멱등적 프로듀서 기능을 켜면 모든 메시지는 고유한 프로듀서 ID와 시퀀스 넘버를 가지게 된다.
토픽 + 파티션 + 프로듀서 ID + 시퀀스 넘버를 합치면 고유한 식별자가 된다.
각 브로커는 해당 브로커에 할당된 모든 파티션들에 쓰여진 마지막 5개 메시지들을 추적하기 위해 이 고유 식별자를 사용한다.
파티션 별로 추적되어야 하는 시퀀스 넘버의 수를 제한하고 싶다면 프로듀서의 max.in.flights.requests.per.connection 설정값이 5이하로 잡혀 있어야 한다. (기본값: 5)
브로커가 예전에 받은 적이 있는 메시지를 받게 될 경우, 적절한 에러를 발생시켜 중복 메시지를 거부한다.
이 에러는 프로듀서에 로깅도 되고 지푯값에도 반영되지만, 예외가 발생하는 것은 아니기 때문에 사용자에게 경보를 보내지는 않는다.
프로듀서 클라이언트에서는 record-error-rate 지푯값을 확인함으로써 에러를 확인할 수 있다.
브로커의 경우 RequestMetrics 유형의 ErrorsPerSec 지푯값에 기록된다.
만약 브로커가 예상보다 높은 시퀀스 넘버를 받게 된다면, 브로커는 ‘out of order sequence number’ 에러를 발생시킨다.
하지만 트랜잭션 기능 없이 멱등성 프로듀서만 사용하고 있다면 이 에러는 무시해도 좋다.
‘out of order sequence number’ 에러가 발생한 뒤에도 프로듀서가 정상 작동한다면, 이 에러는 보통 프로듀서와 브로커 사이에 메시지 유실이 있었음을 의미한다. 프로듀서와 브로커 설정을 재검토하고 프로듀서 설정이 고신뢰성을 위해 권장되는 값으로 잡혀 있는지, 아니면 언클린 리더 선출이 발생했는지 여부를 확인해볼 필요가 있다.
각 실패 상황에 따른 멱등적 프로듀서의 동작 방식
상황1: 프로듀서 장애
새 프로듀서를 생성해서 장애가 난 프로듀서를 대체하고, 프로듀서는 초기화 과정에서 카프카 브로커로부터 프로듀서 ID를 생성 받는다.
트랜잭션 기능을 켜지 않았을 경우, 프로듀서는 초기화할 때마다 완전시 새로운 ID가 생성된다.
즉, 프로듀서에 장애가 발생해서 대신 투입된 새 프로듀서가 기존 프로듀서가 이미 전송한 메시지를 다시 전송할 경우 ,브로커는 메시지에 중복이 발생했음을 알아차리지 못한다.
상황2: 브로커 장애
컨트롤러는 장애가 난 브로커가 리더를 맡고 있었던 파티션들에 대해 새 리더를 선출한다. 새로 선출된 브로커도 최근 5개의 시퀀스 넘버를 가지고 있다.
이유: 리더는 새 메시지가 쓰여질 때마다 인-메모리 프로듀서 상태에 저장된 최근 5개의 시퀀스 넘버를 업데이트하고, 팔로워 레플리카는 리더로부터 새로우 메시지를 복제할 때마다 자체적인 인-메모리 버퍼를 업데이트한다.
추가 상황: 예전 리더가 다시 돌아온다면?
현재 리더로부터 복제한 레코드를 사용해서 프로듀서 상태를 업데이트함으로써 최신 상태를 복구한다.
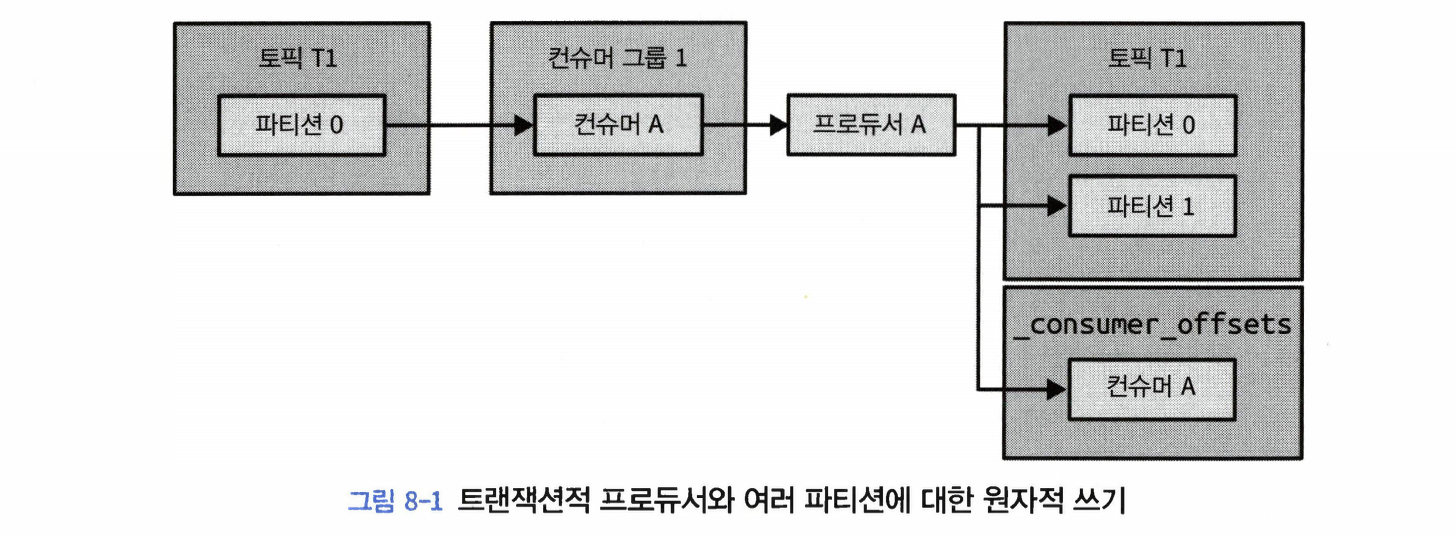
읽어 온 원본 메시지의 오프셋이 커밋되고 결과가 성공적으로 쓰여지거나, 아니면 둘 다 안 일어나거나, 우리는 부분적인 결과가 결코 발생하지 않을 거라는 보장이 필요하다.
이러한 작동을 지원하기 위해, 카프카 트랜잭션은 원자적 다수 파티션 쓰기(atomic multipartition write) 기능을 도입했다.
이 아이디어는 오프셋을 커밋하는 것과 결과를 쓰는 것은 둘 다 파티션에 메시지를 쓰는 과정을 수반한다는 점에 착안했다.
결과는 출력 토픽에, 오프셋은 _consumer_offsets 토픽에
트랜잭션을 사용해서 원자적 다수 파티션 쓰기를 수행하려면 ‘트랜잭션적 프로듀서’를 사용해야 한다.
보통 프로듀서와 차이점: transactional.id 설정이 잡혀있고, initTransactions()를 호출해서 초기화해준다.
producer.id는 브로커에 의해 자동으로 생성되지만, transactional.id는 프로듀서 설정의 일부이며, 재시작하더라도 값이 유지된다.
transactional.id의 주 용도: 프로듀서가 재시작 후에도 동일한 프로듀서를 식별하는 것
동일한 프로듀서로 식별해주는 이유: 브로커에서 transactional.id 에서 producer.id 로의 대응 관계를 가지고 있다가, 만약 이미 있는 transactional.id 프로듀서가 initTransactions()를 호출하면 새로운 랜덤값이 아닌 producer.id 값을 할당해 준다.
주의점: 메시지를 쓰고나서 커밋하기 전에 다른 애플리케이션이 응답하기를 기다리는 패턴은 반드시 피해야 한다.
다른 애플리케이션은 트래잭션이 커밋될 때까지 메시지를 받지 못할 것이기 때문에 결과적으로 데드락이 발생한다.
좀비 펜싱: 좀비 애플리케이션이 출력 스트림에 중복된 결과를 쓰는 것을 방지하는 것
구현 방법: 에포크(epoch)를 사용하는 방식
브로커는 트랜잭션적 프로듀서가 초기화를 위해 initTransaction()을 호출하면 transactional.id에 해당하는 에포크 값을 증가시킨다.
같은 transactional.id를 가지고 있지만 에포크 값은 낮은 프로듀서가 메시지 전송, 트랜잭션 커밋, 트랜잭션 중단 요청을 보낼 경우 FencedProducer 에러가 발생하면서 거부된다.
컨슈머에 올바른 격리 수준을 설정하지 않을 경우, 트랜잭션적 프로듀서로 메시지를 써도 ‘정확히 한 번’이 보장되지 않는다.
이유: 트랜잭션 기능을 사용해서 쓰여진 레코드는 비록 결과적으로 중단된 트랜잭션에 속할지라도 다른 레코드들과 마찬가지로 파티션에 쓰여진다.
격리 수준 설정 방법: isolation.level 설정
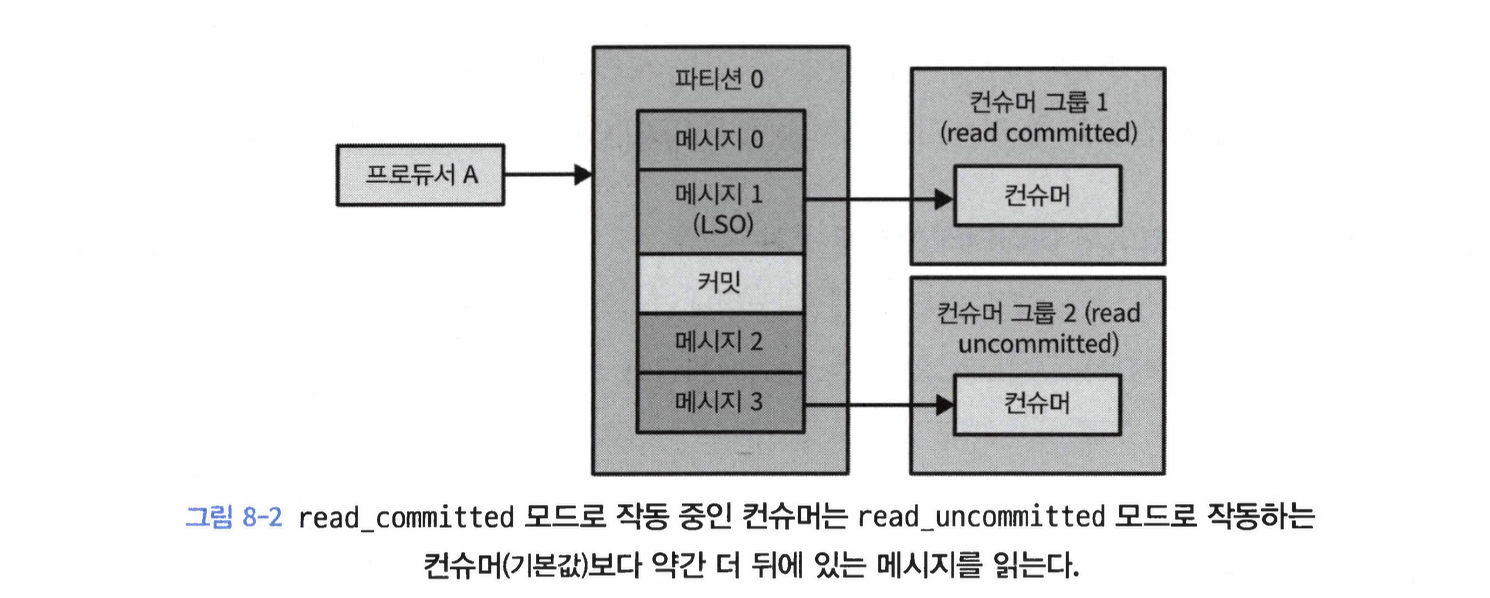
read_committed: consumer.poll()을 호출하면 커밋된 트랜잭션에 속한 메시지나 처음부터 트랜잭션에 속하지 않는 메시지만 리턴된다.
read_uncommitted(기본값): 중단된 트랜잭션에 속하는 것들 포함, 모든 레코드가 리턴된다.
read_committed로 설정한다고 해서 특정 트랜잭션에 속한 모든 메시지가 리턴된다고 보장되는 것도 아니다.
트랜잭션에 속하는 토픽의 일부만 구독했기 때문에 일부 메시지만 리턴받을 수도 있다.
메시지의 읽는 순서를 보장하기 위해 read_committed 모드에서는 아직 진행중인 트랜잭션이 처음으로 시작된 시점 이후에 쓰여진 메시지는 읽지 않는다.
이 메시지들은 트랜잭션이 프로듀서에 의해 커밋되거나 중단될 때까지, 혹은 transaction.time.ms 설정값(기본값: 15분)만큼 시간이 지나 브로커가 트랜잭션을 중단시킬 때까지 보류된다.
이렇게 트랜잭션이 오랫동안 닫히지 않고 있으면 컨슈머들이 지체되면서 종단 지연이 길어진다.