분산 시스템을 설계할 떄는 CAP 정리(Consistency, Availability, Partition Tolerance theorem)를 이해하고 있어야 한다.
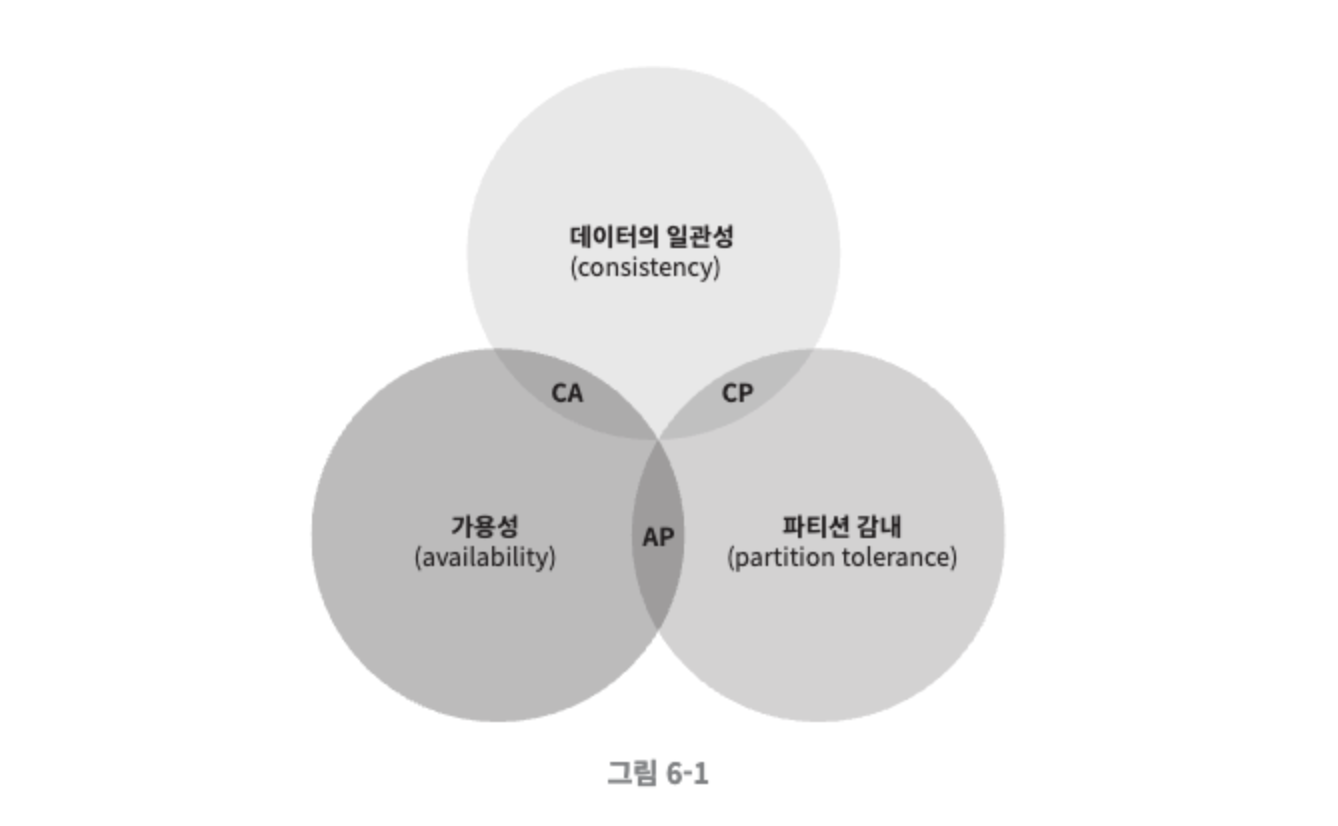
CAP 정리: 데이터 일관성, 가용성, 파티션 감내라는 세 가지 요구사항을 동시에 만족하는 분산 시스템을 설계하는 것은 불가능하다.
데이터 일관성: 분산 시스템에 접속하는 모든 클라이언트는 어떤 노드에 접속했느냐에 관계없이 언제나 같은 데이터를 보게 되어야 한다.
가용성: 분산 시스템에 접속하는 클라이언트는 일부 노드에 장애가 발생하더라도 항상 응답을 받을 수 있어야한다.
파티션 감내: 파티션은 두 노드 사이에 통신 장애가 발생하였음을 의미한다. 파티션 감내는 네트워크에 파티션이 생기더라도 시스템은 계속 동작하여야 한다.
CP 시스템: 일관성과 파티션 감내를 지원하는 키-값 저장소. 가용성을 희생한다.
AP 시스템: 가용성과 파티션 감내를 지원하는 키-값 저장소. 데이터 일관성을 희생한다.
CA 시스템: 일관성과 가용성을 지원하는 키-값 저장소. 파티션 감내는 지원하지 않는다. 그러나 통상 네트워크 장애는 피할 수 없는 일로 여겨지므로, 분산 시스템은 반드시 파티션 문제를 감내할 수 있도록 설계되어야 한다. 그러므로 CA 시스템은 존재하지 않는다.
키-값 저장소 구현에 사용될 핵심 컴포넌트 및 기술
데이터 파티션: 대규모 애플리케이션에서 전체 데이터를 한 대 서버에 욱여넣는 것은 불가능하다. 가장 단순한 해결책은 데이터를 작은 파티션들로 분할한 다음 여러 대 서버에 저장하는 것이다.
안정 해시를 이용해 데이터를 여러 서버에 고르게 분산하고, 노드가 추가/삭제될 때 데이터으 이동을 최소화할 수 있다.
데이터 다중화: 높은 가용성과 안정성을 확보하기 위해서는 데이터를 N개 서버에 비동기적으로 다중화할 필요가 있다.
여기서 N은 튜닝 가능한 값이다.
어떤 키를 해시 링 위에 배치한 후, 그 지점으로부터 시계 방향으로 링을 순회하면서 만나는 첫 N개 서버에 데이터 사본을 보관하는 것이다.
가상 노드를 사용한다면 노드를 선택할 때 같은 물리 서버를 중복 선택하지 않도록 해야 한다.
데이터 일관성: 여러 노드에 다중화된 데이터는 적절히 동기화가 되어야 한다. 정족수 합의 프로토콜을 사용하면 읽기/쓰기 연산 모두에 일관성을 보장할 수 있다.
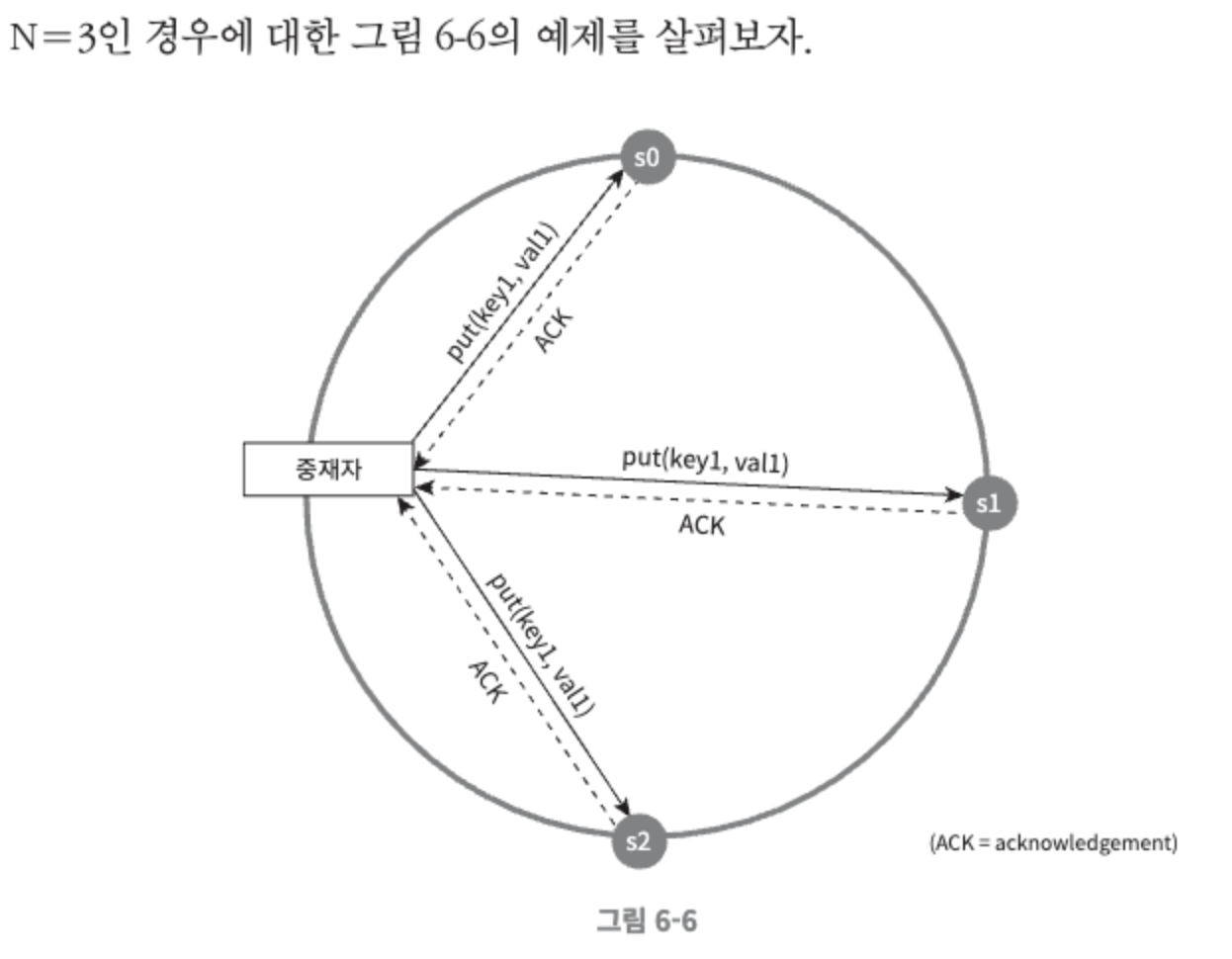
N=사본 개수
W=쓰기 연산에 대한 정족수. 쓰기 연산이 성공한 것으로 간주되려면 적어도 W개의 서버로부터 쓰기 연산이 성공했따는 응답을 받아야 한다.
R=읽기 연산에 대한 정족수. 읽기 연산이 성공한 것으로 간주되려면 적어도 R개의 서버로부터 응답을 받아야 한다.
중재자(coordinator)는 클라이언트와 노드 사이에서 프록시 역할을 한다.
W=1의 의미는, 데이터가 한 대 서버에만 기록된다는 뜻이 아니다. 쓰기 연산이 성동했다고 판단하기 위해서 중재자는 최소 한 대 서버로부터 쓰기 성공 응답을 받아야 한다는 뜻이다.
R=1, W=N: 빠른 읽기 연산에 최적화된 시스템
W=1, R=N: 빠른 쓰기 연산에 최적화된 시스템
W+R>N: 강한 일관성이 보장됨(보통 N=3, W=R=2)
W+R<=N: 강한 일관성이 보장되지 않음
일관성 모델
강한 일관성: 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환한다. 클라이언트는 절대로 낡은 데이터를 보지 못한다.
모든 사본에 현재 쓰기 연산의 결과가 반영될 때까지 해당 데이터에 대한 읽기/쓰기를 금지하는 것이다. 이 방법은 고가용성 시스템에는 적합하지 않다.
약한 일관성: 읽기 연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있다.
최종 일관성: 약한 일관성의 한 형태로, 갱신 결과가 결국에는 모든 사봄에 반영되는 모델이다.
다이나모 또는 카산드라 같은 저장소는 최종 일관성 모델을 택하고 있다.
비 일관성 해소 기법(버저닝과 벡터 시계)
데이터를 다중화하면 가용성은 높아지지만 사본 간 일관성이 깨질 가능성은 높아진다. 버저닝과 백터 시계는 그 문제를 해소하기 위해 등장한 기술이다.
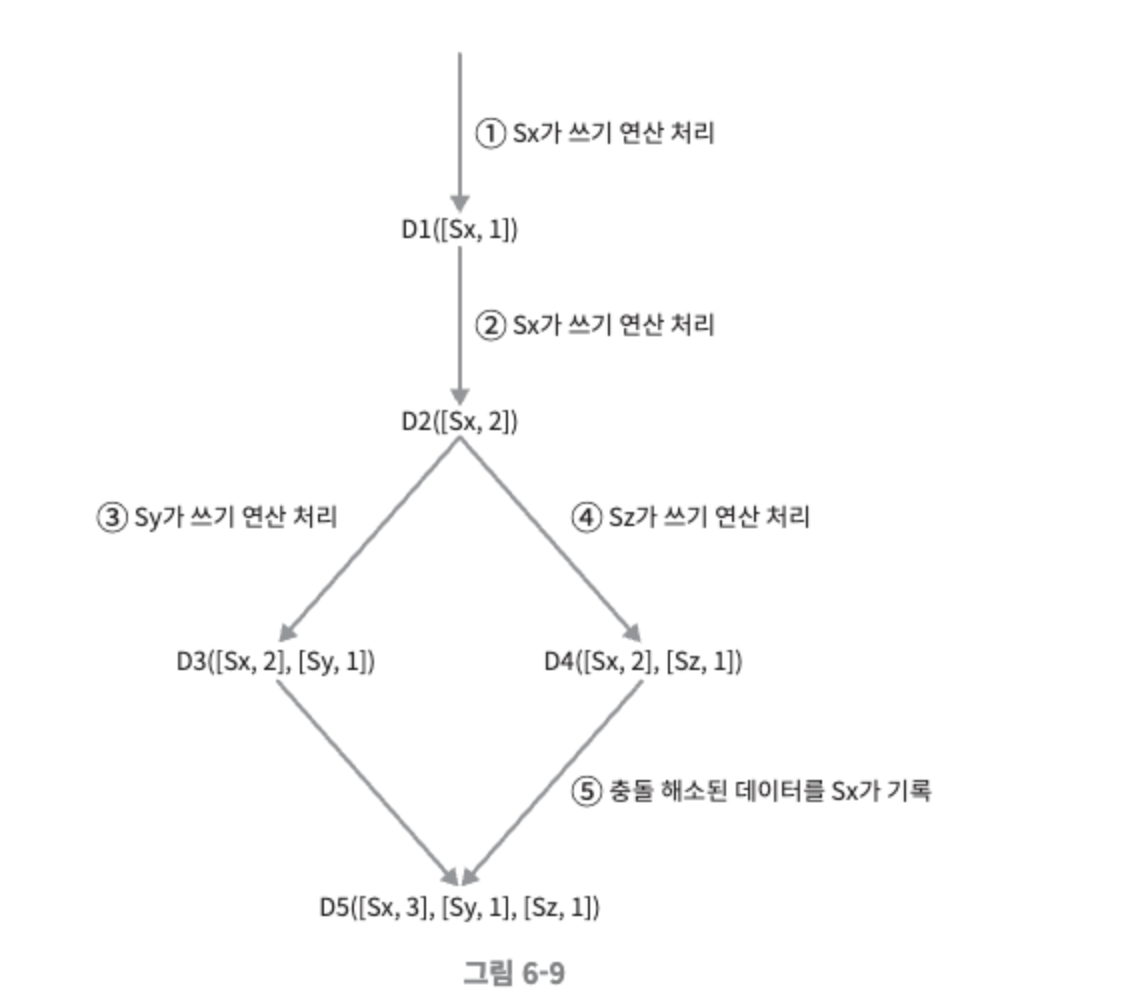
백터 시계는 [서버, 버전]의 순서쌍을 데이터에 매단 것이다.
백터 시계는 D([S,1 v1], [S2, v2], …, [Sn,vn])와 같이 표현한다고 가정하자. 여기서 D는 데이터이고, vi는 버전 카운터, Si는 서버 번호이다.
데이터 D를 서버Si에 기록하면, 시스템은 아래 작업 가운데 하나를 수행하여야 한다.
[Si, vi]가 있으면 vi를 증가시킨다.
그렇지 않으면 새 항목 [Si, 1]를 만든다.
어떤 버전 Y에 포함된 모든 구성요소의 값이 X에 포함된 모든 구성요소 값보다 같거나 크면, X가 Y의 이전버전이다.
어떤 버전 Y의 구성요소 가운데 X의 벡터 시계 동일 서버 구성요소보다 작은 값을 갖는 것이 있으면 충돌이 있따.(물론 모든 구성요소가 작은 값을 갖는 경우에는 Y는 X의 이전 버전이다.)
벡터 시계를 이용한 충돌 감지 및 해소의 단점
충돌 감지 및 해소 로직이 클라이언트에 들어가야 하므로, 클라이언트 구현이 복잡해진다.
[서버: 버전]의 순서쌍 개수가 굉장히 빨리 늘어난다.
이 문제를 해결하려면 그 길이에 어떤 임계치를 설정하고, 임계치 이상으로 길이가 길어지면 오래된 순서쌍을 벡터 시계에서 제거하도록 해야 한다.
그러나 이렇게 하면 버전 선후 관계가 정확하게 결정될 수 없기 때문에 충돌 해소 과정의 효율성이 낮아지게 된다.
실제 아마존 서비스에서 이런 문제가 발생한적이 없다고 한다. 그러니 기업에서 벡터 시계는 적용해도 괜찮은 솔루션일 것이다.
장애 감지
분산 시스템에서는 그저 한 대 서버가 “지금 서버 A가 죽었습니다"라고 한다해서 바로 서버 A를 장애처리 하지는 않는다.
보통 두 대 이상의 서버가 똑같이 서버 A의 장애를 보고해야 해당 서버에 실제로 장애가 발생했다고 간주한다.
모든 노드 사이에 멀티캐스팅 채널을 구축하여 서버 장애를 감지하는 것이 손쉬운 방법이지만, 서버가 많을 때는 비효율적이다.
가십 프로토콜(gossip protocol) 같은 분산형 장애 감지 솔류션을 채택하는 편이 보다 효율적이다.
각 노드는 멤버십 목록을 유지한다. 멤버십 목록은 각 멤버 ID의 그 박동 카운터 쌍의 목록이다.
각 노드는 주기적으로 자신의 박동 카운터를 증가시킨다.
각 노드는 무작위로 선정된 노드들에게 주기적으로 자기 박동 카운터 목록을 보낸다.
박동 카운터 목록을 받은 노드는 멤버십 목록을 최신 값으로 갱신한다.
어떤 멤버의 박동 카운터 값이 지정된 시간 동안 갱신되지 않으면 해당 멤버는 장애 상태인 것으로 간주한다.
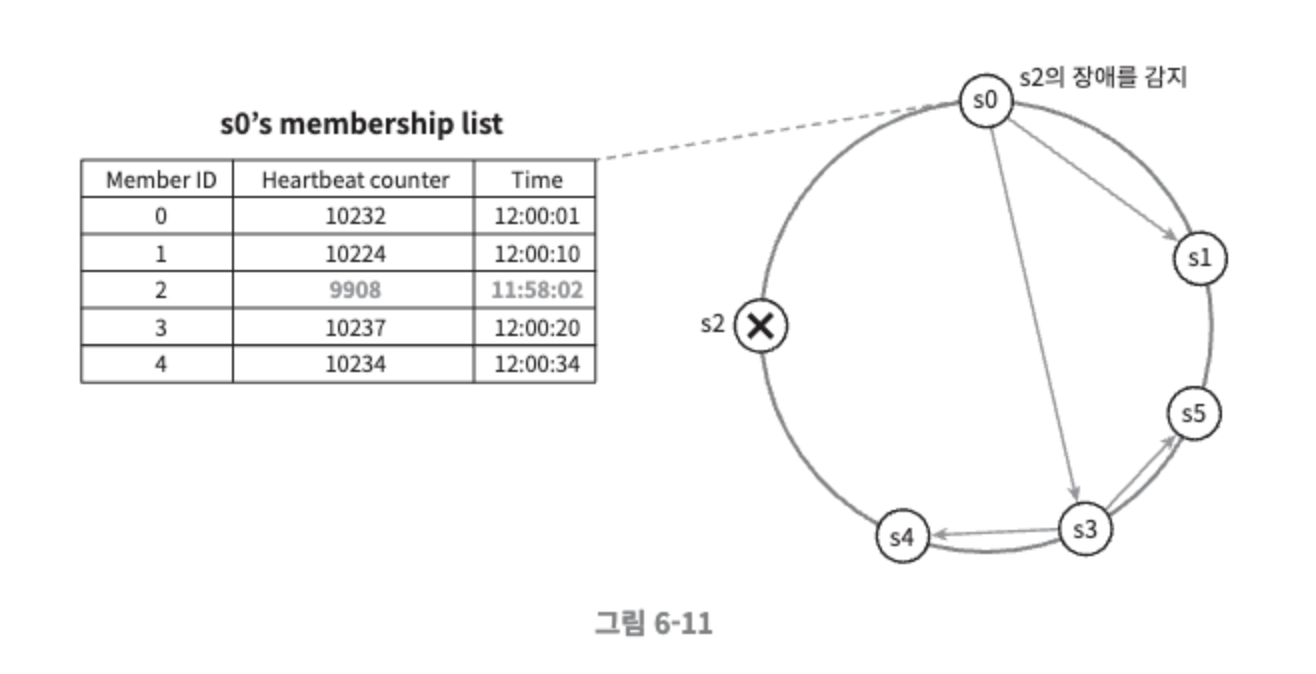
노드 s0는 그림 좌측의 테이블과 같은 멤버십 목록을 가진 상태이다.
노드 s0는 노드 s2의 박동 카운터가 오랫동안 증가되지 않았다는 것을 발견한다.
노드 s0는 노드 s2를 포함하는 박동 카운터 목록을 무작위로 선택된 다른 노드에게 전달한다.
노드 s2의 박동 카운터가 오랫동안 증가되지 않았음을 발견한 모든 노드는 해당 노드를 장애 노드로 표시한다.
일시적 장애 처리
가십 프로토콜로 장애를 감지한 시스템은 가용성을 보장하기 위해 필요한 조치를 해야 한다.
엄격한 정족수 접근법을 썬드면, 읽기와 쓰기 연산을 금지해야 할 것 이다.
느슨한 정족수 접근법은 이 조건을 완화하여 가용성을 높인다.
정족수 요구사항을 강제하는 대신, 쓰기 연산을 수행할 W개의 건강한 서버와 읽기 연산을 수행할 R개의 건강한 서버를 해시 링에서 고른다. 장애 상태은 서버는 무시한다.
단서 후 임시 위탁(hinted handoff): 장애 상태인 서버로 가는 요청은 다른 서버가 잠시 맡아 처리하고, 그동안 발생한 변경사항은 해당 서버가 복구되었을 때 일관 반영하여 데이터 일관성을 보존한다. 이를 위해 임시로 쓰기 연산을 처리한 서버에는 그에 대한 단서를 남겨둔다.
영구 장애 처리
영구적인 노드의 장애 상태를 처리하기 위해서는 우리는 반-엔트로피 프로토콜을 구현하여 사본들을 동기화할 것이다.
반-엔트로피 프로토콜은 사본들을 비교하여 최신 버전으로 갱신하는 과정을 포함한다.
사본 간의 일관성이 망가진 상태를 탐지하고 전송 데이터의 양을 줄이기 위해서는 머클 트리를 사용할 것이다.
머클 트리: 각 노드에 그 자식 노드들에 보관된 값의 해시, 또는 자식 노드들의 레이블로부터 계산된 해시값을 레이블로 붙여두는 트리
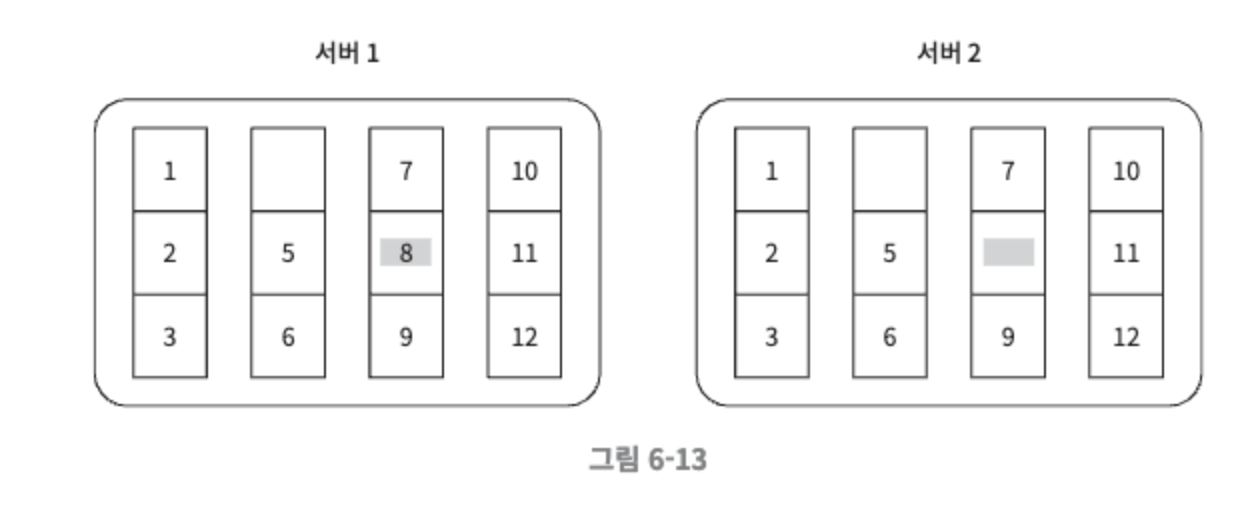
키 공간이 1부터 12까지일 때 머클 트리를 만드는 예시
키 공간을 그림과 같이 버킷으로 나눈다.
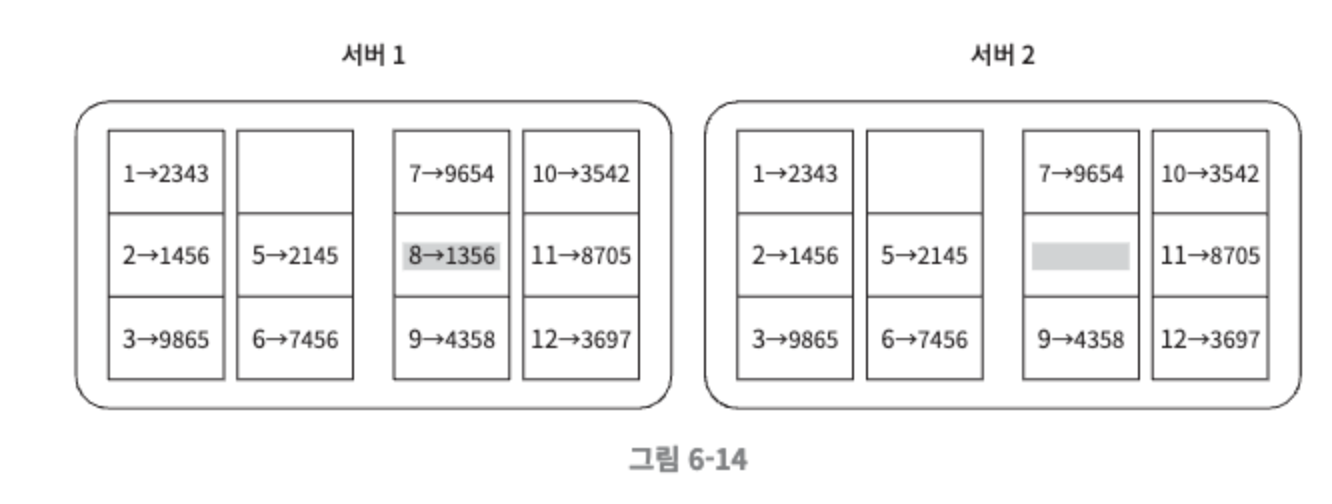
버킷에 포함된 각각의 키에 균등 분포 해시 함수를 적용하여 해시 값을 계산한다.
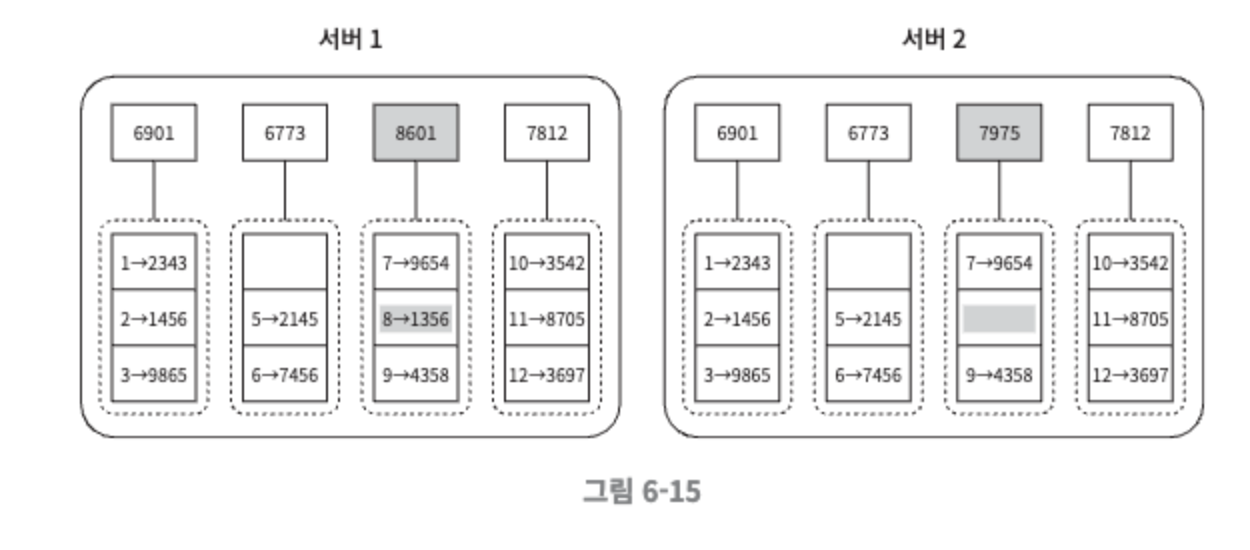
버킷별로 해시값을 계산한 후, 해당 해시 값을 레이블로 갖는 노드를 만든다.
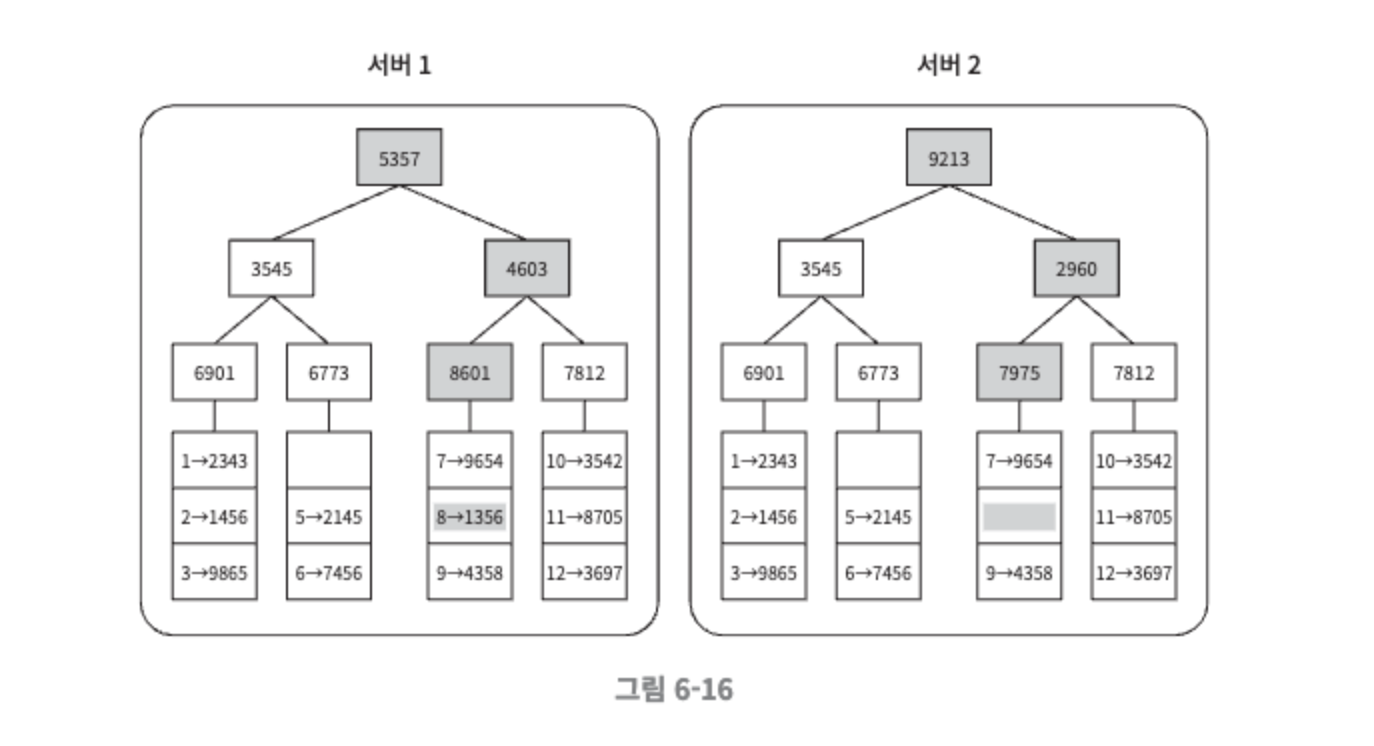
자식 노드의 레이블로부터 새로운 해시 값을 계산하여, 이진 트리를 상향식으로 구성해 나간다.
두 머클 트리의 비교는 루트 노드의 비교하는 것으로 시작하고, 루트 노드의 값이 다른 경우 왼쪽 자식 노드의 해시 값을 비교하고, 그 다음으로 오른쪽 자식 노드의 해시 값을 비교한다. 이렇게 하면 아래쪽으로 나가면서 다른 데이터를 갖는 버킷을 찾을 수 있다. 그 버킷들만 동기화하면 된다.
시스템 아키텍처 다이어그램
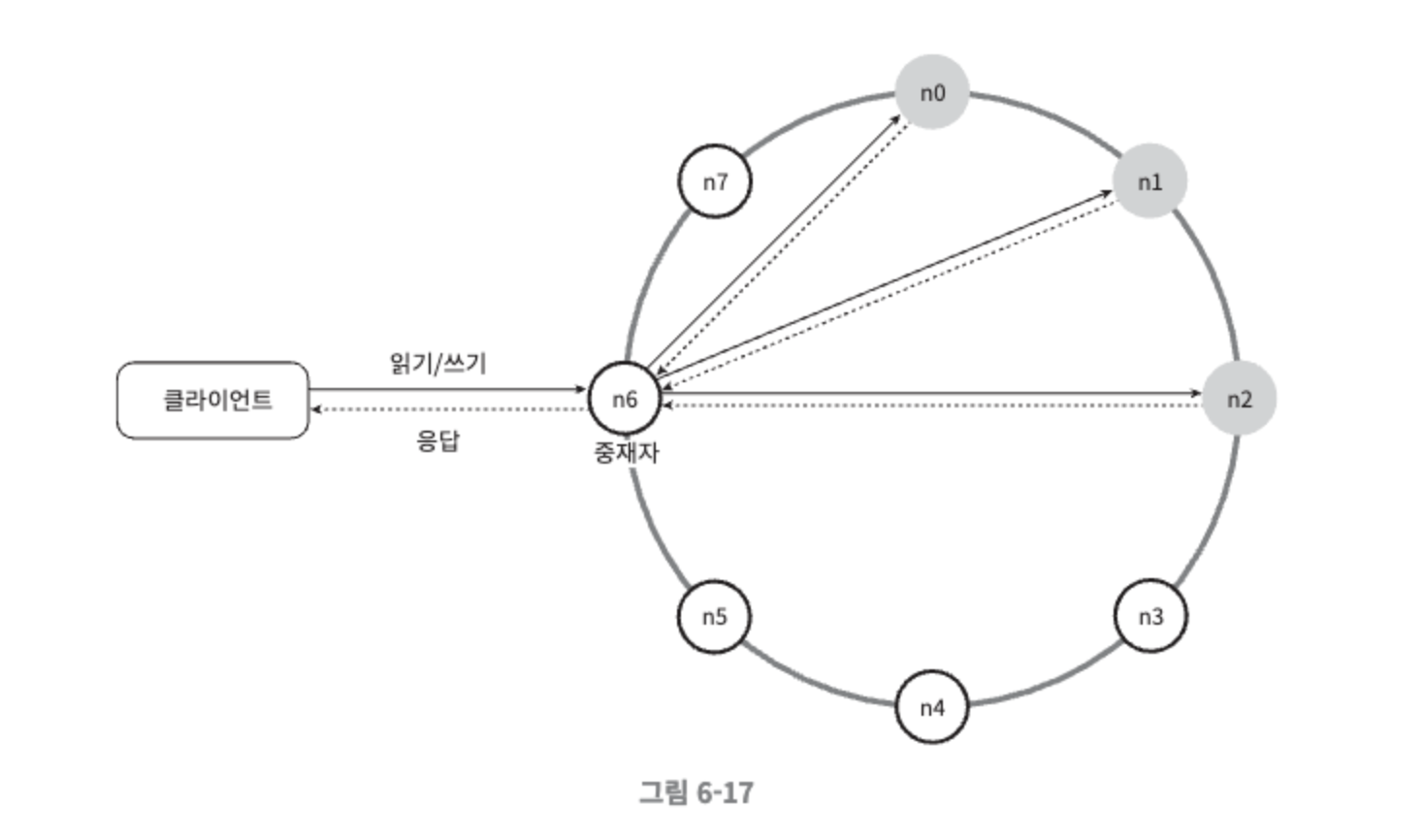
클라이언트는 키-값 저장소가 제공하는 두 가지 단순한 API, 즉 get(key) 및 put(key, value)와 통신된다.
중재자는 클라이언트에게 키-값 저장소에 대한 프록시 역할을 하는 노드다.
노드는 안정 해시의 해시 링 위에 분포한다.
모든 노드가 같은 책임을 지므로, SPOF는 존재하지 않는다.
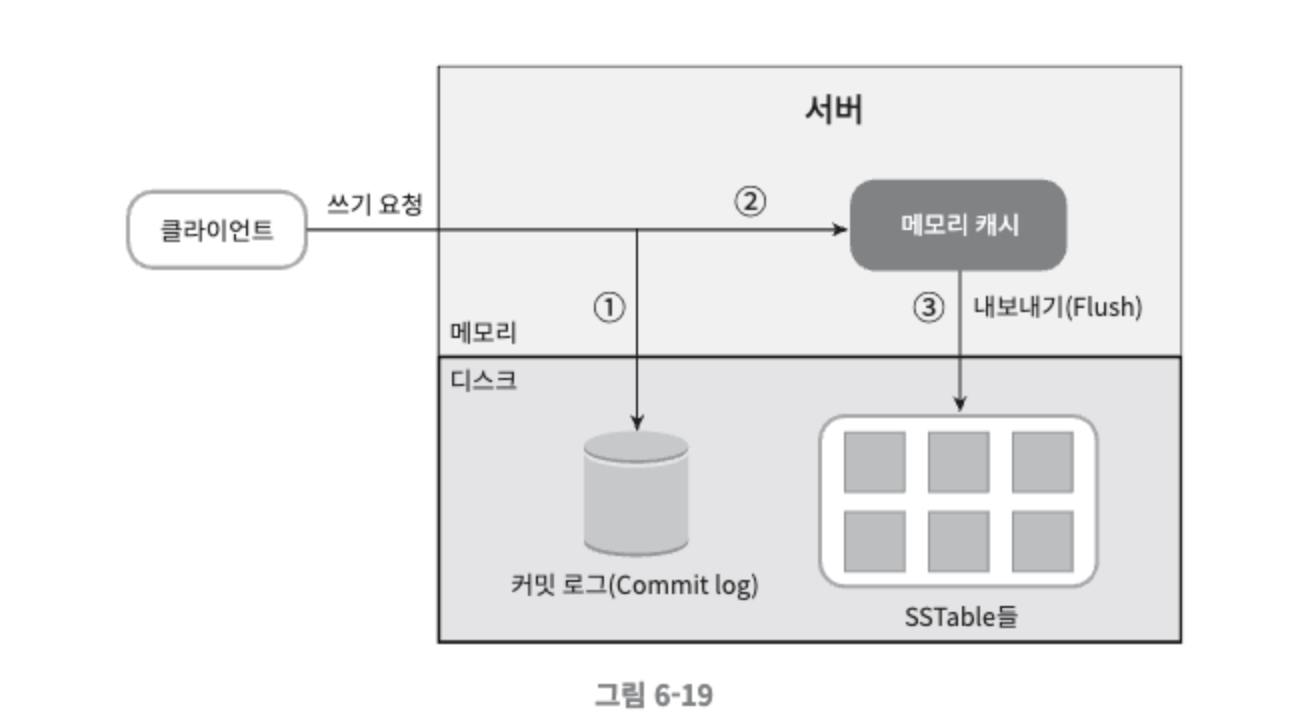
쓰기 경로
쓰기 요청이 특정 노드에 전달되면 커밋 로그 파일에 기록된다.
데이터가 메모리 캐시에 기록된다.
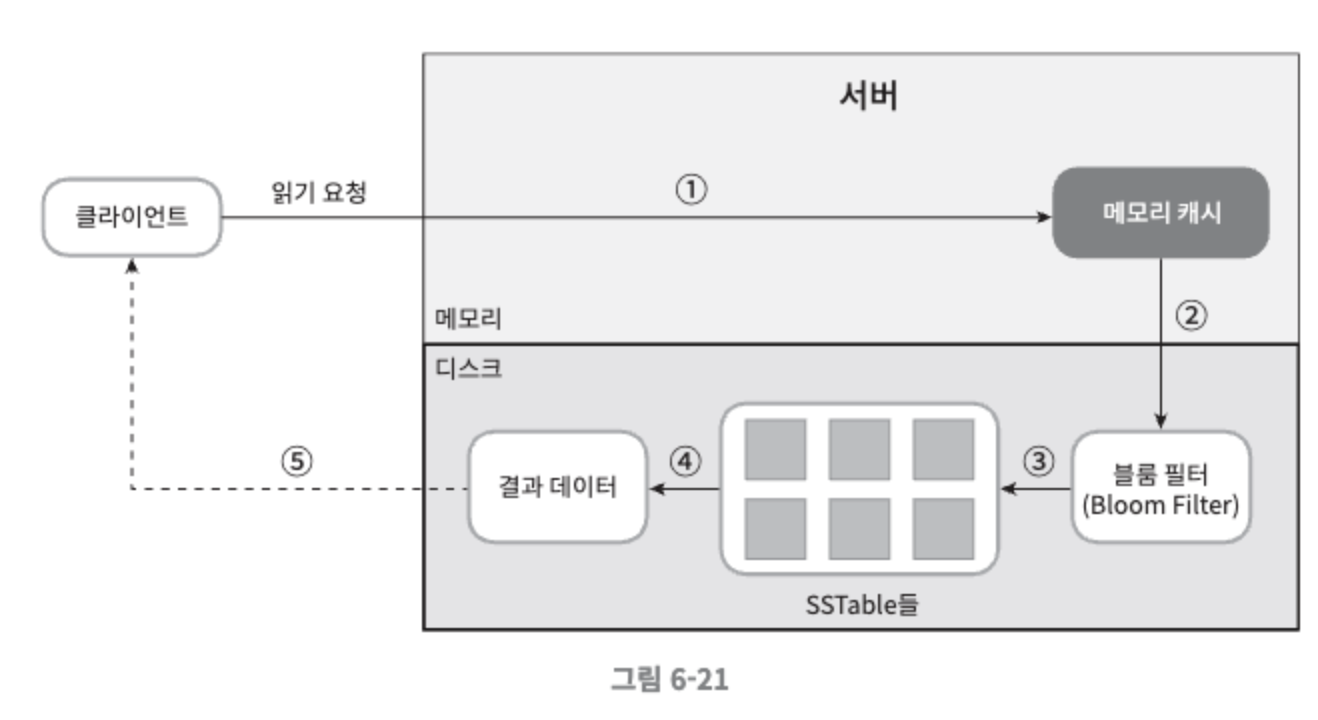
메모리 캐시가 가득차거나 사전에 정의된 어떤 임계치에 도달하면 데이터는 디스크에 있는 SSTable에 기록된다. SSTable은 Sorted-String Table의 약어로, <키, 값>의 순서쌍을 정렬된 리스트 형태로 관리하는 테이블이다.