상속 관계 매핑#
- 관계형 데이터베이스에는 객체지향 언어에서 다루는 상속이라는 개념이 없다.
- 슈퍼타입 서브타입 논리 모델을 실제 물리 모델인 테이블로 구현하는 방법 3가지
- 조인 전략: 모두 테이블로 만들고 조회할 때 조인을 사용한다.
- 단일 테이블 전략: 테이블을 하나만 사용해서 통합한다.
- 구현 클래스마다 테이블 전략: 서브 타입마다 하나의 테이블을 만든다.
조인 전략#
- 엔티티 각각을 모두 테이블로 만들고 자식 테이블이 부모 테이블의 기본 키를 받아서 기본 키 + 외래 키로 사용하는 전략
- 주의 점: 타입을 구분하기 위한 컬럼이 추가 되어야 한다.
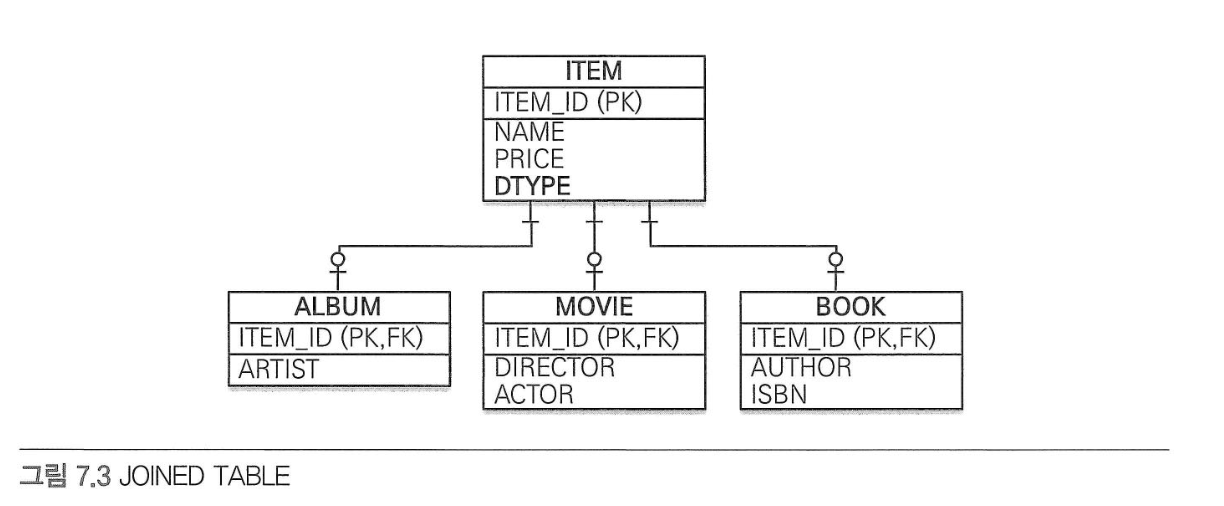

@Inheritance(strategy = InheritanceType.JOINED): 조인 전략 매핑을 사용하기 위한 어노테이션@DiscriminatorColumn(name ="DTYPE"): 구분 컬럼을 지정한다. 이 컬럼으로 저장된 자식 테이블을 구분할 수 있다.@DiscriminatorValue("M"): 엔티티를 저장할 때 구분 컬럼에 입력할 값을 지정한다.
- 자식 테이블의 기본 키 컬럼명을 변경하고 싶으면
@PrimaryKeyJoinColumn을 사용하면 된다. - 장점
- 테이블이 정규화된다.
- 외래 키 참조 무결성 제약조건을 활용할 수 있다.
- 저장공간을 효율적으로 사용한다.
- 단점
- 조회할 때 조인이 많으므로 성능이 저하될 수 있다.
- 조회 쿼리가 복잡하다.
- 데이터를 등록할 때 INSERT SQL을 두 번 실행한다.
단일 테이블 전략#
- 주의 점: 구분 컬럼을 필수로 사용해야 한다.


- 장점
- 조인이 필요 없으므로 일반적으로 조회 성능이 빠르다.
- 조회 쿼리가 단순하다.
- 단점
- 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 한다.
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 그러므로 상황에 따라서는 조회 성능이 오히려 느려질 수 있다.
구현 클래스마다 테이블 전략#
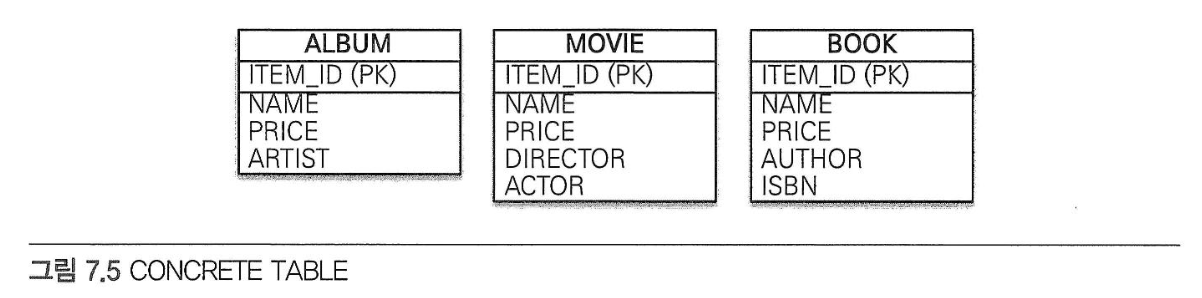
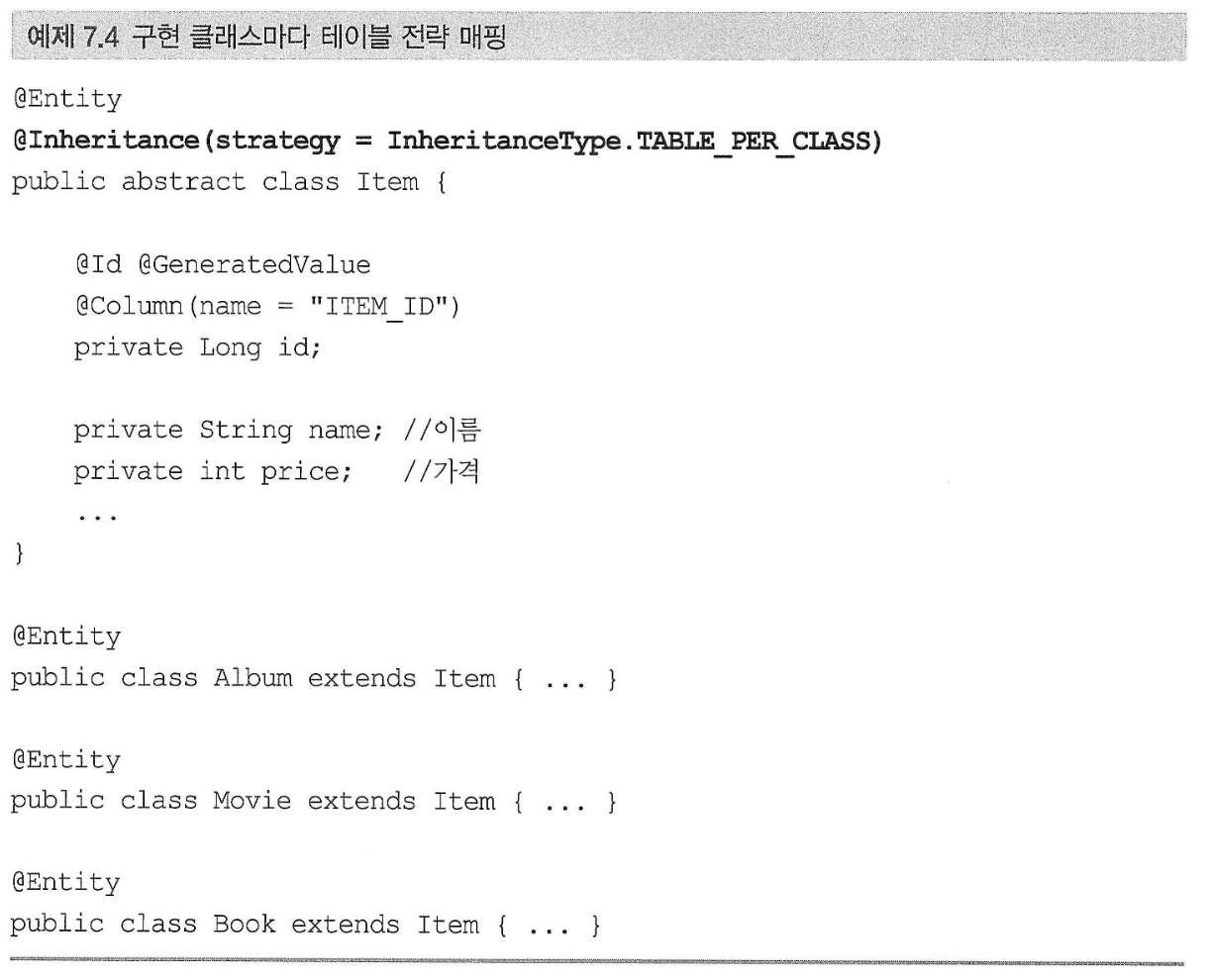
- 장점
- 서브 타입을 구분해서 처리할 때 효과적이다.
not null 제약조건을 사용할 수 있다.
- 단점
- 여러 자식 테이블을 함께 조회할 때 성능이 느리다(SQL에 UNION을 사용해야 한다).
- 자식 테이블을 통합해서 쿼리하기 어렵다.
- 이 전략은 데이터베이스 설계자와 ORM 전문가 둘 다 추천하지 않는 전략이다.
@MappedSuperclass#
- 부모 클래스는 테이블과 매핑하지 않고 부모 클래스를 상속받는 자식 클래스에게 매핑 정보만 제공하고 싶으면
@MappedSuperclass를 사용하면 된다. 
- 부모로부터 물려받은 매핑 정보를 정의하려면
@AttributeOverrides나 @AttributeOverride를 사용하고, 연관관계를 재정의하려면 @AssociationOverrides나 @AssociationOverride를 사용한다. @MappedSuperclass의 특징- 테이블과 매핑되지 않고 자식 클래스에 엔티티의 매핑 정보를 상속하기 위해 사용한다.
@MappedSuperclass로 지정한 클래스는 엔티티가 아니므로 em.find()나 JPQL에서 사용할 수 없다.- 이 클래스를 직접 생성해서 사용할 일은 거의 없으므로 추상 클래스로 만드는 것을 권장한다.
@MappedSuperclass를 사용하면 등록일자, 수정일자, 등록자, 수정자 같은 여러 엔티티에서 공통으로 사용하는 속성을 효과적으로 관리할 수 있다.- 엔티티(
@Entity)는 엔티티(@Entity)이거나 @MappedSuperclass로 지정된 클래스만 상속받을 수 있다.
복합 키와 식별 관계 매핑#
식별 관계 vs 비식별 관계#
- 식별 관계: 부모 테이블의 기본 키를 내려받아서 자식 테이블의 기본 키 + 외래 키로 사용하는 관계
- 비식별 관계: 부모 테이블의 기본 키를 받아서 자식 테이블의 외래 키로만 사용하는 관계
- 필수적 식별 관계: 외래 키에 NULL을 허용하지 않는다. 연관관계를 필수적으로 맺어야 한다.
- 선택적 비식별 관계: 외래 키에서 NULL을 허용한다. 연관관계를 맺을지 말지 선택할 수 있다.
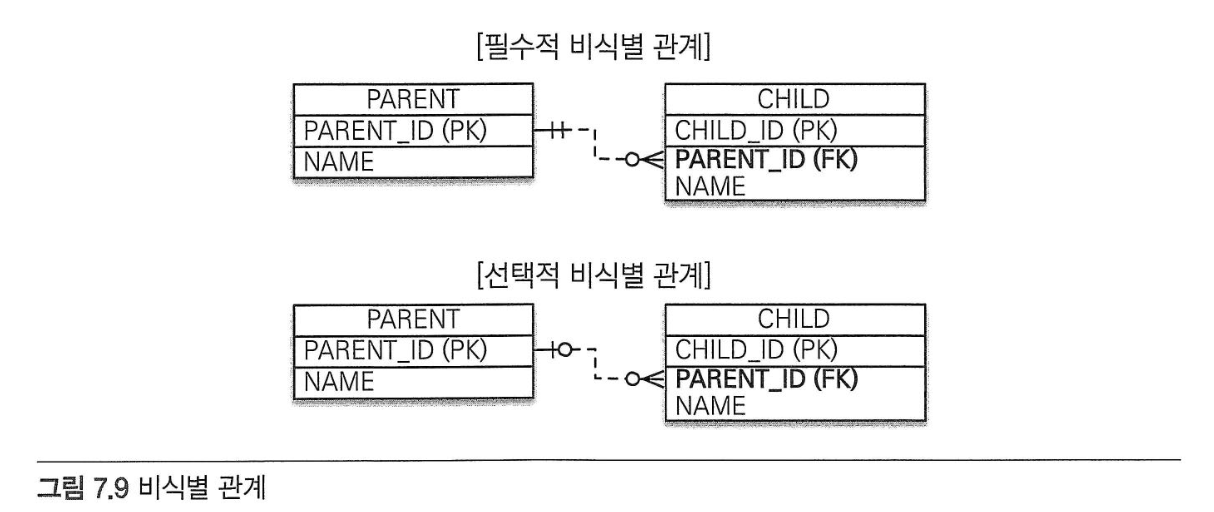
- JPA는 식별 관계와 비식별 관계를 모두 지원한다.
- 최근에는 비식별 관계를 주로 사용하고 꼭 필요한 곳에만 식별 관계를 사용하는 추세다.
복합 키: 비식별 관계 매핑#
- JPA는 영속성 컨텍스트에 엔티티를 보관할 때 엔티티의 식별자를 키로 사용한다.
- 식별자를 구분하기 위해
equals와 hashCode를 사용해 동등성 비교를 한다.- 식별자 필드가 2개 이상이면 별도의 식별자 클래스를 만들고 그곳에
equals와 hashCode를 구현해야 한다.
- 복합 키를 지원하기 위해
@IdClass와 @EmbeddedId 2가지 방법을 제공한다. @IdClass
- 식별자 클래스의 속성명과 엔티티에서 사용하는 식별자의 속성명이 같아야 한다.
- 예제)
Parent.id1과 ParentId.id1, 그리고 Parent.id2와 ParentId.id2가 같다.
Serializable 인터페이스를 구현해야 한다.equals, hashCode를 구현해야 한다.- 기본 생성자가 있어야 한다.
- 식별자 클래스는 public이어야 한다.
- 복합키 조회
- 연관관계 매핑을 할 때
@JoinColumns 어노테이션을 사용해야 한다.
@EmbeddedId@EmbeddedId는 좀 더 객체지향적인 방법이다.@EmbeddedId를 적용한 식별자 클래스는 다음 조건을 만족해야 한다.@Embeddable 어노테이션을 붙여주어야 한다.Serializable 인터페이스를 구현해야 한다.equals, hashCode를 구현해야 한다.- 기본 생성자가 있어야 한다.
- 식별자 클래스를 public이어야 한다.
@IdClass vs @EmbeddedId- 취향 차이
@EmbeddedId가 @IdClass와 비교해서 더 객체지향적이고 중복도 없어서 좋아보이지만 특정 상황에 JPQL이 조금 더 길어질 수 있다.
복합 키: 식별 관계 매핑#
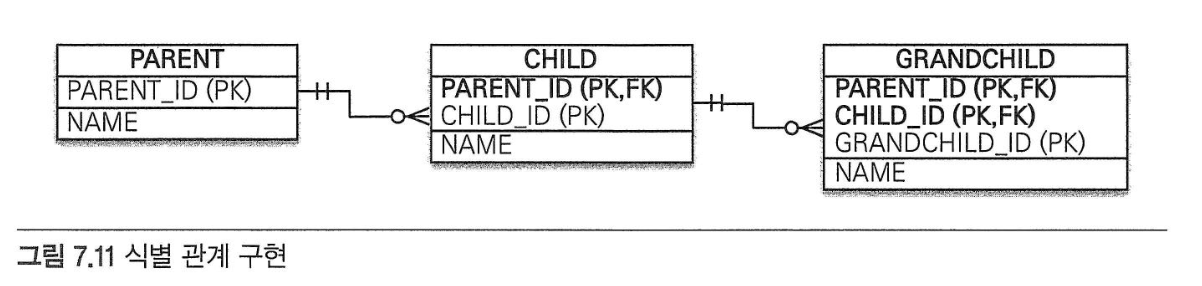
IdClass와 식별 관계- 식별자 매핑인
@Id와 연관관계 매핑인 @ManyToOne을 같이 사용한다. 

@EmbeddedId와 식별 관계@MapsId: 외래키와 매핑한 연관관계를 기본 키에도 매핑하겠다는 뜻

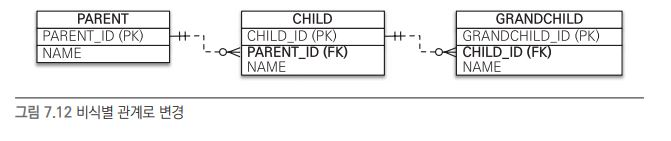
비식별 관계로 구현#
- 비식별 관계로 구현하는 것이 매핑도 쉽고, 복합 키가 없으므로 복합 키 클래스를 만들지 않아도 된다.
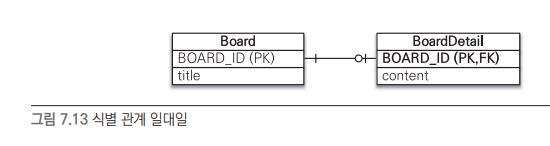
일대일 식별 관계#
- 일대일 식별 관계는 자식의 기본 키 값으로 부모 테이블의 기본 키 값만 사용한다.
식별, 비식별 관계의 장단점#
- 데이터베이스 설계 관점에서 식별 관계보다 비식별 관계가 좋은 점
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블로 전파하면서 자식 테이블의 기본 키 컬럼이 점점 늘어난다.
- 식별 관계는 2개 이상의 컬럼을 합해서 복합 기본 키를 만들어야 하는 경우가 많다.
- 식별 관계를 사용할 때 기본 키로 비즈니스 의미가 있는 자연 키 컬럽을 조합하는 경우가 많다. 비즈니스 요구사항은 시간이 지남에 따라 언젠가는 변한다.
- 식별 관계는 부모 테이블의 기본 키를 자식 테이블의 기본 키로 사용하므로 비식별 관계보다 테이블 구조가 유연하지 못하다.
- 객체 관계 매핑 관점에서 식별 관계보다 비식별 관계가 좋은 점
- 일대일 관계를 제외하고 식별 관계는 2개 이상의 컬럼을 묶는 복합 기본 키를 사용한다.
- 비식별 관계의 기본 키는 주로 대리 키를 사용하는데 JPA는
@GenerateValue 처럼 대리 키를 생성하기 위한 편리한 방법을 제공한다.
- 식별 관계의 장점
- 기본키 인덱스를 활용하기 좋다.
- 상위 테이블의 기본 키 컬럼을 자식, 손자 테이블들이 가지고 있으므로 특정 상황에 조인 없이 하위 테이블만으로 검색을 완료할 수 있다.
- ORM 신규 프로젝트 진행시 추천하는 방법은 될 수 있으면 비식별 관계를 사용하고 기본 키는 Long 타입의 대리 키를 사용하는 것이다.
조인 테이블#
- 테이블의 연관관계를 설계하는 방법은 2가지다.
- 조인 컬럼 사용(외래 키)
- 조인 테이블 사용(테이블 사용)
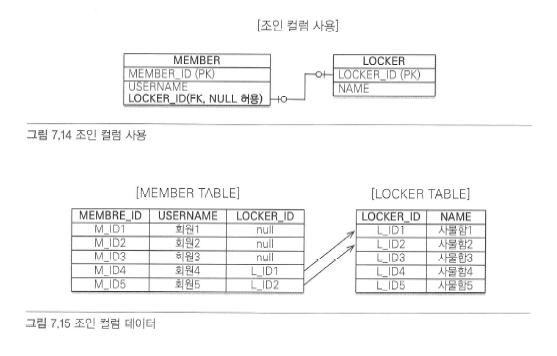
- 조인 컬럼 사용 단점
- 선택적 비식별 관계는 외래 키에 null을 허용하므로 회원과 사물함을 조인할 때 외부 조인을 사용해야 한다.
- 실수로 내부 조인을 사용하면 일부 레코드가 조회되지 않는다.
- 가끔 관계를 맺는 데이터라면 대부분의 값이 null로 저장된다.
- 조인 테이블 단점
- 따라서 기본은 조인 컬럼을 사용하고 필요하다고 판단되면 조인 테이블을 사용하자.
일대일 조인 테이블#
- 부모 엔티티에
@JoinTable을 사용했다. @JoinTable 속성name: 매핑할 테이블 이름joinColumns: 현재 엔티티를 참조하는 외래 키inverseJoinColumns: 반대방향 엔티티를 참조하는 외래 키
- 양방향으로 매핑하려면 자식 엔티티에
@OnetoOne(amppedBy="child")를 추가하면 된다.
//부모
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToOne
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID")
)
private Child child;
...
}
//자식
@Entity
public class Chiㅣd {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
...
}
일대다 조인 테이블#
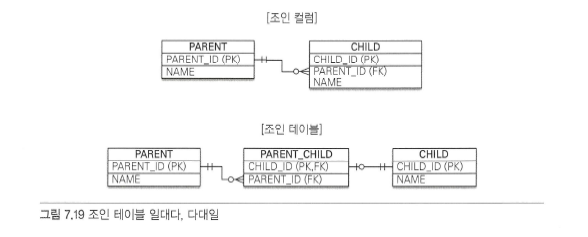
//부모
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToMany
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"),
inverseJoinColumns = @JoinColumn(name = "CHILD_ID")
)
private List<Child> child = new ArrayList<Child>();
...
}
//자식
@Entity
public class ChiId {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
...
}
다대일 조인 테이블#
//부모
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "parent")
private List<Child> child = new ArrayList<Child>();
}
//자식
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = ”CHILD_ID")
private Long id;
private String name;
@ManyToOne(optional = false)
@JoinTable(name = HPARENT_CHILD",
joinColumns = @JoinColumn(name = "CHILD_ID"),
inverseJoinColumns = @JoinColumn(name = "PARENT_ID")
)
private Parent parent;
}
다대다 조인 테이블#
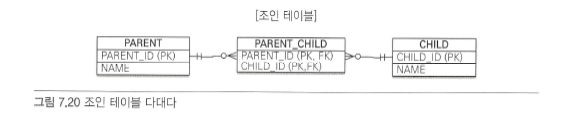
- 조인 테이블에 컬럼을 추가하면
@JoinTable 전략을 사용할 수 없다. 대신에 새로운 엔티티를 만들어서 조인 테이블과 매핑해야 한다.
//부모
@Entity
public class Parent {
@Id @GeneratedValue
@Column(name = "PARENT_ID")
private Long id;
private String name;
@ManyToMany
@JoinTable(name = "PARENT_CHILD",
joinColumns = @JoinColumn(name = "PARENT_ID"》,
inverseJoinColumns = @JoinColumn(name = "CHILD_ID")
)
private List<Child> child = new ArrayList<Child〉();
}
//자식
@Entity
public class Child {
@Id @GeneratedValue
@Column(name = "CHILD_ID")
private Long id;
private String name;
}
엔티티 하나에 여러 테이블 매핑#
- 잘 사용하지 않지만 하나의 엔티티에 여러 테이블을 매핑하려면
@SecondaryTable을 사용하면 된다.@SecondaryTable.name: 매핑할 다른 테이블의 이름@SecondaryTable.pkJoinColumns: 매핑할 다른 테이블의 기본 키 컬럼 속성- 더 많은 테이블을 매핑하려면
@SecondaryTables를 사용하면 된다.
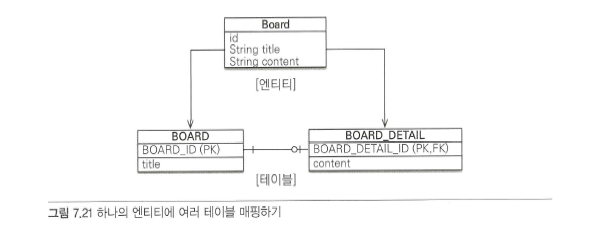
@Entity
@Table(name="BOARD")
@SecondaryTable (name = "BOARD_DETAIL" ,
pkJoinColumns = SPrimaryKeyJoinColumn (name = "BOARD_DETAIL_ID"))
public class Board {
@Id @GeneratedValue
@Column(name = "BOARD_ID")
private Long id;
private String title;
@Column(table = "BOARD_DETAIL")
private String content;
...
}
- 가능하면 테이블당 엔티티를 각각 만들어서 일대일 매핑하는 것을 권장한다.
- 이 방법은 항상 두 테이블을 조회하므로 최적화하기 어렵기 때문이다.