문서 색인과 조회
색인 API
4가지 API
PUT /<target>/_doc/<_id>POST /<target>/_doc/PUT /<target>/_create/<_id>POST /<target>/_create/<_id>
문서 ID를 지정해서 새 문서를 추가하려면
PUT /<target>/_create/<_id>형식을 사용해야 된다.<target>: 인덱스 이름- 대상이 존재하지 않고 데이터
<_id>: 문서 식별자예시
색인 API 호출시 flow
- 기존에 숫자 형태로 정의된 필드에 문자 형태의 값이 들어오면 스키마 충돌이라고 판단하고 에러를 출력한다.
- 에러가 출력되면 해당 문서는 기본적으로는 색인되지 않는다.
- 기존 문서를 업데이트하면 문서의
_version값이 올라간다. 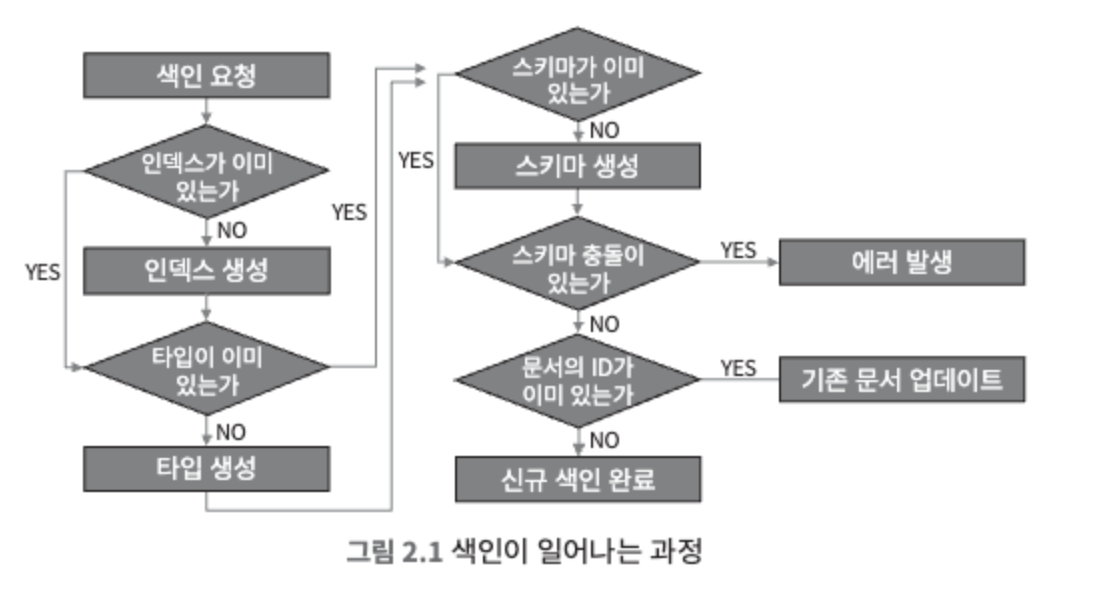
문서 색인 없이 인덱스만 색인할 수도 있다.
PUT /<index>

조회 API
GET /<index>/_doc/<_id>- 예시

_index: 어떤 인덱스에 있는지_type: 어떤 타입인지_id: 문서의 ID_source: 문서의 내용
삭제 API
DELETE /<index>/_doc/<_id>- 예시:
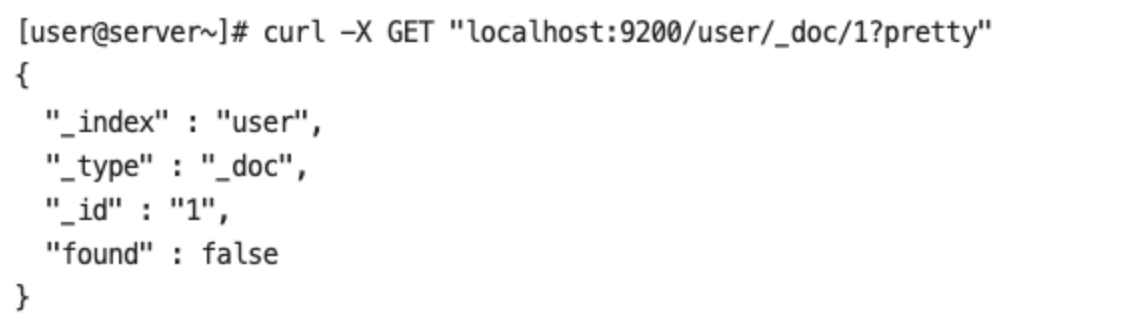
- 삭제 후에 조회하면 다음과 같은 결과가 나온다.

스키마 조회
GET /<target>/_mapping<target>: 인덱스, 데이터 스트림, alias 등이 될 수 있다.
- 예시
- 색인한 무넛에 author와 title 필드가 정의되었고 둘 다 문자열 형태의 타입으로 정의된 것을 볼 수 있다.

문서 검색하기
- 검색 결과를 읽는 법 위주로 이해한다.
GET /<target>/_searchGET /_searchPOST /<target>/_searchPOST /_search
- 모든 데이터 풀 스캔
q=*: 모든 단어를 쿼리로 설정took: 검색에 소요된 시간(ms)_shards.total: 검색에 참여한 샤드의 개수hits.total: 검색 결과의 개수
- 평점이 5.0인 책 검색
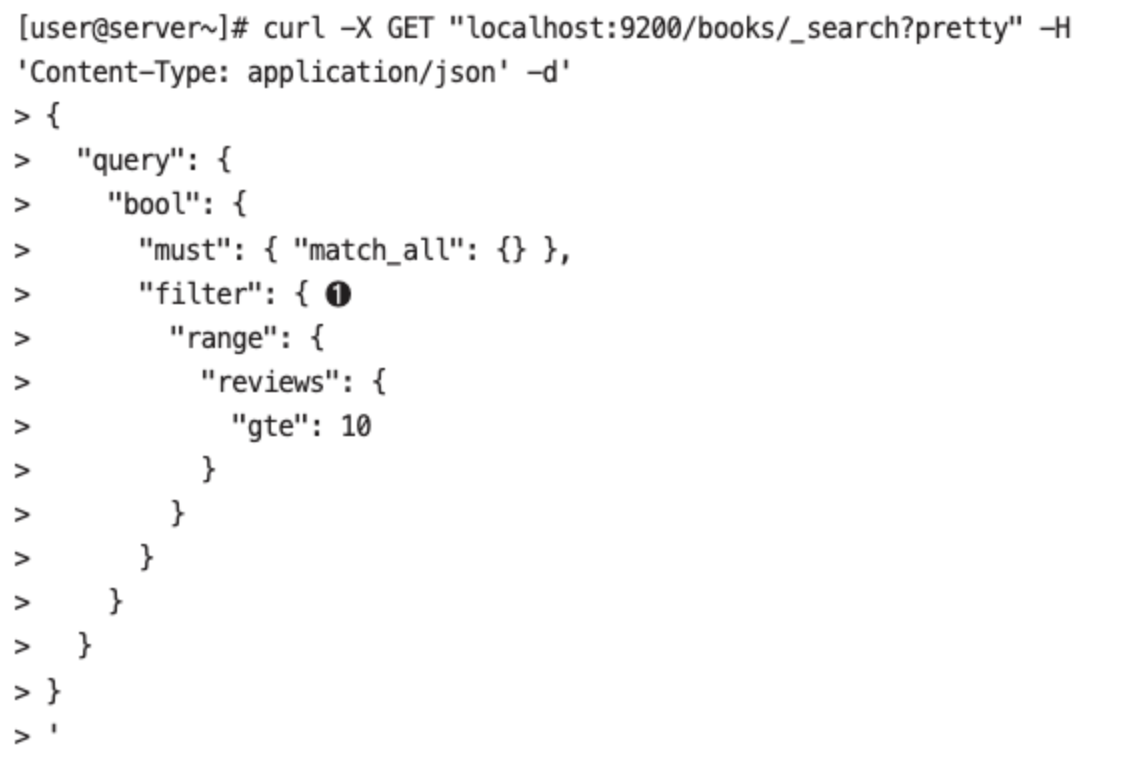
- 책에 대한 리뷰가 10개 이상인 책 검색
- 필터와 쿼리는 다르다.
- 쿼리: 문자열 안에 특정 문자가 포함되었는지 아닌지를 확인하는 과정
- 필터: 예/아니오로 구분하는 방식

문서 분석하기
- ElasticSearch에서는 검색 작업을 바탕으로 분석 작업도 할 수 있다.
- 분석 작업을 aggregation이라고 부르며 search API를 기반으로 진행된다.
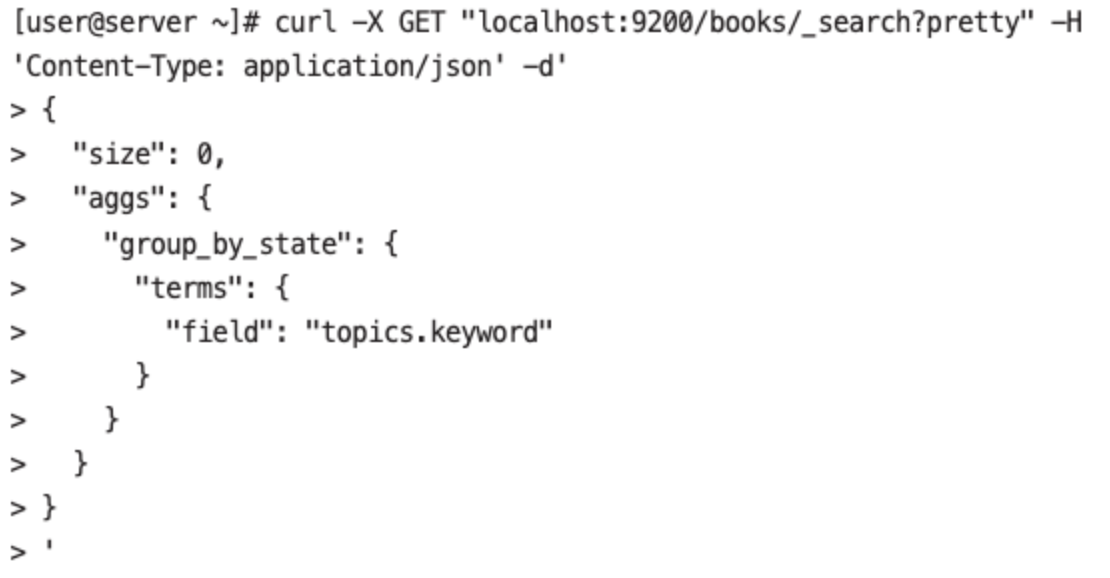
- 책들 중에 topics에 어떤 단어가 가장 많은지
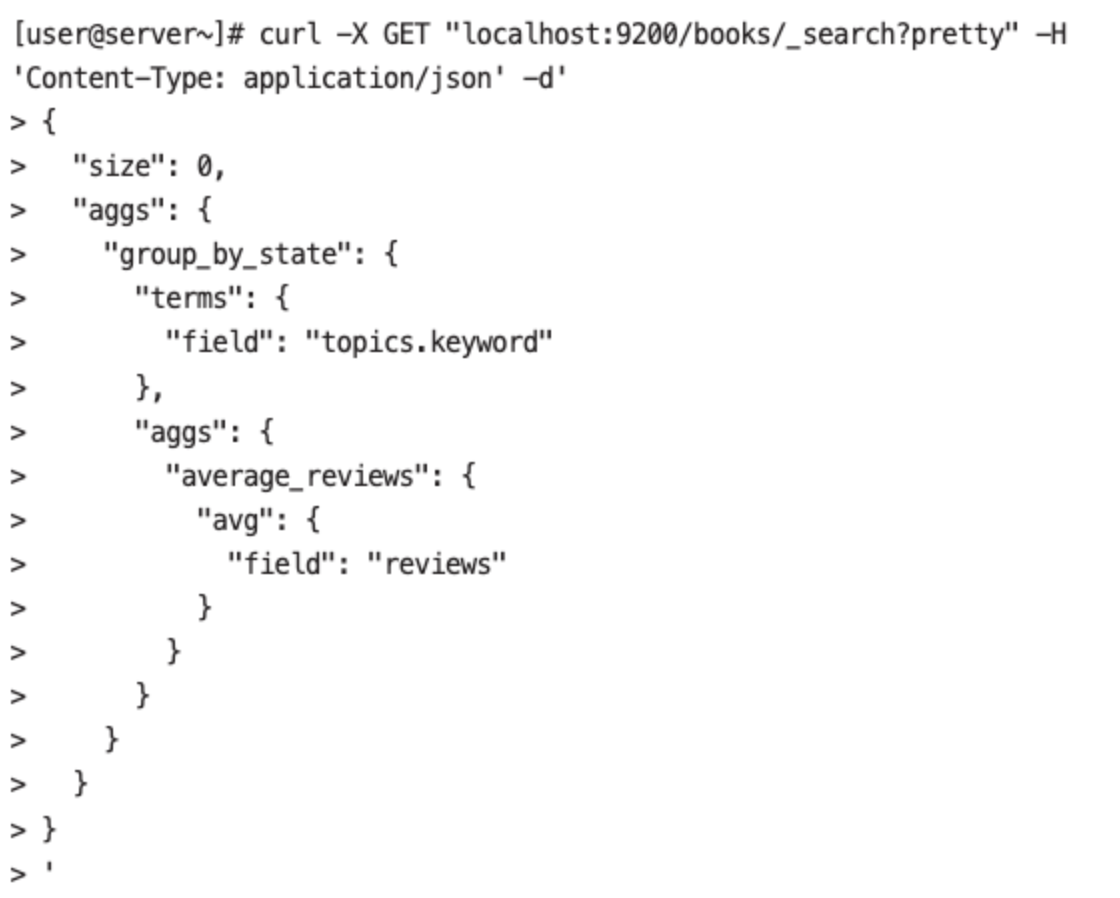
- 토픽별로 평균 몇 개의 리뷰가 생성되어 있는지
- 보통 분석 작업은 직접 쿼리를 생성하기보다는 Kibana 혹은 Grafana 같은 시각화 툴을 사용한다.
- 분석 작업은 경우에 따라 매우 많은 양의 힙 메모리를 필요로 할 수 있기 때문에 시각화 툴을 사용할 때에는 조심해야 한다.