상속보다는 컴포지션을 사용하라#
간단한 행위 재사용#
- 재사용을 위해 상속을 사용했을 때 단점
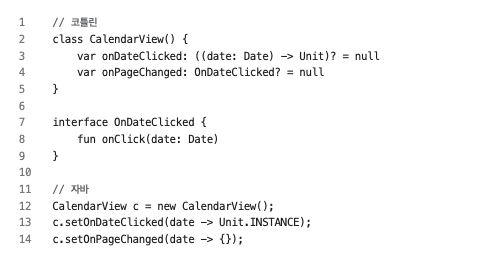
- 상속은 하나의 클래스만을 대상으로 할 수 있다. 상속을 사용해서 행위를 추출하다 보면, 많은 함수를 갖는 거대한 BaseXXX 클래스를 만들게 되고, 굉장히 깊고 복잡한 계층 구조가 만들어진다.
- 상속은 클래스의 모든 것을 가져오게 된다. 따라서 불필요한 함수를 갖는 클래스가 만들어질 수 있다.
- 상속은 이해하기 어렵다. 작동 방식을 이해하기 위해 슈퍼클래스를 여러 번 확인해야 한다.
- 재사용을 위해 컴포지션을 사용했을 때 장점
- 코드의 실행을 더 명확하게 예측할 수 있다.
- 하나의 클래스 내부에서 여러 기능을 재사용할 수 있다.
모든 것을 가져올 수밖에 없는 상속#
- 클래스의 일부분만 재사용하기 위한 목적으로는 컴포지션을 사용하는 것이 좋다.
- 상속은 인터페이스 분리 원칙에 위반되고, 슈퍼클래스의 동작을 깨버리므로 리스코프 치환 원칙에도 위반된다.
- 만약 타입 계층 구조를 표현해야 한다면, 인터페이스를 활용해서 다중 상속을 하는 것이 좋을 수도 있다.
캡슐화를 깨는 상속#
- 상속을 사용하면 내부적인 구현 방법 변경에 의해 클래스의 캡슐화가 깨질 수 있다.
- 상속 대신 컴포지션을 사용하게 되면 다형성이 사라지는데, 이는 위임 패턴을 사용해서 해결할 수 있다.
- 위임 패턴: 클래스가 인터페이스를 상속받게 하고, 포함한 객체의 메서드들을 활용해서, 인터페이스에서 정의한 메서드를 구현하는 패턴
- 포워딩 메서드: 위임 패턴을 통해 구현된 메서드
- 코틀린에서는 위임 패턴을 쉽게 구현할 수 있는 문법을 제공한다.
class CounterSet<T>(
private val innerSet: MutableSet<T> = mutableSetOf()
) : MutableSet<T> by innerSet {
var elementsAdded: Int = 0
private set
override fun add(element: T): Boolean {
elementsAdded++
return innerSet.add(element)
}
override fun addAll(elements: Collection<T>): Boolean {
elementsAdded += elements.size
return innerSet.addAll(elements)
}
}
오버라이딩 제한하기#
- 개발자가 상속용으로 설계되지 않은 클래스를 상속하지 못하게 하려면,
final을 사용하면 된다. open 클래스는 open 메서드만 오버라이드할 수 있다.
데이터 집합 표현에 data 한정자를 사용하라#
data 한정자를 붙이면, 다음과 같은 몇 가지 함수가 자동으로 생성된다.toStringequals와 hashCodecopycomponentN(component1, component2 등)
componentN 함수로 객체를 해제할 때 단점- 위치를 잘못 지정하면, 문제가 발생할 수 있다.
- 읽는 사람에게 혼동을 줄 수 잇다. 특히 람다 표현식과 함께 활용될 때 문제가 된다.
튜플 대신 데이터 클래스 사용하기#
Pair와 Triple은 몇 가지 지역적인 목적으로 인해 남아있다.- 값에 간단하게 이름을 붙일 때
- 표준 라이브러리에서 볼 수 있는 것처럼 미리 알 수 없는 aggregate(집합)를 표현할 때
- 위 경우를 제외하면 무조건 데이터 클래스를 사용하는 것이 좋다.
- 데이터 클래스를 사용했을 때 장점
- 데이터 클래스를 리턴 함수가 있다면, 함수의 리턴 타입이 더 명확해지고 전달하기 쉬워진다. 또한, 사용자가 데이터 클래스에 적혀있는 것과 다른 이름을 활용해 변수를 해제하면, 경고가 출력된다.
- 데이터 클래스를 좁은 스코프를 갖게 하고 싶다면, 가시성에 재한을 걸어 둘 수 있다.
연산 또는 액션을 전달할 때는 인터페이스 대신 함수 타입을 사용하라#
- SAM(Single-Abstract Method): 메서드가 하나만 있는 인터페이스
- 연산 또는 액션을 전달할 때 SAM 대신 함수 타입을 사용하면 얻는 장점
- 람다 표현식 또는 익명 함수로 전달이 가능하다.
- 함수 레퍼런스 또는 제한된 함수 레퍼런스로 전달이 가능하다.
- 선어된 함수 타입을 구현한 객체로 전달이 가능하다.
- type alias 를 사용하면, 함수 타입도 이름을 붙일 수 있다.
- 이름을 붙이면, IDE의 지원을 받을 수 있다.
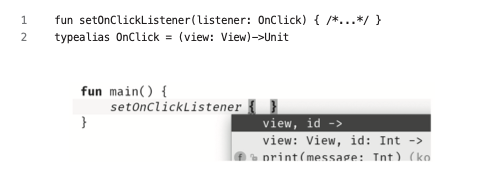
언제 SAM을 사용해야 할까?#
- 코틀린이 아닌 다른 언어(자바)에서 사용할 클래스를 설계할 때
- 함수 타입으로 만들어진 클래스는 자바에서 타입 별칭칭과 IDE의 지원 등을 제대로 받을 수 없다.
- 코틀린 함수 타입에서
Unit을 리턴하는 경우, 다른 언어에서는 명시적으로 Unit을 리턴해야된다.
태그 클래스보다는 클래스 계층을 사용하라#
- 큰 프로젝트에서 상수 모드를 가진 클래스를 많이 볼 수 있다.
- 이런 상수 모드를 ‘태그’라고 부른다.
- 태그 클랫: 태그를 포함한 클래스
- 태그 클래스의 문제점: 서로 다른 책임을 한 클래스에 태그로 구분해서 넣는다.
- 한 클래스에 여러 모드를 처리하기 위한 bilerplate가 추가된다.
- 여러 목적으로 사용되므로 프로퍼티가 일관적이지 않게 사용될 수 있으며, 더 많은 프로퍼티가 필요하다.
- 여러 목적으로 사용되므로 상태의 일관성과 정확성을 지키기 어렵다.
- 팩토리 메서드를 사용해야 하는 경우가 많다.
- 태그 클래스대신 sealed 클래스를 많이 사용하자.
sealed 한정자#
sealed 대신 abstract 한정자를 사용할 수도 있지만, sealed 한정자는 외부 파일에서 서브클래스를 만드는 행위를 제한한다.- 따라서,
when을 사용할 때 else 브랜치를 따로 만들 필요가 없다.
태그 클래스와 상태 패턴의 차이#
- 차이점
- 상태는 더 많은 책임을 가진 큰 클래스다.
- 상태는 변경할 수 있다.
- 상태 패턴도 sealed 클래스 계층으로 만들 수 있다.
- immutable 객체로 만들어, 변경할 때마다
state 프로퍼티를 변경하게 만든다. 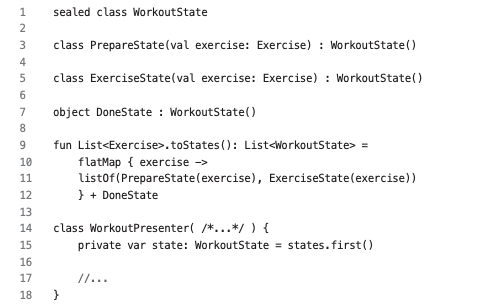
- 상태 패턴의 상태 변화를 관찰할 수 있다.
equals 규약을 지켜라#
동등성#
- 코틀린의 두가지 종류의 동등성
- 구조적 동등성:
equals 메서드와 이를 기반으로 만들어진 == 연산자로 확인하는 동등성. - 레퍼런스적 동등성:
=== 연산자로 확인하는 동등성. 두 피연산자가 같은 객체를 가리키면, true를 리턴한다.
equals가 필요한 이유#
data 한정자를 붙이면, 자동으로 기본 생성자의 프로퍼티들을 비교해서 동등성을 비교한다.- 기본 생성자에 선언되지 않은 프로퍼티는
copy로 복사되지 않기 때문에 동등성 비교에 사용되지 않는다. equals를 직접 구현해야 하는 경우- 기본적으로 제공되는 동작과 다른 동작을 해야 하는 경우
- 일부 프로퍼티만으로 비교해야 하는 경우
data 한정자를 붙이는 것을 원하지 않거나, 비교해야 하는 프로퍼티가 기본 생성자에 없는 경우
equals의 규약#
- 반사적 동작: x가 null이 아닌 값이라면,
x.equals(x)는 true를 리턴해야 한다. - 대칭적 동작: x와 y가 널이 아닌 값이라면,
x.equals(y)는 y.equals(x)와 같은 결과를 출력해야 한다. - 연속적 동작: x, y, y가 널이 아닌 값이고
x.equals(y)와 y.equals(z)가 true라면, x.equals(z)도 true 여야 한다. - 일관적 동작: x와 y가 널이 아닌 값이라면,
x.equals(y)는 여러 번 실행하더라도 항상 같은 결과를 리턴해야 한다. - 널과 관련된 동작: x가 널이 아닌 값이라면,
x.equals(null)은 항상 false를 리턴해야 한다. equals, toString, hashCode의 동작은 매우 빠를 거라 예측되므로, 빠르게 동작해야 한다.
URL과 관련된 equals 문제#
java.net.URL은 잘못 설계한 예다.
- 위 코드는 상황에 따라서 결과가 달라진다.
- 일반적인 상황에서는 두 주소가 같은 IP 주소를 나타내므로
true를 출력한다. - 인터넷 연결이 끊겨 있으면
false를 출력한다.
- 문제점
- 동작이 일관되지 않는다.
equals, hashCode 처리가 굉장히 느린다.- 동작 자체에 문제가 있다. 동일한 IP 주소를 갖는다고, 동일한 콘텐츠를 나타내는 것이 아니다.
equals 구현하기#
- 가능하면 직접
equals를 구현하지 않는 것이 좋다.- 기본적으로 제공되는 것을 그대로 쓰거나, 데이터 클래스를 만들어서 사용하느 ㄴ것이 좋다.
- 직접 구현했다면 규약을 지켰는지 확인해야된다.
- 직접 구현헀다면 final 클래스로 만들어야된다.
hashCode 규약을 지켜라#
hashCode 함수는 수많은 컬렉션과 알고리즘에 사용되는 자료 구조인 해시 테이블을 구축할 때 사용된다.
해시 테이블#
- 동일한 요소가 이미 들어 있는지 확인해야 하는 경우, 해시 테이블이 유리하다.
- 해시 함수의 특성
- 코틀린에 있는 기본 세트(
LinkedHashSet)와 기본 맵(LinkedHashMap)도 이를 사용한다. - 일반적으로
hashCode 함수가 Int를 리턴하므로, 32비트 부호 있는 정수만큼의 버킷이 만들어진다.- 한두 개의 요소만 포함할 세트로는 너무 큰 크기이므로, 기본적으로 숫자를 더 작게 만드는 변환을 사용하닥, 필요한 경우 변환 방법을 바꿔서 해시 테이블을 크게 만들고, 요소를 재배치한다.
가변성과 관련된 문제#
- 요소가 추가될 때만 해시 코드를 계산한다.
- 요소가 변경되어도 해시 코드는 계산되지 않으며, 버킷 재배치도 이루어지지 않는다.
- 세트와 맵의 키로 mutable 요소를 사요하면 안 되며, 사용하더라도 요소를 변경해서는 안된다.
hashCode의 규약#
- 어떤 객체를 변경하지 않았다면, hashCode는 여러 번 호출해도 그 결과가 항상 같아야된다.
equals 메서드의 실행 겨로가로 두 객체가 같다고 나온다면, hashCode 메서드의 호출 결과도 같다고 나와야 한다.- 필수 요구 사항은 아니지만,
hashCode는 최대한 요소를 넓게 퍼뜨려야 한다.
hashCode 구현하기#
- 일반적으로
data 한정자를 붙이면, 코틀린이 알아서 적당한 equals와 hashCode를 정의해 준다. equals를 따로 정의 했다면, hashCode는 equals에서 비교에 사용되는 프로퍼티를 기반으로 해시 코드를 만들어야 한다.- 관례적으로, 이전 프로퍼티의 해시 코드 값에 31을 곱한 뒤 해시 코드의 값을 더한다.
- 코틀린/JVM의
Objects.hashCode를 활용할 수 있다. 
compareTo의 규약을 지켜라#
compareTo는 수학적인 부등식으로 변환되는 연산자다.compareTo는 다음과 같이 동작해야 한다.- 비대칭적 동작: a >= b이고 b >= a라면, a == b 여야 하며, 서로 일관성이 있어야 한다.
- 연속적 동작: a >= b이고 b >= c 라면, a >= c여야 한다. 마찬가지로 a > b 이고 b > c라면, a > c 여야 한다.
- 코넥스적 동작: 두 요소는 확실환 관계를 갖고 있어야 한다. 즉, a >= b 또는 b >= a 중에 적어도 하나는 항상 true여야 한다.
compareTo를 따로 정의해야 할까?#
- 코틀린에서
compareTo를 따로 정의해야 하는 상황은 거의 없다. sortedBy를 사용하면, 원하는 키로 컬렉션을 정렬할 수 있다.- 여러 프로퍼티를 기반으로 정렬해야 한다면
sortedWith 함수를 사용하면 된다.compareBy를 활용해 comparator를 만들 수 있다.
- 직관적이지 않는 부등호 기호를 기반으로 두 문자열을 비교하는 코드를 작성하지 않게 유의해야된다.
compareTo 구현하기#
compareTo를 구현할 때 유용하게 활용할 수 있는 compareValues 톱레벨 함수가 있다.comrapreTo의 리턴의 의미- 0: 리시버와 other가 같은 경우
- 양수: 리시버가 other보다 큰 경우
- 음수: 리시버가 other보다 작은 경우
API의 필수적이지 않는 부분은 확장 함수로 추출하라#
- 일반 함수와 확장 함수의 차이
- 확장은 다른 패키지에 위치해, 따로 가져와야 된다.
- virtual이 아니다. 즉, 파생 클래스에서 오버라이드할 수 없다. 확장 함수는 컴파일 시점에 정적으로 선택된다. (확장 함수는 ‘첫 번째 아규먼트로 리시버가 들어가는 일반 함수’로 컴파일된다.)
- 확장 함수는 클래스가 아닌 타입에 정의하는 것이다. 그래서 nullable 또는 구체적인 제네릭 타입에도 확장 타입을 정의할 수 있다.
- 확장은 클래스 레퍼런스에서 멤버로 표시되지 않는다. 그래서 확장 함수는 어노테이션 프로세서가 따로 처리하지 않는다.
멤버 확장 함수의 사용을 피하라#
- 아래 사진과 같이 확장 함수를 클래스의 멤버나 인터페이스 내부에 정의하는 것은 DSL을 만들 때를 제외한다면 피해야된다.
- 가시성 제한을 위해 확장 함수를 멤버로 정의하는 것의 문제점
- 가시성을 제한하지 못한다.
- 확장 함수의 가시성을 제한하고 싶다면, 멤버로 만들지 말고, 가시성 한정자를 붙여 주면 된다.
- 멤버 확장을 피해야 하는 이유
- 레퍼런스를 지원하지 않는다.
- 암묵적 접근을 할 때, 두 리시버 중 어떤 리서버가 선택될지 혼동된다.
- 확장 함수가 외부에 있는 다른 클래스를 리시버로 받을 때, 해당 함수가 어떤 동작을 하는지 명확하지 않다.
- 경험이 적은 개발자의 경우 확장 함수를 보면, 직관적이지 않다.