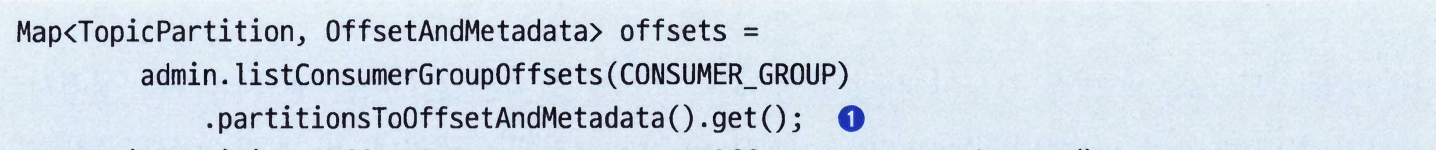0.11 부터 프로그램적인 관리 기능 API를 제공하기 위한 목적으로 AdminClient가 추가되었다. AdminClient 개요# 비동기적이고 최종적 일관성을 가지는 API# 카프카의 AdminClient는 비동기적으로 작동한다. 카프카 컨트롤러로부터 브로커로의 메타데이터 전파가 비동기적으로 이루어지기 때문에, AdminClient API가 리턴하는 Future 객체들은 컨트롤러의 상태가 완전히 업데이트된 시점에 완료된 것으로 간주한다.이 시점에 모든 브로커가 전부 다 새로운 상태에 대해 알고 있지는 못할 수 있기 때문에, listTopics 요청은 최신 상태를 전달받지 않은 브로커에 의해 처리될 수 있다. 이러한 속성을 최종적 일관성(eventual consistency)이라고 한다. 최종적 일관성: 최종적으로 모든 브로커는 모든 토픽에 대해 알게 될 것 이지만, 정확히 그게 언제가 될지에 대해서는 아무런 보장도 할 수 없다. AdminClient의 각 메서드는 메서드별로 특정한 Options 객체를 인수로 받는다.이 객체들은 브로커가 요청을 어떻게 처리할지에 대해 서로 다른 설정을 담는다. 수평 구조# 모든 어드민 작업은 KafkaAdminClient에 구현되어 있는 아파치 카프카 프로토콜을 사용해서 이루어진다. 추가 참고 사항# 클러스터의 상태를 변경하는 모든 작업(create, delete, alter)은 컨트롤러에 의해 수행된다. 클러스터 상태를 읽기만 하는 작업(list, describe)은 아무 브로커에서나 수행될 수 있으며 클라이언트 입자에서 보이는 가장 부하가 적은 브로커로 전달된다. 카프카 2.5을 기준으로, 대부분의 어드민 작업인 AdminClient를 통해서 수행되거나 아니면 주키퍼에 저장되어 있는 메타데이터를 직접 수정하는 방식으로 이루어진다. 주키퍼를 직접 수정하는 것은 절대 쓰지 말 것을 권장한다. AdminClient 사용법: 생성, 설정, 닫기# 정적 메서드인 create 메서드는 설정값을 담고 있는 Properties 객체를 인수로 받는다.반드시 있어야 하는 설정은 클러스터에 대한 URI 하나뿐이다. AdminClient를 시작했으면, close를 호출해서 결국엔 닫아야 한다.close 메서드를 호출할 때는 아직 진행중인 작업이 있을 수 있어, 타입아웃 매개변수를 받는다.close를 호출하면 다른 메서드를 호출해서 요청을 보낼 수 는 없지만, 클라이언트는 타임아웃이 만료될 때까지 응답을 기다릴 것이다.타임아웃이 발생하면 모든 진행중인 작동을 멈추고 모든 자원을 해제한다. 타임아웃 없이 close를 호출한다는 것은 얼마가 되었든 모든 진행중인 작업이 완료될 때까지 대기하게 된다는 의미다. client.dns.lookup# 기본적으로 카프카는 부트스트랩 서버 설정에 포함된 호스트명을 기준으로 연결을 검증하고, 해석하고, 생성한다. DNS 별칭을 사용하는 경우모든 브로커들을 부트스트랩 서버 설정에 일일이 지정하는 것보다 이 모든 브로커 전체를 가리킬 하나의 DNS 별칭을 만들 수 있다. 이것은 편리하지만, SASL을 사용해서 인증하려고할 때 중간자 공격으로 처리하여 인증을 거부한다. 이러한 경우 client.dns.lookup=resolve_canonical_bootstrap_servers_only 설정을 잡아 주면, 클라이언트는 DNS 별칭을 ‘펼치게’ 되기 때문에 DNS 별칭을 포함된 모든 브로커 이름이 일일이 부트스트랩 서버 목록에 넣어 준 것고 ㅏ동일하게 된다. 다수의 IP 주소로 연결되는 DNS 이름을 사용하는 경우최근 네트워크 아키텍처에 모든 브로커를 프록시나 로드 밸런서 뒤로 숨기는 것은 매우 흔하다. 이와 같은 이유 떄문에 broker1.host.com를 여러 개의 IP 주소로 연결하는 것은 매우 흔하다. 기본적으로, 카프카 클라이언트는 해석된 첫 번째 호스트명으로 연결을 시도한다. 따라서, 해석된 IP 주소가 사용 불능일 경우 브로커가 멀쩡학 ㅔ작동하고 있는데도 클라이언트는 연결에 실패할 수 있다. 바로 이러한 이유 때문에 클라이언트가 로드 밸런싱 계층의 고가용성을 충분히 활용할 수 있도록 client.dns.lookup=use_all_dns_ips를 사용하는 것이 권장된다. request.timeout.ms# 애플리케이션이 AdminClient의 응답을 기다릴 수 있는 시간의 최대값을 정의한다.(기본값은 120초)이 시간에는 클라이언트가 재시도가 가능한 에러를 받고 재시도하는 시간이 포함된다. Options 객체에 해당 메서드에만 해당하는 타임아웃값을 설정할 수 있다.설정 관리# 설정 관리는 ConfigResource 객체를 사용해서 할 수 있다. 설정 가능한 자원에는 브로커, 브로커 로그, 토픽이 있다. 토픽 설정이 기본값이 아닌 것으로 취급하는 경우는 다음과 같다.사용자가 토픽의 설정값을 기본값이 아닌 것으로 잡아준 경우 브로커 단위 설정이 수정된 상태에서 톺기이 생성되어 기본값이 아닌 값을 브로커 설정으로부터 상속받았을 경우 컨슈머 그룹 관리# 컨슈머 그룹 살펴보기# 컨슈머 그룹의 목록 조회valid() 메서드로 리턴되는 모음은 클러스터가 에러없이 리턴한 컨슈머 그룹만 포함한다.errors() 세버드를 사용해서 모든 예외를 가져올 수 있다.만약 우리가 다른 예제에서 본 것 처럼 all() 메서드를 호출한다면, 클러스터가 리턴한 에러 중 맨 첫 번째 것만 예외 형태로 발생한다. 특정 그룹에 대해 상세한 정보 조회그룹 멤버와 멤버별 식별자와 호스트명, 멤버별로 할당된 파티션, 할당 알고리즘, 그룹 코디네이터의 호스트명이 포함된다. 컨슈머 그룹의 오프셋 정보 조회 컨슈머 그룹 수정하기# 오프셋 토픽의 오피셋 값을 변경한다 해도 컨슈머 그룹에 변경 여부가 전달되지 않는다는 점을 명심해라. 컨슈머가 모르는 오프셋 변경을 방지하기 위해, 카프카에서는 현재 작업이 돌아가고 있느 컨슈머 그룹에 대한 오프셋을 수정하는 것을 허용하지 않는다.아래 alterConsumerGroupOffsets가 실패하는 가장 흔한 이유 중 하나는 컨슈머 그룹을 미리 정지시키지 않아서다. 만약 컨슈머 그룹이 여전히 돌아가고 있는 중이라면, 컨슈머 코디네이터 입장에서는 컨슈머 그룹에 대한 오프셋 변경 시도가 곧 그룹의 멤버가 아닌 클라이언트가 오프셋을 커밋하려 드는 것으로 간주한다. 이 경우, UnknownmemberIdException이 발생한다. 클러스터 메타데이터# 애플리케이션이 연결된 클러스터에 대한 정보를 읽을 수 있다. 고급 어드민 작업# 토픽에 파티션 추가하기# 만약 토픽에 파티션을 추가해야 한다면 이것 때문에 토픽을 ㅇ릭고 있는 애플리케이션들이 깨지지 않을지 확인해야 할 것 이다.토픽의 메시지들이 키를 가지고 있는 경우 같은 키를 가진 메시지들이 모두 동일한 파티션에 들어가 동일한 컨슈머에 의해 동일한 순서로 처리될 것이라고 생각할 수 있기 때문이다. 토픽에서 레코드 삭제하기# 토픽에 30일간의 보존 기한이 설정되어 있다 하더라도 파티션별로 모든 데이터가 하나의 세그먼트에 저장되어 있다면 보존 기한을 넘긴 데이터라 한들 삭제되지 않을 수도 있다. deleteRecords() 메서드는 호출 시점을 기준으로 지정된 오프셋보다 더 오래된 모든 레코드에 삭제 표시를 함으로써 컨슈머가 접근할 수 없도록 한다.이 메서드는 삭제된 레코드의 오프셋 중 가장 큰 값을 리턴하기 때문에 의도했던 대로 삭제가 이루어졌는지 확인할 수 있다. 리더 선출# electLeader() 메서드는 파티션별로 리더 선출 방식을 변경할 수 있다.선호 리더 선출각 파티션은 선호 리더라 불리는 레플리카를 하나씩 가진다. 모든 파티션이 선호 리더 레플리카를 리더로 삼을 경우 각 브로커마다 할당되는 리더의 개수가 균형을 이룬다. 기본적으로, 카프카는 5분마다 선호 리더 레플리카가 실제로 리더를 맡고 있는지를 확인해서 리더를 맡을 수 있는데도 맡고 있지 않은 경우 해당 레플리카를 리더로 삼는다. auto.leader.rebalance.enable 설정을 false로 잡혀 있거나 아니면 좀 더 빨리 이 과정을 작동시키고 싶다면 electLeader() 메서드를 호출하면 된다. 언클린 리더 선출만약 어느 파티션의 리더 레플리카가 사용 불능 상태가 되었는데 다른 레플리카들은 리더를 맡을 수 없는 상황이라면(대개 데이터가 없는 경우), 해당 파티션은 리더가 없게 되고 사용 불능 상태가 된다. 이 문제를 해결하는 방법 중 하나가 리더가 될 수 없는 레플리카를 그냥 리더로 삼아버리는 언클린 리더 선출을 동작시키는 것이다. 이것은 데이터 유실을 초래한다. 레플리카 재할당# 레플리카의 현재 위치가 마음에 안 들 때가 있다. alterPartitionReassignments를 사용하면 파티션에 속한 각각의 위치를 정밀하게 제어할 수 있다.레플리카를 하나의 브로커에서 다른 브로커로 재할당하는 일은 브로커 간에 대량의 데이터 복제를 초래한다는 점을 명심하라.사용 가능한 네트워크 대역폭에 주의하고, 필요할 경우 쿼터를 설정해서 스로틀링해주는 게 좋다. 테스트하기# 아파치 카프카는 원하는 수만큼의 브로커를 설정해서 초기화할 수 있는 MockAdminClient 테스트 클래스를 제공한다.이 클래스를 사용하면 실제 카프카 클러스터를 돌려서 거기에 실제 어드민 작업을 수행할 필요 없이 애플리케이션이 제대로 작동하는지 확인할 수 있다. 이 테스트 클래스는 자주 사용되는 메서드가 매우 포괄적인 목업 기능을 제공한다.MockAdminClient의 토픽 생성 메서드를 호출한 뒤 listTopics()를 호출하면 방금 전 생성한 토픽이 리턴된다. Please enable JavaScript to view the comments powered by Disqus. comments powered by