쿠버네티스 이해하기
- 쿠버네티스는 컨테이너 오케스트레이션을 위한 솔루션이다.
- 오케스트레이션: 복잡한 단계를 관리하고 요소들의 유기적인 관계를 미리 정의해 손쉽게 사용하도록 서비스를 제공하는 것
- 다수의 컨테이너를 유기적으로 연결, 실행, 종료할 뿐만 아니라 상태를 추적하고 보존하는 등 컨테이너를 안정적으로 사용할 수 있게 만들어준다.
쿠버네티스 구성 요소 간 통신

- 마스터 노드
- kubectl: 쿠버네티스 클러스터에 명령을 내리는 역할을 한다.
- 다른 구성 요소들과 다르게 바로 실행되는 멍령 형태인 바이너리로 배포되기 때문에 마스터 노드에 있을 필요는 없지만, 통상적으로 API 서버와 주로 통신하므로 이 책에서는 API 서버가 위치한 마스터 노드에 구성했다.
- API 서버: 쿠버네티스 클러스터의 중심 역할을 하는 통로이다.
- 주로 상태 값을 저장하는 etcd와 통신하지만, 그 밖의 요소들 또한 API 서버를 중심에 두고 통신하므로 API 서버의 역할이 매우 중요하다.
- etcd: 구성 요소들의 상태 값이 모두 저장되는 곳
- 그러므로 etcd의 정보만 백업돼 있다면 긴급한 장애 상황에서도 쿠버네티스 클러스터는 복구할 수 있다.
- etcd는 분산 저장이 가능한 key-value 저장소이므로, 복제해 여러 곳에 저장해 두면 하나의 etcd에서 장애가 나더라도 시스템의 가용성을 확보할 수 있다.
- 컨트롤러 매니저: 쿠버네티스 클러스터의 오브젝트 상태를 관리한다.
- 예시1) 워커 노드에서 통신이 되지 않느 경우, 상태 체크와 복구는 컨트롤러 매니저에 속한 노드 컨트롤러에서 이루어진다.
- 예시2) 레플리카셋 컨트롤러는 레플리카셋에 요청받은 파드 개수대로 파드를 생성한다.
- 예시3) 뒤에 나오는 서비스와 파드를 연결하는 역할을 하는 엔드포인트 컨트롤러 또한 컨트롤러 매니저이다.
- 다양한 상태 값을 관리하는 주체들이 컨트롤러 매니저에 소속돼 각자의 역할을 수행한다.
- 스케줄러: 노드의 상태와 자원, 레이블, 요구 조건 등을 고려해 파드의 어떤 워커 노드에 생성할 것인지 결정하고 할당한다.
- kubectl: 쿠버네티스 클러스터에 명령을 내리는 역할을 한다.
- 워커 노드
- kubelet: 파드의 구성 내용(PodSpec)을 받아서 컨테이너 런타임으로 전달하고, 파드 안의 컨테이너들이 정상적으로 작동하는지 모니터링한다.
- kubectl에 문제가 생기면 파드가 정상적으로 관리되지 않는다.
- 컨테이너 런타임(CRI, Container Runtiem Interface): 파드를 이루는 컨테이너의 실행을 담당한다. 파드 안에서 다양한 종류의 컨테이너가 문제 없이 작동하게 만드는 표준 인터페이스다.
- 파드(Pod): 한 개 이상의 컨테이너로 단일 목적의 일을 하기 위해서 모인 단위이다.
- 파드는 언제라도 죽을 수 있는 존재라고 가정하고 설계됐기 때뭉네 쿠버네티스는 여러 대안을 디자인 했다.
- kubelet: 파드의 구성 내용(PodSpec)을 받아서 컨테이너 런타임으로 전달하고, 파드 안의 컨테이너들이 정상적으로 작동하는지 모니터링한다.
- 위 순서 외 요소
- 네트워크 플러그인: 쿠버네티스 클러스터의 통신을 위해서 네트워크 플러그인을 선택하고 구성해야한다. 네트워크 플러그인은 일반적으로 CNI로 구성하는데, 주로 사용하는 CNI에는 캘리코, 플래널, 실리움, 큐브 라우터, 로마나, 위브넷, Canal이 있다.
- CoreDNS: 클라우드 네이티브 컴퓨팅 재단에서 보증하는 프로젝트로, 빠르고 유연한 DNS 서버다.
- 쿠버네티스 클러스터에서 도메인 일므을 이용해 통신하는 데 사용한다.
- 실무에서 쿠버네티스 클러스터를 구성하여 사용할 때는 IP보다 도메인 네임을 편리하게 관리해 주는 CoreDNS를 사용하는 것이 일반적이다.
사용자가 배포된 파드에 접속할 때
- kube-proxy: 쿠버네티스 클러스터는 파드가 위치한 노드에 kube-proxy를 통해 파드가 통신할 수 있는 네트워크를 설정한다.
파드의 생명주기로 쿠버네티스 구성 요소 살펴보기
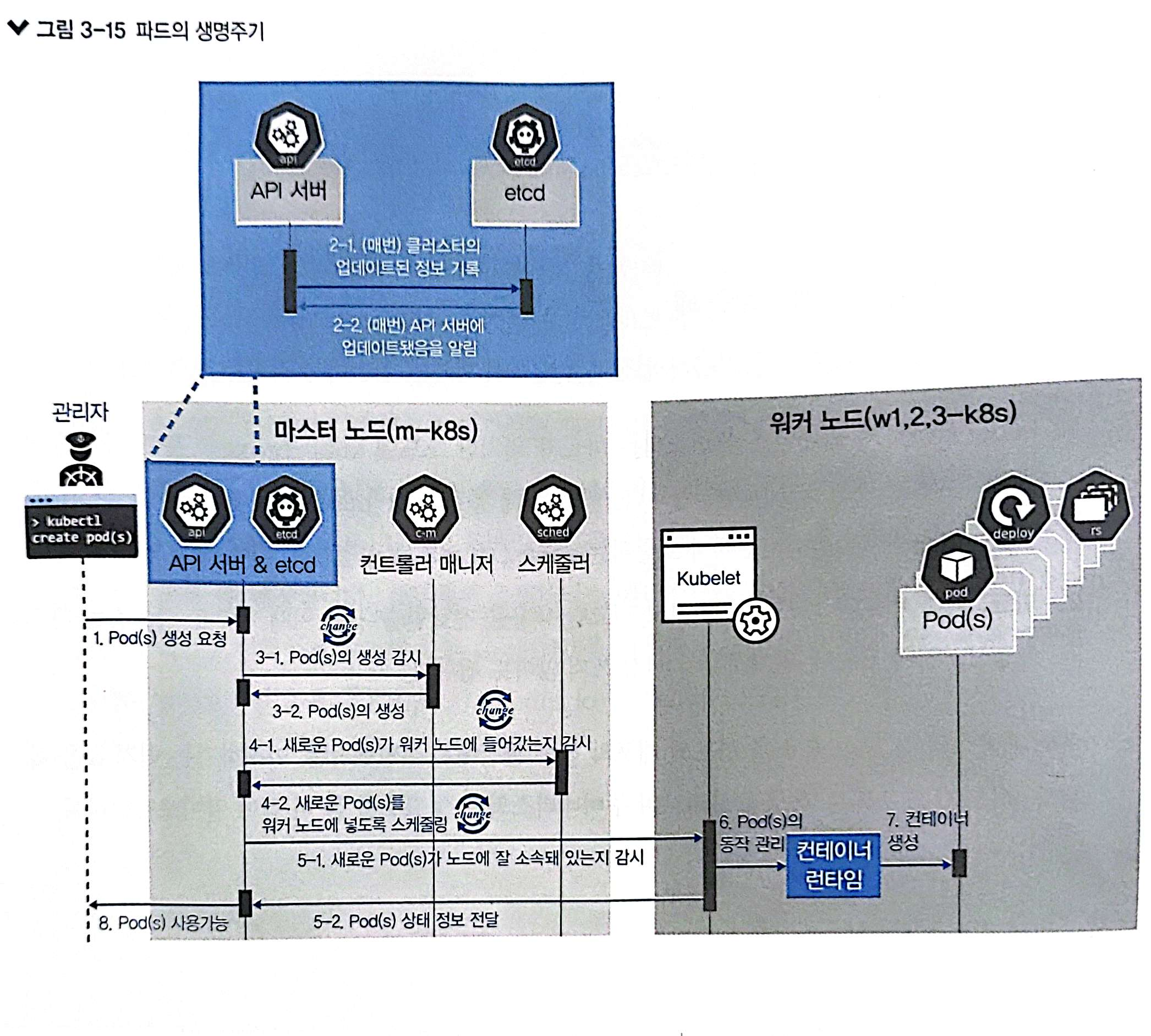
- 쿠버네티스는 작업을 순서대로 진행하는 워크플로 구조가 아니라 선언적인 시스템 구조를가지고 있다.
- 즉, 각 요소가 추구하는 상태를 선언하면 현재 상태와 맞는지 점검하고 그것에 맞추도록 노력하는 구조로 돼 있다.
- 다라서 추구하는 상태를 API 서버에 선언하면 다른 요소들이 API 서버에 와서 현재 상태와 비교하고 그에 맞게 상태를 변경하려고 한다.
- 여기서 API는 현재 상태를 가지고 있는데 이것을 보존해야 해서 etcd가 필요하다.
- API 서버와 etcd는 거의 한몸처럼 움직이도록 설계됐다.
- 다만, 워커 노드는 워크플로 구조에 따라 설계됐다.
- 쿠버네티스가 kubelet과 컨테이너 런타임을 통해 파드를 생성하고 제거해야 하는 구죠여서 선언적인 방식으로 구조화하기에는 어려움이 있기 때문이다.
- 또한 명령이 절차적으로 전달되는 방식은 시스템의 성능을 높이는 데 효율적이다.
쿠버네티스 구성 요소의 기능 검증하기
- 클러스터 내 노드 정보 확인:
kubectl get nodes

쿠버네티스 기본 사용법 배우기
파드 생성하는 방법
- 단일 파드 생성
nginx-pod: 생선된 파드의 이름--image=nginx: 생성할 이미지의 이름
kubectl run nginx-pod --image=nginx
- deployment를 통해서 파드 생성하는 방법
- deployment라는 관리 그룹 내에서 파드가 생성되어 관리된다.
kubectl create deployment dpy-nginx --image=nginx
오브젝트란
- 쿠버네티스를 사용하는 관점에서 파드와 디플롤이먼트는 스펙과 상태 등의 값을 가지고 있다.
- 파드와 디플로이먼트를 개별 속성을 포함해 부르는 단위를 오브젝트라고 한다.
- 기본 오브젝트
- 파드: 쿠버네티스에서 실행되는 최소단위.
- 독립적인 공간과 사용 가능한 IP를 가지고 있다.
- 하나의 파드는 1개 이상의 컨테이너를 갖고 있기 때문에 여러 기능을 묶어 하나의 목적으로 사용할 수 있다. 그러나 범용으로 사용할 때는 대부분 1개의 파드에 1개의 컨테이너를 적용한다.
- 네임스페이스: 쿠버네티스 클러스터에서 사용되는 리소스들을 구분해 관리하는 그룹.
- 초기 네임스페이스 종류
- default: 네임스페이스를 지정하지 않으면 기본으로 사용한다.
- kube-node-lease: 각 노드와 연관된 리스 오브젝트를 갖는다. 노드 리스는 kubelet이 하트비트를 보내서 컨트롤 플레인이 노드의 장애를 탐지할 수 있게 한다.
- kube-public: 모든 클라이언트(인증되지 않은 클라이언트 포함)가 읽기 권한으로 접근할 수 있다. 이 네임스페이스는 전체 클러스터 중에 공개적으로 드러나서 읽을 수 있는 리소스를 위해 예약되어 있다.
- kube-system: 쿠버네티스 시스템에 생성한 오브젝트를 위한 네임스페이스.
- 초기 네임스페이스 종류
- 볼륨: 파드가 생성될 때 파드에서 사용할 수 있는 디렉터리를 제공한다.
- 기본적으로 파드는 영속되는 개념이 아니라 제공되는 디렉터리도 임시로 사용한다.
- 하짐나 파드가 사라지더라도 저장과 보존이 가능한 디렉터리를 볼륨 오브젝트를 통해 생성하고 사용할 수 있다.
- 서비스: 새로 파드가 생성될 때 부여되는 새로운 IP를 기존에 제공하던 기능과 연결해준다.
- 파드는 클러스터 내에서 유동적이기 때문에 접속 정보가 고정일 수 없다.
- 따라서 파드 접속을 안정적으로 유지하도록 서비스를 통해 내/외부로 연결된다.
- 기존 인프라에서 로드밸런서, 게이트웨이와 비슷한 역할을 한다.
- 파드: 쿠버네티스에서 실행되는 최소단위.
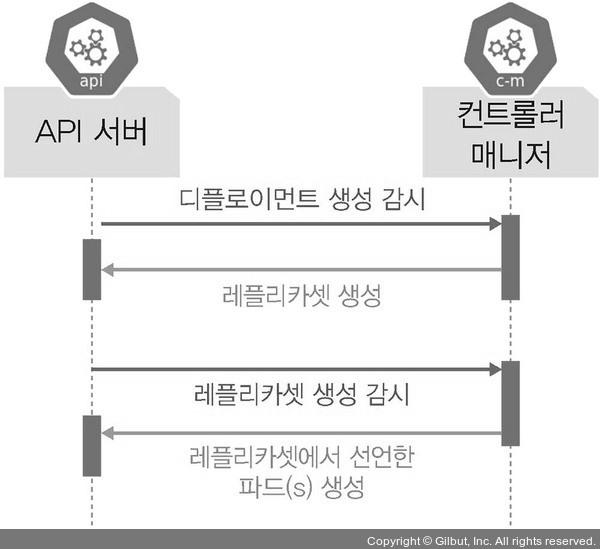
- 디플로이먼트: 파드에 기반을 두고 있으며, 레플리카셋 오브젝트를 합쳐놓은 형태의 오브젝트.
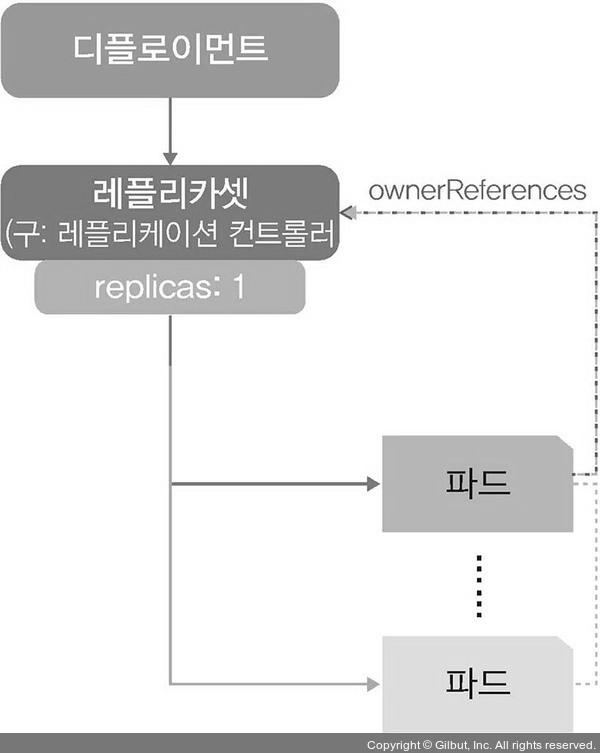
- API 서버와 컨트롤러 매니저는 단순히 파드를 생성되는 것을 감시하는 것이 아니라 디플로이먼트처럼 레플리카셋을 포함하는 오브젝트의 생성을 감시한다.
- 디플로이먼트 삭제
kubectl delete deployment dpy-hname- 디플로이먼트가 삭제되면 디플로이먼트가 관리하던 파드도 삭제한다.
레플리카셋으로 파드 수 관리하기
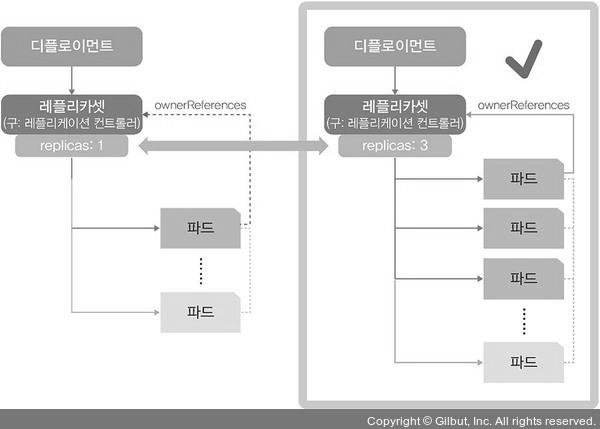
- 다수의 파드가 필요할 때, 이를 하나씩 생성한다면 매우 비효율적이다. 그래서 쿠버네티스에서는 다수의 파드를 만드는 레플리카셋 오브젝트를 제공한다.
- 레플리카셋은 파드 수를 보장하는 기능만 제공하기 때문에 롤링 업데이트 기능 등이 추가된 디플로이먼트를 사용해 파드 수를 관리하기를 권장한다.
- 디플로이먼트로 생성된 dpyh-nginx를 scale 명령과 –replica=3 옵션으로 파드의 수를 3개로 만든다.
kubectl scale deployment dpy-nginx --replicas=3
스펙을 지정해 오브젝트 생성하기
- 디플로이먼트를 생성하면서 한꺼번에 여러 개의 파드를 만들기 위해서는 오브젝트 스펙을 작성해야된다.
- 오브젝트 스펙은 일반적으로 yaml 문법으로 작성한다.
- apiVersion은 오브젝트를 포함하는 API의 버전을 의미힌다.
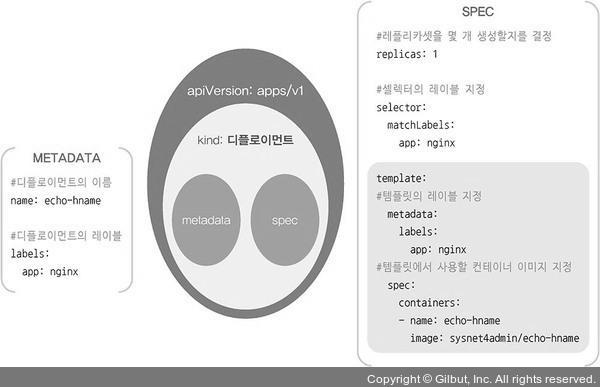
apiVersion: apps/v1 # API 버전
kind: Deployment # 오브젝트 종류
metadata:
name: echo-hname
labels:
app: nginx
spec:
replicas: 3 # 몇 개의 파드를 생성할지 결정
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: echo-hname
image: sysnet4admin/echo-hname # 사용되는 이미지
- 아래는 파드를 나타내는 PodSpec이다.
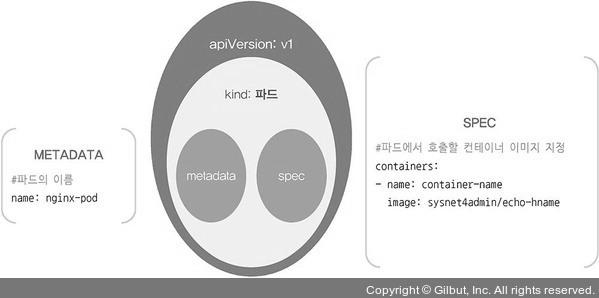
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: container-name
image: nginx
- yaml 파일을 이용해 디플로이먼트 생성
kubectl create -f ~/echo-hname.yaml
apply로 오브젝트 생성하고 관리하기
- 앞에서 다른
create명령어로 디플로이먼트를 생성하면 yaml 파일의 수정 내용을 적용할 수 없다. apply로 yaml 파일 수정 내용을 반영할 수 있다.kubectl apply -f ~/echo-hname.yaml
- 만약
create로 생성한 디플로이먼트에apply명령문을 실행하면 아래와 같이 경고가 뜨지만 동작은 한다. 따라서, 변경 사항이 발생할 가능성이 있는 오브젝트는 처음부터 apply로 생성하는 것이 좋다.
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
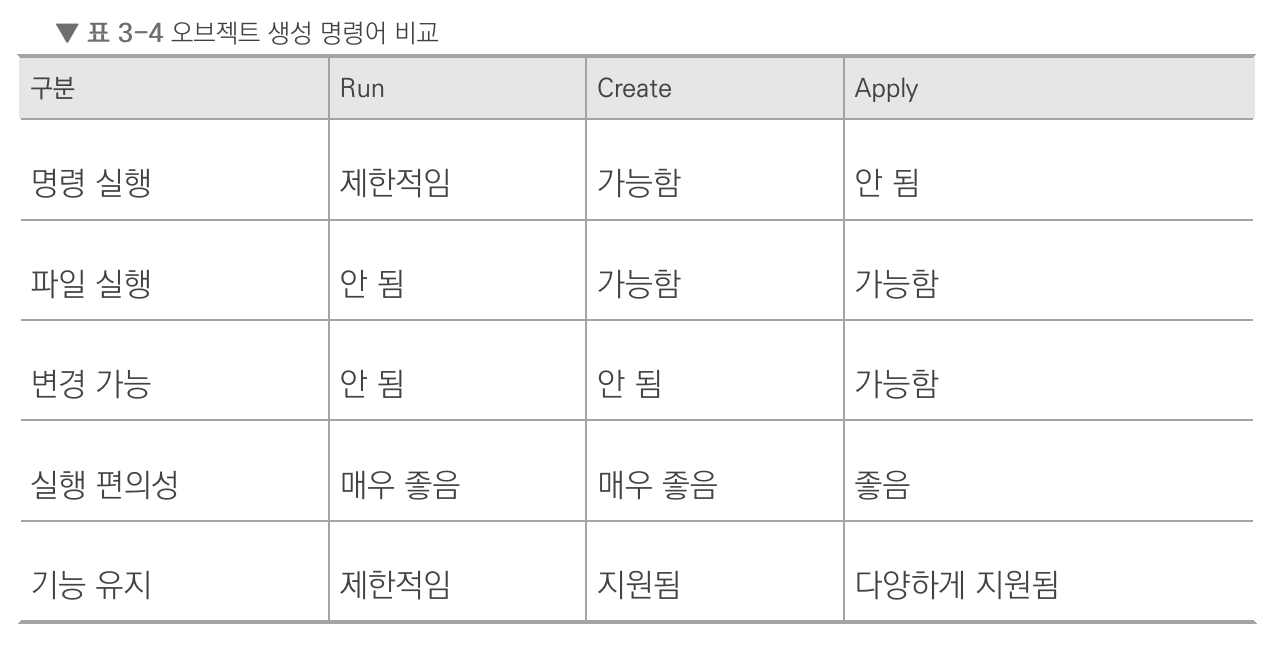
파드의 컨테이너 자동 복구 방법
- 쿠버네티스의 거의 모든 부분이 자동 복구되도록 설계됐다. 이런 자동 복구 기술을 셀프 힐링이라고 한다.
파드 컨테이너의 셸 접속 방법
kubectl exec -it nginx-pod -- /bin/bashi 옵션은 표준 입력을 의미하고, t 옵션은 tty(teletypewriter)를 뜻한다. 즉, 표준 입력을 명령줄 인터페이스로 작성한다는 의미다.
파드의 동작 보증 기능
- 디플로이먼트의 레플리카셋은 선언한 파드의 개수를 보장해준다.
- 레플리카셋은 파드를 선언한 수대로 유지하도록 파드의 수를 항상 확인하고 부족하면 새로운 파드를 만들어낸다.
- 디플로이먼트에 속한 파드를 삭제하려면, 디플로이먼트를 삭제해야 한다.
kubecrtl delete deployment echo-hname
노드의 자원 보호하기
- 노드의 목적: 쿠버네티스 스케줄러에서 파드를 할당받고 처리하는 역할
- 특정 노드에 문제가 생겼다면 쿠버네티스의
cordon기능을 사용해, 해당 노드에 파드가 할당되지 않게 스케줄되지 않는 상태(SchedulingDisabled)로 만든다. - 아래와 같이 스케줄되지 않는 상태의 노드는 STATUS에
SchedulingDisabled표시가 되어 있는 것을볼 수 있다. 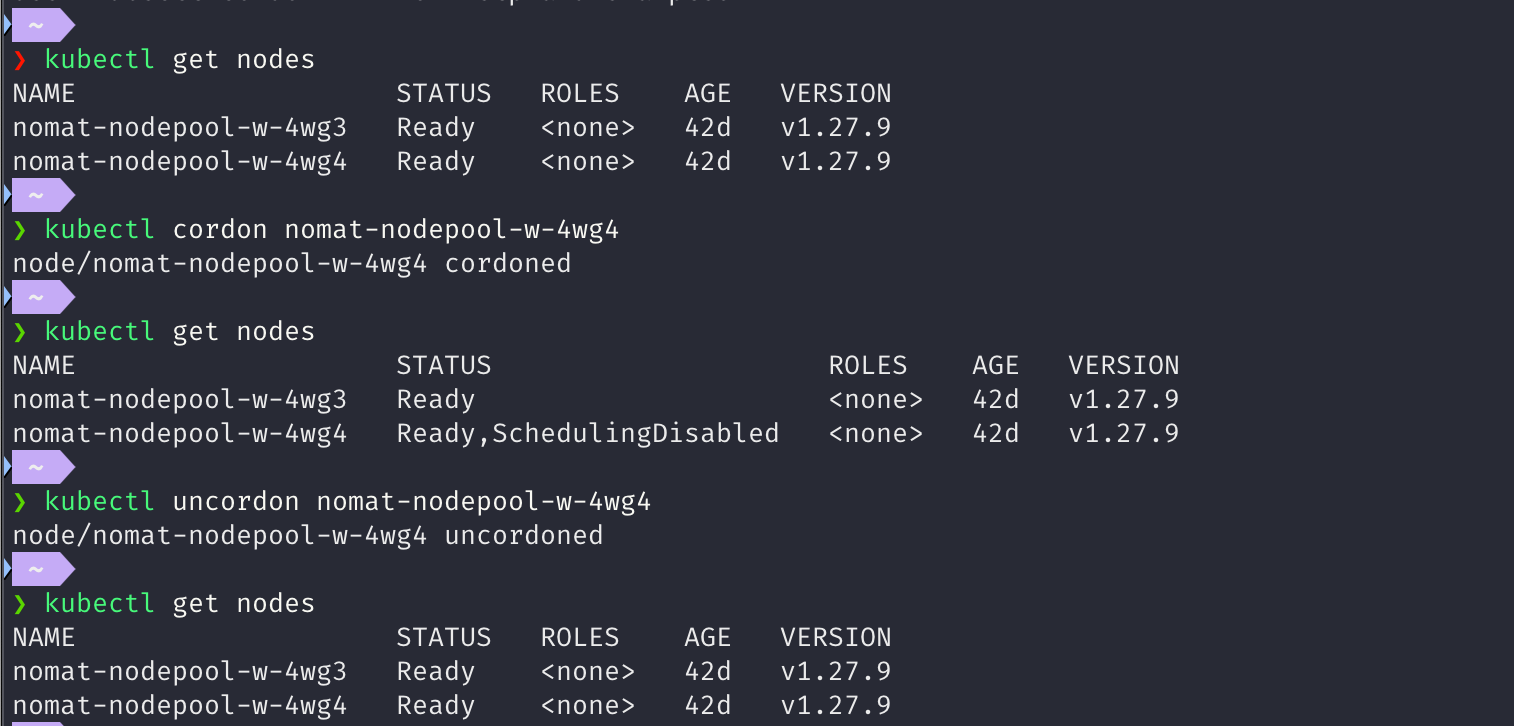
노드 유지보수하기
- 커널 업데이트 등 유지보수를 위해 노드를 꺼야 하는 상황이 있다.
- 이를 대비해 쿠버네티스는
drain기능을 통해, 지정된 노드의 파드를 전부 다른 곳으로 이동시킨다. kubectl drain w3-k8s- 이렇게 실행하면 DaemonSet 파드를 삭제할 수 없다는 오류가 발생할 수 있다.
- DaemonSet은 각 노드에 1개씩 존재하는 파드라서 drain으로 삭제할 수 없기 때문이다.(3.4.1 장에 설명)
kubectl drain w3-k8s --ignore-daemonsets- DaemonSet을 무시하고 실행하도록 한다.
- drain을 사용하면 현재 노드에 있는 파드를 제거하고 다른 노드에 파드를 새로 생성한다.
- 또한 cordon을 실행했을 때 처럼 노드를
SchedulingDisabled상태로 만든다.
- 또한 cordon을 실행했을 때 처럼 노드를
파드 업데이트하고 복구하기
- 파드 업데이트가 필요하거나, 업데이트 중 문제가 발생하면 기존 버전으로 롤백해야 하는 일도 있다.
- 파드 배포할 때
--record옵션을 주면, 배포한 정보의 히스토리를 기록한다.kubectl apply -f ~/.nginx.yaml --record
record옵션으로 기록된 히스토리는rollout history명령을 실행해 확인할 수 있다. `
kubectl rollout history deployment rollout-nginx
deployment.apps/rollout-nginx
REVISION CHANGE-CAUSE
1 kubectl apply --filename=/root/_Book_k8sInfra/ch3/3.2.10/rollout-nginx.yaml --record=true
- 아래와 같이 nginx 버전을 업데이트하면, 파드를 하나씩 순차적으로 지우고 생성한다.
- 이때 파드 수가 많으면 하나씩이 아니라 다수의 파드가 업데이트 된다. 업데이트 기본값은 전체의 1/4개이며, 최솟값은 1개이다.
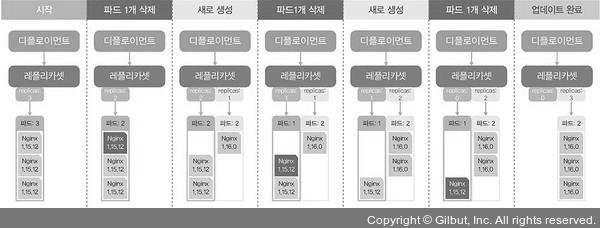
- 아래 명령어로 디플로이먼트의 업데이트 상태를 확인할 수 있다.
kubectl rollout history deployment rollout-nginx
rollout undo명령 실행으로 디플로이먼트의 마지막 던계를 전 단계 상태로 돌릴 수 있다.
$ kubectl rollout history deployment rollout-nginx
deployment.apps/rollout-nginx
REVISION CHANGE-CAUSE
1 kubectl apply --filename=~/_Book_k8sInfra/ch3/3.2.10/rollout-nginx.yaml --record=true
2 kubectl set image deployment rollout-nginx nginx=nginx:1.16.0 --record=true
3 kubectl set image deployment rollout-nginx nginx=nginx:1.17.23 --record=true
$ kubectl rollout undo deployment rollout-nginx
deployment.apps/rollout-nginx rolled back
$ kubectl rollout history deployment rollout-nginx
deployment.apps/rollout-nginx
REVISION CHANGE-CAUSE
1 kubectl apply --filename=/root/_Book_k8sInfra/ch3/3.2.10/rollout-nginx.yaml --record=true
3 kubectl set image deployment rollout-nginx nginx=nginx:1.17.23 --record=true
4 kubectl set image deployment rollout-nginx nginx=nginx:1.16.0 --record=true
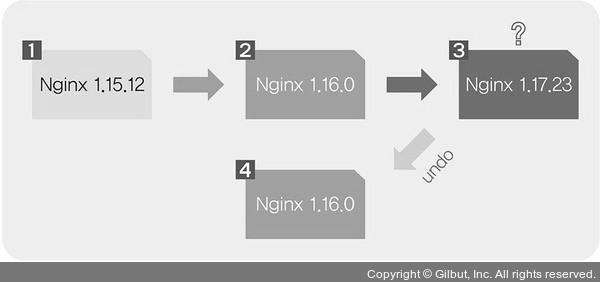
- 바로 전 상태가 아니라 특정 시점으로 돌아가고 싶다면,
--to-revision옵션을 사용한다.kubectl rollout undo deployment rollout-nginx --to-revision=1
쿠버네티스 연결을 담당하는 서비스
- 쿠버네티스에서 ‘서비스’: 외부에서 쿠버네티스 클러스터에 접속하는 방법
- 서비스를 ‘소비를 위한 도움을 제공한다’는 관점으로 바라본다면 쿠버네티스가 외부에서 클러스터에 접속하기 위한 ‘서비스’를 제공한다고 볼 수 있다.
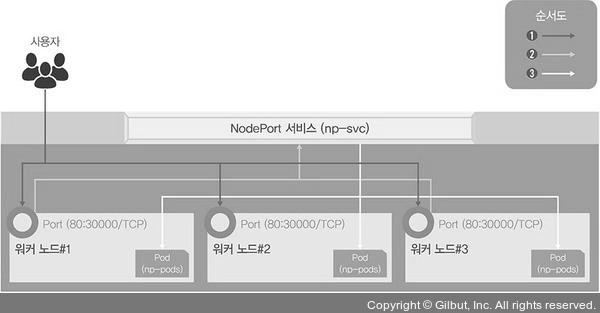
가장 간단하게 연결하는 노드포트
- 노드포트 서비스를 설정하면 모든 워커 노드의 특정 포트를 열고 여기로 오는 모든 요청을 노드포트 서비스로 서비스로 전달한다.
kubectl create로 노드포트 서비스를 생성한다.kubectl create -f ./nodeport.yaml- 아래는
nodepart.yaml파일 내용이다. - 셀렉터로 이름이
np-pods인 오브젝트(디플로이먼트)를 선택했다. - 노드에 30000번 포트로 요청이오면, 파드의 80번 포트로 전달한다.
- 디플로이먼트에 파드가 여러 개 존재하면 자동으로 부하가 분산된다.
apiVersion: v1
kind: Service
metadata:
name: np-svc
spec:
selector:
app: np-pods
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
nodePort: 30000
type: NodePort
- 생성된 서비스 확인:
kubectl get services expose명령령어로도 노드포트 서비스를 생성할 수 있다.kubectl expose deployment np-pods --type=NodePort --name=np-svc-v2 --port=80- 서비스 이름 np-svc-v2
- 서비스가 파드로 보내줄 연결 포트를 80으로 지정
expose를 사용하면 노드포트의 포트 번호는 30000~32767에서 임의 지정된다. 직접 지정할 수 없다.
- 노드포트 제거:
kubectl delete services np-svc-v2
사용 목적별로 연결하는 인그레스
- 노드포트 서비스는 포트를 중복 사용할 수 없어서 1개의 노드포트에 1개의 디플로이먼트만 적용된다.
- 그래서 노드포트를 사용한다면, 여러 개의 디플로이먼트가 있을 때 그 수 만큼 노드포트 서비스를 구동해야된다.
- 인그레스는 고유한 주소를 제공해 사용 목적에 따라 다른 응답을 제공할 수 있고, 트래픽에 대한 L4/L7 로드밸런서와 보안 인증서를 처리하는 기능을 제공한다.
- 인그레스를 사용하려면 인그레스 컨트롤러가 필요하다.
- 여러가지 인그레스 컨트롤러가 있지만, 책에서는 쿠버네티스에서 프로젝트로 지원하는 NGINX 인그레스 컨트롤러로 구성해본다.
- 인그레스 컨트롤러는 파드와 직접 통신할 수 없어서 노드포트 또는 로드밸런서 서비스와 연동이 필요하다.
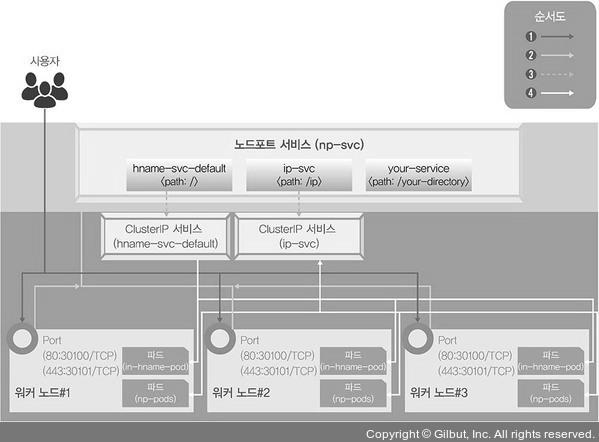
- 인그레스 작동 순서
- 사용자는 노드포트를 통해 노드포트 서비스로 접속한다. 이때 노드포트 서비스를 NGINX 인그레스 컨트롤러로 구성한다.
- NGINX 인그레스 컨트롤러는 사용자의 접속 경로에 따라 적합한 클러스터 IP 서비스로 경로를 제공한다.
- 클러스터 IP 서비스는 사용자를 해당 파드로 연결해준다.
- NGINX 인그레스 컨트롤러 서비스 구성도
- 위 그림 구현해보기
- 디플로이먼트 2개(in-hname-pod, in-ip-pod)를 배포
kubectl create deployment in-hname-pod --image=sysnet4admin/echo-hnamekubectl create deployment in-ip-pod --image=sysnet4admin/echo-ip
- NGINX 인그레스 컨트롤러 설치. 여기에는 많은 종류의 오브젝트 스펙이 포함되어 있어서 책에서 제공하고 있는 yaml 파일을 이용한다.
kubectl appply -f ./ingress-nginx.yaml
- 인그레스를 사용자 요구 사항에 맞게 설정하려면 경로와 작동을 정의해야 한다. yaml 파일로도 설정할 수 있다.
kubectl apply -f ./ingress-config.yaml- 파일은 아래 코드 블럭 참고
- 기본 경로와 80번 노드포트로 요청이 오면 hname-svc-default 서비스와 연결된 파드로 넘기고, 80번 노드포트와 함께 /ip 경로의 요청은 ip-svc 서비스와 연결된 파드로 접속한다.
- 외부에서 NGINX 인그레스 컨트롤러에 접속할 수 있게 노드포트 서비스로 NGINX 인그레스 컨트롤러를 외부에 노출
kubectl apply -f ./ingress.yaml- 파일은 아래 코드 블럭 참고
- http를 처리하기 위해 30100 번 포트로 들어온 요청은 80번 포트로 넘기고, https를 처리하기 위해 30101번 포트로 들어온 것은 443번 포트로 넘긴다.
- NGINX 인그레스 컨트롤러가 위치하는 네임스페이스 ingress-nginx로 지정하고, NGINX 인그레스 컨트롤러의 요구 사항에 따라 셀렉터를 ingress-nginx로 지정했다.
expose명령으로 in-hname-pod, in-ip-pod도 서비스로 노출- 외부와 통신하기 위해 클러스터 내부에서만 사용하는 파드를 클러스터 외부에 노출할 수 잇는 구역으로 옮기는 것이다.
- 내부와 외부 네트워크를 분리해 관리하는 DMZ와 유사한 기능
kubectl expose deployment in-hname-pod --name=hname-svc-default --port=80,443kubectl expose deployment in-ip-pod --name=ip-svc --port=80,443
- 디플로이먼트 2개(in-hname-pod, in-ip-pod)를 배포
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: ingress-nginx
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path:
backend:
serviceName: hname-svc-default
servicePort: 80
- path: /ip
backend:
serviceName: ip-svc
servicePort: 80
- path: /your-directory
backend:
serviceName: your-svc
apiVersion: v1
kind: Service
metadata:
name: nginx-ingress-controller
namespace: ingress-nginx
spec:
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
nodePort: 30100
- name: https
protocol: TCP
port: 443
targetPort: 443
nodePort: 30101
selector:
app.kubernetes.io/name: ingress-nginx
type: NodePort
클라우드에서 쉽게 구성 가능한 로드밸런서
- 앞에서 배운 연결 방식은 들어오는 요청을 모두 워커 노드의 노드포트를 통해 노드포트 서비스로 이동하고 다시 쿠버네티스의 파드로 보내는 구조였다.
- 이 방식은 매우 비효율적이다.
- 그래서 로드밸런서라는 서비스 타입을 제공해 다음과 같은 간단한 구조로 파드를 외부에 노출하고 부하를 분산한다.
kubectl expose deployment ex-lb --type=LoadBalancer --name=ex-svc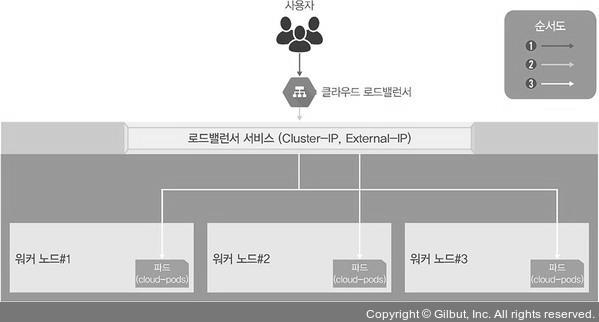
- 로드밸런서를 사용하려면 로드밸런서를 이미 구현해둔 서비스업체의 도움을 받아 쿠버네티스 클러스터 외부에 구현할 수 있다.
- 클라우드에서 제공하는 쿠버네티스를 사용하는 경우에만 위 명령어로 선언할 수 있다.
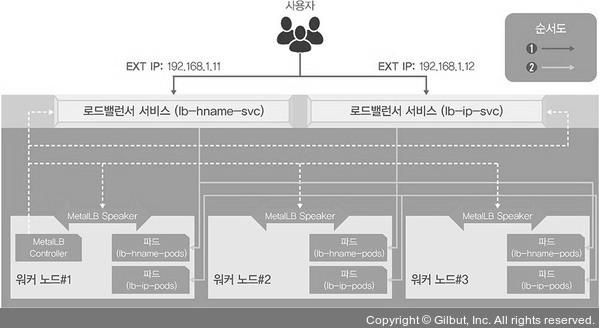
온프레미스에서 로드밸런서를 제공하는 MetalLB
- 온프레미스에서 로드밸런서를 사용하려면 내부에 로드밸런서 서비스를 받아주는 구성이 필요한데, 이를 지원하는 것이 MetalLB이다.
- MetalLB는 네트워크 설정이나 구성이 있는 거이 아니라 기존의 L2 네트워크(ARP/NDP)와 L3 네트워크(BGP)로 로드밸런서를 구현한다.
- 책에서는 미리 구성된 MetalLB를 실행해보는 형식의 실습이라 생략
부하에 따라 자동으로 파드 수를 조절하는 HPA
- 갑자기 늘어난 부하량에 따라 디플로이먼트의 파드 수를 유동적으로 관리하는 기능을 HPA(Horizontal Pod Autoscaler)라고 한다.
- HPA 작동 구조
- HPA가 메트릭 서버를 통해 계측값을 전달받고, 더 많은 자원이 필요한 경우 scale 요청을 하게 된다.

- 메트릭 서버 설치
- 메트릭 서버를 설정하고 나면
kubectl top pods명령으로 파드의 메트릭을 확인할 수 있다.- 여기서 단위 m은 milliunits의 약어로 1000m은 1개의 CPU가 된다. 파드가 CPU 1개의 1초를 사용하면 1000m가 된다.
[root@m-k8s ~]# kubectl top pods
NAME CPU(cores) MEMORY(bytes)
hpa-hname-pods-9b7b5d789-lwx79 0m 1Mi
kubectl edit deployment hpa-hname-pods명령어로 각 파드마다 주어진 부하량을 결정하는 기준을 설정할 수 있다.- requests.cpu “10m"는 파드의 CPU 0.01 사용을 기준으로 파드를 증설하게 설정하는 것이다.
- limits.cpu “50m"는 순간적으로 한쪽 파드에 부하가 몰리는 경우를 대비해 CPU 사용 사용 제한을 0.05s로 주는 것이다.
[root@m-k8s ~]# kubectl edit deployment hpa-hname-pods
[중략]
35 spec:
36 containers:
37 - image: sysnet4admin/echo-hname
38 imagePullPolicy: Always
39 name: echo-hname
40 resources:
requests:
cpu: "10m"
limits:
cpu: "50m"
41 terminationMessagePath: /dev/termination-log
42 terminationMessagePolicy: File
[생략]
:wq
deployment.apps/hpa-hname-pods edited
kubectl autoscale deployment hpa-hname-pods --min=1 --max=30 --cpu-percent=50로 hpa 를 설정할 수 있다.- min은 최소 파드 수
- max는 최대 파드 수
- cpu-percent는 CPU 사용량이 50%를 넘게되면 autoscale 하겠다는 뜻이다.
- 만약 현재 파드의 수가 1개고 CPU 사용량이 29m라면,
- 1개의 파드가 처리할 수 있는 부하는 10m이고, CPU 부하량이 50%가 넘으면 추가 파드를 생성해야 하므로 부하가 5m이 넘으면 파드를 증설하게 돼 있다.
- 29/5를 하고 올림하면 6이므로 파드 6개로 증설하게 될 것이다.
- 현재 파드가 6개이고 1개의 파드만 24m, 나머지 파드는 0m라면
- 디플로이먼트 기준으로 부하 분산이 이루어지므로, 디플로이먼트 내 파드에서 50%가 넘지 않아서 추가 파드가 생성되지 않는다.
kubectl get hpa로 HPA 현재 상태를 요약해서 볼 수 있다.
[root@m-k8s ~]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
hpa Deployment/hpa 48%/50% 1 30 6 9m35s
알아두면 쓸모 있는 쿠버네티스 오브젝트
데몬셋
- 디플로이먼트의 replicas가 노드 수만큼 정해져 있는 형태라고 할 수 있는데, 노드 하나당 파드 한 개만 생성한다.
- kube-proxy, MetalLB의 스피커 같이 노드를 관리하는 파드라면 데몬셋으로 만드는 것이 효율적이다.
컨피그맵
- 설정을 목적으로 하는 오브젝트이다.
PV와 PVC
파드에서 생성한 내용을 기록하고 보관하거나 모든 파드가 동일한 설정 값을 유지하고 관리하기 위해 공유된 볼륨으로부터 공통된 설정을 가지고 올 수 있도록 설계할 때 사용할 수 있다.
쿠버네티스에서 제공하는 볼륨
- 임시: emptyDir
- 로컬: host path, local
- 원격: persistentVolumeClaim, cephfs, cinder, csi, fc(fibre channel), flexVolume, flocker, glusterfs, iscsi, nfs, portworxVolume, quobyte, rbd, scalelO, storageos, vsphereVolume
- 특수 목적: downwardAPI, configMap, secret, azureFile, projected
- 클라우드: awsElasticBlockStore, azureDisck, gcePersistentDisk
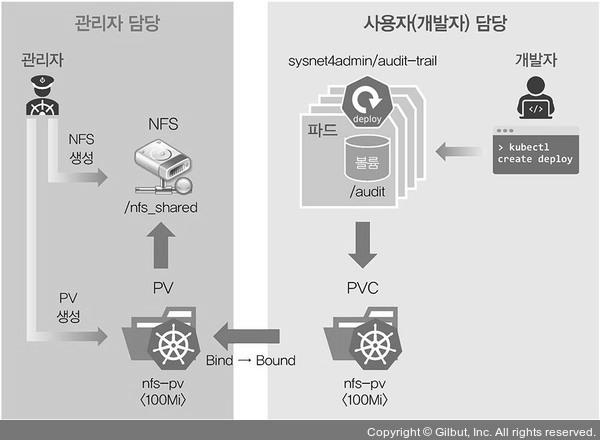
쿠버네티스는 필요할 때 PVC(PersistentVolumeClaim)을 요청해 사용한다.
PVC를 사용하려면 PV로 볼륨을 선언해야 한다.
- PV는 볼륨을 주비하는 단계이고, PVC는 준비된 볼륨에서 일정 공간을 할당받는 것이다.
PV로 볼륨을 선언할 수 있는 타입은 다음과 같다.
nfs를 이용한 PV 생성
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Mi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
nfs:
server: 192.168.1.10
path: /nfs_shared
- nfs PV의 PVC 생성
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Mi
- 아래와 같이 Deployment 생성 시 볼륨을 지정해주면 생성해놓은 PVC를 사용할 수 있다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-pvc-deploy
spec:
replicas: 4
selector:
matchLabels:
app: nfs-pvc-deploy
template:
metadata:
labels:
app: nfs-pvc-deploy
spec:
containers:
- name: audit-trail
image: sysnet4admin/audit-trail
volumeMounts:
- name: nfs-vol
mountPath: /audit
volumes:
- name: nfs-vol
persistentVolumeClaim:
claimName: nfs-pvc
- 볼륨 용량 제한하는 방법
- PVC로 PV에 요청되는 용량을 제한하는 방법
- LimitRange를 아래와 같이 설정하면 PVC가 사용하는 총 용량이 5Mi를 넘으면 에러가 발생하도록 제한된다.
- 스토리지 리소스에 대한 사용량을 제한하는 방법
- resourceQuota를 생성햐여, 스토리지를 사용할 수 있는 용량을 25Mi로 제한하고 생성할 수 있는 PVC를 5개로 제한한다.
- PVC로 PV에 요청되는 용량을 제한하는 방법
apiVersion: v1
kind: LimitRange
metadata:
name: storagelimits
spec:
limits:
- type: PersistentVolumeClaim
max:
storage: 5Mi
min:
storage: 1Mi
apiVersion: v1
kind: ResourceQuota
metadata:
name: storagequota
spec:
hard:
persistentvolumeclaims: "5"
requests.storage: "25Mi"
스테이트풀셋
- 파드가 만들어지는 이름과 순서를 예측할 수 있어야되는 경우에 스테이트풀셋을 사용한다.
- 또한 스테이트풀셋는 volumeClaimTemplates 기능을 사용해 PVC를 자동으로 생성할 수 있고, 각 파드가 순서대로 생성되기 때문에 고정된 이름, 볼륨, 설정 등을 가질 수 있다.
- 이전 상태를 기억하는 세트이고, 효율성 면에서 좋은 구조가 아니므로 요구 사항에 맞게 적절히 사용하는 것이 좋다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nfs-pvc-sts
spec:
replicas: 4
serviceName: sts-svc-domain #statefulset need it
selector:
matchLabels:
app: nfs-pvc-sts
template:
metadata:
labels:
app: nfs-pvc-sts
spec:
containers:
- name: audit-trail
image: sysnet4admin/audit-trail
volumeMounts:
- name: nfs-vol # same name of volumes's name
mountPath: /audit
volumes:
- name: nfs-vol
persistentVolumeClaim:
claimName: nfs-pvc
- 스테이트풀셋은
expose명령을 지원하지 않기 때문에, 직접 로드밸런스 서비스를 생성해야 된다.
apiVersion: v1
kind: Service
metadata:
name: nfs-pvc-sts-svc
spec:
selector:
app: nfs-pvc-sts
ports:
- port: 80
type: LoadBalancer