LLM은 무엇인가?
- LLM: 텍스트를 입력하면 텍스트가 출력되는 서비스
- LLM은 학습 데이터셋이라고 하는 방대한 문서를 활용해 훈련한다.
- 학습 데이터셋에서 모델은 학습 데이터셋과 유사해 보이는 출력을 생성하는 방법을 배워야 한다.
- 과적합: 모델이 학습 데이터셋의 패턴을 학습하는 대신 문장 덩어리르 암기하는 것
문장 자동 완성
- 학습 데이터를 잘 알수록 그 학습 데이터에서 학습된 LLM이 어떤 결과를 만들어낼 가능성이 높은지에 대한 직관이 좋아진다.
인간 사고 vs LLM 처리
- 사람은 LLM과 달리 텍스트를 만들어낼 때 단지 그러릇해 보이는 문장을 만드는 것 이상의 과정을 거친다.
- 예시: 구글 검색 하기, 창문 밖을 확인하기
환각
- 환각: 사실이 아니지만 그럴듯 해보이는 정보를 자신 있게 생상하는 행동
- 모델에게 ‘없는 일을 꾸며내지 마라’ 같은 지시문보다는, 완성한 결과가 사실인지 여부를 확인해볼 만한 배경을 물어보는 것이 좋다.
LLM이 세상을 보는 방법
- 사람과 마찬가지로 LLM도 문자열을 읽을 때 단일 문자 단위로 읽지 않는다.
- 모델에 텍스트를 전송하면 텍스트를 토큰이라고 부르는 여러 문자로 구성된 단위로 나눈다.
- 토크나이저를 통해 텍스트를 토큰 시퀀스로 변환한 다음 LLM에 전달한다.
- LLM은 일련의 토큰을 생성하고, 이는 다시 텍스트로 변환된 다음 사용자에게 반환된다.
- LLM과 사람은 텍스트를 유사한 방식으로 보는 것 같지만 중요한 차이점이 있다.
차이점1: LLM은 결정적 토크나이저를 사용한다
- 사람은 자신이 본 글자 시퀀스와 가장 비슷한 단어를 찾으려고 한다.
- LLM은 결정적 코트아니저를 사용하기 떄문에 ‘ghost’와 ‘gohst’는 다른 토큰으로 번역된다.
- 그럼에도 불구하고 LLM은 일반적으로 학습 데이터셋에서 오타에 익숙해져 있기 떄문에 오타가 결과에 큰 영향을 미치지 않을 수 있다.
차이점2: LLM은 속도를 늦추고, 글자를 살펴볼 수 없다
- 인간들은 속도를 늦추고 각각의 글자를 의식적으로 검토할 수 있지만 LLM은 내장된 토크나이저만 사용할 수 있고 이 토크나이저는 속도를 늦출 수 없다.
- 토큰을 분해하고 재조립하는 일은 LLM에게 어려운 일이다.
- 예시: 단어의 문자를 뒤집기
차이점3: LLM은 텍스트를 다르게 본다
- 사람은 어떤 문자가 둥글고 어떤 문자가 네모난지 알지만, LLM은 알지 못한다.
- 대표 예: LLM은 대문자를 포함한 토큰과 소문자를 포함한 토큰을 다르게 한다.
- GPT 토크나이저 기준
- ‘strange new worlds’ ->
[str][ange][ new][ worlds] - ‘STRANGE NEW WORLDS’ ->
[STR][ANGE][ NEW][ WOR][L][DS]
- ‘strange new worlds’ ->
- GPT 토크나이저 기준
토큰 세기
- 모든 모델은 고정된 토크나이저를 사용하기 때문에 모델의 토크나이저를 이해해두는 것이 좋다.
- 토큰의 개수가 모델 관점에서 텍스트 길이를 결정한다.
- 모델이 프롬프트를 끝까지 읽는 데 소요되는 시간은 프롬프트의 토큰 수에 따라 선형적으로 증가한다.
- LLM은 콘텍스트 윈도가 존재한다.
- 콘텍스트 윈도 크기보다 작은 토큰으로 구성된 텍스트를 가져와서 프롬프트와 완성된 텍스트를 합친 토큰 수가 콘텍스트 윈도 크기보다 크지 않도록 결과 텍스트를 완성한다.
- GPT 토크나이저는 영어 자연어 텍스트를 코튼화할 때 토큰당 약 4개의 문자를 갖는다.
- 다른 언어에서는 상대적으로 덜 효율적이다.
- 대부분의 LLM은 몇 개의 특수 토큰이 있다.
- 예: 텍스트 종료 토큰
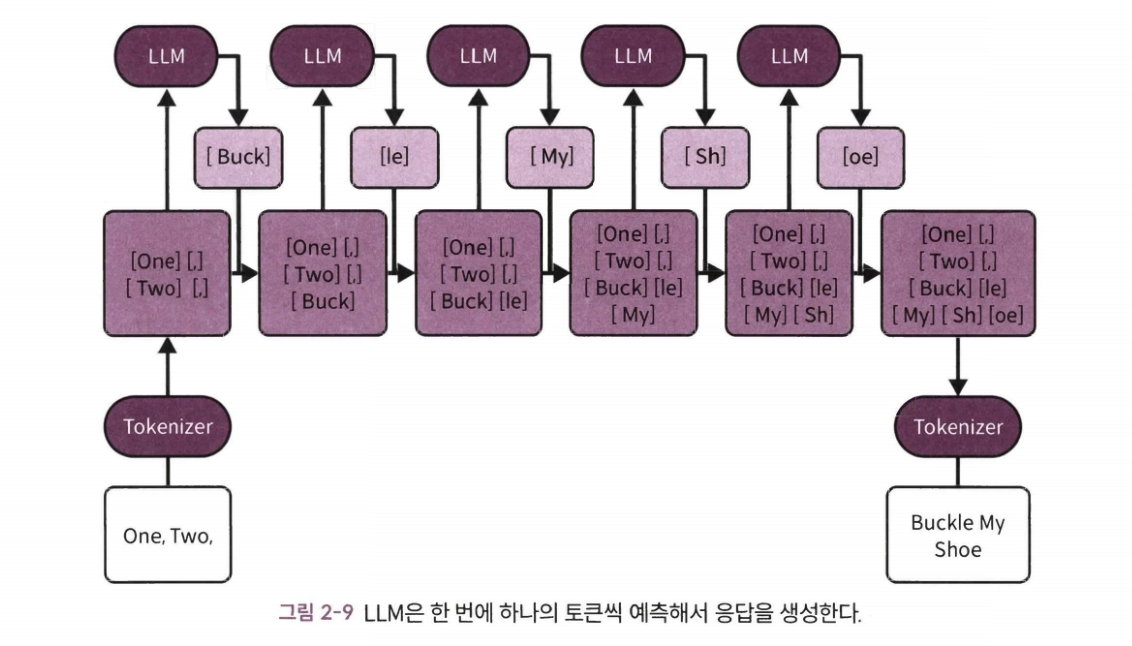
한 번에 토큰 1개
- LLM은 여러 개의 토큰을 입력 받아 1개의 토큰을 출력하는 방식이다.
자기 회귀 모델
- 자기 회귀: 한 번에 하나의 토큰을 예측하고 다음 예측이 이전 예측에 따라 달라지는 프로세스
- 사람은 멈춰서 검토하고 생각할 수 있지만, 모델은 매 단계마다 하나의 토큰을 생성해야 한다. LLM은 더 오래 생각해야 하더라도 추가 시간을 얻을 수 없고 멈출 수도 없다.
- LLM은 한번 토큰을 내놓으면 해당 토큰을 확정적으로 선택하게 된다. 뒤로 돌아가 토큰을 지울수 없다.
- 이러한 자기 회귀의 특성 때문에 LLM은 확실히 말도 안 되는 경로를 계속 탐색할 때 완고하고 다소 우스꽝스럽게 보인다.
- 애플리케이션 설계자는 이러한 실수를 인식하고 다시 돌아갈 수 있는 기능을 제공해야 한다.
패턴과 반복
- 자기 회귀 시스템은 또 다른 문제로는 자신만의 패턴에 빠질 수 있다는 것이다.
- 이러한 반복적인 결과를 처리하는 방법
- 감지하고 필터링하는 것이다.
- 출력을 약간 무작위화하는 것이다.
온도와 확률
- LLM은 뒤에 나올 가능성이 있는 모든 토큰의 확률을 계산한 뒤 그중 토큰 하나를 선택한다.
- 실제 토큰을 선택하는 내부 프로세스를 샘플링리라고 한다.
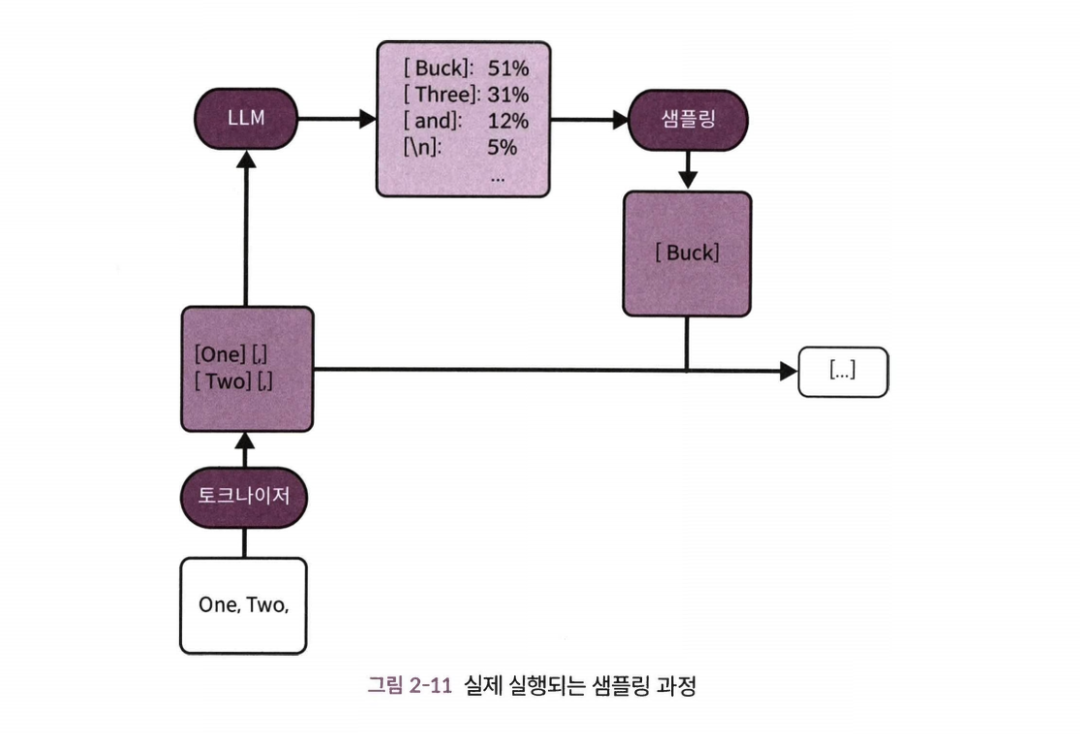
- LLM은 가장 가능성이 높은 토큰만 계산하는 것이 아니라 모든 토큰의 가능성을 계산한다.
- 모델은 일반적으로 토큰의 확률을 로그 확률로 반환한다.
- 로그 확률이 0이라는 것은 모델이 이것이 다음 토큰임을 확신하는 것이다.
- 가장 가능성이 높은 토큰은 -2와 0 사이의 로그 확률을 가진다고 보면된다.
- 항상 가장 가능성이 높은 토큰을 원하는 것은 아니다. 이를 해결할 수 있느 전형적인 방법은 0보다 큰 온도를 사용하는 것이다.
- 아래 식에서 t가 온도 파라미터
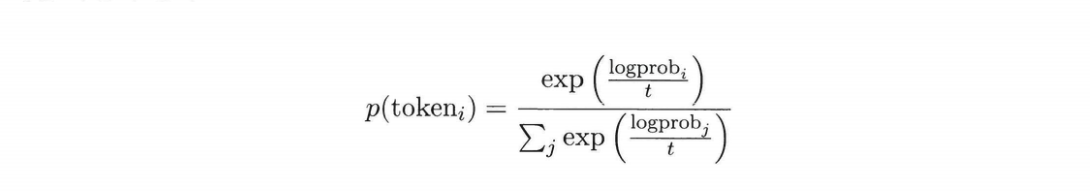
- 온도 파라미터 값에 따른 설명
- 0: 항상 가장 가능성이 높은 토큰을 사용한다. 0으로 설정하면 LLM은 결정적인 모델에 가까워진다.
- 0.1~0.4: 선두 주자보다 아주 약간 처진 대치 토큰이 있다면 해당 토큰이 선택될 기회를 부여하고 싶은 상황에 사용한다.
- 0.5~0.7: 해결책이 우연이 더 크게 작용하기를 원하며, 모델이 더 그럴듯하다고 판단한 다른 선택지가 있음에도 불구하고, 가끔은 덜 가능성 높은 토큰이 선택되는 상황에 사용한다.
- 1: 토큰 분포가 학습 데이터셋의 분포를 반영하고자 할 때 사용한다.
1: 학습 데이터셋보다 ‘더 무작위적인’ 텍스트를 얻고자할 때 사용한다. 이는 모델이 학습데이터셋에서 봤던 전형적인 문서보다 ‘표준’에 가까운 텍스트가 전개될 가능성이 적고 학습 데이터셋에서 봤던 전형적인 문서에 비해 ‘특이한’ 텍스트로 전개될 가능성이 높다.

- 샘플링의 또 다른 방법: 빔 검색
- 다음 몇 개의 토큰을 미리 보고 가능성 있는 시퀀스가 있는지 확인함으로써 토큰을 선택한다.
- 더 정확한 해결책을 얻을 수 있지만 시간과 컴퓨팅 비용이 훨씬 많이 들기 때문에 애플리케이션에서는 자주 사용하지 않는다.
트랜스포머 아키텍처
- 트랜스포머 아키텍처: 각 토큰마다 미니 브레인이 있으며, 레이어를 여러 번 돌며 문맥을 업데이트한다.
- 아래 레이어에서 자기 토큰의 의미를 이해하고, 위 레이어로 갈수록 토큰간의 관계를 반영한다.
- 맨 마지막 토큰 위에 있는 미니 브레인은 다음 토큰을 예측하기 위해 실행된다.
- 다음 토큰을 예측할 때 자기 회귀가 작동한다.
- 새로운 토큰을 뱉어내고, 그 위에 새로운 미니 브레인이 설정되어 정해진 수의 레이어에 대해 자신의 위치에서 일어나고 있는 일을 이해하는 방식을 개선한다.
- 다음 토큰을 예측할 때 자기 회귀가 작동한다.
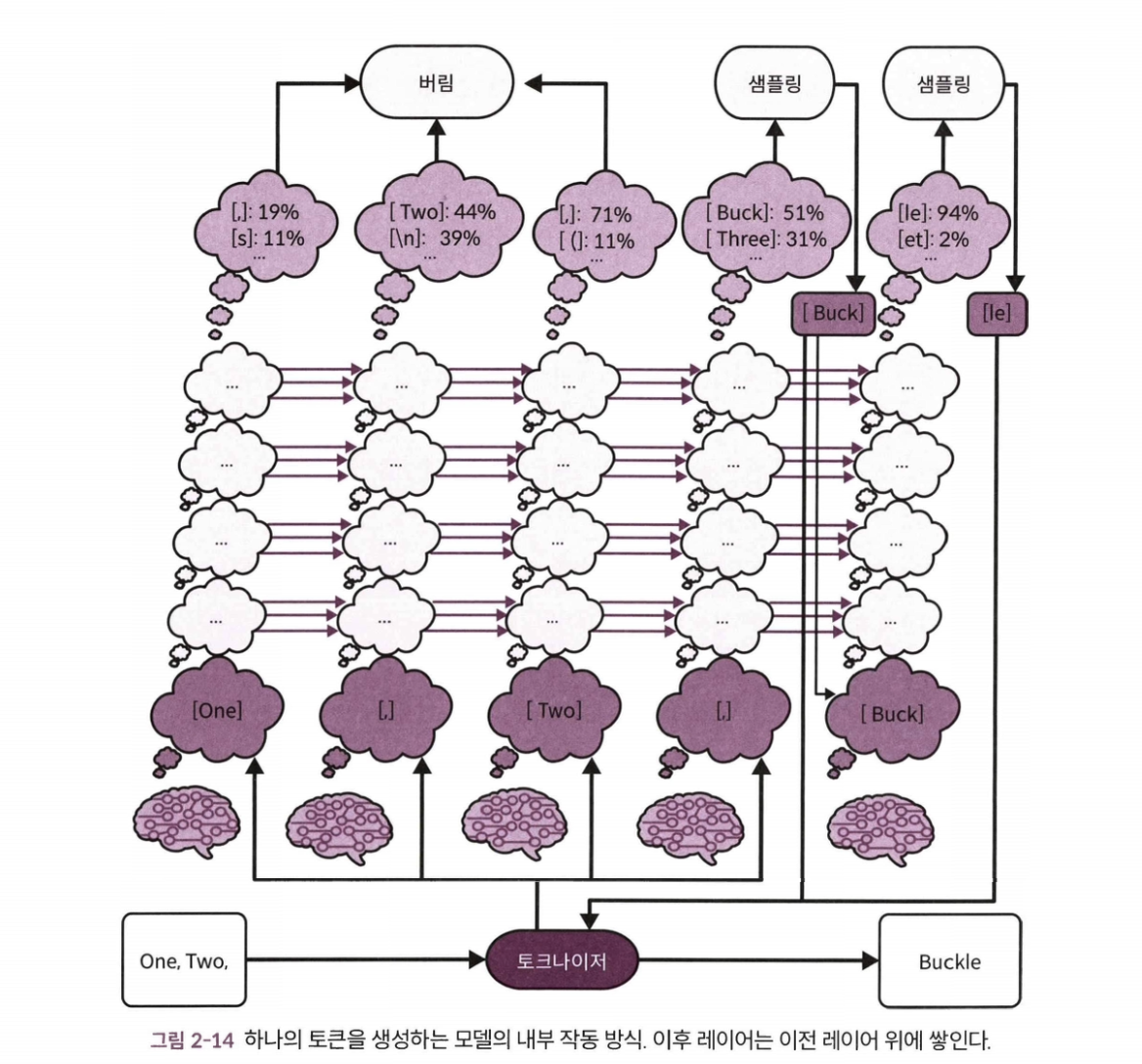
- 트랜스포머는 내부 계산을 병렬로 진행할 수 있어 빠르다는 장점이 있다.
- 대각선 방향으로 병렬 계산이 가능하다.
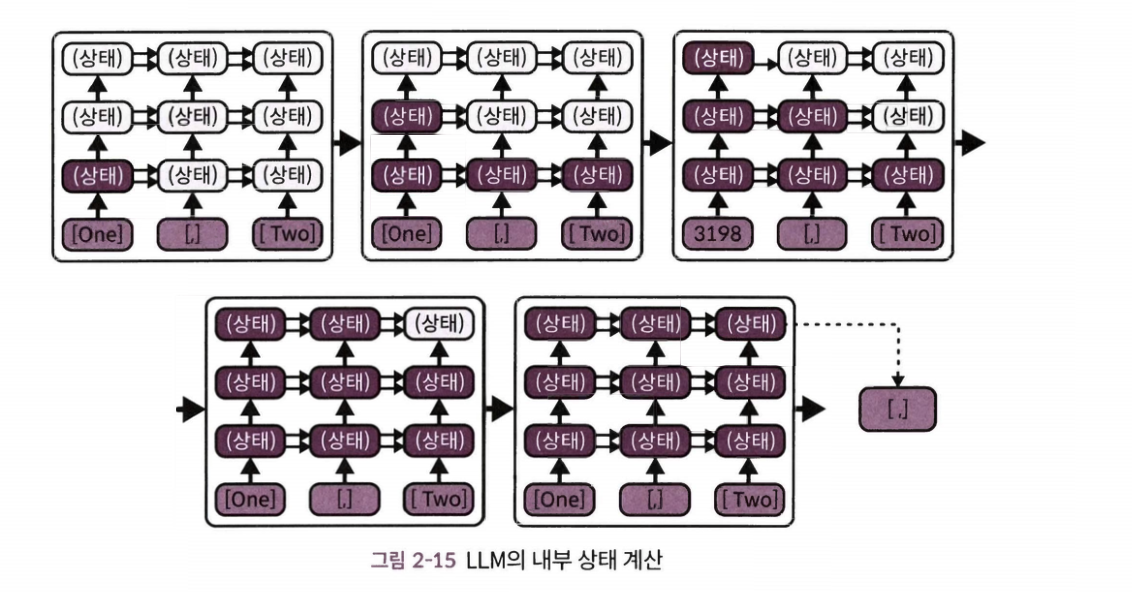
- 미니 브레인 간 공유되는 중간 결과는 어텐션 메커니즘으로 동작한다.
- 트랜스포머 아키텍처의 제약사항(마스킹 규칙)
- 미니 브레인은 자기보다 왼쪽 토큰만 볼 수 있다.
- 미니 브레인은 자신의 아래 레이어만 볼 수 있다.
- 마스킹 규칙으로 인해, 프롬프트 엔지니어링에서 프롬프트의 순서가 중요하다.
- 예시: ‘단락에 있는 단어의 개수가 몇 개일까?’ 라는 질문을 뒤에 두는것보다 앞에 두는것이 정답에 가까워진다.