- 최적화를 초기 단계에서부터 하는 것은 얻는 것보다 잃는 것이 많은 경우가 많다.
- 가독성과 성능 사이에서 트레이드 오프가 발생할 때, 개발하는 컴포넌트에서 무엇이 더 중요한지 스스로 답할 수 있어야 한다.
불필요한 객체 생성을 피하라
- 객체 생성은 언제나 비용이 들어간다.
- JVM에서는 하나의 가상 머신에서 동일한 문자열을 처리하는 코드가 여러개 있다면, 기존의 문자열을 재사용한다.
Integer나Long처럼 박스화한 기본 자료형도 작은 경우에는 재사용한다. (기본적으로Int는 -128~127 범위를 캐시해 둔다.)
객체 생성 비용은 항상 클까?
- 객체를 wrap하면 더 많은 용량을 차지한다.
- 64비트 JDK 기준: 헤더(12바이트) + 객체에 대한 레퍼런스 공간(-Xmx32G까지는 4바이트, -Xmx32G부터는 8바이트)
- 5배 이상의 공간을 차지할 수 있다.
- 요소가 캡슐화되어 있다면, 접근에 추가적인 함수 호출이 필요하다.
- 처리속도가 빠르지만, 티끌 모아 태산이 발생할 수 있다.
- 객체가 생성되고, 메모리 영역에 할당되고, 이에 대한 레퍼런스를 만드는 등의 작업이 필요하다. 적은 비용이지만, 모이면 큰 비용이 된다.
객체 선언
- 매 순간 객체를 생성하지 않고, 객체를 재사용하는 간단한 방법은 객체 선언(싱글톤)을 사용하는 것이다.
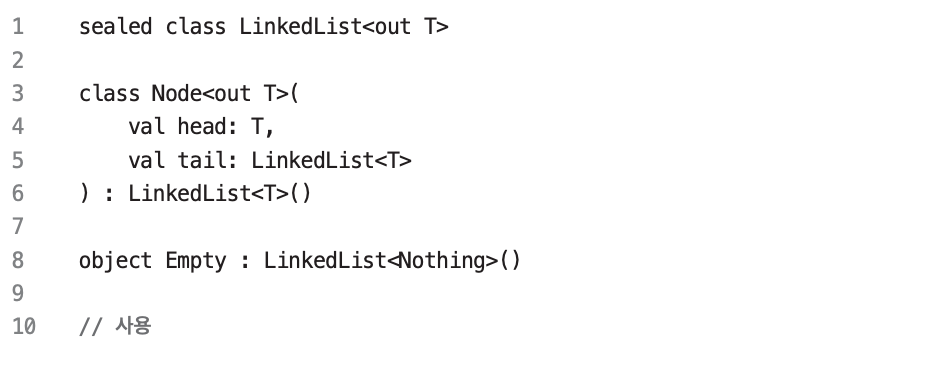
캐시를 활용하는 팩토리 함수
- 팩토리 함수는 캐시를 가질 수 있다.
- 팩토리 함수는 항상 같은 객체를 리턴하게 만들 수도 있다.
- 모든 순수 함수는 캐싱을 활용할 수 있다.(메모이제이션)
- 단점: 캐시를 위한
Map을 저장해야 하므로, 더 많은 메모리를 사용한다.- 메모리가 필요할 때 GC가 자동으로 메모리를 해제해 주는
SoftReference를 사용하면 더 좋다. WeakReference: GC가 weakly reachable 상태 인경우에 메모리를에서 제거된다. weakly reachable은WeakReference를 통해서만 참조되고 있는 경우를 말한다.SoftReference: GC가 OutOfMemoryError가 발생하기 전에 메모리가 부족해지면, 언제든 제거될 수 있다.- 참고 자료: https://d2.naver.com/helloworld/329631
- 메모리가 필요할 때 GC가 자동으로 메모리를 해제해 주는
SoftReference를 이용해 캐싱을 구현한 예시: https://o7planning.org/13695/java-softreference#a64445222
무거운 객체를 외부 스코프로 보내기
- 연산을 외부로 추출해서 값 계산을 추가로 하지 않게 만든다.
- 아래의 예시도 함수를 사용할 때마다
Regex객체를 계속해서 새로 만들어서, 성능적으로 문제를 일으킨다. - 정규 표현식을 톱레벨로 보내서 문제를 해결한다.



지연 초기화
- 무거운 클래스를 만들 때는 지연되게 만드는 것이 좋다.
- 지연 초기화의 단점: 클래스가 무거운 객체를 가졌지만, 메서드의 호출은 빨라야 하는 경우에 불리하다. 첫 호출 때 응답 시간이 굉장히 길어진다.

기본 자료형 사용하기
- 코틀린/JVM 컴파일러에서 wrap한 자료형이 사용되는 경우
- nullable 타입을 연산할 때
- 타입을 제네릭으로 사용할 때
- 숫자에 대한 작업이 여러 번 반복될 때만 의미가 있다.
- 성능이 그렇게까지 중요하지 않은 코드에서는 큰 의미가 없는 최적화다. 다만 라이브러리를 구현한다면, 성능이 중요할 수 있다.
함수 타입 파라미터를 갖는 함수에 inline 한정자를 붙여라
inline한정자는 컴파일 시점에 ‘함수를 호출하는 부분’을 ‘함수의 본문’으로 대체한다.inline한정자를 사용하면, 얻는 장점- 타입 아규먼트에
reified한정자를 붙여서 사용할 수 있다. - 함수 타입 파라미터를 가진 함수가 훨씬 빠르게 동작한다.
- 비지역 리턴을 사용할 수 있다.
- 타입 아규먼트에
타입 아규먼트를 reified로 사용할 수 있다
- JVM 바이트 코드에는 제네릭이 존재하지 않다.
- 구버전의 자바에는 제네릭이 없기 때문이다.
- 따라서 컴파일 하면, 제네릭 타입과 관련된 내용이 제거 된다.

- 함수를 인라인으로 만들면, 함수 호출이 본문으로 대체되므로,
reified한정자를 지정하면 타입 파라미터를 사용한 부분이 타입 아규먼트로 대체된다.

함수 타입 파라미터를 가진 함수가 훨씬 빠르게 동작한다
inline한정자를 붙이면 함수 호출과 리턴을 위해 점프하는 과정과 백스택을 추적하는 과정이 없기 때문에 조금 더 빠르다.- 코틀린/JVM에서는 함수 타입 파라미터를 JVM 익명 클래스 또는 일반 클래스를 기반으로 객체로 만들어 낸다.
()->Unit은Function0<Unit>로 컴파일()->Int는Function0<Int>로 컴파일(Int)->Int는Function1<Int, Int>로 컴파일(Int, Int)->Int는Function2<Int, Int, Int>로 컴파일
- 함수 본문을 객체로 wrap하면, 코드의 속도가 더 느려진다.
- 코틀린/JVM에서는 함수 타입 파라미터를 JVM 익명 클래스 또는 일반 클래스를 기반으로 객체로 만들어 낸다.
inline한정자를 붙이면 함수 리터럴 내부에서 지역 변수를 캡처할 때, 객체로 wrapping할 필요가 없어서 더 빠르다.inline을 사용하지 않으면, 컴파일 과정 중에 지역 변수를 캡처하기 위해서 레퍼런스 객체로 wrapping 된다. 아래 사진이 관련된 코드다.
- 일반적으로 함수 타입의 파라미터가 어떤 식으로 동작하는지 이해하기 어려우므로, 함수 타입 파라미터를 활용해서 유틸리티 함수를 만들 때는 그냥 인라인을 붙여 준다 생각해도 좋다.
비지역 리턴(non-local return)을 사용할 수 있다
inline한정자를 붙이면 함수 리터럴 내에서return을 사용할 수 있다.inline을 사용하지 않으면 함수가 객체로 래핑되어서,return을 사용할 수 없다.- 지역 리턴은 사용 가능하다.

fun repeatNoinline(times: Int, action: (Int) -> Unit) {
for (index in 0 until times) {
action(index)
}
}
fun main() {
repeatNoinline(10) {
println(it)
return@repeatNoinline
println("next ${it + 1} ")
}
}
inline 한정자의 비용
- 인라인 함수는 재귀적으로 동작할 수 없다.
- 재귀적으로 사용하면, 코드를 무한하게 대체되는 문제가 발생한다.
- 이러한 문제는 인텔리제이가 오류를 잡아 주지 못하므로 위험하다.
- 인라인 함수는 더 많은 가시성 제한을 가진 요소를 사용할 수 없다.
public인라인 함수 내부에서는private와internal가시성을 가진 함수와 프로퍼티를 사용할 수 없다.- 인라인 함수는 구현을 숨길 수 없어서 그렇다.
inline한정자를 남용하면, 코드가 대체되면서 코드 크기가 쉽게 커지므로 유의해야된다.
crossinline과 noinline
- 함수를 인라인으로 만들고 싶지만, 함수 타입 파라미터는
inline으로 받고 싶지 않은 경우 사용할 수 있다. crossinline: 아규먼트로 인라인 함수를 받지만, 비지역적 리턴을 하는 함수는 받을 수 없게 만든다.noinline: 아규먼트로 인라인 함수를 받을 수 없게 만든다.
인라인 클래스의 사용을 고려하라
- 기본 생성자 프로퍼티가 하나인 클래스 앞에
inline을 붙이면, 해당 객체를 사용하는 위치가 모두 해당 프로퍼티로 교체된다. inline클래스의 메서드는 모두 정적 메서드로 만들어진다.- 인라인 클래스는 다른 자료형을 래핑해서 새로운 자료형을 만들 때 많이 사용한다.
- 측정 단위를 표현할 때
- 타입 오용으로 발생하는 문제를 막을 때

측정 단위를 표현할 때
- 함수 파라미터로 시간을 입력받을 때
Int타입이면 해당 파라미터가 ms, s, min 중에 어떤 단위인지 명확하지 않다. - 타입에 제한을 걸어서, 잘못된 단위를 입력하지 않도록 막는다. 올바른 타입을 사용하는 것을 강제할 수 있다.

타입 오용으로 발생하는 문제를 막을 때
- 하나의 클래스에서 여러 ID를 가지고 있을 때, 모든 ID가
Int형이므로 실수로 잘못된 값을 넣을 수 있다.- 다음과 같이
Int자료형의 값을ineline클래스를 활용해 래핑하면 실수를 막을 수 있다. 
- 다음과 같이
- 컴파일할 때 타입이
Int로 대체되므로 코드를 바꾸어도 별도의 문제가 발생하지 않는다.
인라인 클래스와 인터페이스
- 인라인 클래스도 다른 클래스와 마찬가지로 인터페이스를 구현할 수 있다.
- 하지만 인라인 클래스로 얻을 수 있는 장점이 없어진다.
- 인터페이스를 통해서 타입을 나타내려면, 객체를 래핑해서 사용해야 하기 때문이다.
typealias
typealias를 사용하면, 타입에 새로운 이름을 붙여 줄 수 있다.- 길고 반복적으로 사용해야 하는 함수 타입에 유용하다.
typealias는 안전하지 않다. 이름이 달라도 이름이 가리키는 타입이 같다면 오류가 발생하지 않는다.- 단위 등을 표현할 때,
typealias를 사용하면 오히려 디버깅이 힘들어질 수 있으므로 인라인 클래스를 사용하는 것이 좋다.



더 이상 사용하지 않는 객체의 레퍼런스를 제거하라
- 더 이상 사용하지 않는 객체의 레퍼런스를 유지하면 안 된다.
- 그렇지 않으면 메모리 누수가 발생할 수 있다.
- 스택에서
pop()구현시,size만 줄이고, 배열에 레퍼런스를 해제하지 않으면, GC가 이를 해제하지 않는다. - 쓸데없는 최적화가 모든 악의 근원일 수 있지만,
null을 설정하는 것은 어려운 일이 아니므로 하는 것이 좋다. Stack과 같이 범용적으로 사용되는 라이브러리를 만들 때는 최적화가 중요하다.- 일반적으로 메모리 누수가 발생하는 부분
- 절대 사용하지 않는 객체를 캐시해서 저장해 두는 경우는
SoftReference를 사용해서 해결가능 하다. - 화면 위의 대화상자와 같은 일부 객체는
WeakReference를 사용하는 것이 좋다.
- 절대 사용하지 않는 객체를 캐시해서 저장해 두는 경우는
- 메모리 누수는 예측하기 어렵기 때문에, 힙 프로파일러를 통해 메모리 누수를 찾는 것도 중요하다.
- 일반적으로 스코프를 벗어나면서, 어떤 객체를 가리키는 레퍼런스가 제거될 때 객체가 자동으로 해제된다.
- 따라서 메모리와 관련된 문제를 피하는 가장 좋은 방법은 지역 스코프에 정의하고, 톱레벨 프로퍼티 또는 객체 선언으로 큰 데이터를 저장하지 않는 것이다.
