것은 피할 수 있다면 피하는 것이 좋다.카프카는 주키퍼의 지연과 타임아웃에 민감한 시스템이고, 앙상블과 통신에 중단이 발생할 경우 브로커들이 예상치 못한 방식으로 작동할 수 있다. Please enable JavaScript to view the comments powered by Disqus. comments powered by