- API에 처리율 제한을 두면 좋은점
- DoS 공격에 의한 자원 고갈을 방지할 수 있다.
- 비용을 절감할 수 있다.
- 서버 과부하를 막는다.
1단계 문제 이해 및 설계 범위 확정#
- 면접관과 소통하면서 어떤 제한 장치를 구현해야 하는지 분명히 한다.
- 예시:
- 설정된 처리율을 초과하는 요청은 정확하게 제한한다.
- 낮은 응답 시간
- 가능한 한 적은 메모리를 써야 한다.
- 분산형 처리율 제한: 하나의 처리율 제한 장치를 여러 서버나 프로세스에서 공유할 수 있어야 한다.
- 예외 처리: 요청이 제한되었을 때는 그 사실을 사용자에게 분명하게 보여주어야 한다.
- 높은 결함 감내성: 제한 장치에 장애가 생기더라도 전체 시스템에 영향을 주어서는 안된다.
2단계 개략적 설계안 제시 및 동의 구하기#
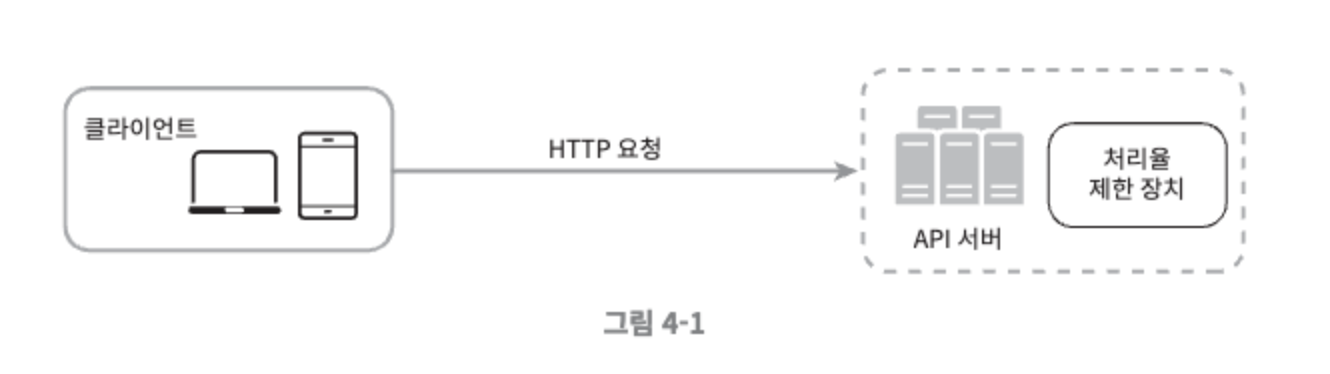
처리율 제한 장치는 어디에 둘 것인가?#
- 클라이언트 요청은 쉽게 위변조가 가능해, 클라이언트는 처리율 제한을 안정적으로 걸 수 있는 장소가 못된다.
- 서버 측에 두는 방법1: API 서버에 처리율 제한 장치를 둔다.
- 서버 측에 두는 방법2: 처리율 제한 미들웨어를 만들어 해당 미들웨어로 하여금 API 서버로 가는 요청을 통제한다.
- 클라우드 마이크로서비스의 경우, 처리율 제한 장치는 보통 API 게이트웨이라 불리는 컴포넌트에 구현된다.
- API 게이트웨이: 처리율 제한, SSL 종단, 사용자 인증, IP 허용 목록 관리 등을 지원하는 완전 위탁관리형 서비스
- 처리율 제한 기능을 설계할 때 적용할 수 있는 지침
- 프로그래밍 언어, 캐시 서비스 등 현재 사용하고 있는 기술 스택을 점검한다.
- 사업 필요에 맞는 처리율 제한 알고리즘을 찾는다.
- 사용자 인증이나 IP 허용목록 관리 등을 처리하기 위해 API 게이트웨이를 이미 설계에 포함시켰다면 처리율 제한 기능 또한 게이트웨이에 포함시켜야 할 수도 있다.
- 처리율 제한 장치를 구현하기에 충분한 인력이 없다면 상용 API 게이트웨이를 쓰는 것이 바람직한 방법이다.
처리율 제한 알고리즘#
- 토큰 버킷 알고리즘
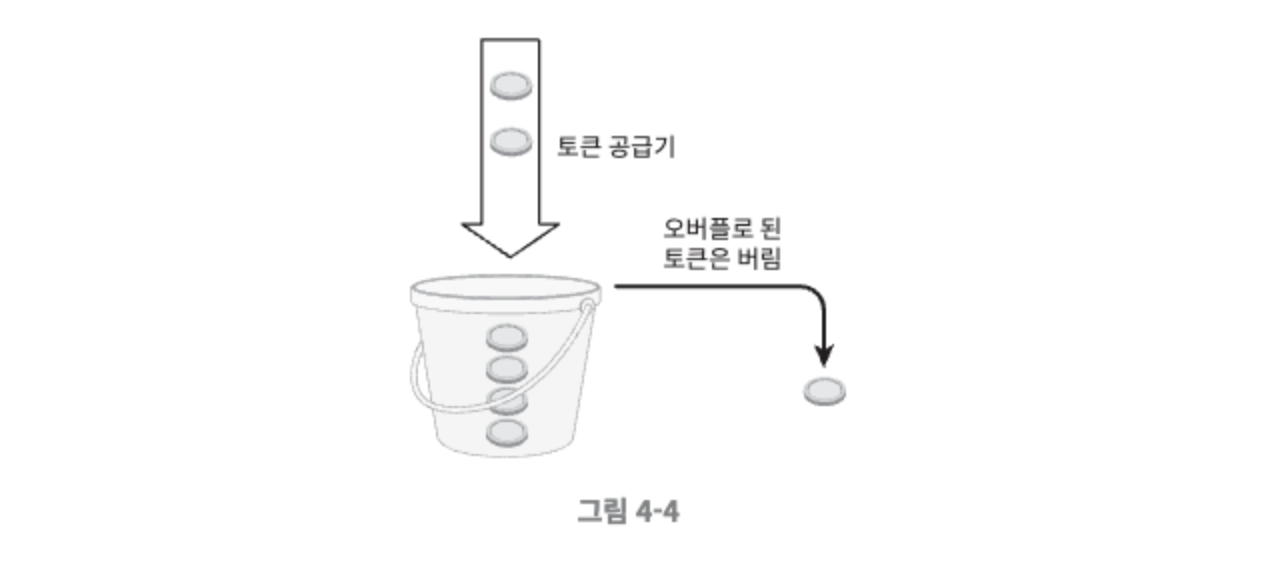
- 토큰 버킷: 지정된 용량을 갖는 컨테이너
- 버킷에는 사전에 설정된 양이 주기적으로 채워진다. 토큰이 꽉 찬 버킷에는 더 이상의 토큰은 추가되지 않는다.
- 각 요청은 처리될 때마다 하나의 토큰을 사용한다. 충분한 토큰이 없는 경우, 해당 요청은 버려진다.
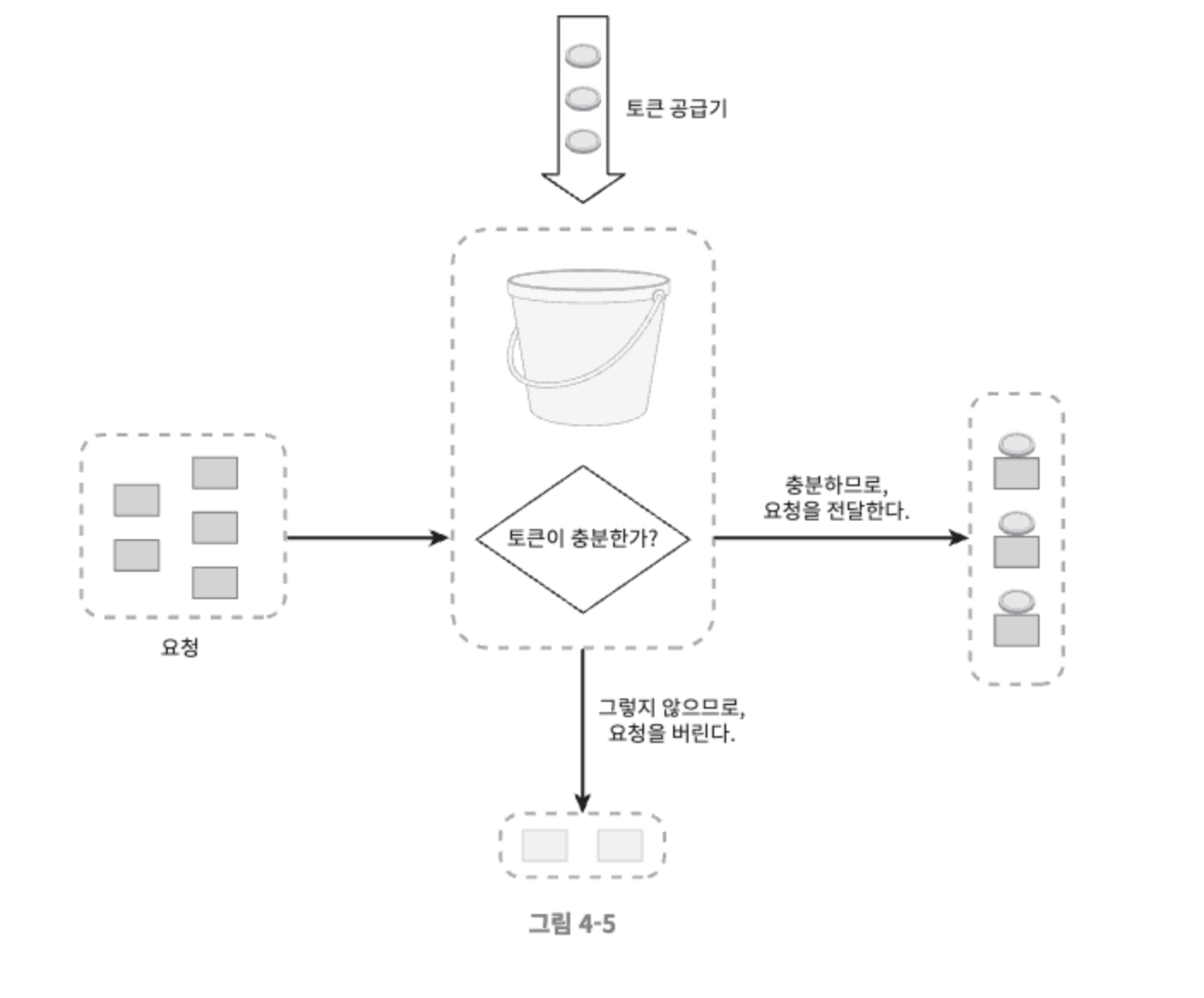
- 토큰 버킷 알고리즘 파라미터 2개
- 버킷 크기: 버킷에 담을 수 있는 토큰의 최대 개수
- 토큰 공급률(refill rate): 초당 몇 개의 토큰이 버킷에 공급되는가
- 장점
- 구현이 쉽다.
- 메모리 사용 측면에서 효율적이다.
- 짧은 시간에 집중되는 트래픽도 처리 가능하다.
- 단점
- 파라미터가 2가지 있는데, 값을 적절하게 튜닝하는 것이 까다롭다.
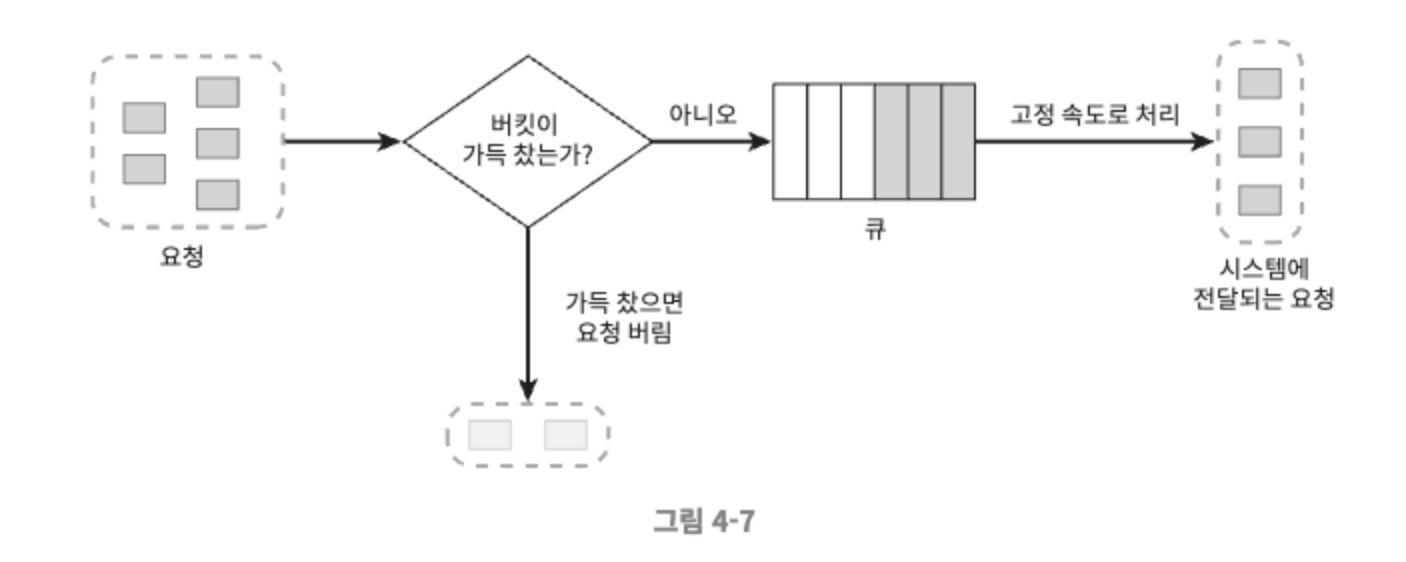
- 누출 버킷 알고리즘
- FIFO 큐로 구현한다.
- 요청이 도착하면 큐가 가득 차 있는지 본다. 빈자리가 있으면 큐에 요청을 추가하고, 없으면 요청을 버린다.
- 지정된 시간마다 큐에서 요청을 꺼내어 처리한다.
- 알고리즘 파라미터 2개
- 버킷 크기: 큐 사이즈와 같은 값
- 처리율: 지정된 시간당 몇 개의 항목을 처리할지 지정하는 값
- 장점
- 큐의 크기가 제한되어 있어서 메모리 사용량 측면에서 효율적이다.
- 고정된 처리율을 갖고 있기 때문에 안정적 출력이 필요한 경우에 적합하다.
- 단점
- 단시간에 많은 트래픽이 몰리는 경우 큐에 오래된 요청들이 쌓이게 되고, 그 요청들을 제떄 처리 못하면 최신 요청들은 버려지게 된다.
- 두 개 인자를 갖고 있는데, 이들을 올바르게 튜닝하기 까다로울 수 있따.
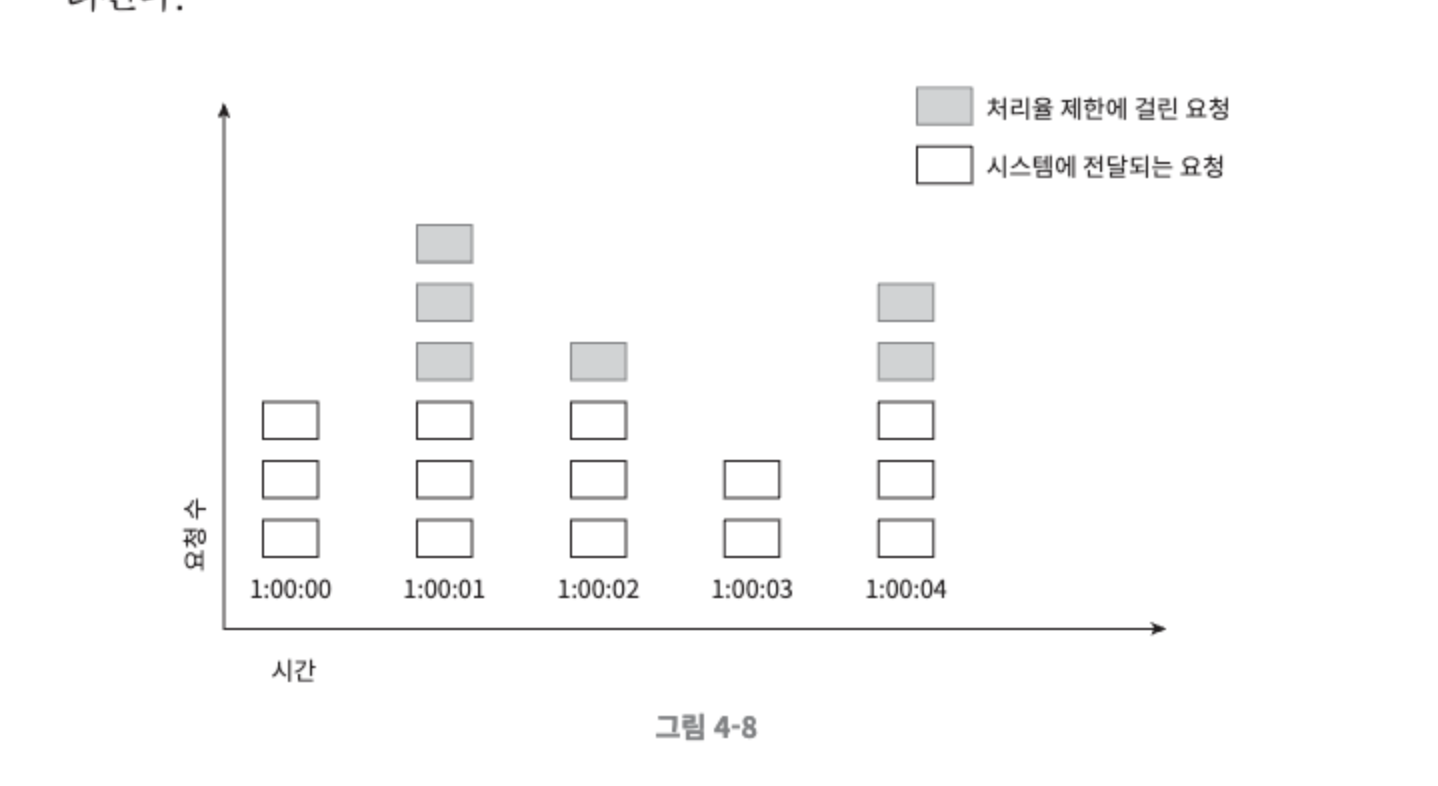
- 고정 윈도 카운터 알고리즘
- 타임라인을 고정된 간격의 윈도로 나누고, 각 윈도마다 카운터를 붙인다.
- 요청이 접수될 때마다 이 카운터의 값은 1씩 증가한다.
- 이 카운터의 값이 사전에 설정된 임계치에 도달하면 새로운 요청은 새 윈도가 열릴 때까지 버려진다.
- 장점
- 메모리 효율이 좋다.
- 이해하기 쉽다.
- 윈도가 닫히는 시점에 카운터를 초기화하는 방식은 특정한 트래픽 패턴을 처리하기에 적합하다.
- 단점
- 윈도 경계 부근에서 일시적으로 많은 트래픽이 몰려드는 경우, 기대했던 시스템의 처리 한도보다 많은 양의 요청을 처리하게 된다.
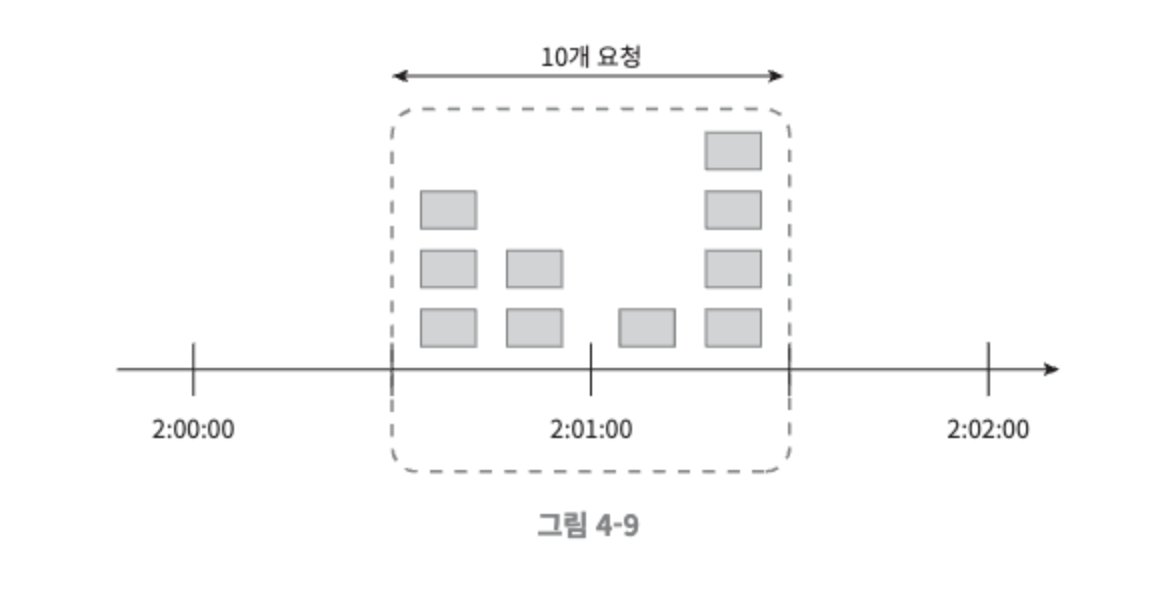
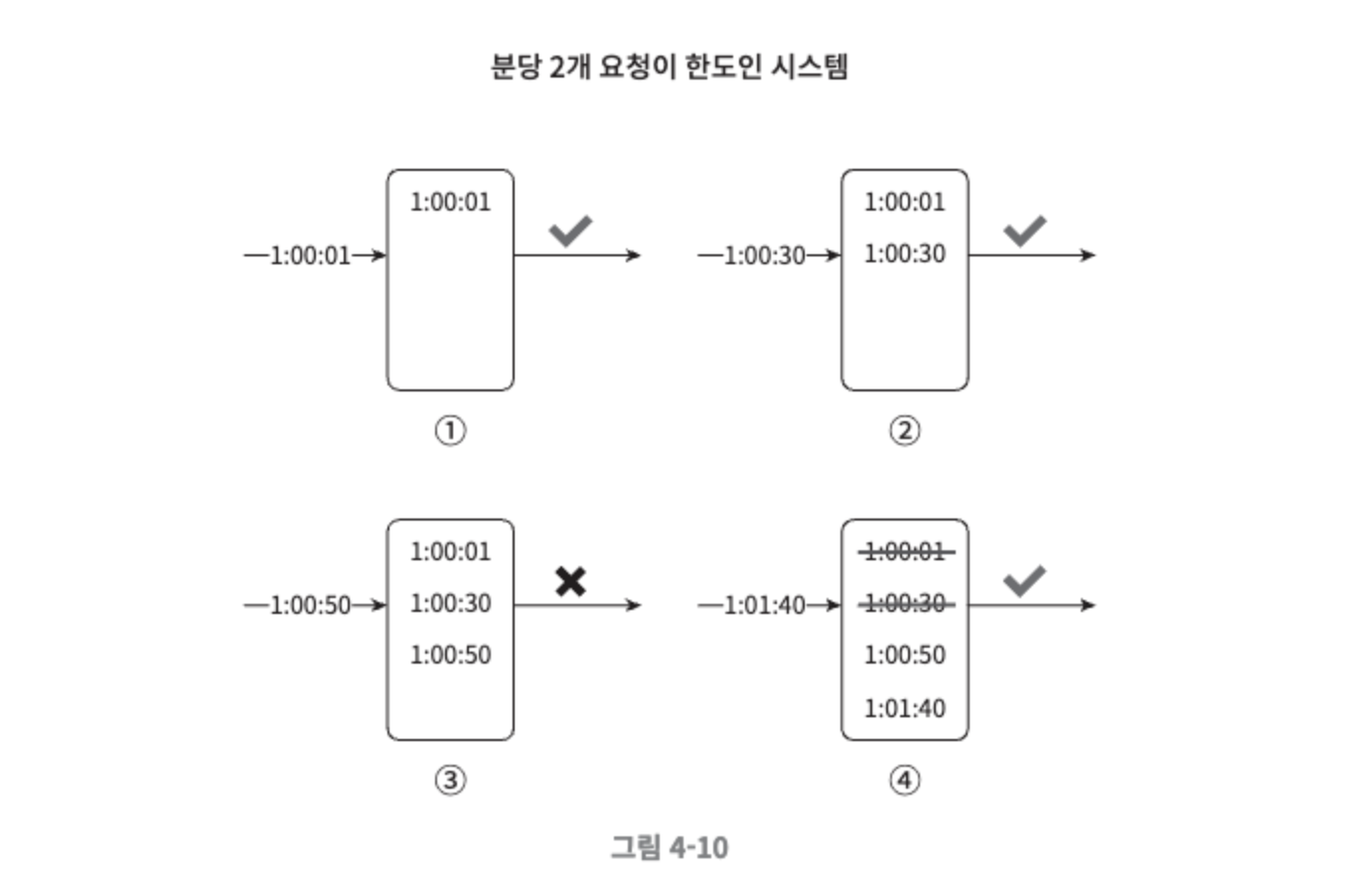
- 이동 윈도 로깅 알고리즘
- 요청의 타임 스탬프를 추적한다.
- 새 요청이 오면 만료된 타임스팸트는 제거한다. 만료된 타임스탬프는 그 값이 현재 윈도의 시작 시점보다 오래된 타임스탬프를 말한다.
- 새 요청의 타임스탬프를 로그에 추가한다.
- 로그의 크기가 허용치보다 같거나 작으면 요청을 시스템에 전달한다. 그렇지 않은 경우에는 처리를 거부한다.
- 장점
- 아주 정교하다. 어느 순간의 윈도를 보더라도, 허용되는 요청의 개수는 기스템의 처리율 한도를 넘지 않는다.
- 단점
- 다량의 메모리를 사용하늗네, 거부된 요청의 타임스탬프도 보관하기 때문이다.
- 이동 윈도 카운터 알고리즘
- 고정 윈도 카운터와 이동 윈도 로깅 알고리즘을 결합
- 현재 1분간의 요청 수 + 직전 1분간의 요청수 * 이동 윈동와 직전 1분이 겹치는 비율
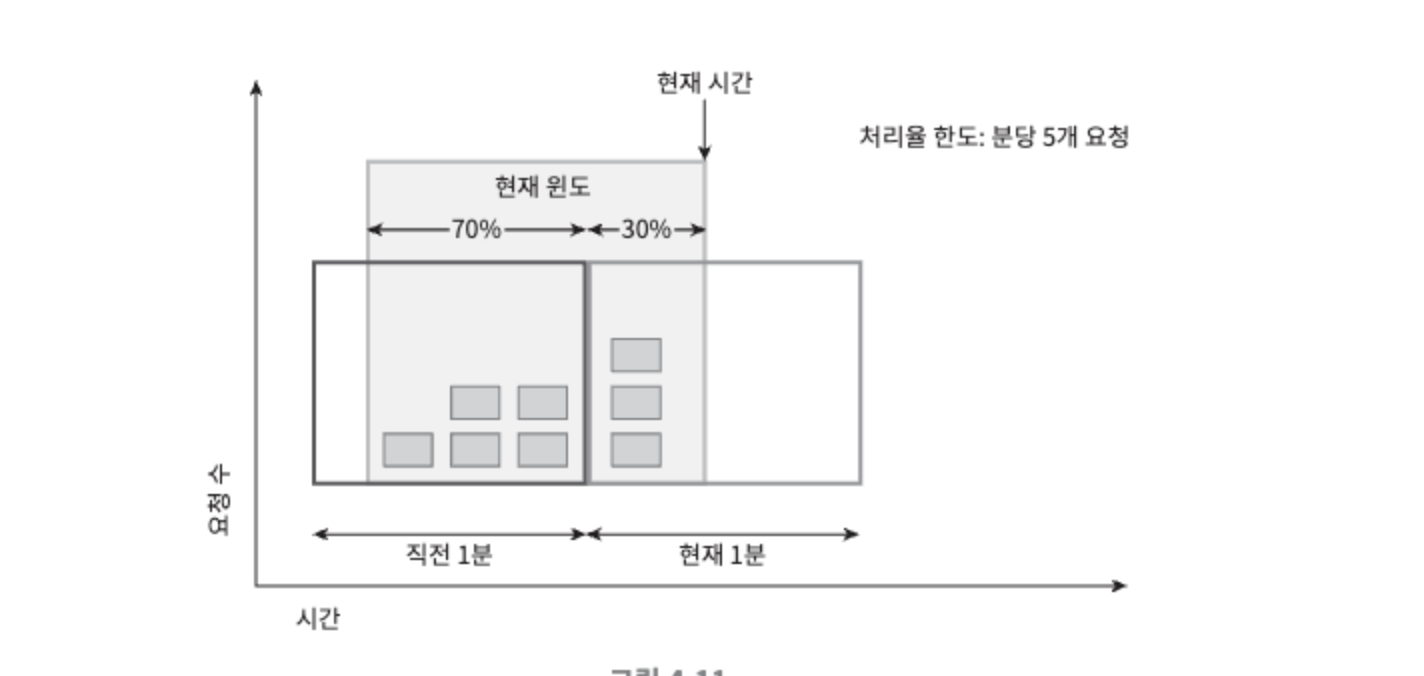
- 장점
- 짧은 시간에 몰리는 트래픽에도 잘 대응한다.
- 메모리 효율이 좋다.
- 단점
- 도착한 요청이 균등하게 분포되어 있다고 가정한 상태에서 추정치를 계산하기 때문에 다소 느슨하다. 하지만 이 문제는 생각만큼 심각한 것은 아니다.
개략적인 아키텍처#
- 카운터 추적 대상: 사용자 추적, IP 주소, API 엔드 포인트
- 카운터 보관 위치
- 데이터베이스는 디스크 접근 때문에 느리다.
- 메모리상 동작하는 캐시가 바람직한데, 빠른데다 시간에 기반한 만료 정책을 지원하기 때문이다.
- Redis는 처리율 제한 장치를 구현할 때 자주 사용되는 메모리 기반 저장장치로서 INCR과 EXPIRE의 두 가지 명령어를 지원한다.
- INCR: 메모리에 저장된 카운터 값을 1만큼 증가시킨다.
- EXPIRE: 카운터에 타임아웃 값을 설정한다. 설정된 시간이 지나면 카운터는 자동으로 삭제된다.
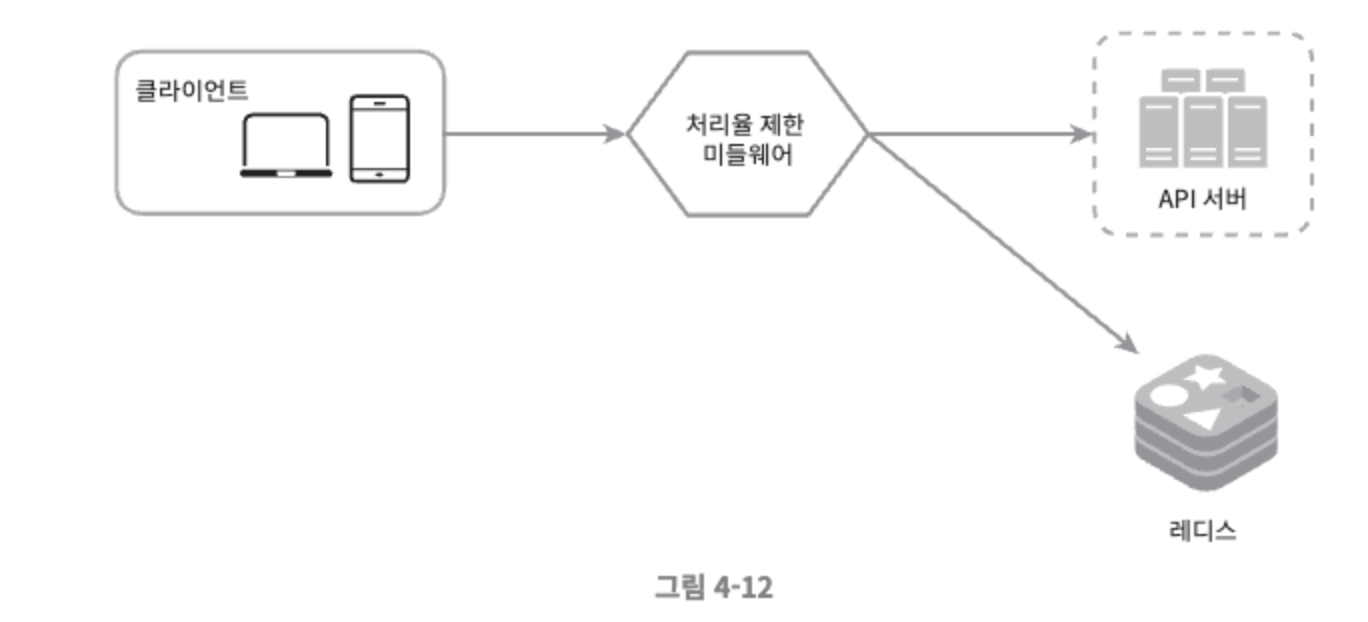
- 동작 원리
- 클라이언트가 처리율 제한 미들웨어에게 요청을 보낸다.
- 처리율 제한 미들웨어는 Redis의 지정 버킷에서 카운터를 가져와 한도에 도달했는지 아닌지를 검사한다. 한도에 도달했다면 요청은 거부된다.
- 한도에 도달하지 않았다면 요청은 API 서버로 전달된다. 한편 미들웨어는 카운터의 값을 증가시킨 후 다시 레디스에 저장한다.
3단계 상세 설계#
처리율 제한 규칙#
- Lyft는 처리율 제한에 오픈 소스를 사용하고 있다.
- 처리율 제한 규칙들을 설정 파일 형태로 디스크에 저장한다.
처리율 한도 초과 트래픽의 처리#
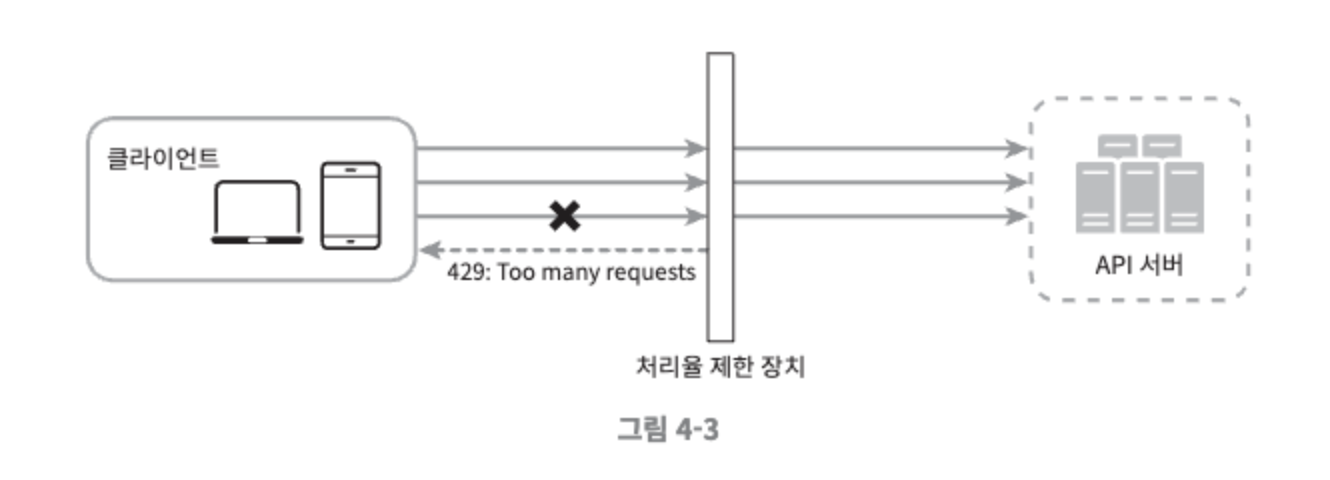
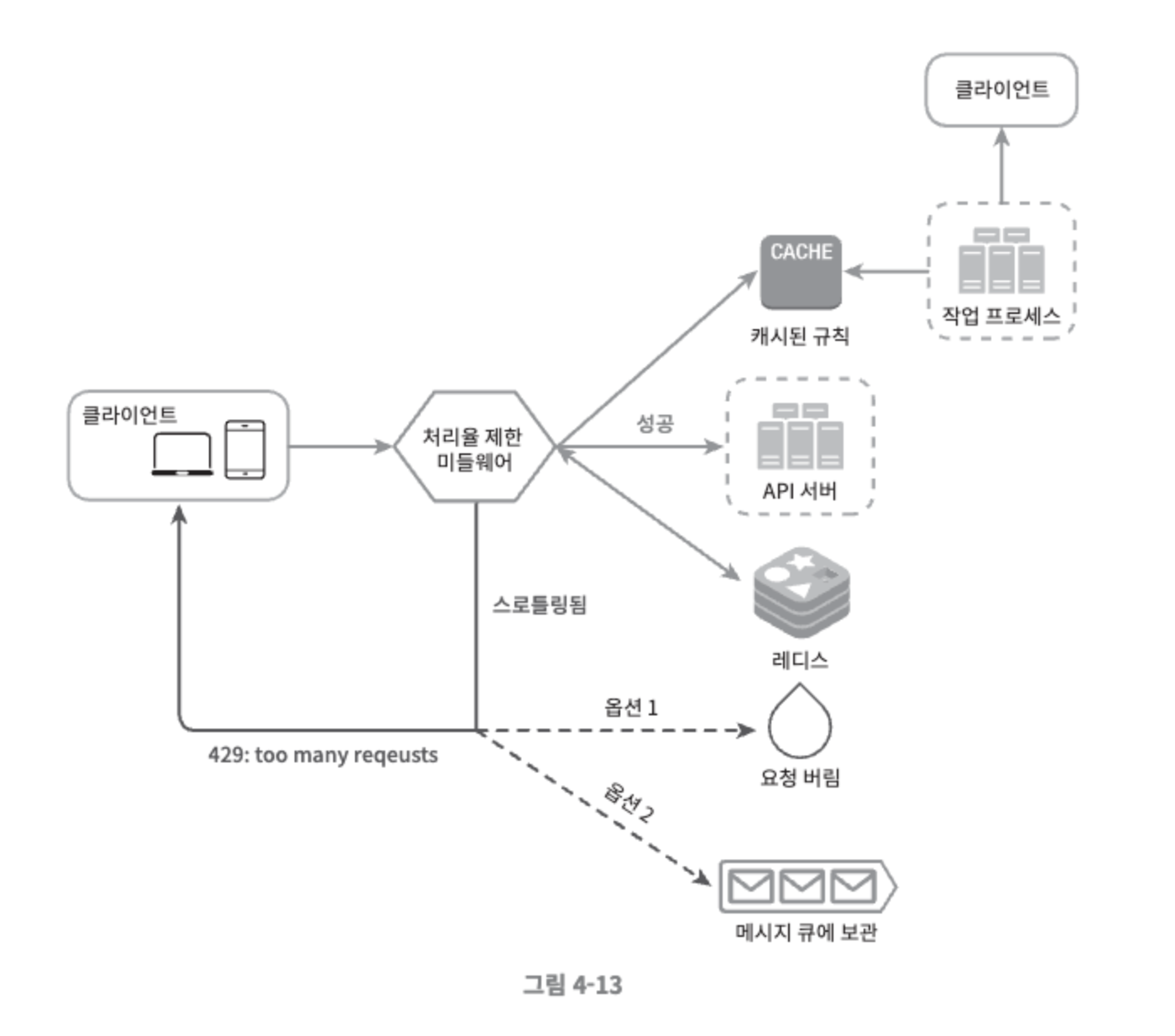
- 어떤 요청이 한도 제한에 걸리면 API는 HTTP 429 응답(too many requests)을 클라이언트에 보낸다.
- 클라이언트가 자기 요청이 처리율 제한이 걸리고 있는지 감지할 수 있도록 HTTP 응답 헤더를 추가할 수 있다.
- X-Ratelimit-Remaining: 윈도 내에 남은 처리 가능 요청의 수
- X-Ratelimit-Limit: 매 윈도마다 클라이언트가 전송할 수 있는 요청의 수
- X-Ratelimit-Retry-After: 한도 제한에 걸리지 않으려면 몇 초 뒤에 요청을 다시 보내야 하는지 알림
상세 설계 도면#
- 처리율 제한 규칙은 디스크에 보관한다. 작업 프로세스는 수시로 규칙을 디스크에서 읽어 캐시에 저장한다.
- 클라이언트가 요청을 서버에 보내면 요청은 먼저 처리율 제한 미들웨어에 도달한다.
- 처리율 제한 미들웨어는 제한 규칙을 캐시에서 가져온다.
- 아울러 카운터 규칙 및 마지막 요청의 타임스탬프를 래디스 캐시에서 가져온다.
분산 환경에서의 처리율 제한 장치의 구현#
- 2가지 문제를 해결해야 된다.
- 경쟁 조건
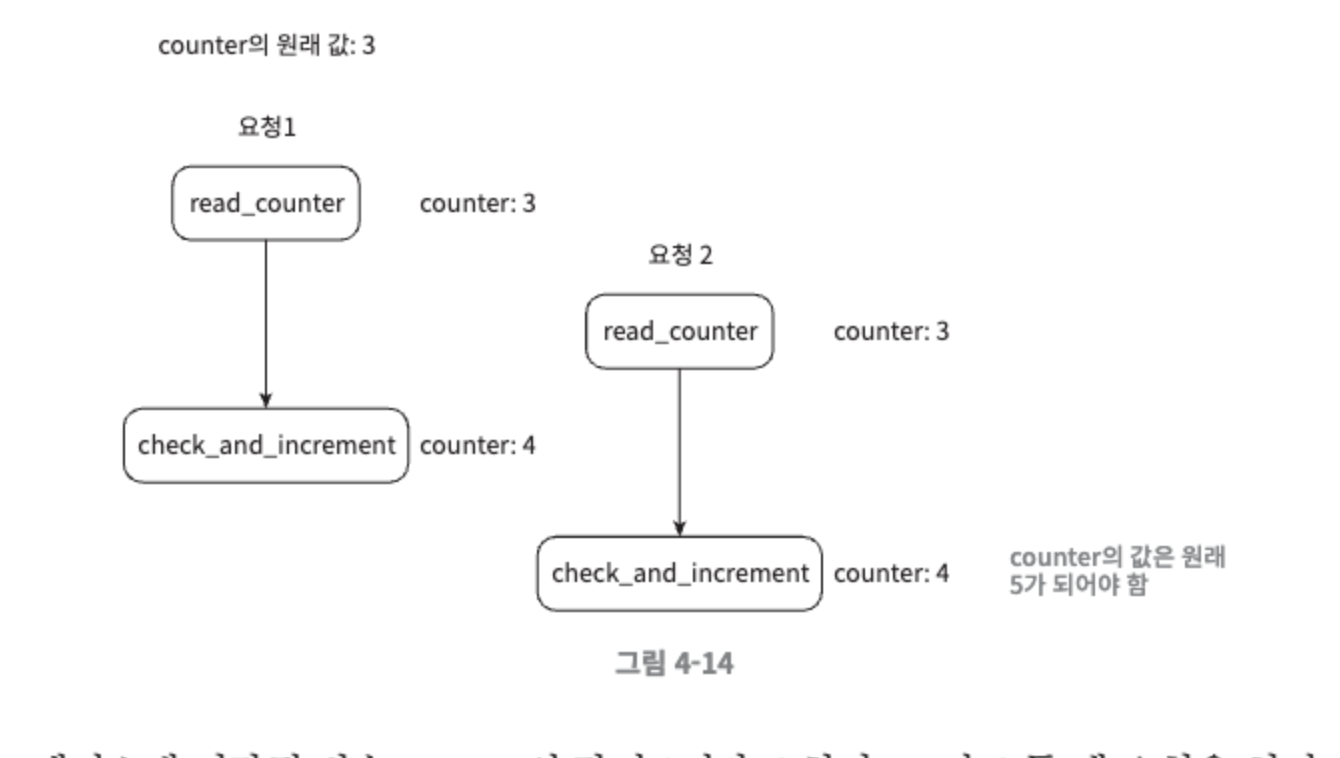
- 가장 널리 알려진 해결책은 락이지만 성능을 떨어뜨린다는 문제가 있다.
- 락 대신 쓸 수 있는 해결책 2가지
- 루아 스크립트
- sorted set이라 불리는 레디스 자료구조
- 동기화 이슈
- 처리율 제한 장치 서버를 여러 대 두게 되면 동기화가 필요해진다.
- 고정 세션을 활용해 같은 클라이언트로부터의 요청은 항상 같은 처리율 제한 장치로 보낼 수 있도록 할 수 있지만, 이는 확장 가능하지도 않고 유연하지도 않다.
- 더 나은 해결책은 레디스와 같은 중앙 집중형 데이터 저장소를 쓰는 것이다.
성능 최적화#
- 여러 데이터센터를 지원하는 문제는 지연시간 증가를 고려해야된다.
- 세계 곧곧에 edge server를 심어놓아 지연시간을 줄인다.
- 제한 장치 간에 데이터를 동기화할 때 최종 일관성 모델(eventual consistency model)을 사용하는 것이다.
모니터링#
- 모니터링을 통해 다음을 확인한다.
- 채택된 처리율 제한 알고리즘이 효과적이다.
- 정의한 처리율 제한 규칙이 효과적이다.