세 가지 비밀#
인덱스가 도움이 되지 않을 수 있다#
- 인덱스는 성능에서 핵심이지만 좋은 인덱스라도 쿼리가 느릴 수 있다.
- 인덱스 없이는 성능을 달성할 수 없지만 무한한 데이터 크기에 대해 무한한 영향력을 제공한다는 의미는 아니다.
- 인덱스 스캔의 경우
- 테이블의 행 수가 증가할수록 인덱스 스캔을 사용하는 쿼리에 대한 응답 시간도 늘어나므로 반드시 지연 시간이 발생한다.
- 더 이상 최적화할 수 없으면 간접 쿼리 최적화를 한다.
- 행 찾기의 경우
- 아래 나열된 것 처럼 한 행만 일치하는 인덱스 조회 접근 유형이 아니라면, rows 필드에 주의를 기울여야 한다.
- system
- const
- eq_ref
- unique_subquery
- 선택도가 낮은 인덱스는 인덱스 조회를 느리게하는 공범일 가능성이 높다.
- 테이블 조인의 경우
- 테이블 조인할 때는 한 행만 일치하는 인덱스 조회 접근 유형 중 하나를 사용하여 하나의 행만 일치 시키는 것이 좋다.
- 다른 테이블에서 더 나은 인덱스를 생성하여 MySQL이 조인 순서를 변경할 수 있도록 하는 방법도 있다.
- 작업 세트 크기
- 작업 세트: 자주 사용하는 인덱스값과 참조하는 프라이머리 키 행
- 일반적으로 작업 세트는 테이블 크기에서 작은 비율을 차지한다.
- 인덱스를 구성하는 B-트리 노드는 16KB 페이지에 저장되고, MySQL은 필요에 따라 메모리와 디스크 간에 페이지를 교환한다.
- 작업 세트의 크기가 사용할 수 있는 메모리보다 커지면, 인덱스가 메모리를 놓고 경쟁하게되어 인덱스가 도움이 되지 않을 수 있다.
- 작업 세트 크기가 적절한 크기의 메모리에 맞지 않을 정도로 많은 데이터를 저장하고 접근해야 할 때 해결책은 샤딩이다. (이후 5장에서 다룬다.)
데이터가 적을 수록 좋다#
- 데이터 크기가 클수록 성능 최적화가 더 어렵고 관리가 위험해 진다.
- 데이터 크기 때문에 문제가 발생하기 전에 제한 없이 증가하는 데이터가 있다면 문제를 제기해야 한다.
QPS가 낮을수록 좋다#
- QPS는 일반적으로 쿼리나 성능에 대해 질적인 정보를 제공하지 않는다. 숫자에 불과하다.
- 똑같은 QPS에서도 수많은 질적 차이가 발생한다.
- QPS는 좋거나 나쁘지도 않고, 높거나 낮지도 않으며, 전형적이거나 비전형적이지도 않다.
- QPS값은 애플리케이션과 관련해서만 의미가 있다.
- 한 애플리케이션의 평균이 2000QPS라면 100QPS는 중단을 나타내는 급격한 하락일 수 있다.
- 데이터 크기는 1GB에서 100GB로 비교적 쉽게 증가할 수 있다. 그러나 QPS는 100 높이기는 매우 어렵다.
- 위 3가지를 요약하면 QPS는 도움이 되지 않는다. 자산이라기보다는 부채에 가깝다.
- 숙련된 엔지니어는 QPS가 낮을수록 성장 잠재력이 있기 때문에 QPS가 의도적으로 감소하는 것을 반가워한다.
최소 데이터 원칙#
데이터 접근#
- 데이터 접근 효율성을 확인하기 위한 점검 목록
- 필요한 열만 반환
- 쿼리 복잡성 감소
- 행 접근 제한
- 결과 세트 제한
- 행 정렬 피하기
- 위 목록을 모두 만족해야되다는 의미는 아니다. 예를 들어 ‘행 정렬 피하기’는 성능에 영향을 미치지 않기에 무시된다.
- 필요한 열만 반환
SELECT * 쿼리를 실행하지 않는다.- 테이블에
BLOB, TEXT, JSON 열이 있을 때 특히 중요하다.
- 쿼리 복잡성 감소
- 쿼리 복잡도는 쿼리를 구성하는 모든 테이블, 조건, SQL 절을 나타낸다.
- 쿼리가 복잡할수록 분석하고 최적화하기가 더 어렵다.
- 단순 쿼리는 테이블, 조건, SQL 절이 몇 개 없어서 MySQL에 대한 작업이 더 단순해지기 때문에 더 작은 데이터에 접근하는 경향이 있다.
- 행 접근 제한
- 접근하는 행의 범위와 목록을 제한하지 않으면, 데이터가 커지면서 느린 쿼리가 될 수 있다.
LIMIT 절은 행을 일치시킨 후 결과 세트에 LIMIT가 적용되므로 행 접근을 제한하지 않는다.- 하지만
ORDER BY ... LIMIT 최적화는 예외이다.- MySQL이 인덱스 순서대로 행에 접근할 수 있을 때, 일치하는 행을 찾다가
LIMIT 수만큼 발견되면 행 읽기를 중지한다. - 하지만
EXPLAIN에는 이 최적화가 사용될 때 보고되지 않는다. EXPLAIN SELECT * FROM elem WHERE a > 'Ag' ORDER BY a LIMIT 2- 아래 사진처럼 EXPLAIN에는 보고되지 않는다.
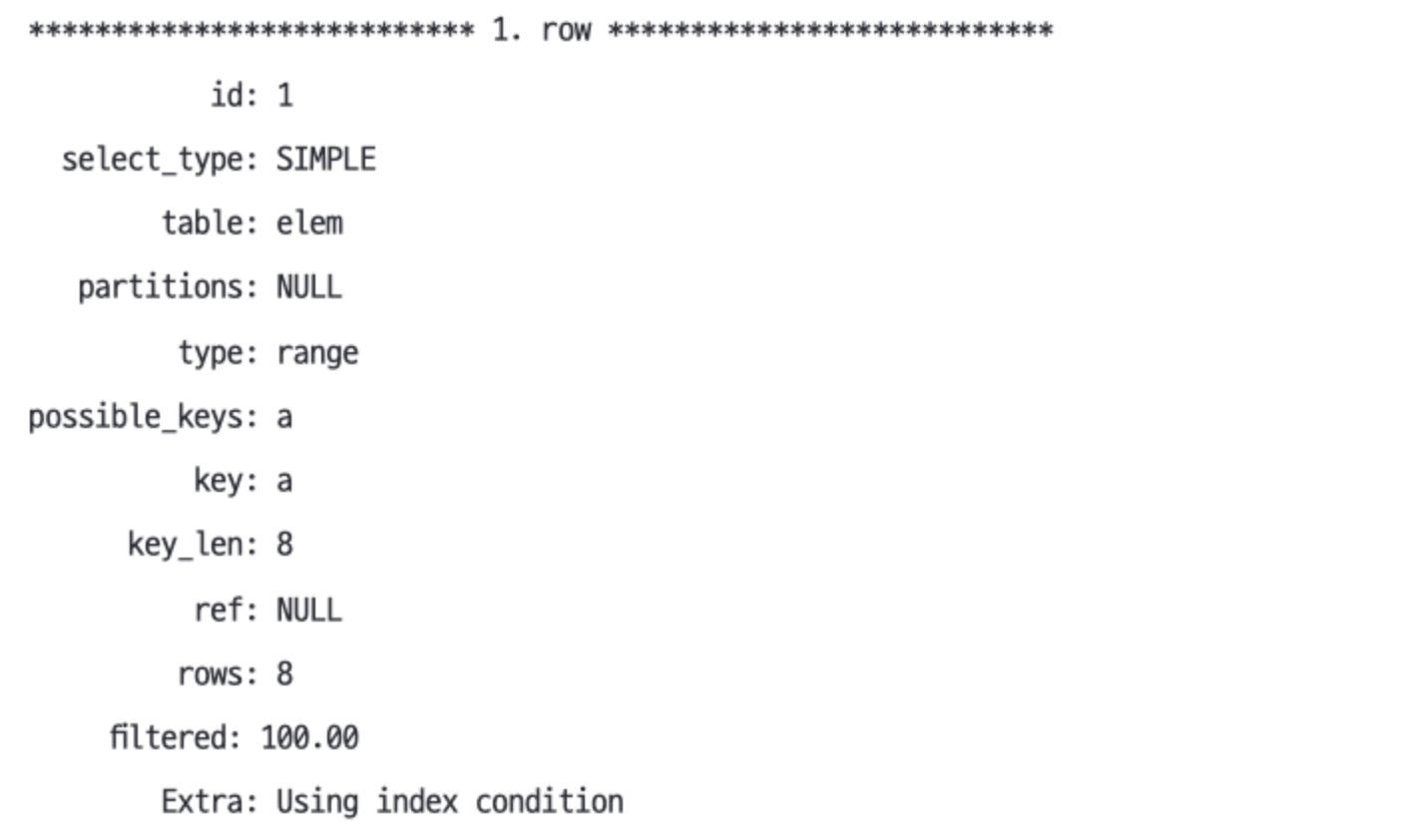
- 하지만 슬로 쿼리 로그에 있는 쿼리 메트릭에는
Rows_examined: 2로 접근한 행의 수가 2인 것을 확인할 수 있다. 
- 쓰기는 일반적으로 InnoDB가 일치하는 행을 갱신하기 전에 접근하는 모든 행을 잠그므로 행 접근을 제한하는 것이 중요하다
- 테이블을 조인할 때도 행 접근을 제한하는 것이 중요하다.
- 결과 세트 제한
- 쿼리는 될 수 있는 한 적은 수의 행을 반환해야된다.
- result set 전체를 사용하지 않는 경우
- 의도로 또는 의도하지 않게
WHERE 절에 충분한 조건으로 필터링하지 않는 경우- 의도적으로 쿼리의 복잡도를 낮추거나 응답 시간을 단축시키기 위해서 그런 경우는 허용 한다.
- 쿼리에
ORDER BY 절이 있고 애플리케이션이 정렬된 행의 일부분만 사용할 때ORDER BY ... LIMIT 최적화를 사용할 수 있을 때만 LIMIT으로 가져오는 것을 줄인다.
- 애플리케이션이 result set을 집계 용도로만 사용하는 경우
- 통계 함수를 통해서 MySQL이 행을 반환하는 대신 MySQL이 계산을 수행하도록 한다.
- 열값 더하기:
SUM(column) - 행의 개수 세기:
COUNT(*) - 값의 개수 세기:
COUNT(column) ... GRUOP BY column - 고윳값의 개수 세기:
COUNT(DISTINCT column) - 고유값 추출하기:
DISTINCT
COUNT(*) vs COUNT(column)COUNT(*)는 일치하는 행의 수를 계산한다.COUNT(column)은 일치하는 행의 열에서 NULL이 아닌 값의 수를 계산한다.
- 행 정렬 피하기
- 쿼리는 행 정렬을 피해야한다.
- MySQL 대신 애플리케이션에서 행을 정렬하면
ORDER BY절을 제거하여 쿼리 복잡성을 줄이고 애플리케이션 인스턴스에 작업을 분산시켜 더 좋은 확장성을 가질 수 있다. LIMIT 절이 없는 ORDER BY 절은 삭제하여 애플리케이셔넹서 행을 정렬하도록 한다.
데이터 스토리지#
- 필요 이상으로 많은 데이터를 저장하지 않아야 한다.
- 효율적으로 데이터를 저장하는지 확인하는 점검표
- 필요한 행만 저장됨
- 모든 열이 사용됨
- 모든 열이 간결하고 실용적임
- 모든 값이 간결하고 실용적임
- 모든 세컨더리 인덱스가 사용되며 중복되지 않음
- 필요한 행만 유지됨
- 필요한 행만 저장됨
- 애플리케이션이 커지면서 애플리케이션이 저장하고 있는 내용을 추적하지 못 할 수 있다.
- 애플리케이션이 저장하고 있는 데이터를 살펴봐야한다.
- 모든 열이 사용됨
- ORM 등을 사용하면서 사용하지 않는 열을 추적하지 못할 수 있다.
- 수동으로 검토해서 사용하지 않는 열이 있는지 비교해본다.
- 모든 열이 간결하고 실용적임
- 간결함: 가장 작은 데이터 타입을 사용하여 값을 저장한다.
- 실용적: 너무 작아서 사용자나 애플리케이션에 번거롭거나 오류가 발생하기 쉬운 데이터를 사용하지 않는 것
- 비트 필드를 부호 없는
INT로 저장하는 것은 간결하지만 실용적이지 않다.
VARCHAR(255)는 대표적인 안티 패턴- 데이터 타입과 크기는 일반적이지만 잘못된 값이 쉽게 들어갈 수 있다.
BLOB, TEXT, JSON 데이터 타입은 매우 보수적으로 사용해야 된다.- 불필요한 공간이나 쓸데없는 데이터, 일반 버킷 용도로 사용하지 말아야한다.
- 예를 들어, 이미지를
BLOB에 저장할 수 있지만 Amazon S3와 같은 훨씬 더 나은 해결책이 있다.
- 모든 값이 간결하고 실용적임
- 간결함: 가장 작은 표현
- 실용적: 너무 작아서 사용자나 애플리케이션에 번거롭거나 오류가 발생하기 쉬운 데이터를 사용하지 않는 것
- 공백, 주석, 헤드 등 불필요하고 관련 없는 데이터를 제거해 최소화하라.
- SQL 문에 기능정인 부분을 하는 공백만 유지하고 나머지 공백, 주석등은 최소화하라.
- 값을 최소화하는 것이 경미한 것이 아니다.
- 실용적이라 판단하면 빈 문자열, 0값, 매직 넘버 대신
NULL을 사용해라.- 단, MySQL에서
NULL 끼리는 서로 다른 값으로 비교되므로 유의해야된다.
- 데이터베이스에 데이터를 저장할 때 인코딩을 해라.
- IP 주소를 문자열로 저장하는 것은 안티패턴이다.
- IP 주소는 4bytes의 부호없는 정수이며 이것이 진정한 인코딩이다.
- IP 주소를 인코딩해 저장하려면
INT UNSIGNED 데이터 타입과 INET_ATON() 그리고 INET_NTOA() 함수를 사용할 수 있다. - 인코딩 IP 주소가 실용적이지 않을 떄
CHAR(15) 데이터 타입이 허용할 수 있는 대안이다.
- UUID를 문자열로 저장하는 것은 안티패턴이다.
- UUID는 문자열로 표현되는 멀티바이트 정수이다.
- UUID는 바이트 길이가 다양하므로
BINARY(N) 데이터 타입과 UUID_TO_BIN()과 그리고 BIN_TO_UUID() 함수를 사용할 수 있다. - UUID 인코딩이 실용적이지 않으면 최소한
CHAR(N) 데이터 타입으로 문자열 표현을 저장하라.
- 중복 제거를 해라.
- 중복 값을 제거하려면 열을 일대일 관계가 있는 다른 테이블로 정규화해야한다.
- 아래 예시는 여전히
genre_id 열에 중복된 값이 있지만, 규모에 따른 데이터 크기의 감소는 크다. 

- 값 중복 제거는 데이터베이스 정규화에 의해 수행된다.
- 비정규화는 정규화와 반대로 관련 데이터를 하나의 테이블로 결합하는 것이다.
- 비정규화는 테이블 조인과 수반되는 복잡성을 제거하여 성능을 향상 시키는 기술이지만, 중복 데이터가 발생한다.
- 모든 세컨더리 인덱스가 사용되며 중복되지 않음
- 인덱스는 데이터의 복사본이므로 데이터 크기에 특히 중요하다.
- 사용되지 않고 중복된 세컨더리 인덱스를 삭제하는 것은 데이터 크기를 줄이는 쉬운 방법이지만 주의해야 한다.
- 인덱스 크기 확인한느 방법 세 가지
INFORMATION_SCHEMA.TABLES 쿼리SHOW TABLES STATUSmysql.innodb_index_stats 테이블 조회
- 필요한 행만 유지됨
데이터 삭제 또는 보관#
- 데이터가 관리하기 어려울 정도로 쌓이면 문제가 발생할 수 있다.
- 문제가 발생하지 않게 데이터를 삭제하거나 보관해야된다.
- 데이터를 보관하려면 먼저 데이터를 복사한 다음 삭제해야한다.
- 데이터 복사는 애플리케이션에 영향을 미치지 않도록 비잠금
SELECT 문을 사용한 다음, 애플리케이션이 접근하지 않는 다른 테이블이나 데이터 스토리지에 복사된 행을 작성해야 한다.
- 데이터를 삭제하거나 보관하려면 도구를 직접 작성해야 한다.
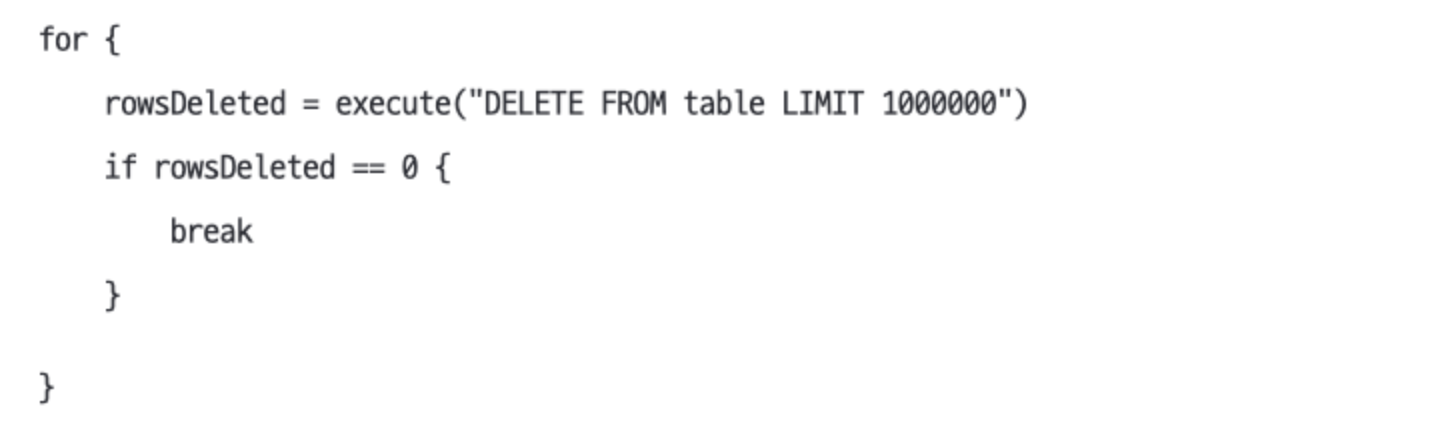
- 아래처럼 너무 큰
LIMIT을 잡지말고 반복문 사이에 지연이 없도록 하지 않는다.
배치 크기#
- MySQL에 큰 부하가 없는 단일
DELETE 문에서 1000개 이하의 행을 직렬로 실행하도록 하는 것이 안전하다. - 행을 빠르고 안전하게 삭제할 수 있는 비율은 쿼리 응답 시간이나 복제 지연에 영향을 주지 않고 MySQL과 애플리케이션이 유지할 수 있는 배치 크기에 따라 결정된다.
- 배치 크기는 실행 시간으로 조정되며 500ms는 좋은 시작점이다.
- 복제 지연도 고려해야된다.
- 원본 인스턴스에서
DELETE문을 실행하는데 500ms가 걸렸다면 본제본에서 실행하는 데 500ms가 걸리므로 500ms의 복제 지연이 발생한다.
- 스로틀링이 없으면 대량 쓰기가 다른 쿼리를 방해하고 애플리케이션에 영향을 줄 수 있기 때문에, 스로틀링도 조절해야한다.
- 예) DELETE 문 사이에 200ms의 지연
로우 락 경합#
- 쓰기 작업이 많은 워크로드의 경우, 대량 작업으로 인해 로우 락 경합이 발생할 수 있다.
- 배치 크기가 큰 경우 500ms 내에 100,000개의 행에 대해 잠금이 발생하여 로우 락 경합이 발생할 수 있다.
- 작은 배치 크기, 긴 지연 등으로 로우 락 경합을 줄여야한다.
공간과 시간#
- 데이터를 삭제해도 바로 디스크 공간이 확보되지 않는다.
- 행 삭제는 물리적 삭제가 아닌 논리적이며 데이터베이스에서 일반적인 성능 최적화이다.
- 500GB의 데이터를 삭제하면 500GB의 디스크 공간이 아니라 500GB의 여유 페이지가 생긴다.
- 디스크 공간을 회수하는 가장 좋은 방법은
ALTER TABLE...ENGINE=INNODB 문을 실행하여 테이블을 재구성하는 것이다.
바이너리 로그 역설#
- 데이터를 삭제하면 데이터가 생성된다.
- 데이터 변경 사항이 바이너리 로그에 기록되기 때문에 발생한다.
- 테이블에 큰
BLOB, TEXT, JSON 열이 포함된 경우, MySQL 시스템 변수 binlog_row_image는 full 설정이 기본이므로 바이너리 로그 크기가 급격히 증가할 수 있다. binlog_row_image 변수는 세 가지로 설정할 수 있다.- full: 모든 열(전체 행)의 값을 기록한다.
- minimal: 변경된 열의 값과 행을 식별하는 데 필요한 열을 기록한다.
- noblob: 필요하지 않는 BLOB과 TEXT 열을 제외한 모든 열의 값을 기록한다.
- 바이너리 로그의 전체 행 이미지에 의존하는 외부 서비스가 없는 경우
minimal 또는 noblob을 사용하는 것이 안전하고 권장된다.