메모리 관리의 개요
메모리 관리의 복잡성
- 메모리의 구조는 1B 크기로 나뉜다. 1B로 나뉜 각 영역은 메모리 주소로 구분하는데 보통 0번지부터 시작한다.
- CPU는 메모리에 있는 내용을 가져오거나 작업 결과를 메모리에 저장하기 위해 메모리 주소 레지스터(MAR)를 사용한다.
- 폰노이만 구조의 컴퓨터에서 메모리는 유일한 작업 공간이며 모든 프로그램이 메로리에 올라와야 실행이 가능하다.
- 운영체제도 메모리에 올라와야 실행할 수 있다.
- 운영체제를 비롯해 여러 작업을 동시에 처리하는 복잡한 메모리 관리는 메모리 관리 시스템(Memory Management System, MMS)이 담당한다.
메모리 관리의 이중성
- 메모리 관리의 이중성: 프로세스 입장에서 작업의 편리함과 관리자 입장에서 관리의 편리함이 충돌을 일으키는 것
소스코드의 번역과 실행
저급 언어: 기계어와 어셈블리어같이 컴퓨터의 동작을 가장 직접적으로 표현한 언어
고급 언어: 사용자가 이해하기 쉽게 프로그래밍할 수 있는 언어
언어 번역 프로그램: 고급 언어로 작성한 소스코드를 컴퓨터가 실행할 수 있는 기계어로 번역하는 프로그램
- 컴파일러: 소스코드를 컴퓨터가 실행할 수 있는 기계어로 번역한후 한꺼번에 실행한다. C언어, 자바 등이 이 방식으로 프로그램을 실행한다.
- 인터프리터: 소스코드를 한 행씩 번역하여 실행한다. 자바스크립트, 베이직 등이 이 방식으로 프로그램을 실행한다.
컴파일러의 목적
- 오류 발견: 컴파일러는 오류를 찾기위해 심벌 테이블(symbol table)을 사용한다.
- 심벌 테이블: 변수 선언부에 명시한 각 변수의 이름과 타입을 모아놓은 테이블
- 심벌 테이블로 선언하지 않은 변수를 사용하지는 않았는지, 변수에 다른 타입의 데이터를 저장하지는 않았는지 알 수 있다.
- 코드 최적화:코드의 군더더기와 사용하지 않는 변수를 삭제하면 더욱 간결해져서 실행속도가 빨라진다.
- 오류 발견: 컴파일러는 오류를 찾기위해 심벌 테이블(symbol table)을 사용한다.
컴파일러와 인터프리터의 차이
| 구분 | 컴파일러 | 인터프리터 |
| ——- | ————————————– | ————— |
| 변수 | 변수를 선언해야 한다. | 변수를 선언할 필요가 없다. |
| 실행 | 컴파일 후 실행된다. | 한 줄씩 실행된다. |
| 장점 | 오류 찾기와 코드 최적화, 분할 컴파일에 의한 공동 작업이 가능하다. | 실행이 편리하다. |
| 사용 프로그램 | 대형 프로그램 | 간단한 프로그램 |
컴파일 과정
- 소스 코드 작성 및 컴파일: 컴파일하여 목적 코드를 만든다.
- 목적 코드와 라이브러리 연결: 라이브러리에 있는 코드를 목적 코드에 삽입하여 최종 실행 파일을 만든다. 라이브러리는 자주 사용하는 함수를 시스템 내에 미리 만들어둔 것이다.
- 동적 라이브러리를 포함하여 최종 실행
- 동적 라이브러리 : 실행할 때 삽입되는 함수를 가진 라이브러리. 동적 라이브러리 방식에서는 함수가 변경되어도 새로 컴파일할 필요가 없다. (예: 윈도우의 DDL 파일)
메모리 관리자의 역할
- 메모리 관리자는 메모리 관리 유닛(Memory Manage Unit, MMU)라는 하드웨어를 말한다.
- 메모리 관리자의 작업은 가져오기(fetch), 배치(placement), 재배치(replacement)다.
- 가져오기 정책: 프로세스가 필요로 하는 데이터를 언제 메모리로 가져올지 결정하는 정책. 프로세스가 요청할 떄 메모리로 가져오는 것이 일반적이지만, 필요하다고 예상되는 데이터를 미리 가져오는 방법(prefetch)도 있다.
- 배치 정책: 가져온 프로세스를 메모리의 어떤 위치에 올려놓을지 결정하는 정책.
- 페이징: 메모리를 같은 크기로 자르는 것.
- 세그먼테이션: 프로세스의 크기에 맞게 자르는 것.
- 재배치 정책: 메모리가 꽉 찼을 때 메모리 내에 있는 어떤 프로세스를 내보낼지 결정하는 정책.
- 앞으로 사용하지 않을 프로세스를 내보내면 시스템의 성능이 올라가지만 자주 사용할 프로세스를 내보내면 성능이 떨어진다.
메모리 주소
32bit CPU와 64bit CPU의 차이
| 구분 | 32bit CPU | 64bit CPU |
|---|---|---|
| 주소 범위 | 0~2^32-1 번지 | 0~2^64번지 |
| 총 메모리 크기 | 4GB | 16777216TB |
| 버스의 크기 | 32bit | 64bit |
| 레지스터 크기 | 32bit | 64bit |
- 물리 주소 공간(pyhsical address space): 하드웨어 입장에서 바라본 주소 공간
- 논리 주소 공간(logical address space): 사용자 입장에서 바라본 주소 공간
절대 주소와 상대 주소
- 일괄 처리 시스템에서 사용할 수 있는 단순 메모리 구조는 다음과 같다.
- 사용자 영역이 운영체제 영역으로 침범하는 것을 막기 위해 CPU 내에 있는 경계 레지스터를 사용한다.
- 메모리 관리자는 사용자가 작업을 요청할 때 경계 레지스터의 값을 벗어나는지 검사하고, 만약 벗어나는 작업을 요청하면 그 프로세스를 종료한다.
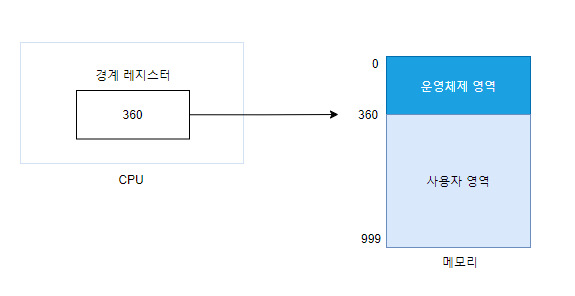
운영체제 크기에 따라 주소가 달라지는 것이 번거로워 사용자 프로세스를 메모리 촤상위부터 사용하는 방법도 있다. 하지만 메모리를 거꾸로 사용하기 위해 주소를 변경하는 일이 복잡하기 때문에 잘 사용하지 않는다.

절대 주소: 실제 물리 주소를 가리키는 주소 지정 방식. 메모리 관리자 입장에서 바라본 주소. 물리 주소 공간은 절대 주소를 사용하는 주소 공간이다.
상대 주소: 사용자 영역이 시작되는 번지를 0번지로 변경하여 사용하는 주소 지정 방식. 사용자 프로세스 입장에서 바라본 주소. 논리 주소 공간은 상대 주소를 사용하는 주소 공간.
상대 주소를 사용하여 메모리에 접근할 떄마다 상대 주소값에 재배치 레지스터 값을 더해 절대 주소를 구한다.

단일 프로그래밍 환경에서의 메모리 할당
메모리 오버레이
프로그램의 크기가 실제 메모리보다 클 때 전체 프로그램을 메모리에 가져오는 대신 적당한 크기로 잘라서 가져온다. 이를 메모리 오버레이라고 한다.
프로그램을 몇 개의 모듈로 나누고 필요할 때마다 모듈을 메모리에 가져와 사용한다.

어떤 모듈을 가져오거나 내보낼지는 CPU 레지스터인 프로그램 카운터(PC)가 결정한다.
- PC는 앞으로 실행할 명령어의 위치를 가리키는데 해당 모듈이 메모리에 없으면 메모리 관리자에게 요청하여 메모리로 가져오게 한다.
메모리 오버레이는 다음과 같은 의미가 있다.
- 한정된 메모리에서 메모리보다 큰 프로그램의 실행이 가능하다.
- 프로그램 전체가 아니라 일부만 메모리에 올라와도 실행이 가능하다.
스왑

- 메모리 오버레이에서 사용하지 않는 모듈을 저장장치의 별도의 공간에 보관해야 한다. 이 공간을 스왑 영역이라고 부른다.
- 스왑 영역에서 메모리로 데이터를 가져오는 작업을 스왑인(swap in), 메모리에서 스왑 영역으로 데이터를 내보내는 작업을 스왑아웃(swap out)이라고 한다.
- 원래 하드 디스크 같은 저장장치는 저장장치 관리자가 관리하지만, 스왑 영역은 메모리에서 쫓겨났다가 다시 돌아가는 데이터가 머무는 곳이기 때문에 메모리 관리자가 관리한다.
- 스왑을 이용하면 스왑 영역의 크기가 메모리 크기로 인식된다. 즉 실제 메모리와 스왑 영역의 크기를 합쳐서 전체 메모리로 인식하고 사용할 수 있다.
💡 윈도우 운영체제는 스왑 영역을 운영체제와 같은 파티션에 넣고 파일 형태로 관리한다. 유닉스 운영체제는 운영체제를 설치할 때 하드디스크의 분리된 파티션에 스왑 영역을 배정한다.
다중 프로그래밍 환경에서의 메모리 할당
메모리 분할 방식

- 가변 분할 방식: 프로세스의 크기에 따라 메모리를 분할하는 것. 한 프로세스가 연속된 공간에 배치되기 때문에 연속 메모리 할당이라고 한다.
- 장점: 프로세스를 한 덩어리로 처리하여 하나의 프로세스를 연속된 공간에 배치한다.
- 단점: 메모리 관리가 복잡하다. 프로세스 B, D가 작업을 마치고 19KB가 넘는 프로세스가 메모리로 올라오면 18KB와 17KB 빈 메모리 공간을 합치는 과정이 필요하다.(외부 단편화)
- 고정 분할 방식: 프로세스의 크기와 상관없이 메모리를 같은 크기로 분할하는 것. 한 프로세스가 분산되어 배치되기 떄문에 비연속 메모리 할당이라고도 한다.
- 장점: 메모리를 일정한 크기로 나누어 관리하기 때문에 메모리 관리가 수월하다.
- 단점: 쓸모없는 공간으로 인해 메모리 낭비가 발생할 수 있다. 일정하게 나누어진 공간보다 작은 프로세스가 올라올 경우 메모리 낭비가 발생한다.
- 현대 운영체제에서 메모리 관리는 기본적으로 고정 분할 방식을 사용하면서 일부분은 가변 분할 방식을 혼합하고 있다.
가변 분할 방식의 메모리 관리
- 가변 분할 방식에서 발생하는 작은 빈 공간을 외부 단편화라고한다. 프로세스의 바깥쪽에서 조각이 발생하기 때문에 이렇게 부른다.
- 외부 단편화 문제를 해결하기 위해서, 메모리 배치 방식(memory placement strategy)이나 조각 모음(defragmentation)을 사용한다.
- 메모리 배치 방식: 작은 조각이 발생하지 않도록 프로세스를 배치하는 것.
- 최초 배치: 단편화를 고려하지 않는 것으로, 프로세스를 메모리의 빈 공간에 배치할 때 메모리에 적재 가능한 공간을 순서대로 찾다고 첫 번째로 발견한 공간에 프로세스를 배치하는 방법이다.
- 최적 배치: 메모리의 빈 공간을 모두 확인한 후 적당한 크기 가운데 가장 작은 공간에 프로세스를 배치하는 방법이다. 딱 맞는 빈공간이 있을 때는 단편화가 일어나지 않지만, 없을 때는 아주 작은 조각을 만들어내는 단점이 있다.
- 최악 배치: 메모리의 빈 공간을 모두 확인한 후 적당한 크기 가운데 가장 큰 공간에 프로세스를 배치하는 방법이다. 배치하고 남은 공간이 크기 때문에 쓸모있는 공간을 만들어낸다. 하지만 빈 공간의 크기가 점점 줄어들면 최적 배치처럼 작은 조각을 만들어낸다.
- 조각 모음: 단편화가 발생할 때 이미 배치된 프로세스를 옆으로 옮겨 빈 공간을 하나의 큰 덩어리로 만드는 것. 프로세스를 중지시키고 다시 시작하기 때문에 시간이 많이 걸린다.
- 조각 모음을 하기 위해 이동할 프로세스의 동작을 멈춘다.
- 프로세스를 적당한 위치로 이동한다. 프로세스가 원래의 위치에서 이동하기 때문에 프로세스의 절대 주소값을 바꾼다.
- 작업을 다 마친 후 프로세스를 다시 시작한다.
고정 분할 방식의 메모리 관리
- 고정 분할 방식에서 일정한 크기로 나뉜 파티션 안쪽으로 공간이 남는 현상을 내부 단편화라고 한다.
- 내부 단편화는 파티션 공간의 크기를 조절하여 최소화한다.
- 파티션 공간을 작게 만들면 내부 단편화는 줄지만 프로세스가 여러 개로 분할되어 관리하기 힘들어진다.
- 파티션의 공간을 크게 만들면 프로세스가 같은 파티션에 있을 수 있지만 내부 단편화가 증가한다.
버디 시스템
- 가변 분할 방식의 외부 단편화를 완화하는 방법으로 버디 시스템이 있다. 버디 시스템은 가변 불할 방식이지만 고정 분할 방식과 유사한 점이 있다.
- 버디 시스템의 작동 방식
- 프로세스의 크기에 맞게 메모리를 1/2로 자르고 프로세스를 메모리에 배치한다.
- 나뉜 메모리의 각 구역에는 프로세스가 1개만 들어간다.
- 프로세스가 종료되면 주변의 빈 조각과 합쳐서 하나의 큰 덩어리를 만든다.

- 버디 시스템은 비슷한 크기의 덩어리가 서로 모여 있어서 통합하기가 쉽다. 그래서 가변 분할 방식보다 효과적으로 공간을 관리할 수 있다.
- 효율적인 공간 관리 측면에서 보면 고정 분할 방식과 버디 시스템은 비슷한 수준이다. 그러나 고정 분할 방식이 더 단순하기 때문에 고정 분할 방식이 일반적으로 많이 사용되고 있다.
컴파일과 메모리 관리
컴파일 과정

- 소스코드를 기계어로 번역한 것을 목적 코드라고 한다.
- 목적 코드로 변환하면서 오류가 있는지 점검하고 최적화를 통해 필요 없는 변수와 코드를 삭제한다.
- 분할 컴파일: 프로그래머가 각자 작성한 코드를 컴파일하여 목적 모드만 만든 후 목적 코드만 따로 모아서 컴파일 하는 것
- 소스코드를 모아서 컴파일하면 그 전에 오류 검증을 미리할 수 없기 때문
- 연결 단계: 목적 코드에 라이브러리 코드를 삽입하여 최종 실행 파일을 만든다.
변수와 메모리 할당
컴파일러는 프로그래머가 지정한 자룔형의 크기에 따라 메모리를 확보하고 그곳에 적당한 값을 집어넣는다.
모든 변수에 대해 메모리를 확보하고 오류를 찾기 위해 심벌 테이블을 유지한다.

변수명은 메모리 주소의 또 다른 이름이다.
연습문제
- 인터프리터
- 목적 코드
- 동적 라이브러리
- 재배치 정책
- 4GB
- 상대 주소
- 재배치 레지스터
- 메모리 오버레이
- 스왑 영역
- 외부 단편화
- 내부 단편화
- 최적 배치
- 최초 배치
- 최악 배치
- 조각 모음
- 버디 시스템
심화문제
- 아래
- 컴파일러: 소스코드를 실행할 수 있는 기계어로 번역한 후 한꺼번에 실행한다.
- 인터프리터: 소스코드를 한 행씩 번역하면서 실행한다.
- 아래
- 소스 코드를 목적 코드로 번역한다. 번역하는 과정에서 소스 코드에 오류가 없는지 확인하고 불필요한 코드를 제거하여 최적화한다.
- 목적 코드에 외부 라이브러리를 연결하여 최종적으로 실행가능한 파일로 만든다.
- 동적 라이브러리를 포함시켜 최종 실행한다.
- 아래
- 가져오기 작업: 프로세스가 필요한 데이터를 언제 가져올지 선택하는 작업. 일반적으로 필요한 순간에 메모리에 가져오지만, 미리 필요한 데이터를 가져오는 prefetch 전략도 있다.
- 배치 작업: 데이터를 메모리의 어디에 저장할지 선택하는 작업.
- 재배치 작업: 메모리가 가득 찼을 때 어떤 프로세스를 메모리에서 제거할지 선택하는 작업.
- 아래
- 절대 주소: 물리적인 메모리의 주소를 나타내는 주소 지정 방식.
- 상대 주소: 사용자 영역이 시작되는 번지를 0으로 지정하고 사용하는 주소 지정 방식.
- 아래
- 장점: 프로세스가 한 덩어리로 연속적으로 저장할 수 있다.
- 단점: 외부 단편화가 발생할 수 있다.
- 아래
- 장점: 메모리를 일정한 크기로 잘라서 관리하기 때문에 메모리 관리가 수월하다.
- 단점: 내부 단편화가 발생할 수 있다.
- 프로세스의 크기에 맞도록 1/2씩 잘라가면서 메모리를 나누어주는 방식. 비슷한 크기의 프로세스끼리 모아둘 수 있어서 외부 단편화를 줄일 수 있다는 장점이있다. 하지만 공간관리의 효율성 측면에서 고정 분할 방식과 비슷하기 때문에 비교적 단순한 고정 분할 방식을 사용한다.