카프카 컨슈머: 개념#
컨슈머와 컨슈머 그룹#
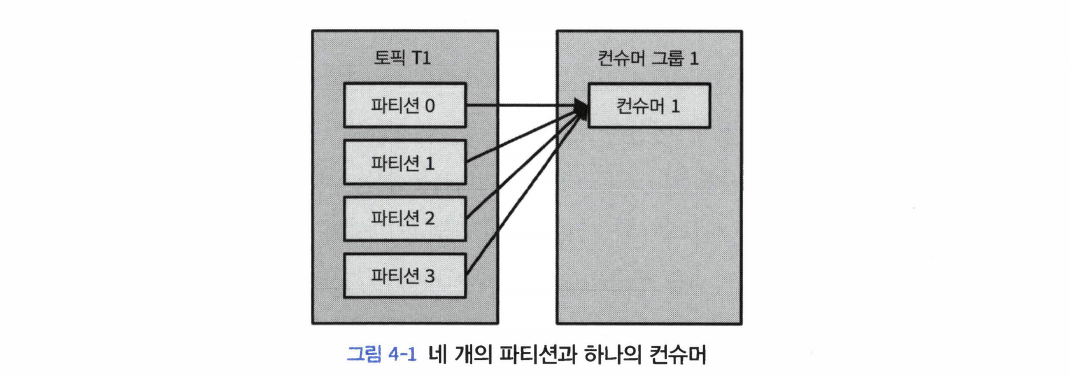
- 카프카 컨슈머는 보통 컨슈머 그룹의 일부로서 작동한다.
- 이유: 우리는 토픽으로부터 데이터를 읽어 오는 작업을 확장할 수 있어야 한다.
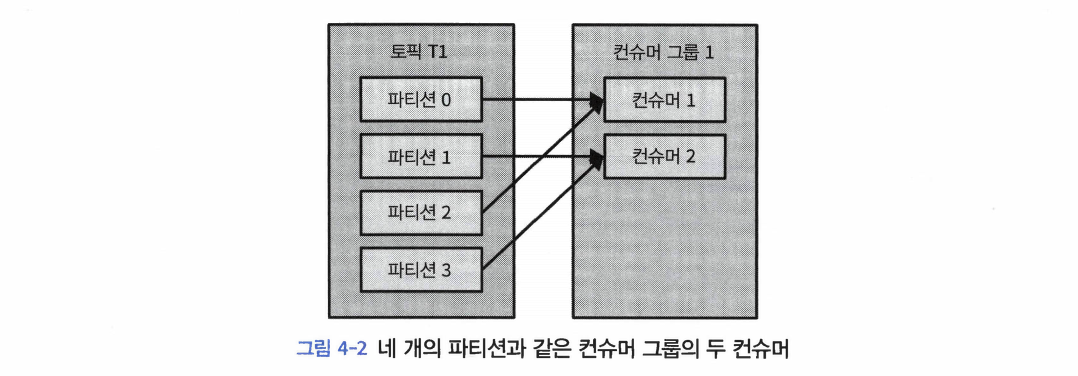
- 동일한 컨슈머 그룹에 속한 여러 개의 컨슈머들이 동일한 토픽을 구독할 경우, 각각의 컨슈머는 해당 토픽에서 서로 다른 파티션의 메시지를 받는 것이다.
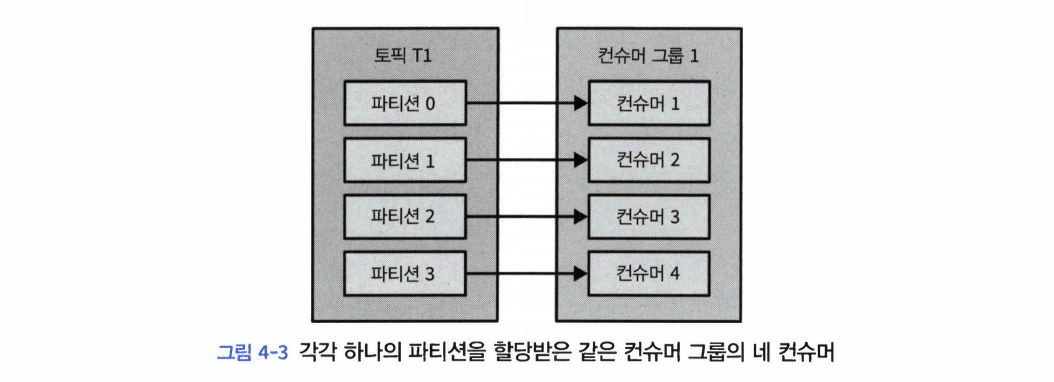
- 컨슈머 그룹에 컨슈머를 추가하는 것은 카프카 토픽에서 읽어오는 데이터 양을 확장하는 주된 방법이다.
- 토픽을 생성할 때 파티션을 크게 잡아주는 게 좋은 이유: 부하가 증가함에 따라서 더 많은 컨슈머를 추가할 수 있게 해주기 때문
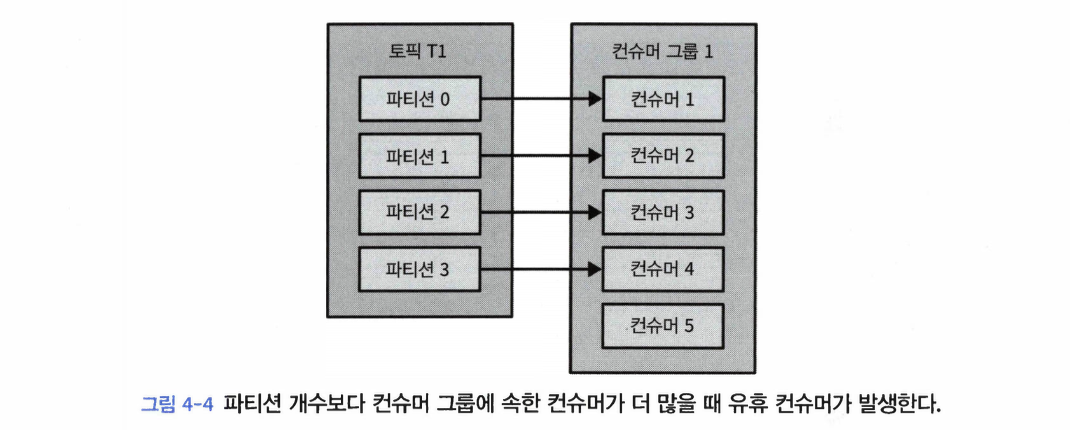
- 토픽에 설정된 파티션 수 이상으로 컨슈머를 투입하는 것은 아무 의미가 없는 점도 명심하라
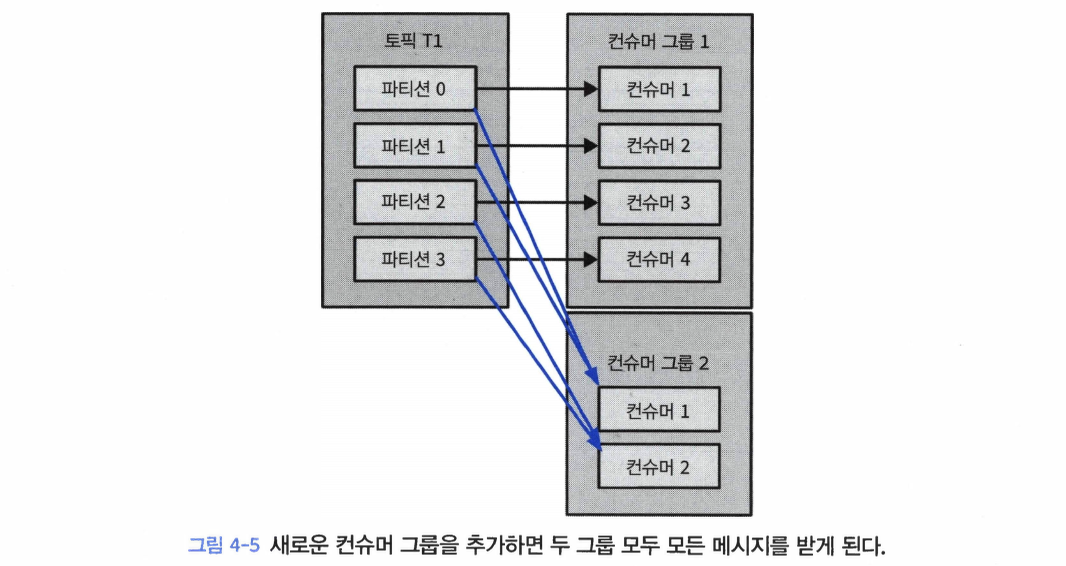
- 새로운 컨슈머 그룹, G2를 추가하게 된다면 이 컨슈머는 G1 컨슈머 그룹에서 무엇을 하고 있든지 상관없이 T1 토픽의 모든 메시지를 받게 된다.
컨슈머 그룹과 파티션 리밸런스#
- 리밸런스: 컨슈머에 할당된 파티션을 다른 컨슈머에게 할당해주는 작업
- 리밸런스가 발생하는 상황
- 새로운 컨슈머가 컨슈머 그룹에 추가
- 컨슈머가 종료되거나 크래시가 난 경우
- 컨슈머 그룹이 읽고 있는 토픽이 변경 되었을 때 (예를 들어, 운영자가 토픽에 새 파티션을 추가했을 경우)
- 리밸런스에는 컨슈머 그룹이 사용하는 파티션 할당 전략에 따라 2가지가 있다.
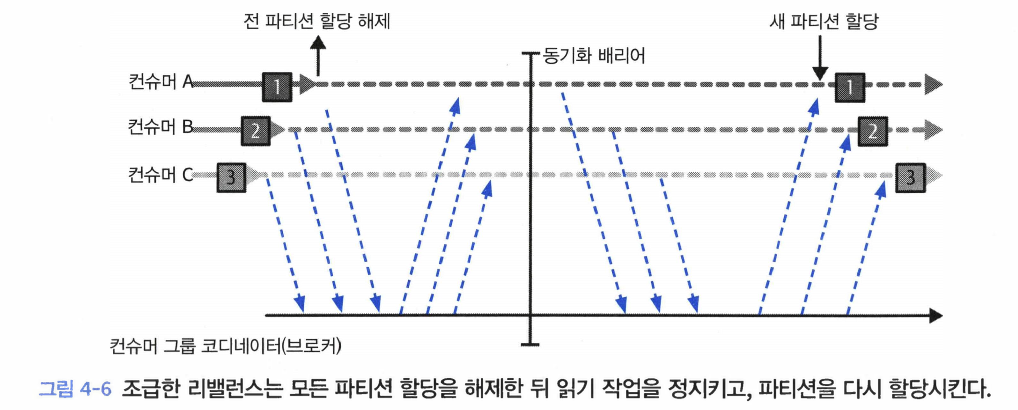
- 조급한 리밸런스(eager rebalance)
- 실행되는 와중에 모든 컨슈머는 읽기 작업을 멈추고 자신에게 할당된 모든 파티션에 대한 소유권을 포기한 뒤, 컨슈머 그룹에 다시 참여하여 완전히 새로운 파티션 할당을 전달받는다.
- 이러한 방식은 근본적으로 전체 컨슈머 그룹에 대해 짧은 시간 동안 작업을 멈추게한다.
- 협력적 리밸런스(cooperative rebalnce)
- 한 컨슈머에게 할당되어 있던 파티션만을 다른 컨슈머에 재할당한다.
- 리밸런싱이 2개 이상의 단계에 걸쳐서 수행된다.
- 우선 컨슈머 그룹 리더가 다른 컨슈머들에게 각자에게 할당된 파티션 중 일부가 재할당될 것이라고 통보하면, 컨슈머들은 해당 파티션에서 데이터를 읽어오는 작업을 멈추고 해당 파티션에 대한 소유권을 포기한다.
- 컨슈머 그룹 리더가 이 포기된 파티션을 새로 할당한다.
- 재할당되지 않은 파티션에서 레코드를 읽어서 처리하던 컨슈머들은 작업에 방해받지 않고 하던 읽을 계속할 수 있을 것이다.
- 컨슈머가 소유권을 유지하는 방식
- 해당 컨슈머 그룹의 그룹 코디네이터(group coordinator) 역할을 지정받은 카프카 브로커에 하트비트를 전송한다.
- 하트비트는 컨슈머의 백그라운드 스레드에 의해 전송되며, 일정한 간격을 두고 전송되는한 연결이 유지되고 있는 것으로 간주한다.
- 만약 컨슈머가 일정 시간 하트비트를 전송하지 않는다면, 세션 타임아웃이 발생하면서 그룹 코디네이터는 해당 컨슈머가 죽었다고 간주하고 리밸런스를 실행한다. 이 몇 초 동안 죽은 컨슈머에 할당되어 있던 파티션은 아무 메시지도 처리되지 않는다.
- 컨슈머를 깔끔하게 닫아줄 경우 컨슈머는 그룹 코디네이터에게 그룹을 나간다고 통지하는데, 그러면 그룹 코디네이터는 즉시 리밸런스를 실행함으로써 처리가 정지되는 시간을 줄인다.
- 파티션은 어떻게 컨슈머에게 할당되는가?
- 컨슈머가 그룹에 참여하고 싶을 때는 그룹 코디네이터에게
JoinGroup 요청을 보낸다. - 가장 먼저 그럽에 참여한 컨슈머가 그럽 리더가 된다.
- 리더는 그룹 코디네이터로부터 해당 그룹 안에 있는 모든 컨슈머의 목록을 받아서 각 컨슈머에게 파티션의 일부를 할당해 준다.
- 카프카에는 몇 개의 파티션 할당 정책이 기본적으로 내장되어 있다.
- 컨슈머 그룹 리더는 파티션 할당이 결정되면 할당 내역을 그룹 코디네이터에게 전달하고, 그룹 코디네이터는 다시 이 정보를 모든 컨슈머에게 전파한다.
- 각 컨슈머 입장에서는 자기에게 할당된 내역만 보인다.
- 리더만 클라이언트 프로세스 중 유일하게 그룹 내 켠슈머와할당 내역을 전부 볼 수 있다.
- 카프카 2.4이후로 조급한 리밸런스가 기본값이었지만, 3.1부터는 협력적 리밸런스가 기본값이 되었다.
정적 그룹 멤버십#
- 기본적으로, 컨슈머가 갖는 컨슈머 그룹의 멤버십은 일시적이다.
- 컨슈머에
group.instance.id 값을 잡아주면 컨슈머 그룹의 정적인 멤버가 되도록 해준다.- 컨슈머가 정적 멤버로서 컨슈머 그룹에 처음 참여하면 평소와 같이 해당 그룹이 사용하고 있느 파티션 할당 전략에 따라 파티션이 할당된다.
- 하지만 이 컨슈머가 꺼질 경우, 자동으로 그럽을 떠나지 않는다.
- 그리고 컨슈머가 다시 그룹에 조인하면 멤버십이 그대로 유지되기 때문에 리밸런스가 발생할 필요 없이 예전에 할당받았던 파티션들을 그대로 재할당받는다.
- 그룹 코디네이터는 그룹 내 각 멤버에 대한 파티션 할당을 캐시해 두고 있기 때문에 정적 멤버가 다시 조인해 들어온다고 해서 리밸런스를 발생시키지는 않는다.
- 만약 같은
group.instance.id 값을 갖는 두 개의 컨슈머가 같은 그룹에 조인할 경우 에러가 발생할 것이다. - 정적 그룹 멤버십이 편리한 케이스: 각 컨슈머에 할당된 파티션의 내용물을 사용해서 로컬 상태나 캐시를 유지해야 할 때
- 반대로 생각하면, 각 컨슈머에 할당된 파티션들이 해당 컨슈머가 재시작한다고 해서 다른 컨슈머로 재할당되지 않는다.
- 컨슈머를 잃어버린 파티션들로부터 메시지를 읽어오지 않을 것이기 떄문에 정지되었던 컨슈머가 다시 돌아오면 이 파티션에 저장된 최신 메시지에서 한참 뒤에 있는 밀린 메시지부터 처리하게 된다.
- 컨슈머 그룹의 정적 멤버는 종료할 때 미리 컨슈머 그룹을 떠나지 않고,
session.timeout.ms 설정에 따라 컨슈머 그룹을 떠나게 된다.
카프카 컨슈머 생성하기#

bootstrap.servers: 카프카 클러스터로의 연결 문자열key.deserializer, value.deserializer: 프로듀서에서 시리얼라이저와 비슷한 역할의 역직렬화 클래스group.id: KafkaConsumer 인스턴스가 속하는 컨슈머 그룹
토픽 구독하기#
subscribe() 메서드로 컨슈머가 1개 이상의 토픽을 구독할 수 있다.- 정규식을 매개변수로 사용해서
subscribe를 호출하는 것이 가능하다.- 정규식은 다수의 토픽 이름에 매치될 수도 있으며, 만약 누군가가 정규식과 매치되는 이름을 가진 새로운 토픽을 생성할경우, 거의 즉시 리밸런스가 발생하면서 컨슈머들은 새로운 토픽으로부터 읽기 작업을 시작하게 된다.
- 정규식을 사용해서 다수의 토픽을 구독하는 것은 카프카와 다른 시스템 사이에 데이터를 복제하는 애플리케이션이나 스트림 처리 애플리케이션에서 매우 흔하게 사용되는 기법이다.
폴링 루프#

- 우리가
poll()에 전달하는 매개변수는 컨슈머 버퍼에 데이터가 없을 경우 poll()이 블록될 수 있는 최대 시간을 결정한다.- 만약 이 값이 0으로 지정되거나 버퍼 안에 이미 레코드가 준비되어 있을 경우 즉시 리턴된다. 그게 아닐 경우 지정된 밀리초만큼 기다린다.
- 새 컨슈머에 처음으로
poll()을 호출하면 컨슈머는 GroupCoordinator를 찾아서 컨슈머 그룹에 참가하고, 파티션을 할당받는다. 리밸런스 역시 연관된 콜백들과 함께 여기서 처리된다. poll()이 max.poll.internval.ms에 지정된 시간 이상으로 호출되지 않을 경우, 컨슈머는 죽은 것으로 판정되어 컨슈머 그룹에서 퇴출된다.- 따라서 폴링 루프 안에 예측 불가능한 시간 동안 블록되는 작업을 수행하는 것은 피해야 한다.
스레드 안정성#
- 하나의 스레드에서 동일한 그룹 내에 여러 개의 컨슈머를 생성할 수는 없으며, 같은 컨슈머를 다수의 스레드가 안전하게 사용할 수도 없다.
- 컨슈머 로직을 자체적인 객체로 감싼 다음 자바의
ExecutorService를 사용해서 각자의 컨슈머를 가지는 다수의 스레드를 시작시키면 좋다. - 또 달느 방법으로는 이벤트를 받아서 큐에 넣는 컨슈머 하나와 이 큐에서 이벤트를 꺼내서 처리하는 여러 개의 워커 스레드를 사용하는 것이다.
컨슈머 설정하기#
fetch.min.bytes#
- 컨슈머가 브로커로부터 레코드를 얻어올 때 받는 데이터의 최소량(바이트)를 지정할 수 있다.
- 기본값은 1바이트
- 만약 읽어올 데이터가 그리 많지 않을 때 컨슈머가 CPU 자원을 너무 많이 사용하고 있거나 컨슈머 수가 많을 때 브로커의 부하를 줄여야 할 경우 이 값을 기본값보다 더 올려잡아 주는 게 좋다.
- 이 값을 증가시킬 경우 처리량이 적은 상황에서 지연 증가할 수 있다.
fetch.max.wait.ms#
- 컨슈머가 레코드를 얻어올 때 까지 얼마나 오래 기다릴 것인지를 결정한다.
- 기본값은 500밀리초
fetch.min.bytes와 fetch.max.wait.ms 두 조건 중 하나가 만족되는 대로 리턴하게 된다.
fetch.max.bytes#
- 컨슈머가 브로커를 폴링할 때 카프카가 리턴하는 최대 바이트 수를 지정한다.
- 기본값은 50MB
- 컨슈머가 서버로부터 받은 데이터를 저장하기 위해 사용하는 메모리의 양을 제한하기위해 사용한다.
max.poll.records#
poll()을 호출할 때마다 리턴되는 최대 레코드 수를 지정한다.- 애플리케이션이 폴링 루프를 반복할 때마다 처리해야 하는 레코드의 개수를 제어하려면 이 설정을 사용하면 된다.
max.partition.fetch.bytes#
- 서버가 파티션별로 리턴하는 최대 바이트 수를 결정한다.
- 브로커가 보내온 응답에 얼마나 많은 파티션이 포함되어 있는지 결정할 수 있는 방법이 없기 떄문에 이 설정을 사용해서 메모리 사용량을 조절하는 것은 꽤 복잡하다.
- 따라서, 특별한 이유가 아닌한
fetch.max.bytes 설정을 대신 사용하는 것을 강력히 권장한다.
session.timeout.ms 그리고 heartbeat.interval.ms#
session.timeout.ms: 컨슈머가 브로커와 신호를 주고받지 않고도 살 있는 것으로 판정되는 최대 시간(기본값 10초)- 컨슈머가 그룹 코디네이터에게 하트비트를 보내지 않고
session.timeout.ms가 지나면 해당 컨슈머를 죽은 것으로 간주하고, 죽은 컨슈머에게 할당되어 있던 파티션들은 다른 컨슈머에게 할당해주기 위해 리밸런싱을 실행시킨다.
heartbeat.interval.ms: 컨슈머가 얼마나 자주 하트비트를 보내는지 결정하는 시간heartbeat.interval.ms는 session.timeout.ms보다 더 낮은값이어야 하며 대체로 1/3으로 결정하는 것이 보통이다.
- 버전 3.0부터는
session.timeout.ms 기본값이 45초 바뀌었다.- 결과적으로 앞에서 이야기한 ‘heartbeat.interval.ms는 session.timeout.ms의 1/3으로 설정한다.‘는 규칙이 기본값 기준으로 더이상 유효하지 않다. 하지만 성급하게 바꾸지는 말자.
max.poll.interval.ms#
- 컨슈머가 폴링을 하지 않고도 죽은 것으로 판정되지 않을 수 있는 최대 시간
- 하트비트는 백그라운드 스레드에 의해 전송된다. 따라서, 카프카에서 레코드를 읽어오는 메인 스레드는 데드락이 걸렸는데 백그라운드 스레드는 멀쩡히 하트비트를 전송하고 있을 수도 있다.
- 이 값은 작동 중인 컨슈머가 매우 드물게 도달할 수 있도록 충분히 크게, 하지만 정지한 컨슈머로 인한 영향이 뚜렷이 보이지 않을 만큼 충분히 작게 설정되어야 한다.
default.api.timeout.ms#
- API를 호출할 때 명시적인 타임아웃을 지정하지 않는 한, 거의 모든 컨슈머 API 호출에 적용되는 타임아웃 값
- 기본값은 1분
- 이 값이 적용되지 않는 중요한 예외로는
poll() 메서드가 있다.- 즉, 이 메서드를 호출할 때는 언제나 명시적으로 타임아웃을 지정해 줘야 한다.
request.timeout.ms#
- 컨슈머가 브로커로부터 응답을 기다릴 수 있는 최대 시간
- 만약 브로커가 이 설정에 지정된 시간 사이에 응답하지 않을 경우, 클라이언트는 브로커가 완전히 응답하지 않을 것이라고 간주하고 연결을 닫은 뒤 재연결을 시도한다.
- 기본값은 30초인데, 더 내리지 않는 걸 권장한다.
default.api.timeout.ms > request.timeout.ms- 예: request.timeout.ms=10s, default.api.timeout.ms=60s
- 개별 요청은 10초 안에 응답이 와야 하지만, 전체 API는 내부적으로 여러 요청을 반복하거나 재시도하면서 최대 60초까지 기다릴 수 있다.
auto.offset.reset#
- 컨슈머가 예전에 오프셋을 커밋한 적이 없거나, 커밋된 오프셋이 유효하지 않을 때 파티션이 읽기 시작할 때의 작동을 정의한다.
- 대개 컨슈머가 오랫동안 읽은 적이 없어서 오프셋의 레코드가 이미 브로커에게 삭제도니 경우다.
- 기본값은 latest
- latest: 가장 최신 레코드부터 읽기 시작한다.
- earliest: 파티션의 맨 처음부터 모든 데이터를 읽는 방식이다.
- none: 예외가 발생한다.
enable.auto.commit#
- 컨슈머가 자동으로 오프셋을 커밋할지 여부를 결정한다.
- 기본값은 true
- 언제 오프셋을 커밋할지 직접 결정하고 싶다면, 이 값을 false로 놓으면 된다.
- 만약 이 값을 true로 놓을 경우,
auto.commit.interval.ms를 사용해서 얼마나 자주 오프셋이 커밋될지를 제어할 수 있따.
partition.assignmnet.strategy#
PartitionAssignor 클래스는 컨슈머와 이들이 구독한 토픽이 주어졌을 때 어느 컨슈머에게 어느 파티션이 할당될지를 결정하는 역할을 한다.- 전략 종류
- Range: 컨슈머가 구독하는 각 토픽의 파티션들을 연속된 그룹으로 나눠서 할당한다.
- 예: 컨슈머 C1, C1가 각각 3개의 파티션을 갖는 토픽 T1, T2를 구독했을 경우
- C1: T1(0, 1번 파티션), T2(0, 1번 파티션)
- C2: T1(2번 파티션), T2(2번 파티션)
- RoundRobin: 모든 구독된 토픽의 모든 파티션을 가져다 순차적으로 하나씩 컨슈머에 할당해 준다.
- 예:
- C1: T1(0, 2번 파티션), T2(1번 파티션)
- C2: T1(1번 파티션), T2(0, 2번 파티션)
- Sticky: 2개의 목표를 가지고 있다.
- 파티션들을 가능한 한 균등하게 할당한다.
- 리밸런스가 발생했을 때 가능하면 많은 파티션들이 같은 컨슈머에 할당되게 함으로써 할당된 파티션을 하나의 컨슈머에서 다른 컨슈머로 옮길 때 발생하는 오버헤드를 최대한 간소화하는 것이다.
- Cooperative Sticky: Sticky 할당자와 기본적으로 동일하지만, 컨슈머가 재할당되지 않은 파티션으로부터 레코드를 계속해서 읽어 올 수 있도록 해주는 협력적 리밸런스 기능을 지원한다.
- 기본값은 Range 전략을 구현하는
org.apache.kafka.clients.consumer.RangeAssignor 이다.
client.id#
- 어떠한 문자열도 될 수 있으며, 브로커가 요청을 보낸 클라이언트를 식별하는 데 쓰인다.
- 로깅, 모니터링 지표, 쿼터에서도 사용된다.
client.rack#
- 기본적으로 컨슈머는 각 파티션의 리더 레플리카로부터 메시지를 읽어 온다.
- 하지만 클러스터가 다수의 데이터센터 혹은 다수의 클라우드 가용 영역에 걸쳐 설치되어 있는 경우 컨슈머와 같은 영역에 있는 레플리카로부터 메시지를 읽어 오는 것이 성능 면에서나 비용 면에서나 유리하다.
- 가장 가까운 레플리카로부터 읽어올 수 있게 하려면
client.rack 설정을 잡아 줌으로써 클라이언트가 위치한 영역을 식별할 수 있게 해줘야 한다.- 그러고 나서 브로커의
replica.selector.class 설정 기본값을 orgapache.kafka.common.replica.RackAwareReplicaSelector로 잡아주면 된다.
group.instance.id#
- 컨슈머에 정적 그룹 멤버십 기능을 적용하기 위해 사용되는 설정으로, 어떤 고유한 문자열도 사용이 가능하다.
receive.buffer.bytes, send.buffer.bytes#
- 데이터를 읽거나 쓸 때 소켓이 사용하는 TCP의 수신 및 수신 버퍼의 크기를 가리킨다.
- -1로 잡아 주면 운영체제 기본값이 사용된다.
- 다른 데이터센터에 있는 브로커와 통신하는 프로듀서나 컨슈머의 경우 이 값을 올려잡아 주는 게 좋다.
- 대체로 이러한 네트워크 회선은 지연은 크고 대역폭은 낮기 때문이다.
offsets.retention.minutes#
- 브로커 설정이지만, 컨슈머 작동에 큰 영향을 미치는 설정이다.
- 컨슈머 그룹에 컨슈머가 비게 된다면 카프카는 커밋된 오프셋을 이 설정값에 지정된 기간 동안만 보관한다.
- 기본값은 7일
오프셋과 커밋#
- 오프셋 커밋: 카프카에서는 파티션에서의 현재 위치를 업데이트하는 작업
- 전통적인 메시지 큐와 다르게, 카프카는 레코드를 개별적으로 커밋하지 않는다.
- 대신, 컨슈머는 파티션에서 성공적으로 처리해 낸 마지막 메시지를 커밋함으로써 그 앞의 모든 메시지들이 역시 성공적으로 처리되었음을 암묵적으로 나타낸다.
- 카프카에 특수 토픽인
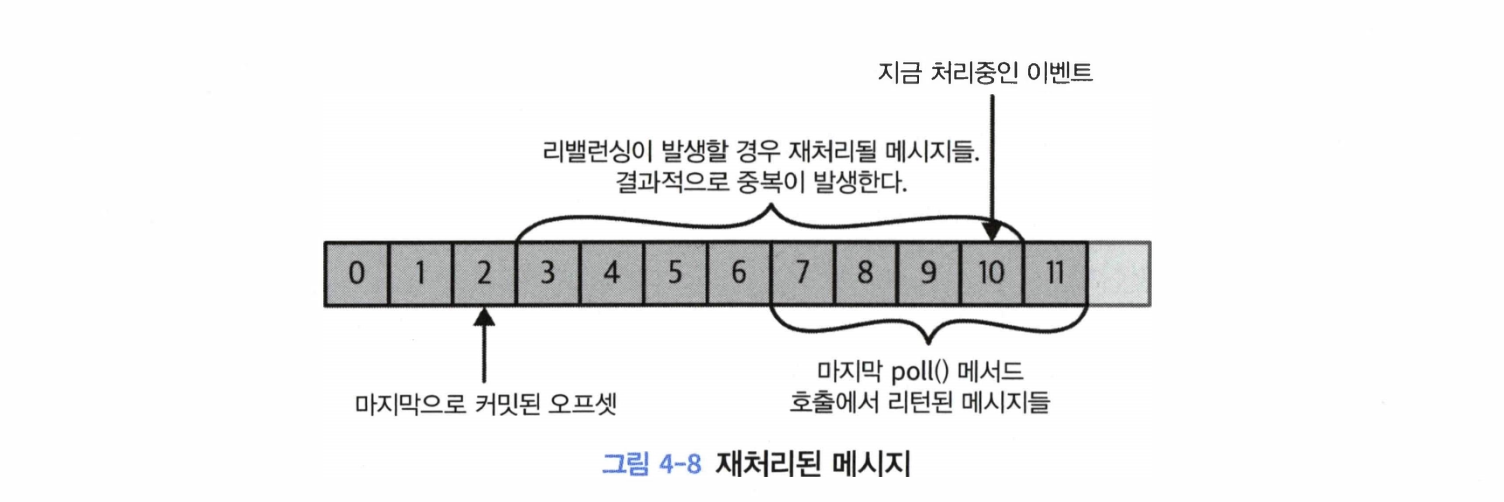
__consumer_offsets 토픽에 각각 파티션별로 커밋된 오프셋을 업데이트하도록 하는 메시지를 보냄으로써 이루어진다. - 리밸런싱이 이루어질 때, 커밋된 오프셋이 이전 클라이언트가 처리한 마지막 메시지의 오프셋보다 작을 경우 마지막으로 처리된 오프셋과 커밋된 오프셋 사이의 메시지들은 두 번 처리되게 된다.
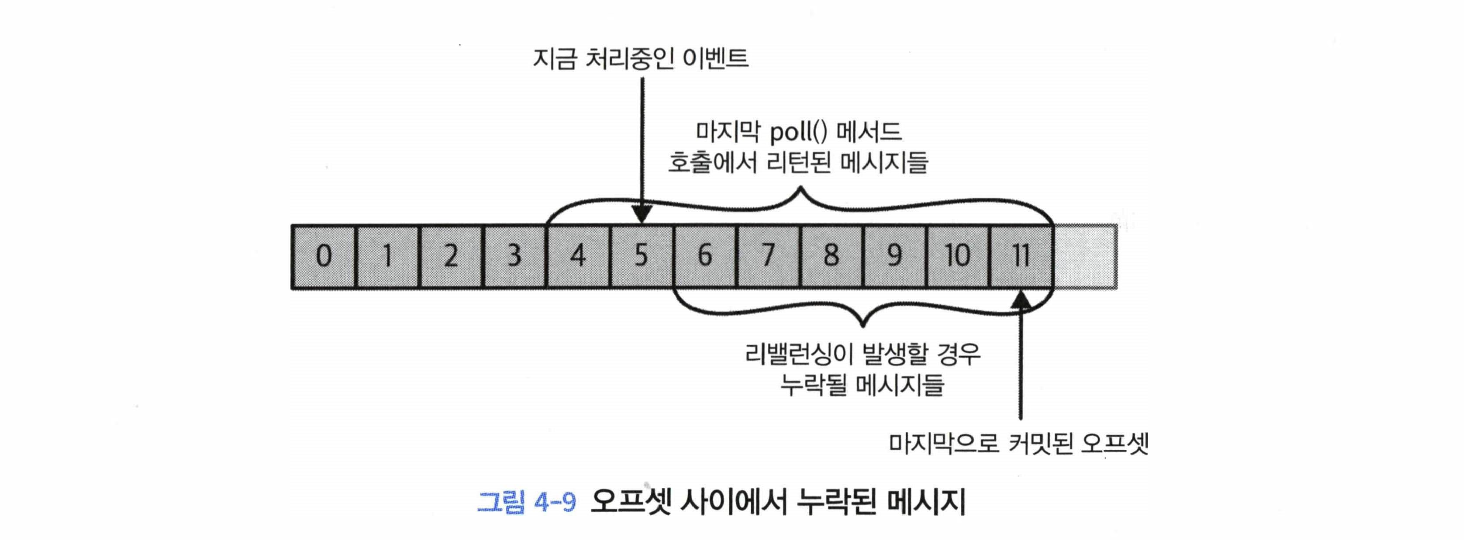
- 커밋된 메시지가 클라이언트가 실제로 처리한 마지막 메시지의 오프셋보다 클 경우, 마지막으로 처리된 오프셋과 커밋된 오프셋 사이의 모든 메시지들은 컨슈머 그룹에서 누락되게 된다.
poll() 이 리턴한 마지막 오프셋 바로 오프셋을 커밋하는 것이 기본적인 작동이다.
자동 커밋#
enable.auto.commit 설정을 true로 잡아주면 컨슈머는 auto.commit.interval.ms에 한 번, poll()을 통해 받은 메시지 중 마지막 메시지의 오프셋을 커밋한다.auto.commit.interval.ms의 기본값은 5초
- 자동 커밋은 폴링 루프에 의해서 실행된다.
poll() 메서드를 실행할 때마다 컨슈머는 커밋해야 하는지를 확인한 뒤 그럴 경우에는 마지막 poll() 호출에서 리턴된 오프셋을 커밋한다.
- 자동 커밋은 중복 메시지를 방지하기엔 충분하지 않다.
- 마지막으로 커밋한지 3초 뒤에 컨슈머가 크래시되었다고 해 보자. 리밸런싱이 완료된 뒤부터 남은 컨슈머들은 크래시된 컨슈머가 읽고 있던 파티션들을 이어받아서 읽기 시작한다.
- 이 경우 커밋되어 있는 오프셋은 3초 전의 것이기 때문에 크래시되기 3초 전까지 읽혔던 이벤트들은 두 번 처리되게 된다.
현재 오프셋 커밋하기#
enable.auto.commit=false로 설정해 줌으로써 애플리케이션이 명시적으로 커밋하려 할 때만 오프셋이 커밋되게 할 수 있다.- 가장 간단하고 또 신뢰성 있는 커밋 API는
commitSync()이다. - 이 API는
poll()이 리턴한 마지막 오프셋을 커밋한 뒤 커밋이 성공적으로 안료되면 리턴, 어떠한 이유로 실패하면 예외를 발생시킨다. - 만약
poll()에서 리턴된 모든 레코드의 처리가 완료되기 전 commitSync()를 호출하게 될 경우 애플리케이션이 크래시되었을 때 커밋은 되었지만 아직 처리되지 않은 메시지들이 누락될 위험을 감수해야 할 것이다. - 만약 애플리케이션이 아직 레코드들은 처리하는 와중에 크래시가 날 경우, 마지막 메시지 배치의 맨 앞 레코드에서부터 리밸런스 시작 시점까지 모든 레코드들은 두 번 처리될 것이다.
- 해결할 수 없는 에러가 발생하지 않는 한,
commitSync는 커밋을 재시도한다.
비동기적 커밋#
- 수동 커밋의 단점 중 하나는 브로커가 커밋 요청에 응답할 때까지 애플리케이션이 블록된다는 점이다.
- 비동기적 커밋 API를 사용하여, 브로커가 커밋에 응답할 때까지 기다리는 대신 요청만 보내고 처리를 계속한다.
- 이 방식의 단점은
commitSync()가 성공하거나 재시도 불가능한 실패가 발생할 때까지 재시도하는 반면, commitAsync()는 재시도를 하지 않는다는 점이다. commitAsync() 에는 브로커가 보낸 응답을 받았을 때 호출되는 콜백을 지정할 수 있다.- 순차적으로 단조증가하는 번호를 사용하면 비동기적 커밋을 재시도할 때 순서를 맞출 수 있다. 커밋할 때마다 번호를 1씩 증가한 뒤
commitAsync 콜백에 해당 번호를 넣어 준다. - 그리고 재시도 요청을 보낼 준비가 되었을 때 콜백에 주어진 번호와 현재 번호를 비교해주는 것이다.
- 만약 콜백에 주어진 번호가 더 크다면 새로운 커밋이 없었다는 의미이므로 재시도를 해도된다.
- 콜백에 주어진 번호가 더 작다면 새로운 커밋이 있었다는 의미이므로 재시도하면 안 된다.
동기적 커밋과 비동기적 커밋을 함께 사용하기#
- 재시도 없는 커밋이 실패한다고 해도 뒤이은 커밋이 성공할 것이기 때문에 문제가 되지 않는다.
- 하지만 이것은 컨슈머를 닫기 전 혹은 리밸런스 전 마지막 커밋이라면, 성공 여부를 추가로 확인할 필요가 있을 것이다.
- 이 경우, 일반적인 패턴은 종료 직전에
commitAsync()와 commitSync()를 함꼐 사용하는 것이다. 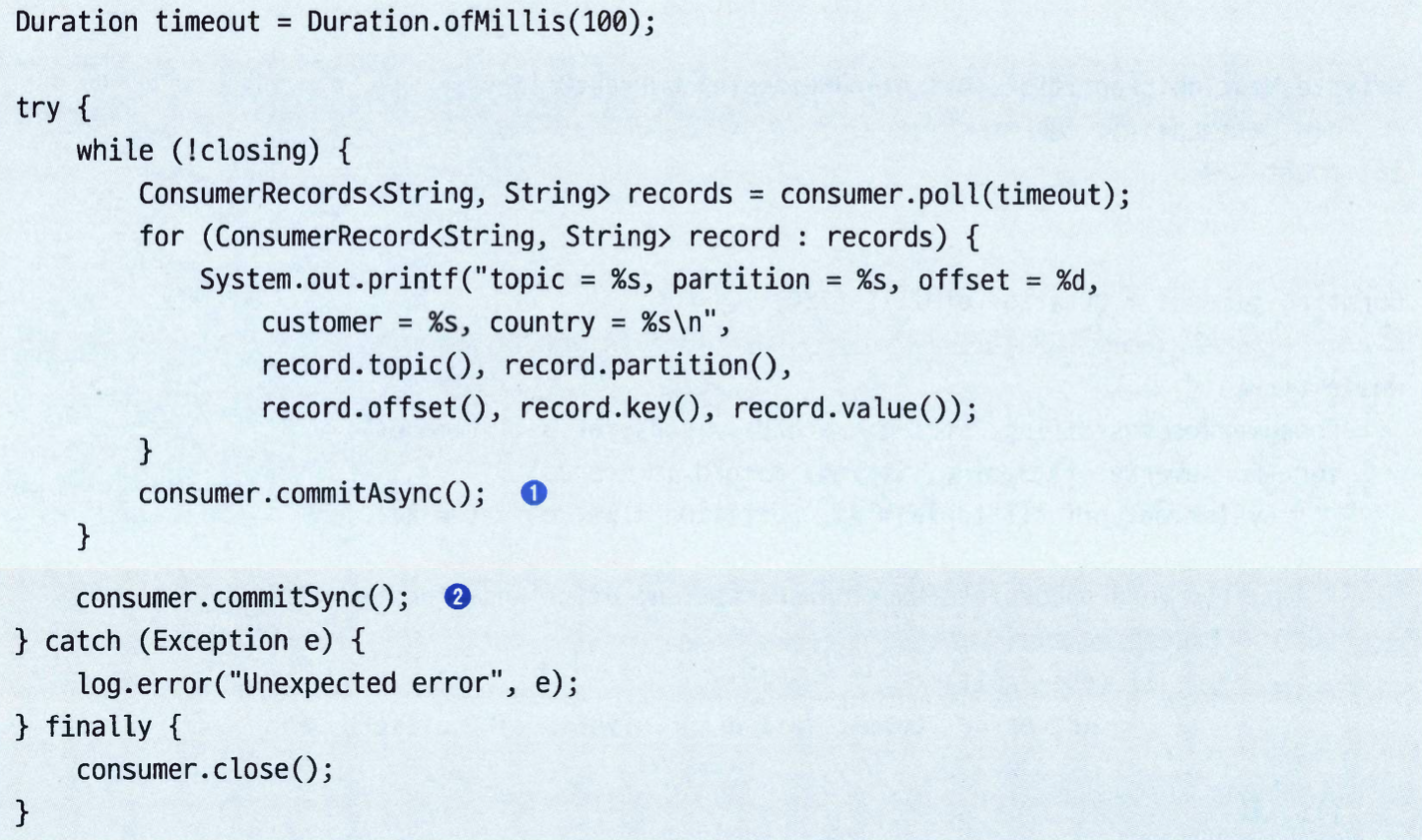
특정 오프셋 커밋하기#
poll()이 엄청나게 큰 배치를 리턴했는데, 리밸런스가 발생했을 경우 전체 배치를 재처리하는 상황을 피하기 위해서 특정 오프셋을 커밋할 수 있다.commitSync()나 commitAsync()를 호출할 때 커밋하고자 하는 파티션과 오프셋의 맵을 전달할 수 있다.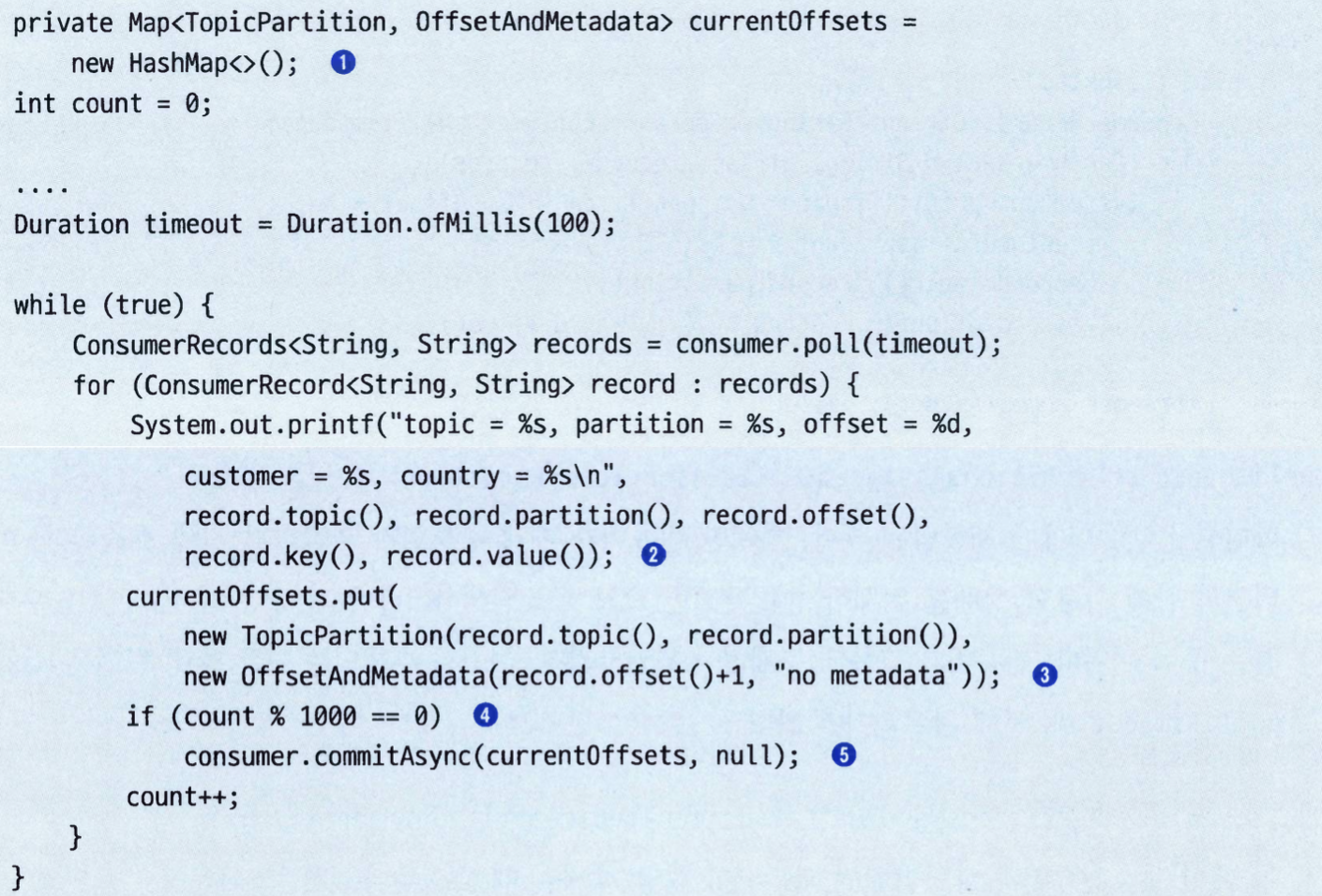
리밸런스 리스너#
- 컨슈머 API는 컨슈머에 파티션이 할당되거나 해제될 때 사용자의 코드가 실행되도록 하는 메커니즘을 제공한다.
subscribe()를 호출할 때 ConsumerRebalnaceListener를 전달해주면 된다.
ConsumerRebalanceListener 에는 3개의 메서드를 구현할 수 있다.public void onPartitionsAssigned(Collection<TopicPartition> partitions)- 타이밍: 파티션이 컨슈머에게 재할당된 후, 하지만 컨슈머가 메시지를 읽기 시작하기 전에 호출
- 대상: 재할당 받은 컨슈머
- 컨슈머가 그룹에 문제없이 조인하려면, 여기서 수행되는 모든 준비 작업은
max.poll.timeout.ms 안에 완료되어야 한다.
public void onPartitionsRevoked(Collection<TopicPartition> partitions)- 타이밍: 컨슈머가 할당받았던 파티션이 할당 해제될 때 호출(리밸런스 때문일 수도 있고, 컨슈머가 닫혀서 그럴 수도 있다)
- 조급한 리밸런스 알고리즘인 경우: 컨슈머가 메시지 읽기를 멈춘 뒤에, 리밸런스가 시작되기 전에 호출
- 협력적 리밸런스 알고리즘인 경우: 리밸런스가 완료되고, 컨슈머에서 할당 해제되기 전에 호출
- 대상:
- 조급한 리밸런스 알고리즘: 모든 컨슈머
- 협력적 리밸런스 알고리즘: 할당해제되어야 할 파티션이 있는 컨슈머
- 여기서 오프셋을 커밋해주어야 이 파티션을 다음에 할당받는 컨슈머가 시작할 지점을 알아낼 수 있다.
public void onParitionsLost(Collection<TopicPartition> partitions)- 타이밍: 협력적 리밸런스 알고리즘이 사용되었을 경우, 할당된 파티션이 리밸런스 알고리즘에 의해 해제되기 전에 다른 컨슈머에서 먼저 할당된 예외적인 상황에서만 호출된다. (세션 타임아웃 등)
- 대상: 할당 해제가 되어야 하는 파티션이 있는 컨슈머
- 여기서 파티션과 함께 사용되었던 상태나 자원들을 정리해줘야 한다.
- 파티션을 새로 할당받은 컨슈머가 이미 상태를 저장했을 수도 있기 때문에 충돌은 피해야한다.
특정 오프셋의 레코드 읽어오기#
- 컨슈머가 특정 오프셋에서부터 읽기를 시작하고 싶은 경우가 있다.
seekTobeginning(Collection<TopicPartition> tp): 파티션의 맨 앞에서부터 모든 메시지를 읽고자 한다.seekToEnd(Collection<TopicPartition> tp): 앞의 메시지를 전부 건너 뛰고 파티션에 새로 들어온 메시지부터 읽고자 한다.offsetsForTimes(Map<TopicPartition, Long> timestampsToSearch): 각 파티션에 대해서 타임스탬프 이후로 생성된 오프셋을 리턴한다.seek(TopicPartition partition, long offset): 해당 파티션의 오프셋을 재설정한다.
폴링 루프를 벗어나는 방법#
- 컨슈머를 종료하고자 할 때, 컨슈머가
poll()을 오래동안 기다리고 있더라도 즉시 루프를 탈출하고 싶다면 다른 스레드에서 consumer.wakeup()을 호출해주어야 한다.wakeup()은 다른 스레드에서 호출해 줄 때만 안전하게 작동한다.
- 만약 폴링 루프가 충분히 짧다면 굳이 wakeup을 호출해줄 필요가 없고, 아토믹 boolean 값을 확인하는 것만으로 충분한다.
- 다른 스레드에서 wakeup을 호출할 경우, 폴링 루프에서
WakeupException가 발생한다. 발생된 예외를 잡아줌으로써 애플리케이션에서 예기치 않게 종료되지 않도록 할 수 있지만, 딱히 뭔가를 추가로 해줄 필요는 없다. - 컨슈머를 종료하기 전에
consumer를 닫아서 리소스를 정리해 준다. 
디시리얼라이저#
- 카프카 컨슈머는 카프카로부터 받은 바이트 배열을 자바 객체로 변환하기 위해 디시리얼라이저가 필요하다.
- 어차피 시리얼라이저와 디시리얼라이저는 함께 쓰일 수밖에 없는 만큼 같은 데이터 타입을 묶어 놓은 클래스도 있는데,
Serdes 클래스가 바로 그것이다. - 카프카 3.0부터
List<T> 타입의 객체를 (디)시리얼라이즈할 수 있는 기능이 기본적으로 탑재되었다. 다음은 키값에 대한 시리얼라이저를 설정하는 예제다.
독립 실행 컨슈머: 컨슈머 그룹 없이 컨슈머를 사용해야 하는 이유와 방법#
- 하나의 컨슈머가 토픽의 모든 파티션으로 부터 모든 데이터를 읽어와야 하거나, 토픽의 특정 파티션으로부터 데이터를 읽어와야 할 때가 있다.
- 이러한 경우 컨슈머 그룹이나 리밸런스 기능이 필요하지는 않다.
- 그냥 컨슈머에게 특정한 토픽과 파티션을 할당해주고, 메시지를 읽어서 처리하고, 필요할 경우 오프셋을 커밋하면 된다.
- 카프카 클러스터에 해당 토픽에 대해 사용 가능한 파티션들을 요청한다. 만약 특정 파티션의 레코드만 읽어 올 생각이라면 이 부분은 건너뛸 수 있다.
- 읽고자하는 파티션을 알았다면 해당 목록에 대해 assign()을 호출해준다.
assign으로 파티션을 직접 할당하면, 더 이상 그룹 코디네이터에 참여하지 않고 리밸런싱이 동작하지 않는다.subscribe() -> 그룹 관리, assign() -> 수동 할당