- 추상화: 복잡한 자료, 모듈, 시스템 등으로부터 핵심적인 개념 또는 기능을 간추려 내는 것
- 객체는 여러 형태로 추상화해서 표현할 수 있다.
- 추상화를 하려면 객체에서 무엇을 감추고 무엇을 노출해야 하는지 결정해야 한다.
- 프로그래밍에서는 다음과 같은 목적으로 추상화를 사용한다.
- 복잡성을 숨기기 위해
- 코드를 체계화하기 위해
- 만드는 사람에게 변화의 자유를 주기 위해
함수 내부의 추상화 레벨을 통일하라#
- 계층이 잘 분리되었을 때 장점
- 어떤 계층에서 작업할 때 그 아래의 계층은 이미 완성되어 있으므로, 해당 계층만 생각하면 된다.
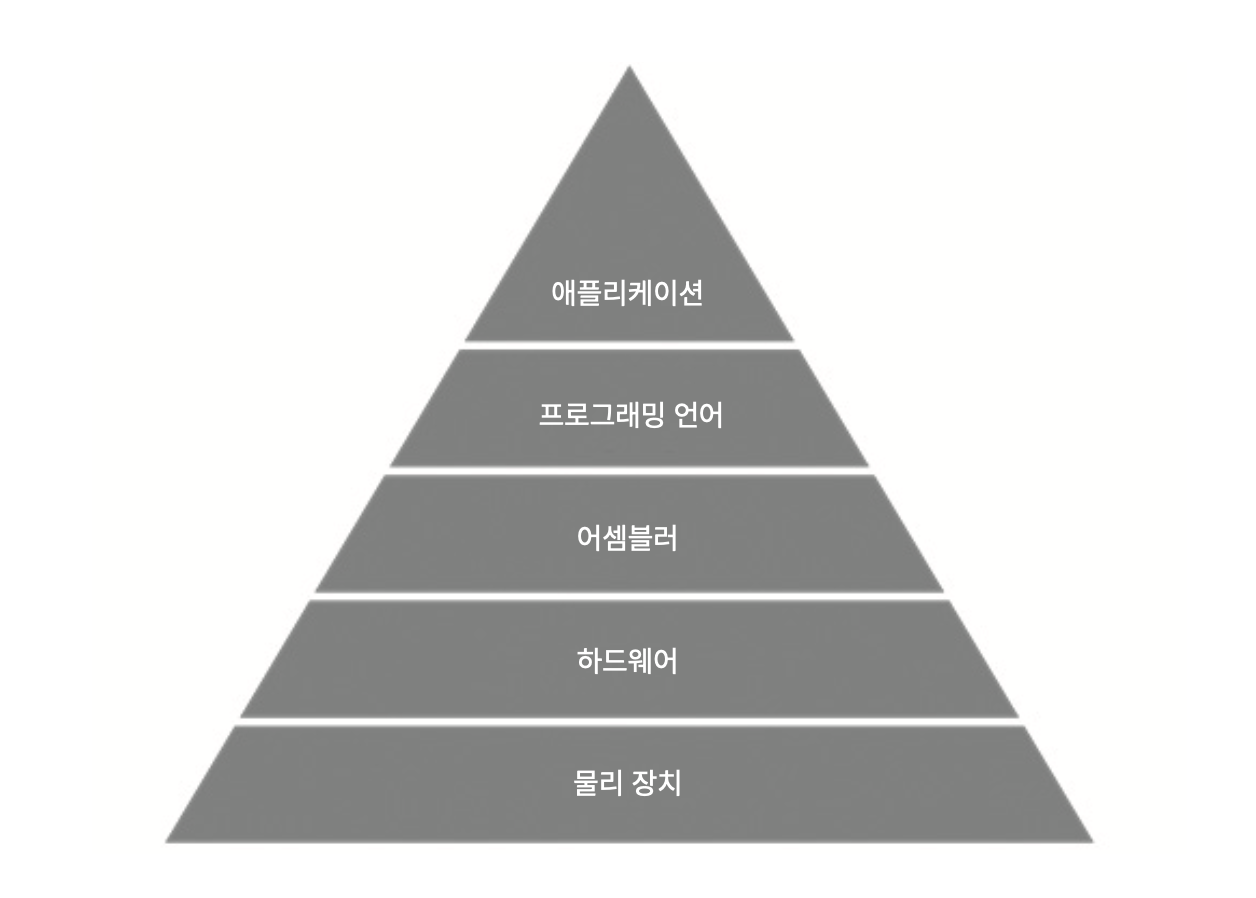
- 높은 레벨일수록 걱정해야 하는 세부적인 내용이 적어지지만, 제어력을 잃는다.(메모리 관리 등)
추상화 레벨 통일#
- 추상화 레벨 통일(Single Level Abstraction, SLA) 원칙: 함수를 높은 레벨과 낮은 레벨로 구분 해서 사용해야 하는 원칙
- 함수는 작아야 하며, 최소한의 책임만을 가지여 한다.
- 어떤 함수가 다른 함수보다 좀 복잡하다면, 일부 부분을 추출해서 추상화 하는 것이 좋다.
- 함수를 추출하면, 재사용과 테스트가 쉬워진다.
프로그램 아키텍처의 추상 레벨#
- 추상화 계층이라는 계념은 함수보다 높은 레벨에서도 적용할 수 있따.
- 추상화를 구분하는 이유는 서브시스템의 세부 사항을 숨김으로써 상호 운영성과 플랫폼 독립성을 얻기 위함이다.
- 모듈을 분리하면 계층 고유의 요소를 숨길 수 있다.
- 애플리케이션을 만들 때 입력과 출력을 나타내는 모듈은 낮은 레벨의 모듈이다.
- 비즈니스 로직을 나타내는 부분이 높은 레벨의 모듈이다.

변화로부터 코드를 보호하려면 추상화를 사용하라#
- 함수와 클래스 등의 추상화로 실질적인 코드를 숨기면, 사용자가 세부 사항을 알지 못해도 괜찮다는 장점이 있다.
- 그리고 이후에 실질적인 코드를 원하는대로 수정할 수도 있다.
- 리터럴을 상수로 추출할 때 장점
- 리터럴에 이름을 붙일 수 있다.
- 나중에 해당 값을 쉽게 변경할 수 있다.
- 리터럴 값이 프로젝트 전체에 퍼져 있다면 변경하기 힘들것이다.
- 함수의 이름을 직접 바꾸는 것은 위험할 수 있다.
- 다른 모듈이 이 함수에 의존하고 있다면, 다른 모듈에 큰 문제가 발생할 것이다.
- 함수는 매우 단순한 추상화지만, 제한이 많다.
- 함수는 상태를 유지하지 않는다.
- 함수 시그니처를 변경하면 프로그램 전체에 큰 영향을 줄 수 있다.
- 구현을 추상화할 수 있는 더 강력한 방법으로 클래스가 있다.
클래스#
- 클래스는 상태를 가질 수 있으며, 많은 함수를 가질 수 있다는 강점을 가지고 있다.
- 생성자를 통해 주입을 한다면 mock 객체를 활용해서 해당 클래스에 의존하는 다른 클래스의 기능을 테스트할 수 있다.
인터페이스#
- 인터페이스를 통해 라이브러리를 노출하면, 사용자가 클래스를 직접 사용하지 못하므로, 라이브러리를 만드는 사람은 인터페이스만 유지한다면 별도의 걱정 없이 자신이 원하는 형태로 그 구현을 변경할 수 있다.
- 인터페이스 뒤에 객체를 숨김으로써 실질적인 구현을 추상화하고, 상요자가 추상화된 것에만 의존하게 만들 수 있다.
- 테스트할 때 인터페이스 페이킹이 클래스 모킹보다 간단하다.
ID 만들기(nextId)#
- 모든 원시 타입의 값들은 의미가 존재한다. 의미 있는 타입으로 감싸서 의미를 전달할 수 있다.
- 원시 타입의 비즈니스 로직은 클래스 안으로 추상화하여, 쉽게 유지보수할 수 있다.
- 비즈니스 로직 변경이 있을 때 해당 클래스만 수정하면 된다.
- 원시 타입을 감싼 클래스의 객체들은 항상 완전한 상태를 보장하고 있다.
- 특정 원시 타입에 구애받지 않고, 다양한 타입을 지원할 수 있다.
추상화가 주는 자유#
- 추상화를 하는 방법
- 상수로 추출한다.
- 동작을 함수로 래핑한다.
- 함수를 클래스로 래핑한다.
- 인터페이스 뒤에 클래스를 숨긴다.
- 보편적인 객체를 특수한 객체로 래핑한다.
- 추상화를 구현할 때 사용할 수 있는 도구
- 제네릭 타입 파라미터를 사용한다.
- 내부 클래스를 추출한다.
- 생성을 제한한다. (팩토리 함수로만 객체를 생성할 수 있게 만든다 등)
추상화의 문제#
- 어떤 방식으로 추상화를 하려면 코드를 읽는 사람이 해당 개념을 배우고, 잘 이해해야 한다.
- 추상화도 비용이 발생하므로, 극단적으로 모든 것을 추상화해서는 안된다.
- 추상화는 많은 것을 숨길 수 있는 테크닉이다. 하지만, 너무 많은 것을 숨기면 결과를 이해하는 것 자체가 어려워진다.
어떻게 균형을 맞춰야 할까?#
- 다음과 같은 요소들에 따라서 달라질 수 있다.
- 팀의 크기
- 팀의 경험
- 프로젝트 크기
- 특징 세트
- 도메인 지식
- 사용할 수 있는 규칙
- 많은 개발자가 참여하는 프로젝트는 이후에 객체 생성과 사용 방법을 변경하기 어렵다. 따라서 추상화 방법을 사용하는 것이 좋다.
- 의존성 주입 프ㄹ임워크를 사용하면, 생성이 얼마나 복잡한지는 신경 쓰지 않아도 된다. 클래스 등은 한 번만 정의하면 되기 때문이다.
- 테스트를 하거나, 다른 애플리케이션을 기반으로 새로운 애플리케이션을 만든다면 추상화를 사용하는 것이 좋다.
- 프로젝트가 작고 실험적이라면, 추상화를 하지 않고도 직접 변경해도 괜찮다. 문제가 발생했다면, 최대한 빨리 직접 변경하면 된다.
API 안정성을 확인하라#
- 프로그래밍에서는 안정적이고 최대한 표준적인 API를 선호한다.
- API가 변경되고, 개발자가 이를 업데이트했다면, 여러 코드를 수동으로 업데이트해야 한다.
- API가 변경되면, 사용자가 새로운 API를 배워야 한다.
- 하지만 좋은 API를 한번에 설계할 수는 없다.
- API가 불안정하다면 이를 명확하게 알려줘야된다.
- 시멘틱 버저닝 사용하기
MAJOR.MINOR.PATCH- MAJOR: 호환되지 않는 수준의 API 변경
- MINOR: 이전 변경과 호환되는 기능을 추가
- PATCH: 간단한 버그 수정
Experimental 메타 어노테이션 사용하여, 해당 요소가 안정적이지 않다는 것을 알려주기- 안정적인 API의 일부를 변경해야 한다면, 전환하는 데 시간을 두고
@Deprecated 어노테이션을 활용해서 사용자에게 미리 알려 주기- 직접적인 대안이 있을 때는
ReplaceWith도 붙여주기 
@Experimental 메타 어노테이션은 Deprecated되어서, @OptIn(ExperimentalContracts:class) 를 사용해야된다.
참고: https://github.com/Junroot/TIL/blob/main/3.Resource/%EA%B0%9C%EB%B0%9C%EC%96%B8%EC%96%B4/Kotlin/Kotlin%20Contracts.md#%EC%8A%A4%EB%A7%88%ED%8A%B8-%EC%BA%90%EC%8A%A4%ED%8A%B8
외부 API를 랩(wrap)해서 사용하라#
- 외부 라이브러리 API를 랩해서 사용하면 다음과 같은 자유와 안정성을 얻는다.
- 문제가 있다면 래퍼만 변경하면 되므로, API 변경에 쉽게 대응할 수 있다.
- 프로젝트의 스타일에 맞춰서 API의 형태를 조정할 수 있다.
- 특정 라이브러리에서 문제가 발생한다면, 래퍼를 수정해서 다른 라이브러리를 사용하도록 코드를 쉽게 변경할 수 있다.
- 필요한 경우 쉽게 동작을 추가하거나 수정할 수 있다.
- 외부 라이브러리 API를 랩 했을 때 단점
- 래퍼를 따로 정의해야 한다.
- 다른 개발자가 프로젝트를 다룰 때, 어떤 래퍼들이 있는지 따로 확인해야 한다.
- 래퍼들은 프로젝트 내부에서만 유효하므로, 문제가 생겨도 질문할 수 없다.
요소의 가시성을 최소화하라#
- 공개적으로 노출되어 있는 요소들은 공개 API의 일부이며, 외부에서 사용할 수 있다.
- 공개적으로 노출되어 있는 요소들을 변경하면, 이 코드를 사용하는 모든 부분이 영향을 받는다.
- 클래스의 상태를 나타내는 프로퍼티를 외부에서 변경할 수 있다면, 클래스는 자신의 상태를 보장할 수 없다.
- 클래스가 만족해야하는 클래스의 상태에 대한 규약 등이 있을 수 있다.
- 클래스의 불변성이 무너질 가능성이 있다.
- 코틀린에서는 구체 접근자의 가시성을 제한해서 모든 프로퍼티를 캡슐화하는 것이 좋다.
가시성 한정자 사용하기#
- 클래스 멤버의 경우 4개의 가시성 한정자
- public(디폴트): 어디에서나 볼 수 있다.
- private: 클래스 내부에서만 볼 수 있다.
- protected: 클래스와 서브 클래스 내부에서만 볼 수 있다.
- internal: 모듈 내부에서만 볼 수 있다.
- 톱레벨 요소에는 세 가지 가시성 한정자를 사용할 수 있다.
- public(디폴트): 어디에서나 볼 수 있다.
- private: 같은 파일 내부에서만 볼 수 있다.
- internal: 모듈 내부에서만 볼 수 있다.
- 모듈의 의미: 함께 컴파일되는 코틀린 소스(그레이들, 메이븐 프로젝트 등)
문서로 규약을 정의하라#
- 이 함수가 무엇을 하는지 명확하게 설명하고 싶다면, KDoc 주석을 붙여 주는 것이 좋다.
- 요소의 규약(contract of an element): 어떤 행위를 설명하면 사용자는 이를 일종의 약속으로 취급하며, 이를 기반으로 스스로 자유롭게 생각하던 예측을 조정한다.
- 규약의 당사자들은 서로 상대방이 규약을 안정적으로 계속 지킬 거라 믿는다.
- 규약이 적절하게 정의되어 있다면, 클래스를 만든 사람은 크래스가 어떻게 사용될지 걱정하지 않아도 된다.
규약 정의하는 방법#
- 이름: 일반적인 개념과 관련된 메서드는 이름만으로도 동작을 예측할 수 있다.
- 주석과 문서: 필요한 모든 규약을적을 수 있는 강력한 방법
- 타입: 자주 사용되는 타입의 경우에는 타입만 보아도 어떻게 사용하는지 알 수 있지만, 일부 타입은 문서에 추가로 설명해야할 의무가 있다.
주석을 써야 할까?#
- 코드만 읽어도 어느 정도 알 수 있는 코드를 만들어야 한다.
- 하지만 주석을 함께 사용하면 요소에 더 많은 규약을 설명할 수 있다.
KDoc 형식#
- Kdoc 주석의 구조
- 첫 번째 부분은 요소에 대한 요약 설명이다.
- 두 번째 부분은 상세 설명이다.
- 이어지는 줄은 모두 태그로 시작한다.. 이러한 태그는 추가적인 설명을 위해 사용된다.
- 사용할 수 있는 태그:
@param <name>, @return, @property <name> 등 - ‘설명’과 ‘태그를 설명하는 텍스트’ 모두 요소, 구체 클래스, 메서드, 프로퍼티, 파라미터를 연결할 수 있다.
- 관련된 요소 등에 링크를 걸 때는 대괄호를 사용한다.
- 만약 링크 대상에 대한 추가 설명을 입력하고 싶을 때는 대괄호를 두 번 연속해서 사용한다.

타입 시스템과 예측#
- 리스코프 치환 원칙: S가 T의 서브타입이라면, 별도의 변경이 없어도 T 타입 객체를 S 타입 객체로 대체할 수 있어야 한다.
- 클래스와 인터페이스에도 여러 가지 예측이 들어간다.
- 클래스가 어떻게 동작할 거라는 예측 자체를 문제가 있으면, 이 클래스와 관련된 다양한 상속 문제가 발생할 수 있다.
- 사용자가 클래스의 동작을 확실하게 예측할 수 있게 하려면, 공개 함수에 대한 규약을 잘 지정해야 한다.
추상화 규약을 지켜라#
- 규약은 개발자들의 단순한 합의이므로 한쪽에서 규약을 위반할 수도 있다.
- 리플렉션을 이용해서 priavte 프로퍼티 값을 변경하는 것은 규약 위반이다.
- private 프로퍼티와 함수의 이름은 언제든 변경될 수 있다.
- 클래스를 상속하거나, 다른 라이브러리의 인터페이스를 구현할 때는 규약을 반드시 지켜야 한다.