inverted index란#
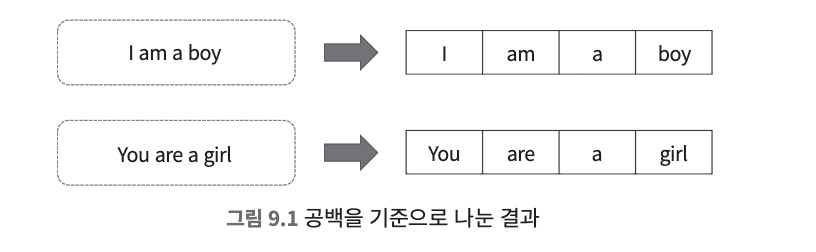
- 문서에 포함된 문자열을 어떤 기준으로 단어로 나누는데 이렇게 나뉜 단어들을 토큰이라고 부른다.
- 이렇게 토큰을 만들어내는 과정을 토크나이징이라고 부른다.
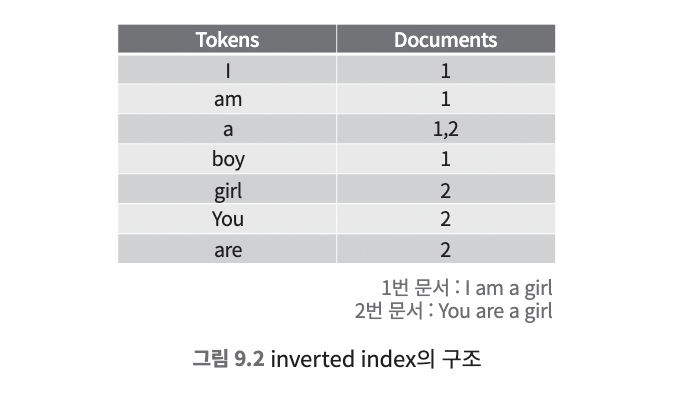
- 토큰을 기준으로 저장된 문서를 아래와 같이 저장하는데 이것을 inverted index라고 부른다.
- analyzer 종류 마다 토크나이징 결과가 달라진다.
analyzer 살펴보기#
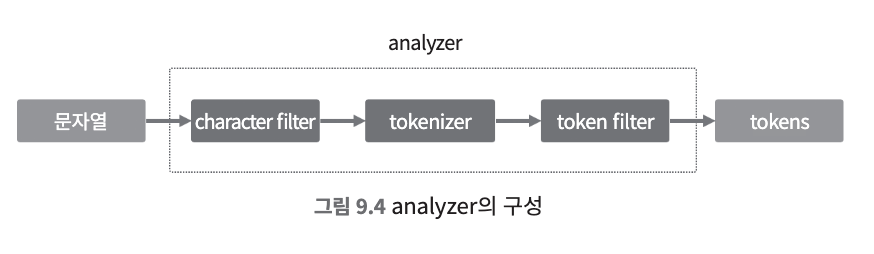
- analyzer를 구성할 때는 tokenizer를 필수로 명시해야 하며 하나의 tokenizer만 설정할 수 있다.
- character filter와 token filter는 필요하지 않은 경우 기술하지 않거나 여러 개를 기술할 수 있다.
- character filter: analyzer로 들어온 문자열을 변형한다.
- 예시:
<, >, ! 등과 같은 의미 없는 특수 문자들을 제거한다거나 HTML 태그들을 제거하는 등 문자열을 구성하고 있는 문자들을 특정한 기준으로 변경한다.
- tokenizer: 일정한 기준에 의해 문자열을 n개의 토큰으로 나눈다.
- token filter: 생성한 토큰들을 변형한다.
- 예시: lowercase token filter는 토큰을 전부 소문자로 바꾼다.
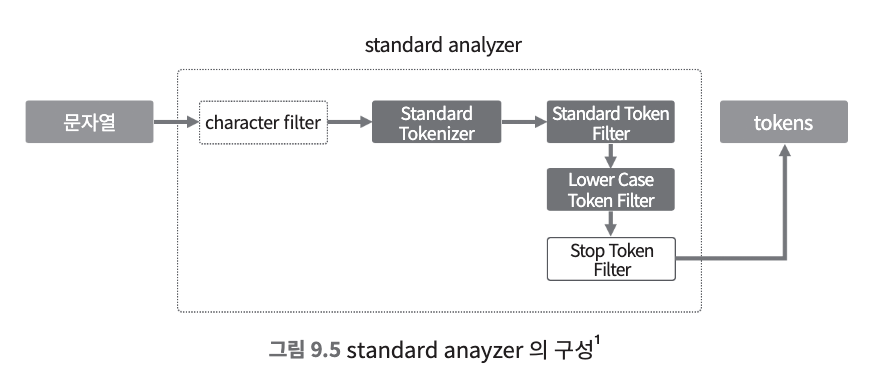
- standard tokenizer는 unicode standard annex 라는 룰에 따라 문자열을 분리한다.
- standard token filter는 실질적으로는 아무런 작업을 하지 않지만, 향후 개발되는 버전에서 필터링 기능을 사용하게 될 경우를 대비하여 포함되어 있다.
analyzer와 검색 관계#
- analyzer를 통해 생성된 토큰들이 inverted index에 저장되고, 검색할 때는 이 inverted index에 저장된 값을 바탕으로 문서를 찾는다.
text 타입의 기본 analyzer는 standard analyzer이고 keyword 타입의 기본 analyzer는 keyword analyzer이다.standard analyzer는 아래와 같이 단어 단위로 토큰을 만든다.- keyword analyzer는 아래와 같이 문자열이 나뉘어지지 않고 통으로 하나의 토큰을 구성하고 있다. 그렇기 때문에
keyword 타입은 일부 단어로 검색이 되지 않는다. - analyzer에 따라서 검색 결과와 품질이 달라지기 때문에 사용자의 검색 니즈를 잘 파악해서 그에 맞는 analyzer를 설정하느 것이 중요하다.
- analyzer는 운영 중에 동적으로 변경할 수 없기 때문에 analyzer를 바꿀 경우 인덱스를 새로 만들어서 재색인해야 한다는 점을 기억하자.
Search API#
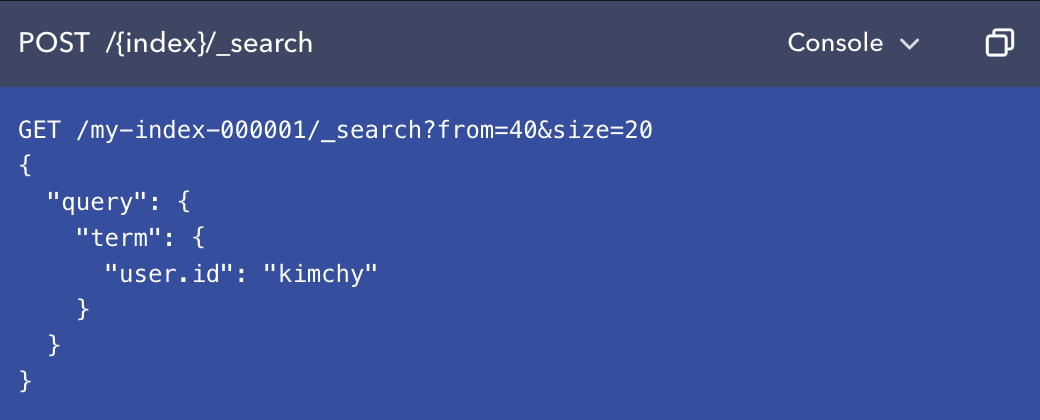
- 검색을 하기 위해서는 아래와 같이 POST 요청으로 쿼리를 보낼 수 있다.
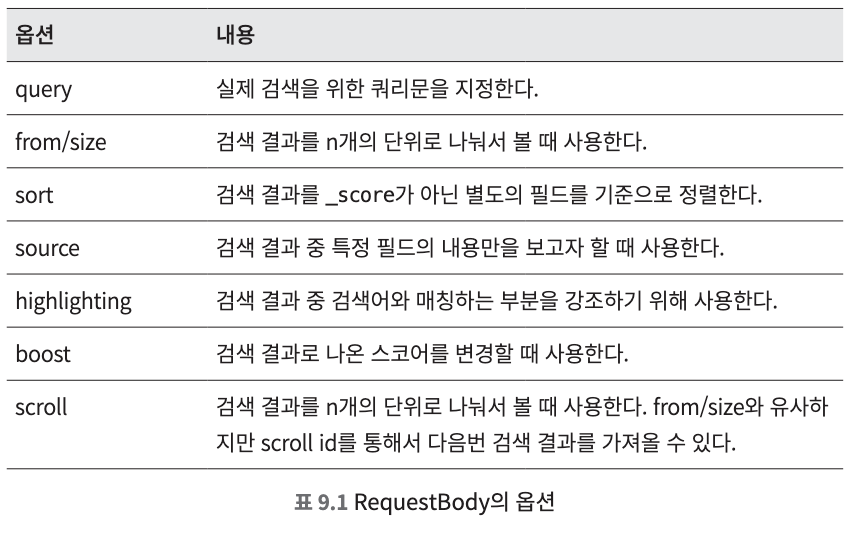
- RequestBody에는 다양한 옵션이 들어갈 수 있다.
- from/size의 기본값은 각각 0/10 이다.
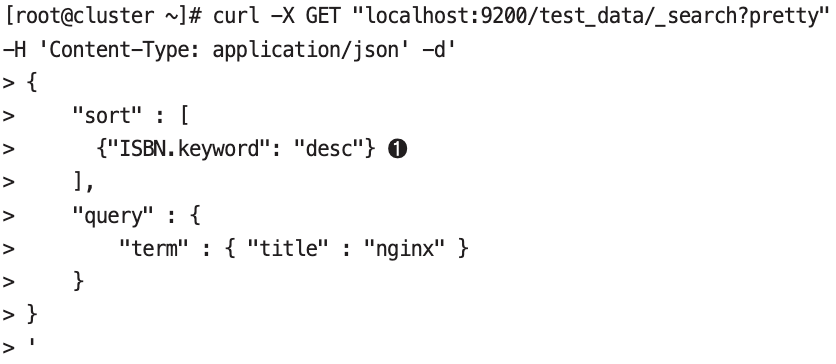
- sort 옵션은 text가 아닌 keyword나 integer와 같이 not analyzed가 기본인 필드를 기준으로 해야한다.
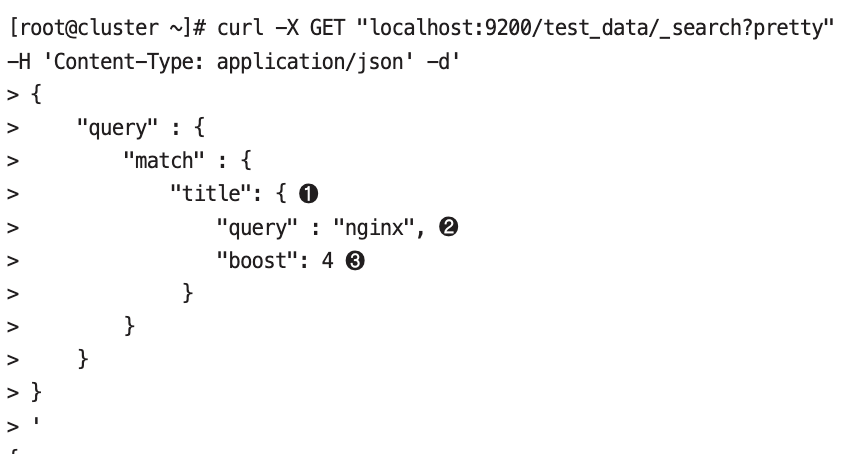
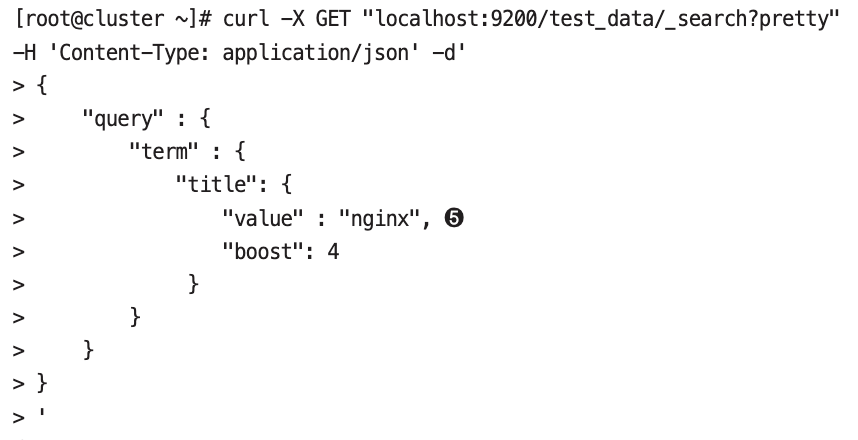
- 특정 검색 쿼리의 스코어를 높이거나 낮추고 싶을 때
boost 옵션을 활용하면 검색 결과로 나온 스코어를 스코어를 대상으로 boost 옵션에 설정된 값을 곱한 값이 스코어로 지정딘다.- match 쿼리를 사용할 때는 query 옵션을 사용하고, term 쿼리를 사용할 때는 value 옵션을 사용해야된다.
scroll 옵션을 사용하면 새로운 문서가 인입된다고 해도 scroll id가 유지되는 동안에는 검색 결과가 바뀌지 않는다. 그래서 scroll 옵션은 검색 결과가 동일하게 유지되어야 하는 paginzation, 혹은 대량의 배치 작업에 주로 활용한다.Scroll_id 유지 기간은 노드의 힙 메모리에 영향을 주기 때문에 지나치게 길게 설정하면 Out Of Memory 에러를 발생시킬 수 있다. 사용자의 검색 패턴을 기반으로 적당한 값으로 설정해 주어야 한다.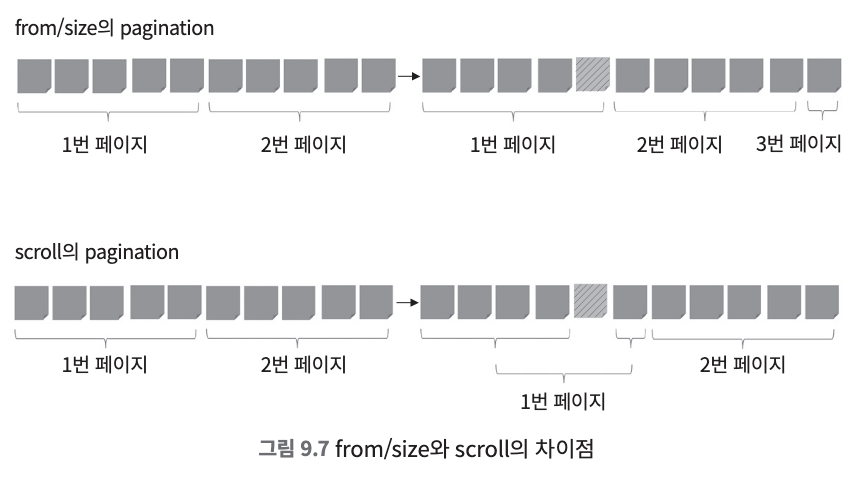
Query DSL이란#
- 검색 쿼리는 Query DSL이라 불리며 크게 Query Context와, Filter Context로 분류한다.
- Query context: Full text search를 의미하며, 검색어가 문서와 얼마나 매칭되는지를 표현하는 score라는 값을 가진다.
- FIlter context: 검색어가 문서에 존재하는지 여부를 Yes나 No 형태의 검색 결과롤 보여준다. score 값을 가지지 않는다.
Query Context#
match 쿼리#
- match 쿼리는 검색어로 들어온 문자열을 analyzer를 통해 분석한 후 inverted index에서 해당 문자열의 토큰을 가지고 있는 문서를 검색한다.
- 문서의 해당 필드에 설정해 놓은 analyzer를 기본으로 사용하며, 별도의 analyzer를 사용할 때는 직접 명시해 주면 된다.
match_phrase 쿼리#
- analyzer를 통해 생성된 토큰들의 순서를 고려한다.
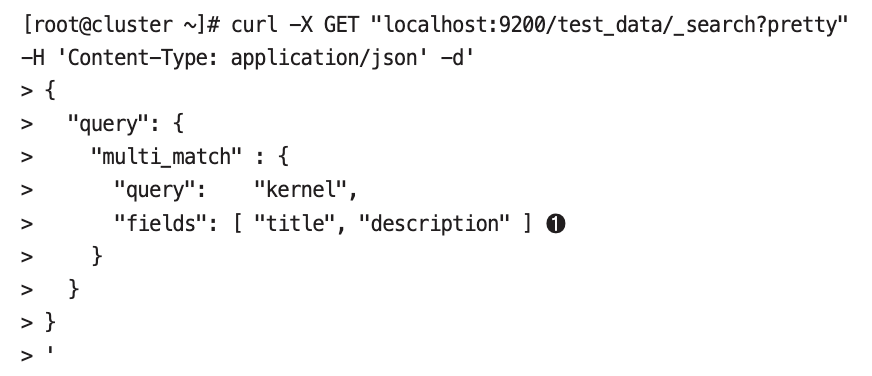
multi_match 쿼리#
- 두 개 이상의 필드에 match 쿼리를 날릴 수 있다.
- 두 필드에서 모두 match가 일어나야되는 것은 아니고, 하나만 만족하면 된다.
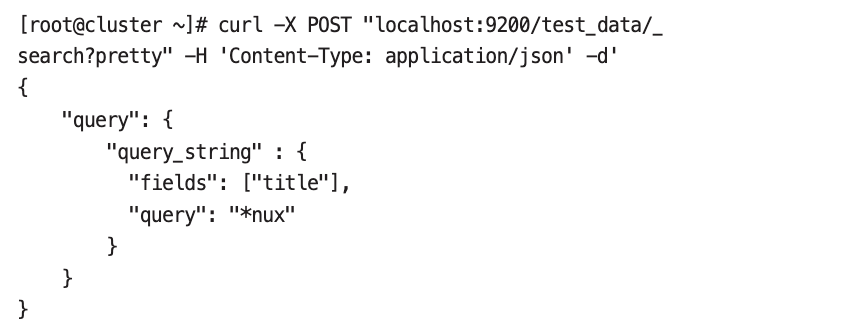
query_string 쿼리#
- and와 or 같은 검색어 간 연결이 필요한 경우에 사용한다.
- query_string 쿼리로 와일드카드 검색을 할 수도 있다.
- 와일드카드 검색은 검색 성능에 좋지 않기 때문에 경우에 따라서는 다른 쿼리로 수정해서 사용하는 것이 좋다.
Filter Context#
term 쿼리#
term 쿼리는 analyze를 하지 않기 때문에 당연히 대소문자를 구분한다.- 보통
text 타입의 필드를 대상으로 할 때는 term 쿼리보다 match 쿼리를 사용하는 것이 일반적이다.
terms 쿼리#
- 둘 이상의
term을 검색할 떄 사용하는 쿼리이며, 다수의 단어를 한 번에 검색할 때 사용한다.
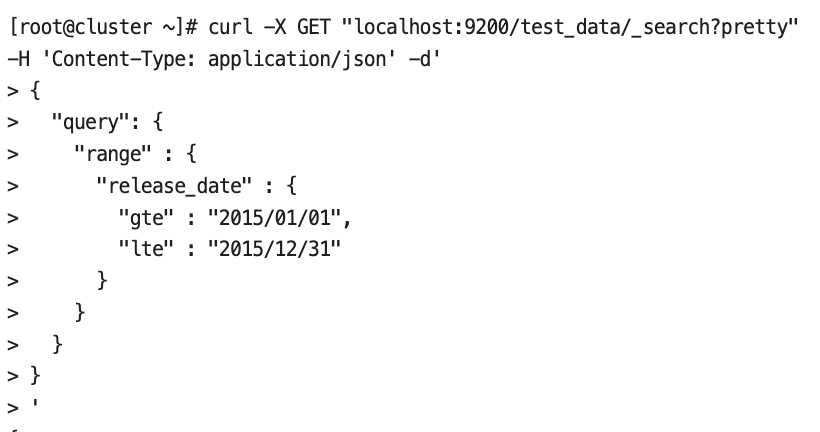
range 쿼리#
- 범위를 지정하여 특정 값의 범위 이내에 있는 경우를 검색할 때 사용한다.
wildcard 쿼리#
- text 필드가 아닌 keyword 타입의 쿼리에 사용해야 한다.
- wildcard query는 모든 inverted index를 하나씩 확인하기 떄문에 검색 속도가 매우 느리다.

bool query를 이용해 쿼리 조합하기#
- bool query에서 사용할 수 있는 항목
must, should는 Query Context에서 실행된다.filter, must_not은 Filter Context에서 실행된다.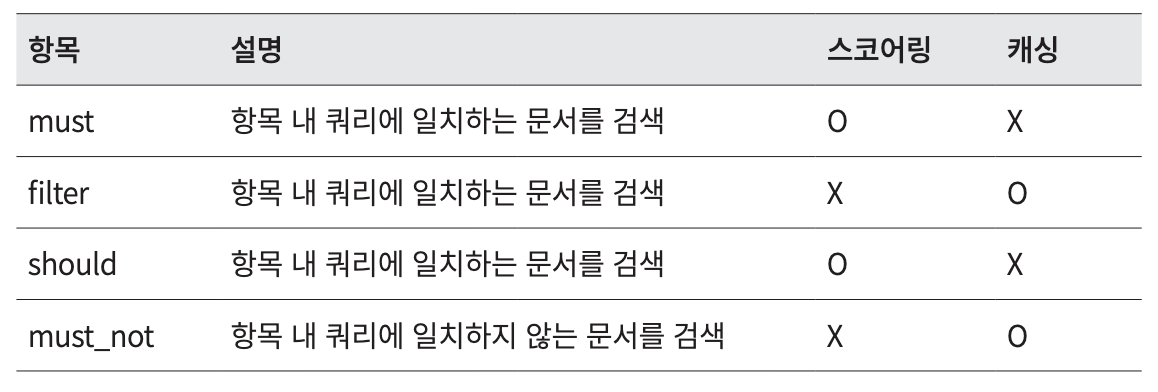
- bool query는 Query/Filter Context를 혼합해서 사용할 수 있다.
- filter context에 포함되는 쿼리들은 filter 절에 넣는 것이 좋다.
- must 절에 포함시켜도 동일한 결과가 나오지만, filter context들이 socre를 계산하는 데 활용되기 때문에 불필요한 연산이 들어가서 검색 속도가 느려진다.
should 절은 minimum_should_match라는 옵션을 제공한다.minimum_should_match 옵션은 should 항목에 포함된 쿼리 중 적어도 설정된 수치만큼의 쿼리가 일치할 때 검색 결과를 보여주는 옵션이다.
should 절은 검색을 통해 문서의 스코어를 올려줄 때 사용할 수 있다.- 따라서
minimum_should_match 옵션이 필수는 아니다.