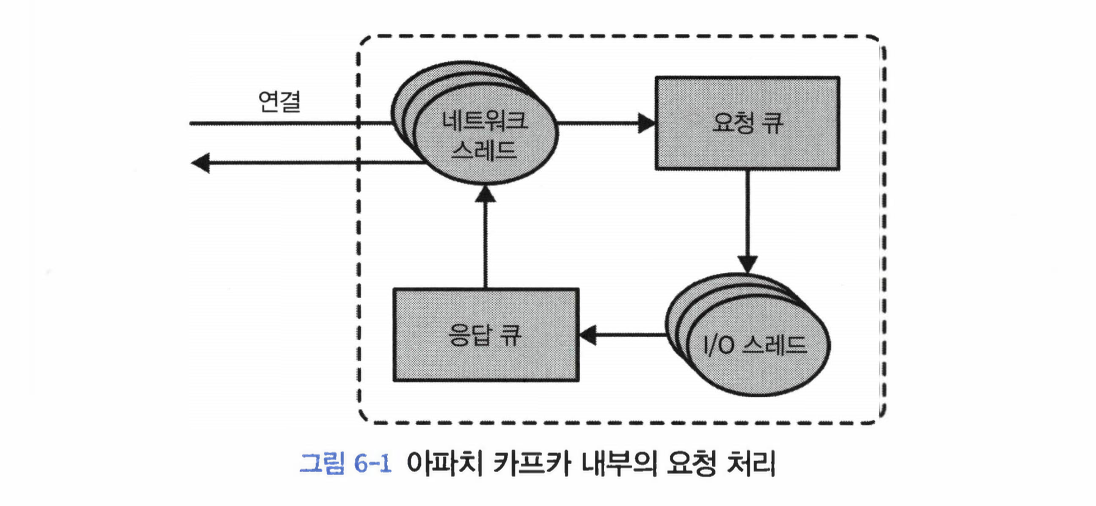
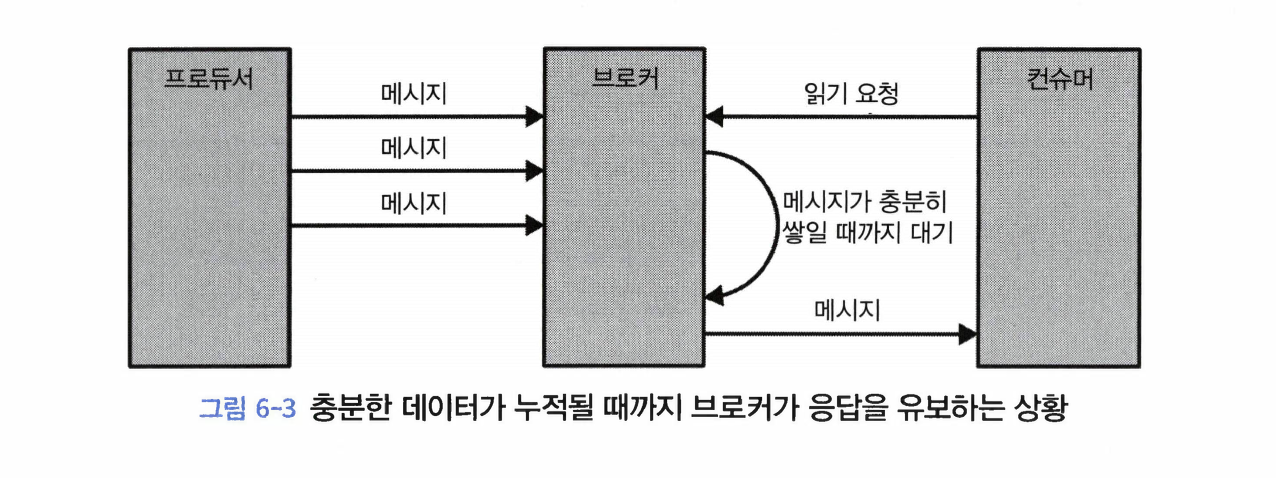
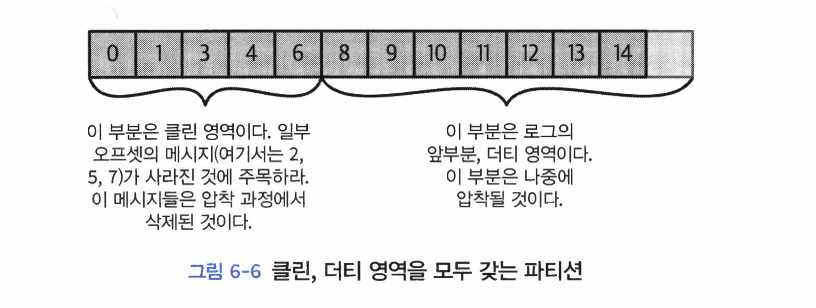
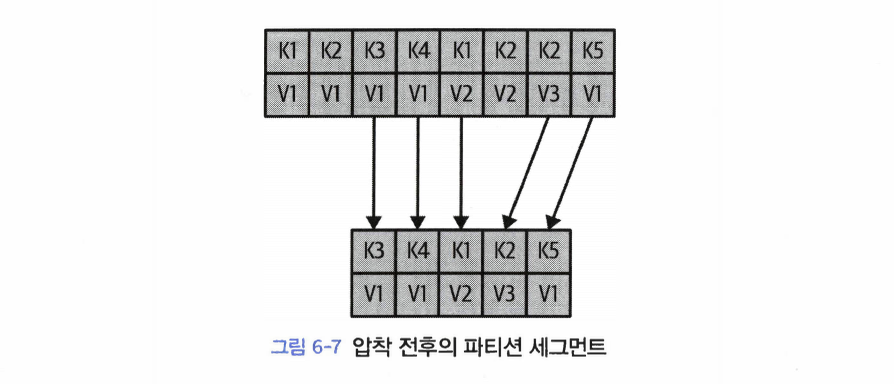
클러스터 멤버십# 카프카는 현재 클러스터의 멤버인 브로커들의 목록을 유지하기 위해 아파치 주키퍼를 사용한다. 각 브로커는 브로커 설정 파일에 저장되었거나, 자동으로 생성된 고유 식별자를 가진다. 브로커 프로세스는 시작될 때마다 주키퍼에 Ephemeral 노드의 형태롤 ID를 등록한다. 컨트롤러들과 몇몇의 생태계 툴들은 브로커가 등록되는 주키퍼의 /brokers/ids 경로를 구독함으로써 브로커가 추가되거나 제거될 때마다 알림을 받는다.만약 동일한 ID를 가진 다른 브로커를 시작한다면, 에러가 발생한다. 브로커가 정지하면 브로커를 나타내는 ZNode는 삭제되지만, 브로커의 ID는 다른 자료구조에 남아 있게 된다.그렇기 때문에 만약 특정한 브로커가 완전히 유실되어 동일한 ID를 가진 새로운 브로커를 투입시킬 경우, 곧바로 클러스터에 유실된 브로커의 자리를 대신해 이전 브로커의 토픽과 파티션들을 할당받는다. 참고: Ephemeral 노드는 ZNode의 한 종류이다. 컨트롤러# 컨트롤러는 일반적인 카프카 브로커의 기능에 더해서 파티션 리더를 선출하는 역할을 추가적으로 맡는다.클러스터에서 가장 먼저 시작되는 브로커는 주키퍼 /controller에 Ephemeral 노드를 생성함으로써 컨트롤러가 된다. 브로커들이 주키퍼의 컨트롤러 노드에 뭔가 변동이 생겼을 때 알림을 받기 위해 이 노드에 와치를 설정한다. 이렇게 함으로써 우리는 클러스터 안에 한 번에 단 한 개의 컨트롤러만 있도록 보장할 수 있다. 컨트롤러 브로커가 멈추거나 주키퍼와의 연결이 끊어질 경우, 이 Ephemeral 노드는 삭제된다.컨트롤러가 사용하는 주키퍼 클라이언트가 zookeeper.session.timeout.ms에 설정된 값보다 더오랫동안 주키퍼에 하트비트를 전송하지 않는 것도 여기에 해당한다. Ephermeral 노드가 삭제될 경우, 클러스터 안의 다른 브로커들은 주키퍼에 설정된 와치를 통해 컨트롤러가 없어졌다는 것을 알아차리게되며 주키퍼에 컨트롤러 노드를 생성하려고 시도하게 된다. 주키퍼에 가장 먼저 새로운 노드를 생성하는 데 성공한 브로커가 다음 컨트롤러가 된다. 브로커는 새로운 컨트롤러가 선출될 때마다 주키퍼의 조건적 증가 연산에 의해 증가된 에포크 값을 전달받게 된다. 브로커는 현재 컨트롤러의 에포크 값을 알고 있기 때문에, 만약 더 낮은 에포크 값을 가진 컨트롤러로부터 메시지를 받을 경우 무시한다.이것은 컨트롤러 브로커가 오랫동안 가비지 수집 때문에 멈춘 사이 주키퍼 사이의 연결이 끊어질 수 있기 때문에 중요하다. 이전 컨트롤러가 작업을 재개할 경우, 새로운 컨트롤러가 선출되었다는 것을 알지 못한 채 브로커에 메시지를 보낼 수 있다. 이러한 컨트롤러를 좀비라고 부른다. 컨트롤러가 전송하는 메시지에 컨트롤러 에포크를 포함하면 브로커는 예전 컨트롤러가 보내온 메시지를 무시할 수 있다. 에포크는 좀비를 방지하는 방법이기도 하다. 브로커가 컨트롤러가 되면, 클러스터 메타데이터 관리와 리더 선출을 시작하기 전에 먼저 주키퍼로부터 최신 레플리카 상태 맵을 비동기로 읽어온다. 브로커가 클러스터를 나갔다는 사실을 컨트롤러가 알아차리면, 컨트롤러는 해당 브로커가 리더를 맡고 있었던 모든 파티션에 대해 새로운 브로커를 할당해주게 된다. KRaft: 카프카의 새로운 래프트 기반 컨트롤러# 주키퍼 방식의 카프카는 필요로 하는 파티션 수까지 확장될 수 없는 원인으로 KRaft 로 만들게 되었다.브로커, 컨트롤러, 주키퍼 간에 메타데이터 불일치가 발생할 수 있다.컨트롤러가 주키퍼에 메타데이터를 쓰는 작업은 동기적으로 이루어지지만, 브로커 메시지를 보내는 작업은 비동기적으로 이루어진다. 또한, 주키퍼로부터 업데이트를 받는 과정 역시 비동기적으로 이루어지기 때문이다. 컨트롤러가 재시작될 때마다 주키퍼로부터 모든 브로커와 파티션에 대한 메타데이터를 읽어와야 한다. 그러고 나서 이 메타데이터를 모든 브로커로 전송한다. 이는 병목이 된다. 메타데이터 소유권 관련 내부 아키텍처가 그리 좋지 못하다. 주키퍼는 그 자체로 분산 시스템이며, 카프카와 마찬가지로 운영을 위해서는 어느 정도 기반 지식이 있어야 한다. 그렇기 때문에 카프카를 사용하려는 개발자들은 두 개의 분산 시스템에 대해 배워야 한다. KRaft의 핵심 아이디어는 카프카 그 자체에 사용자가 상태를 이벤트 스트림으로 나타낼 수 있도록 하는 로그 기반 아키텍처를 도입한다는 점이다.이러한 표현 방법의 장점은 카프카 커뮤니티에게 익숙한 것이다. 즉, 다수의 컨슈머를 사용해서 이벤트를 replay함으로써 최신 상태를 빠르게 따라잡을 수 있다. KRaft에서 컨트롤러 노드들은 메타데이터 이벤트 로그를 관리하는 래프트 쿼럼이 된다.이 로그는 메타데이터의 변경 내역을 저장한다. 현재 주키퍼에 저장되어 있는 모든 정보들이 여기에 저장될 것이다. 메타데이터 로그의 리더 역할을 맡고 있는 컨트롤러는 액티브 컨트롤러라고 부른다.액티브 컨트롤러는 브로커가 보내온 모든 RPC 호출을 처리한다. 팔로워 컨트롤러들은 액티브 컨트롤러에 쓰여진 데이터를 복제하며, 액티브 컨트롤러에 장애가 발생했을 시에 즉시 투입될 수 잇도록 주비 상태를 유지한다. 이제 모든 컨트롤러들이 모두 최신 상태를 가지고 있으므로, 컨트롤러 장애 복구는 모든 상태를 새 컨트롤러로 이전하는 기나긴 리로드 기간을 필요로 하지 않는다. 다른 브로커들이 새로도입된 MetadataFetch API를 사용해서 액티브 컨트롤러로부터 변경 사항을 pull한다. 브로커 프로세스는 시작시 주키퍼가 아닌, 컨트롤러 쿼럼에 등록한다.그리고 운영자가 등록을 해제하지않는 한 이를 유지한다. 따라서 브로커가 종료되면, 오프라인 상태로 들어가는 것일 뿐 등록은 여전히 유지된다. 온라인 상태지만 최신 메타데이터로 최신 메타데이터로 최신 상태를 유지하고 있지는 않은 브로커의 경오 펜스된 상태(fenced state)가 되어 클라이언트 요청을 처리할 수 없다. 브로커에 새로 도입된 펜스된 상태는 클라이언트가 더 이상 리더가 아닌, 하지만 최신 상태에서 너무 떨어지는 바람에 자신이 리더가 아니라는 것조차 인식을 못 하는 브로커에 쓰는 것을 방지한다. 리더 레플리카각 파티션에 하나만 존재 모든 쓰기 요청은 리더 레플리카로 주어진다. 클라이언트들은 리더 레플리카나 팔로워로부터 레코드를 읽어올 수 있다. 팔로워 레플리카별도로 설정하지 않는 한, 팔로워는 클라이언트의 요청을 처리할 수 있다. 리더 레플리카로 들어온 최근 메시지들을 복제함으로써 최신 상태를 유지한다. 만약, 해당 파티션 리더 레플리카에 크래쉬가 날 경우, 팔로워 레플리카 중 하나가 파티션의 새 리더 파티션으로 승격된다. 팔로워로부터 읽기클라이언트가 리더 레플리카 대신 가장 가까이에 있는 인-싱크 레플리카로부터 읽게 함으로써 네트워크 비용을 줄이도록 설정할 수 있다. 이 기능을 사용하려면 클라이언트 위치를 지정하는 client.rack 컨슈머 설정값을 잡아주어야 한다.브로커 설정 중에는 replica.selector.class를 RackAwareReplicaSelector 잡아주어야 한다. 리더 레플리카가 수행하는 또 다른 일은 어느 팔로워 레플리카가 리더 레플리카의 최신 상태를 유지하고 있는지 확인하는 것이다.팔로워 레플리카는 리더 레플리카와 동기화를 유지하기 위해 리더 레플리카에 읽기 요청을 보낸다. 이러한 요청에 대한 응답으로 리더 레플리카는 메시지를 되돌려 준다. 읽기 요청들은 복제를 수행하는 입장에서 다음에 받아야 할 메시지 오프셋을 포함할 뿐만 아니라 언제나 메시지를 순서대로 요청한다. 리더 레플리카는 각 팔로워 레플리카가 마지막으로 요청한 오프셋 값을 확인함으로써 각 레플리카가 얼마나 뒤쳐져 있는지를 알 수 있다. 팔로워 레플리카가 일정 시간 이상 읽기 요청을 보내지 않거나, 읽기 요청을 보내긴 했는데 가장 최근 추가된 메시지를 따라잡지 못하는 경우에 해당 레플리카를 ‘아웃-오브-싱크 레플리카’로 간주한다.아웃-오브-싱크 레플리카는 리더 레플리카의 장애 상황에 리더가 될 수 없다. 반대로 최신 메시지를 요청하고 있는 레플리카는 ‘인-싱크 레플리카’로 간주한다.인-싱크 레플리카는 파티션 리더로 선출 될 수 있다. 아웃-오브-싱크로 판정될 때까지 선정되는 시간은 replica.lag.time.max.ms 설정 매개변수에 의해 결정된다. ‘현재 리더’에 더하여, 각 파티션은 ‘선호 리더’를 갖는다.‘선호 리더’: 토픽이 처음 생성되었을 때 리더 레플리카였던 레플리카 클러스터 내의 모든 파티션에 대해 선호 리더가 실제 리더가 될 경우 부하가 브로커 사이에 균등학 분배될 것이라고 예상할 수 있다. 카프카에는 auto.leader.rebalance.enable=true 설정이 기본적으로 잡혀있다. 이 설정은 선호 리더가 현재 리더가 아니지만, 현재 리더와 동기화 되고 있을 경우 리더 선출을 실행시킴으로써 선호 리더를 현재 리더로 만들어 준다. 요청 처리# 카프카는 TCP로 전달되는 이진 프로토콜을 사용하여, 요청의 형식과 브로커가 응답하는 방식을 정의한다.모든 요청은 다음과 같은 표준 헤더를 갖는다.요청 유형: API 키라고도 불린다. 요청 버전: 브로커는 서로 다른 버전의 클라이언트로부터 요청을 받아 각각의 버전에 맞는 응답을 할 수 있다. Correlation ID: 각각의 요청에 붙은 고유한 식별자. 응답이나 에러 로그에도 포함된다. 트러블 슈팅에 사용할 수 있다. 클라이언트 ID: 요청을 보낸 애플리케이션을 식별하기 위해 사용한다. 카프카 내부 요청 처리 방식브로커는 연결을 받는 각 포트별로 acceptor 스레드를 하나씩 실행시킨다. acceptor 스레드는 연결을 생성하고 들어온 요청을 네트워크 스레드(프로세서 스레드)에 넘겨 처리하도록 한다. 네트워크 스레드는 클라이언트로부터 들어온 요청들을 받아서 요청 큐에 넣고, 응답 큐에서 응답을 가져다 클라이언트로 보낸다. 가끔 클라이언트로 보낼 응답에 지연이 필요하다면, 지연된 응답들은 완료될 때까지 purgatory에 저장된다. 클라이언트 요청 유형쓰기 요청: 카프카 브로커로부터 쓰고 있는 프로듀서가 보낸 요청 읽기 요청: 카프카 브로커로부터 메시지를 읽어오고 있는 컨슈머나 팔로워 레플리카가 보낸 요청 어드민 요청: 토픽 생성이나 삭제와 같이 메타데이터 작업을 수행중인 어드민 클라이언트가 보낸 요청 만약 브로커가 다른 브로커가 리더로 맡고 있는 파티션에 대한 쓰기 요청을 받은 경우 ‘Not a Leader for Partition’에러를 응답으로 보낸다. (읽기 요청의 경우도 동일) 클라이언트는 메타데이터를 통해서 어느 브로커로 요청을 보내야될 지 알 수 있게 된다.메타데이터에 대한 요청은 아무 브로커에 보내도 상관없다.모든 브로커들은 이러한 메타데이터 캐시를 가지고 있기 때문이다. 메타데이터 요청에는 클라이언트가 다루고자 하는 토픽의 목록이 포함한다.메다데이터 요청에 대한 응답으로 아래의 내용이 포함된다.이 토픽들에 어떤 파티션들이 있는지 각 파티션의 레플리카에는 무엇이 있으며, 어떤 레플리카가 리더인지 클라이언트는 메타데이터를 캐시해 두었다가 각 파티션의 리더 역할을 맡고 있는 브로커에 바로 쓰거나 읽는다.클라이언트는 토픽 메타데이터가 변경될 경우 최신값을 유지하기 위해 때때로 새로운 메타데이터 요청을 보내서 이 정보를 새로고침한다.클라이언트가 요청에 대해 ‘Not a Leader’ 에러를 응답 받는 경우에도 메타데이터를 새로고침한다. 쓰기 요청# 파티션의 리더 레플리카를 가지고 있는 브로커가 해당 파티션에 쓰기 요청을 받게 되면 몇 가지 유효성 검증부터 한다.데이터를 보내고 있는 사용자가 토픽에 대한 쓰기 권한을 가지고 있는가? 요청에 지정되어 있는 acks 설정값이 올바른가? (0, 1, all 중에 하나로 설정되어 있는가) 만약 acks 설정값이 all로 잡혀 있을 경우, 메시지를 안전하게 쓸 수 있는 충분한 인-싱크 레플리카가 있는가?현재 인-싱크 레플리카 수가 설정된 값 아래로 내려가면 새로운 메시지를 받지 않도록 브로커를 설정해 줄 수 있다. 브로커는 새 메시지들을 로컬 디스크에 쓴다. 리눅스의 경우 메시지는 파일시스템 캐시에 쓰여지는데, 이들이 언제 디스크에 반영될지에는 보장이 없다. 메시지가 파티션 리더에 쓰여지고 나면,만약 acks가 0이나 1로 설정되어 있다면 응답을 바로 보낸다. 만약 acks가 all로 설정되어 있다면 일단 요청을 purgatory 버퍼에 저장한다. 그리고 팔로워 레플리카들이 메시지를 복제한 것을 확인한 다음에야 클라이언트에 응답을 돌려보낸다. 읽기 요청# 읽기 요청도 쓰기 요청과 비슷한 방식으로 요청을 처리한다. 클라이언트는 브로커에 읽고자 하는 메시지의 토픽, 파티션 그리고 오프셋 목록을 포함해 요청을 보낸다. 클라이언트는 각 파티션에 대해 브로커가 리턴할 수 있는 최대 데이터의 양을 지정해야 된다.한도값이 없으면, 브로커는 클라이언트가 메모리 부족에 처할 수 있을 정도로 큰 응답을 보낼 수도 있다. 클라이언트는 브로커가 리턴될 데이터의 하한도 지정할 수 있다.트래픽이 그리 많지 않은 토픽들로부터 메시지를 읽어오고 있을 때 CPU와 네트워크 사용량을 감소시키는 좋은 방법이다. 클라이언트는 브로커에게 요청할 때 타임아웃 역시 지정해 줄 수 있다.만약 x밀리초 안에 하한만큼의 데이터가 모이지 않으면 그냥 있는 것을 보낸다. 요청을 받는 파티션 리더는 먼저 요청이 유효한지 확인한다.만약 클라이언트가 너무 오래되어 파티션에 삭제된 메시지나 아직 존재하지 않는 오프셋의 메시지를 요청할 경우 브로커는 에러를 응답으로 보내게 된다. 카프카는 클라이언트에게 보내는 메시지에 제로카피 최적화를 적용한다.제로카피: 파일에서 읽어온 메시지들을 중간 버퍼를 거치지 않고 바로 네트워크 채널로 보내는 것 이 방식을 채택함으로써 데이터를 복사하고 메모리 상에 버퍼를 관리하기 위한 오버헤드가 사라지며, 결과적으로 성능이 향상된다. 클라이언트는 모든 인-싱크 레플리카에 쓰여진 메시지들만 읽을 수 있다.파티션 리더는 어느 메시지가 어느 레플리카로 복제되었는지 알고 있으며, 특정 메시지가 모든 인-싱크 레플리카에 쓰여지기 전까지는 컨슈머들이 읽을 수 없다. 만약 리더에 크래시가 발생해서 다른 레플리카가 리더 역할을 이어받는다면, 이 메시지들은 더 이상 카프카에 존재하지 않게 된다.만약 클라이언트가 이렇게 리더에만 존재하는 메시지들을 읽을 수 있도록 한다면, 크래시 상황에서 일관성이 결여될 수 있는 것이다. 모든 인-싱크 레플리카가 메시지를 받을 때까지 기다린 뒤에야 컨슈머가 읽을 수 있기 때문에, 복제가 늦어지면 새 메시지가 컨슈머에 도달하는 데 걸리는 시간도 길어진다. 이렇게 지연된 시간은 replica.lag.time.max.ms 설정에 따라 제한된다.시간을 초과하면 아웃-오브-싱크 레플리카가 된다. 컨슈머가 매우 많은 수의 파티션들로부터 이벤트를 읽어오는 경우에, 컨슈머가 매번 파티션의 전체 목록을 요청하고 브로커는 모든 메타데이터를 돌려 보내는 방식을 비효율적이다.오버헤드를 최소화하기 위해 읽기 세션 캐시를 사용한다. 컨슈머는 읽고 있는 파티션 목록과 그 메타데이터를 캐시하는 세션을 생성할 수 있다.세션이 한 번 생성되면, 컨슈머들은 더 이상 요청을 보낼 때마다 모든 파티션을 지정할 필요없이 점진적으로 읽기 요청을 보낼 수있다. 브로커는 변경 사항이 있는 경우에만 응답에 메타데이터를 포함하면 된다. 세션 캐시의 크기에도 한도가 있어 카프카는 팔로워 레플리카나 일고 있는 파티션의 수가 많은 컨슈머를 우선시하고, 어떤 경우에는 캐시된 세션이 아예 생성되지 않거나 생성되었던 것이 해제될 수 있다. 기타 요청# 카프카 프로토콜은 현재 61개의 서로 다른 요청 유형을 정의하고 있으며, 앞으로도 더 늘어날 것이다. 물리적 저장소# 카프카의 기본 저장 단위는 파티션 레플리카이다.파티션은 서로 다른 브로커들 사이에 분리될 수 없으며, 같은 브로커의 서로 다른 디스크에 분할 저장되는 것조차도 불가능하다. 파티션의 크기는 특정 마운트 지점에 사용 가능한 공간에 제한을 받는다고 볼 수 있다. log.dirs 매개변수: 카프카를 설정할 때 파티션들이 저장될 디렉토리 목록카프카가 사용할 각 마운트 지점별로 하나의 디렉토리를 포함하도록 설정하는 것이 일반적이다. 계층화된 저장소# 카프카 커뮤니티는 카프카에 계층화된 저장소 기능을 추가하기 위한 작업을 시작하였다. 프로젝트의 동기파티션별로 저장 가능한 데이터에 한도가 있다. 지연과 처리량이 주 고려사항일 경우 클러스터는 필요한 것 이상으로 커지는 경우가 많다. 파티션의 크기가 클수록 클러스터의 탄력성은 줄어든다. 계층화된 저장소 기능에서는 클러스터의 저장소를 로컬과 원격, 두 계층으로 나눈다.로컬 계층: 로컬 세그먼트를 저장하기 위해 카프카 브로커의 로컬 디스크를 사용한다. 원격 계층: 완료된 로그 세그먼트를 저장하기 위해 HDFS나 S3와 같은 전용 저장소 시스템을 사용한다.완료된 로그 세그먼트의 기준: log.segment.bytes 크기에 도달하거나 log.roll.ms보다 시간이 경과되어 세그먼트 파일이 닫히는 경우 사용자는 계층별로 서로 다른 보존 정책을 설정할 수 있다. 로컬 저장소는 원격 저장소에 비해 지연이 훨씬 짧다. 특정 토픽만 로컬 계층 전용으로 설정하는 것이 가능하다. 계층화된 저장소 기능으로 얻는 장점카프카 클러스터의 메모리와 CPU에 상관없이 저장소를 확장할 수 있다. 카프카 브로커에 로컬 저장되는 데이터의 양이 줄어드며, 복구와 리밸런싱 과정에서 복사되어야 할 데이터의 양 역시 줄어든다.원격 계층에 저장되는 로그 세그먼트들은 굳이 브로커로 복원될 필요없이 원격 계층에서 바로 클라이언트로 전달된다. 모든 데이터가 브로커에 저장되지 않아서 보존 기한을 늘려잡아 주더라도 더 이상 카프카 클러스터 저장소를 확장하거나 새로운 노드를 추가해 줄 필요가 없다. 파티션 할당# 파티션을 할당할 때 목표는 다음과 같다.레플리카들을 가능한 브로커 간에 고르게 분산시킨다. 각 파티션에 대해 각각의 레플리카들은 서로 다른 브로커에 배치되도록 한다. 만약 브로커에 랙 정보가 설정되어 있다면, 가능한 각 파티션들의 레플리카들을 서로 다른 랙에 할당한다. 이렇게 하면 하나의 랙 전체가 작동 불능에 빠지더라도 파티션 전체가 사용 불능에 빠지는 사태를 방지할 수 있다. 각 파티션과 레플리카에 올바른 브로커를 선택했다면, 새 파티션을 저장할 디렉토리를 결정해야 한다.이 작업 파티션별로 독립적으로 수행된다. 각 디렉토리에 저장되어 있는 파티션이 수를 센 뒤, 가장 적은 파티션이 저장된 디렉토리에 새 파티션을 저장한다. 파일 관리# 각각의 토픽에 대해 보존 기한을 설정할 수 있다. 큰 파일에서 삭제해야 할 메시지를 찾아서 지우는 작업은 시간이 오래 걸릴 뿐만 아니라 에러의 가능성도 높기 때문에, 하나의 파티션을 여러 개의 세그먼트로 분할해서 관리한다.기본값: 각 세그먼트는 1GB의 데이터 혹은 1주일치의 데이터 중 적은 쪽만큼을 저장한다. 파티션 단위로 메시지를 쓰는 만큼 각 세그먼트 한도가 다 차면 세그먼트를 닫고 새 세그먼트를 생성한다. 액티브 세그먼트: 현재 쓰여지고 있는 세그먼트액티브 세그먼트는 어떠한 경우에도 삭제 되지 않기 때문에, 로그 보존 기한을 하루로 설정했는데 각 세그먼트가 5일치 데이터를 저장하고 있을 경우, 실제로 5일치의 데이터가 보존되게 된다. 카프카 브로커는 각 파티션의 모든 세그먼트에 대해 파일 핸들을 연다.이것 때문에 사용중인 파일 핸들 수가 매우 높게 유지될 수 있는 만큼 운영체제 역시 여기에 맞춰서 튜닝해줄 필요가 있다. 파일 형식# 각 세그먼트는 하나의 데이터 파일 형태로 저장된다.파일 안에는 카프카의 메시지와 오프셋이 저장된다. 디스크에 저장되는 데이터의 형식은 사용자가 프로듀서를 통해서 브로커를 보내는, 그리고 나중에 브로커로부터 컨슈머로 보내지는 메시지의 형식과 동일하다.네트워크를 통해 전달되는 형식과 디스크에 저장되는 형식을 통일함으로써 카프카는 컨슈머에 메시지를 전송할 때 제로카피 최적화를 달성할 수 있으며, 프로듀서가 이미 압축한 메시지들을 압축 해제해서 다시 압축하는 수고 역시 덜 수 있다. 카프카 메시지는 ‘사용자 페이로드’, ‘시스템 헤더’ 두 부분으로 나누어진다.‘사용자 페이로드’는 키값(optional), 밸류값, 헤더 모음(optional)을 포함한다. 카프카 프로듀서는 언제나 메시지를 배치 단위로 전송한다. 메시지 배치 헤더에는 다음과 같은 것들이 포함된다.메시지 형식의 현재 버전을 가리키는 매직 넘버 배치에 포함된 첫 번째 메시지의 오프셋과 마지막 오프셋의 차이 첫 번째 메시지의 타임스탬프와 배치에서 가장 큰 타임스탬프 바이트 단위로 표시된 배치의 크기 해당 배치를 바으 리더의 에포크 값, 이 값은 새 리더가 선출된 뒤 메시지를 절삭할 때 사용된다. 배치가 오염되지 않았음을 확인하기 위한 체크섬 서로 다른 속성을 표시하기 위한 16비트: 압축 유형, 타임스탬프 유형, 배치가 트랜잭션의 일부 혹은 컨트롤 배치인지의 여부 프로듀서 ID, 프로듀서 에포크, 그리고 배치의 첫 번째 시퀀스 넘버: 이들은 모두 ‘정확히 한 번’ 보장을 위해 사용된다. 배치에 포함된 메시지들의 집합 레코드는 다음과 같은 정보를 포함한다.바이트 단위로 표시된 레코드의 크기 속성: 현재로서 레코드 단위 속성은 없기 때문에 사용하지 않는다. 현재 레코드의 오프셋과 배치 내 첫 번째 레코드의 오프셋과의 차이 현재 레코드의 타임스탬프와 배치 내 첫 번째 레코드의 타임스탬프의 차이(밀리초) 사용자 페이로드: 키, 밸류, 헤더 사용자 데이터를 저장하는 메시지 배치 외에도, 카프카에는 컨트롤 배치가 있다.컨트롤 배치는 트랜잭션 커밋 등이 있고, 컨슈머가 받아서 처리하기 때문에 사용자 애플리케이션 관점에서는 보이지 않으며, 현재로서는 버전과 타입 정보만 포함한다. 인덱스# 카프카는 컨슈머가 임의의 사용 가능한 오프셋에서부터 메시지를 읽어오기 시작할 수 있도록 한다. 브로커가 주어진 오프셋의 메시지를 빠르게 찾을 수 있도록 하기 위해 인덱스를 저장한다.인덱스는 오프셋과 세그먼트 파일 및 그 안의 위치를 매핑한다. 이와 유사하게, 카프카는 타임스탬프와 메시지 오프셋을 매핑하는 또 다른 인덱스를 가지고 있다.이 인덱스는 타임 스탬프를 기준으로 메시지를 찾을 때 사용된다. 카프카 스트림즈는 타임스탬프 기준 메시지 검색을 광범위하게 사용하며, 몇몇 장애 복구 상황에서도 유용하게 사용될 수 있다. 인덱스들 역시 세그먼트 단위로 분할된다.메시지를 삭제할 때 오래된 인덱스 항목 역시 삭제할 수 있다. 카프카는 인덱스에 체크섬을 유지하거나 하지 않는다.만약 인덱스가 오염될 경우, 해당하는 로그 세그먼트에 포함된 메시지들을 다시 읽어서 오프셋과 위치를 기록하는 방식으로 재생성된다. 따라서 필요한 경우, 운영자가 인덱스 세그먼트를 삭제해도 완벽하게 안전하다. 어차피 자동으로 다시 생성되기 때문이다. 압착 보존 정책: 동일 키를 가진 메시지 중 가장 최신 메시지만 유지하고, 중복된 이전 메시지가 있는 세그먼트를 점진적으로 압축 보존 기한과 압착 설정을 동시에 적용하도록 delete,compact 값을 잡아줄 수도 있다.이 정책은 압착된 토픽이 지나치게 크게 자라나는 것으 방지해 줄 뿐만 아니라 일정 기한 지나간 레코드들을 삭제해야 하는 경우 활용될 수 있다. 압착의 작동 원리# 각 로그는 두 영역으로 나누어진다.클린: 이전에 압착된 적이 있던 메시지들이 저장된다. 이 영역은 하나의 키마다 하나의 값만을 포함한다. 더티: 마지막 압착 작업 이후 쓰여진 메시지들이 저장된다. 카프카 시작되었는데 압착 기능이 활성화되어 있을 경우, 각 브로커는 압착 매니저 스레드와 함께 다수의 압착 스레드를 시작시킨다.압착 스레드: 압착 작업을 담당한다. 각 스레드는 전체 파티션 크기 대비 더티 메시지의 비율이 높은 파티션을 골라서 압착한 뒤 클린 상태로 만든다. 파티션을 압착하기 위해서, 클리너 스레드는 파티션의 더티 영역을 읽어서 in-memory 맵을 생성한다.맵의 각 항목은 메시지 키의 16바이트 해시와 같은 키값을 갖는 이전 메시지의 오프셋(8바이트)으로 이루어진다. 카프카를 설정할 때, 압착 스레드가 이 오프셋 맵을 저장하기 위해 사용할 수 있는 메모리 양을 운영자가 잡아 줄 수 있다.이 설정은 전체 압착 스레드가 사용할 수 있는 메모리 총량을 정의한다. 클리너 스레드가 오프셋 맵을 생성한 다음부터는, 클린 세그먼트들을 오래된 것부터 읽어들이면서 오프셋 맵의 내용과 대조한다.해당 메시지의 키값이 오프셋 맵에 존재하지 않는 경우: 클린 세그먼트에 있는 메시지가 최신값이라는 의미이므로 교체용 세그먼트로 복사 해당 메시지의 키값이 오프셋 맵에 존재하는 경우: 최신 메시지가 있다는 의미이므로 해당 메시지는 건너뛴다. 메시지 복사가 끝나면, 압착 스레드는 교체용 세그먼트와 원본 세그먼트를 바꾼 뒤 다음 세그먼트로 계속 진행한다. 작업이 완료되면, 키별로 하나의 메시지만이 남게 된다. 삭제된 이벤트# 방법1: 가장 최근 메시지조차도 남기지 찮고 시스템에서 특정 키를 완전히 삭제하려면, 해당 키값과 null 밸류값을 메시지를 써주면 된다.클리너 스레드가 이 메시지를 발견하면 평소대로 압착 작업을 한뒤 null 밸류값을 갖는 메시지만 보존할 것이다. 카프카는 사전에 설정된 기간동안 특별한 메시지(툼스톤)로 보존한다. 컨슈머는 툼스톤 메시지를 보고 해당 밸류가 삭제되었음을 알 수 있다. 기간이 지나면 클리너 스레드는 툼스톤 메시지를 삭제하며, 해당 키 역시 카프카 메시지에서 완전히 삭제되게 될 것이다.컨슈머가 툼스톤 메시지를 실제로 볼 수 있도록 충분한 시간을 주는 것이 중요하다. 방법2: 카프카 어드민 클라이언트에서 deleteRecords 메서드를 호출한다.이 메서드는 지정된 오프셋 이전의 모든 레코드를 삭제하는데, 아에 설명한 것과 완전 다른 메커니즘을 사용한다. 이 메서드가 호출되면, 카프카는 파티션의 첫 번째 레코드를 가리키는 ‘로우 워터마크’를 해당 오프셋으로 이동시킨다.이렇게 하면 컨슈머는 업데이트된 로우 워터 마크 이전 메시지를 읽을 수 없게 되므로, 사실상 접근 불가능하게 되는 것이다. 토픽은 언제 압착되는가?# 압착 정책 역시 현재의 액티브 세그먼트를 절대로 압착하지 않는다. 기본적으로, 카프카는 토픽 내용물의 50% 이상이 더티 레코드인 경우에만 압착을 시작한다. 운영자들은 압착이 시작되는 시점을 조절할 수 있다.min.compaction.lag.ms: 메시지가 쓰여진 뒤 압착될 때까지 지나가야 하는 최소 시간을 지정한다.max.compaction.lag.ms: 메시지가 쓰여진 뒤 압착이 가능해질 때까지 딜레이될 수 있는 최대 시간을 지정한다. 이 설정은 특정 기한 안에 압착이 반드시 실행된다는 것을 보장해야 하는 상황에서 자주 사용된다.예) 유럽 연합의 개인정보 보호법인 일반 데이터 보호 규정은 특정한 정보가 삭제가 요청된 지 30일 안에 실제로 삭제될 것은 요구한다. Please enable JavaScript to view the comments powered by Disqus. comments powered by