- LLM 기본 모델은 애플리케이션 설정에 사용하기 어렵다.
- 이유1: 인터넷상의 임의의 문서로 학습했기 때문에 기본 모델은 인터넷의 밝은 면과 어두운 면을 모두 모방할 수 있다.
- 이유2: 기본 모델은 문서 완성만 할 수 있다. 우리는 종종 LLM이 어시스턴트 역할도 하고, 파이썬 코드도 자실행하며, 검색해서 반영하고, 외부 도구를 실행할 수 있기를 바란다.
- 이유3: 사용자가 LLM을 맞춤 설정할 수 있게하고 싶은 경우도 있다.
인간 피드백을 통한 강화학습#
- 인간 피드백을 통한 강화학습(reinforcement learning from human feedback, RLHF): 인간의 선호도를 사용해서 LLM의 동작을 조정하는 LLM 학습 기법
- 모델 정렬: 사용자 기대와 더 부합하는 생성 결과를 만들기 위해 모델을 파인튜닝하는 절차.
RLHF 모델 구축 프로세스#
- 지도 파인 튜닝(supervised fine-tuning, SFT) 모델 만들기
- 기본 모델에 새로운 학습 데이터 샘플을 제공하고 학습시켜, 더 좋은 결과가 나오도록 모델 파라미터를 조정한다.
- 새로운 학습 데이터: 모델에게 바라는 동작을 대표할 만한 수작업으로 제작된 수천 개의 문서
- 파인 튜닝이 완료되면 모델이 거짓말한다는 문제가 남아있다.
- 보상 모델 만들기
- SFT 모델을 강화학습 하기위한 보상 모델을 만든다.
- 강화 학습: 에이전트가 행동 후 보상을 보고 더 좋은 방향으로 행동하도록 학습을 함
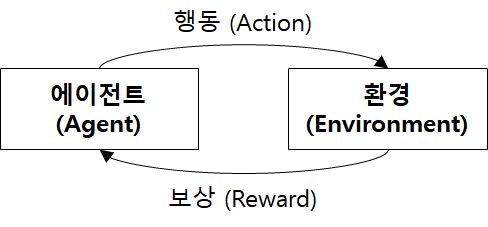
- 에이전트: LLM 모델
- 환경: 완성시켜야 할 문서
- 행동: LLM이 문서를 완성시키기 위해 다음 토큰을 선택하는 것
- 보상: 문서가 주관적으로 얼마나 좋은지를 나타내는 점수
- 인간의 주관적인 점수를 반영하는 보상 모델을 생성한다.
- 보상 모델 생성 방법
- 보상 모델 학습 데이터 생성: GPT-3에서 각 프롬프트에 대해 4~9개의 생성 결과를 만들고, 사람으로 구성된 평가팀이 각 결과들의 순위를 매긴다.
- 보상 모델 학습 데이터를 기준으로 학습
- 보상 모델은 SFT 모델과 최소한 동등한 성능을 가져야 된다.
- RLHF 모델 만들기
- 보상 모델로 강화 학습을 진행하여, RLHF 모델을 만든다.
- 강화 학습을 완료하면 한 가지 문제점이 생긴다.
- RLHF 모델이 보상 모델의 점수를 극대화하기 위해 더 이상 일반 사람이 쓰는 텍스트를 생성하지 못하는 결과가 나올 수 잇다.
- 이 문제를 해결하기 위해 근접 정책 최적화라는 강화학습 알고리즘을 사용한다.
- 근접 정책 최적화: 보상 모델의 점수를 개선할 수 있지만 결과가 SFT 모델 결과와 크게 다르지 않은 경우에만 가중치를 수정할 수 있는 최적화
지시형에서 대화형으로#
- 지시형 모델: 입력된 프롬프트를 바로 수행하려고 함
- 우리에게는 모델이 프롬프트를 바로 완성하기 보다는 사용자와 대화를 나눠야 하는 상황인지, 사용자의 지시를 따라야 하는지, 사용자의 질문에 답변을 해야하는 상황인지 알려줄 수 있는 명확한 방법이 필요하다.
- 오픈AI의 대화형 모델에서 가장 중요한 혁신은 ChatML을 도입했다는 것이다.
- ChatML은 대화에 주석을 달기 위해 사용되는 단순한 마크업 언어로 다음과 같은 형태를 가진다.
- 모든 메시지는
<|im_start|>로 시작하고 <|im_end|>로 끝난다. - 메시지는 세 가지 역할 시스템, 사용자, 어시스턴트와 연결된다.
- 시스템 메시지: 대화와 어시스턴트의 행동에 대한 기대를 설정한다.
- 사용자 메시지: LLM 기반 애플리케이션에서 실제 인간 사용자가 제공하는 텍스트
- 어시스턴트 메시지: LLM 기반 애플리케이션에서 완성된 응답

- RLHF 파인튜닝을 거쳐 ChatML로 주석이 달린 대본 문서를 완성한다.
- ChatML 도입의 장점
- 시스템 메시지에 대화에서 기대하는 바를 설정할 수 있다.
- 프롬프트 인젝션을 예방할 수 있다.
- 예약된 토큰을 사용하기 때문이다.
- 사용자 메시지에
<|im_start|>를 포함하면 단일 토큰으로 처리하는 것이 아니라 <, |, im, _start, |, >의 6개의 토큰으로 처리되ㅑ기 때문에 사용자가 대화에 몰래 프롬프트를 삽입해 행동을 제어할 수 없다.
지금도 변하고 있는 API#
채팅 완성 API#
- API에서 JSON 형태의 메시지가 ChatML로 전환하는 작업은 API 내부에서만 일어난다.
채팅과 생성 결과 비교#
- 대화형 구성을 사용하면서 잃게 된 것
- 정렬 비용이 발생한다.
- 완성된 응답의 행동을 완전히 제어하기 어렵다.
- 예시: 논평을 제외한 코드만 응답으로 받고 싶은 경우
- 응답에 존재하는 인간 다양성의 폭이 좁다.
- 예시: 경찰이 모델과 협력해야 할 때, ‘불법적 행동에 대한 논의는 허용되지 않는다’등의 답변을 들어서는 안된다.
대화형을 넘어 도구로#
- 완성형에서 대화형으로 넘어간 것은 첫걸음을 뗀 것이 불과하다.
- 대략 반년 후, 오픈AI는 모델이 외부 API 실행을 요청할 수 있는 새로운 도구 활용 API를 소개했다.
- 이러한 요청이 있을 때 LLM 애플리케이션은 요청을 가로채서 실제 API에 요청을 보내고 답변을 기다린 다음, 응답을 다음 프롬프트에 삽입함으로써 모델이 새로운 정보를 반영해 다음 완성 결과를 생성할 수 있도록 한다.
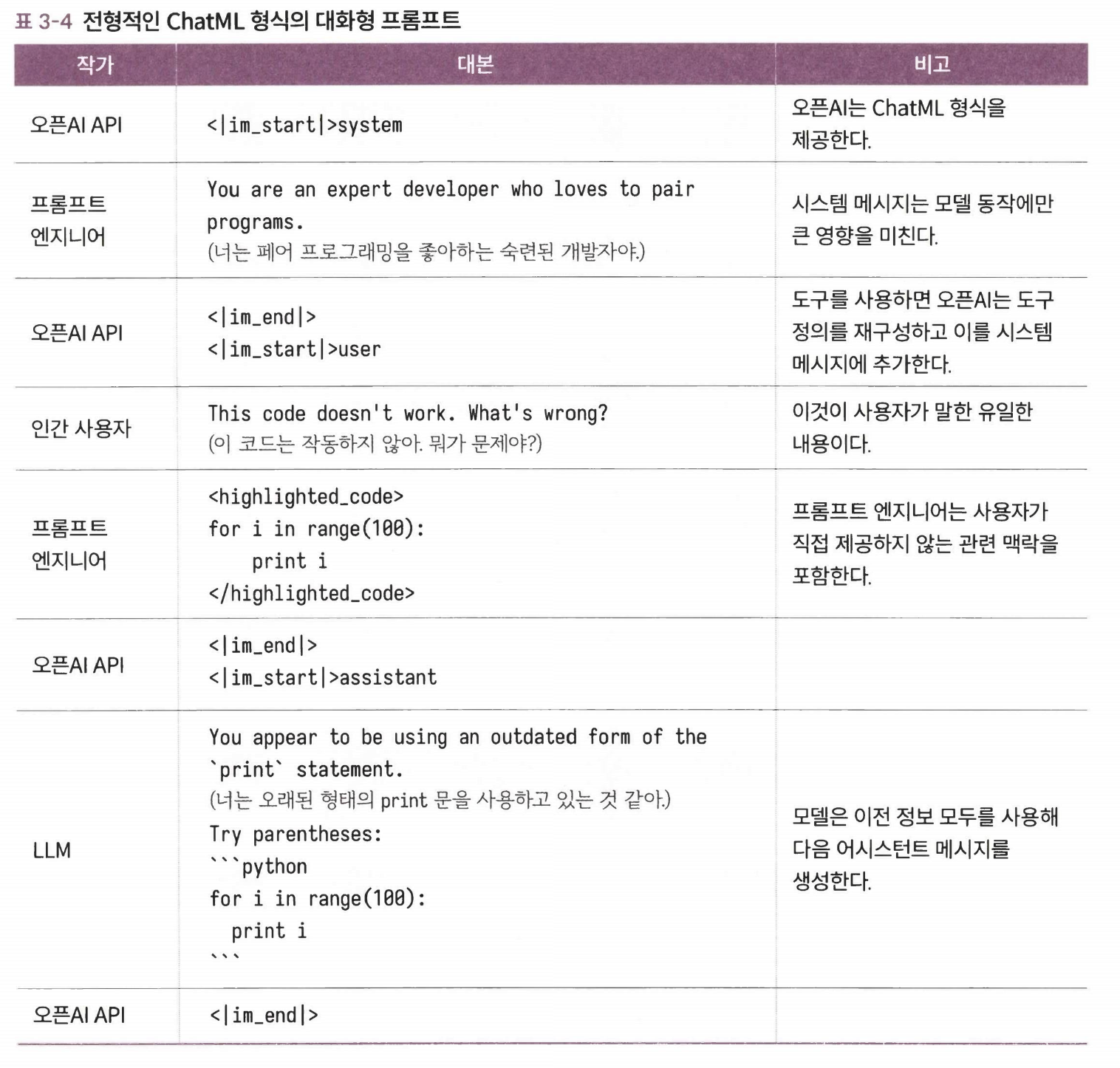
극본 작성으로서의 프롬프트 엔지니어링#
- 애플리케이션과 모델 간의 대화에는 인간 사용자가 결코 알지 못하는 수많은 정보가 포함될 수 있다.
- 예시: ‘이 코드를 어떻게 테스트해야 하나요?‘라고 말하면 ‘이 코드’가 무엇을 가리키는지 추론하는 것은 애플리케이션이고, 추론 한 다음 해당 정보를 프롬프트에 통합해야 된다.
- 프롬프트 엔지니어링 은유: 극본 작성
- 등장인물: 사용자, 어시스턴트, 시스템, 도구
- 대본: 등장인물들이 사용자의 문제를 풀기 위해 협력하면서 주고받은 대화를 기록한 프롬프트
- 작가: 프롬프트 엔지니어, 인간 사용자, LLM, 오픈AI API