- 카프카를 사용한 데이터 파이프라인 구축하는 대표적인 사례
- 사례1: 아파치 카프카가 두 개의 엔드포인트 중 하나가 되는 데이터 파이프라인 구축
- 예시: 카프카에서 가져온 데이터를 Amazon S3에 넣거나 몽고DB의 데이터를 카프카로 가져오기
- 사례2: 두 개의 서로 다른 시스템을 연결하는 파이프라인을 만들면서 그 중간에 카프카를 사용하는 경우
- 예시: 트위터에서 카프카로 데이터를 전달한 후 다시 카프카에서 엘라스틱서치로 전달함으로써 트위터에서 가져온 데이터를 엘라스틱서치로 보내는 경우
- 데이터 파이프라인에 있어서 카프카가 갖는 주요한 역할은 데이터 파이프라인의 다양한 단계 사이사이에 있어 매우 크고 안정적인 버퍼 역할을 해 줄 수 있다는 점이다.
- 카프카 커넥트: 외부 시스템(데이터베이스, 파일 시스템 등)과 카프카 간의 데이터 이동을 담당
- 소스 커넥터: 외부 시스템 -> 카프카로 데이터 가져오기
- 싱크 커넥터: 카프카 -> 외부 시스템으로 데이터 내보내기
- 카프카 스트림즈: 실시간 스트림 처리 라이브러리
데이터 파이프라인 구축 시 고려사항#
적시성#
- 하루에 한 번 대량의 데이터를 받는 시스템이 있는 반면 데이터가 생성된 뒤 몇 밀리초 안에 받아야 하는 시스템도 있다.
- 카프카는 쓰는 쪽과 읽는 쪽 사이의 시간적 민감도에 대한 요구 조건을 분리시키는 거대한 버퍼로 생가할 수 있다.
- 이유: 쓰는 쪽에서는 실시간으로 쓸 수 있지만, 읽는 쪽에서는 배치 단위로 읽을 수 있으며 그 반대도 가능하다.
신뢰성#
- 단일 장애점을 최대한 피하는 한편 모든 종류의 장애 발생에 대해 신속하고 자동화된 복구를 수행해야 한다.
- 데이터 유실을 허용하는 시스템도 있지만, 대부분의 경우 최소 한 번을 보장을 요구하는 게 보통이기 때문에 원본 시스템에서 발생한 이벤트가 모두 목적지에 도착해야 한다.
- 카프카는 자체적으로 ‘최소 한 번’ 전달으 보장하며, 트랜잭션 모델이나 고유 키를 지원하는 외부 데이터 저장소와 결합됐을 때 ‘정확히 한 번’까지도 보장이 가능하다.
높으면서도 조정 가능한 처리율#
- 매우 높은 처리율을 가질 수 있도록 확장이 가능해야 한다. 처리율이 갑자기 증가해야 하는 경우에도 적응할 수 있어야 한다.
- 카프카는 높은 처리율을 받아낼 수 있는 분산 시스템이다.
- 이유: 평범한 클러스터에서도 초당 수백 메가 바이트를 처리할 수 있다. 또한, 카프카 커넥트 API는 작업을 병렬화하는 데 초점을 맞추기 때문에 시스템 요구 조건에 따라 하나의 노드에서는 수평 확장된 여러 개의 노드에서든 아무 상관없이 실행될 수 있다.
데이터 형식#
- 데이터 파이프라인에서 가장 중요하게 고려해야 할 것 중 하나는 서로 다른 데이터 형식과 자료형을 적절히 사용하는 것이다.
- 이유: 서로 다른 데이터베이스와 다른 저장 시스템마다 지원되는 자료형은 제각기 다르다.
- 카프카 자체와 커넥트 API는 데이터 형식에 완전히 독립적이다.
- 컨슈머는 필요한 데이터 형식을 지원할 수만 있다면 어떤 시리얼라이저도 쓸 수 있다.
- 카프카 커넥트는 자료형과 스키마를 포함하는 고유한 인덱스 객체들을 가지고 있는데, 이 레코드를 어떠한 형식으로도 저장할 수 있도록 장착 가능한 컨버터 역시 지원한다. 따라서 카프카에 사용하는 데이터 형식이 무엇이든 간에 사용할 수 있는 커넥터는 영향을 받지 않는다.
- 카프카의 데이터를 외부 시스템에 쓸 경우, 싱크 커넥터가 외부 시스템에 쓰여지는 데이터의 형식을 책임진다.
- 예시: S3 커넥터에서는 에이브로 형식과 파케이 형식 중 하나를 고를 수 있다.
- 데이터 파이프라인을 구축하는 방식 2가지: ETL과 ELT
- ETL(Extract-Transform-Load): 데이터 파이프라인이 통과하는 데이터에 변경을 가하는 작업까지도 담당한다.
- ETL 시스템을 구축할 때, 카프카에 한 번 쓰여진 원본 데이터를 다수의 애플리케이션과 대상 시스템이 읽어 갈 수 있는 일대다 파이프라인을 구축할 수 있다는 점을 명심해야된다.
- 장점: 데이터를 수정한 뒤 다시 저장할 필요가 없기 때문에 시간과 공간을 절약할 수 있다.
- 단점: 파이프라인에서 데이터 변환이 일어나기 떄문에, 파이프라인의 하단에서 데이터를 처리하고 할 경우 손쓸 방법이 없다.
- ELT(Extract-Load-Transform): 데이터 파이프라인은 대상 시스템에 전달되는 데이터가 원본 데이터와 최대한 비슷하도록 최소한의 변환만을 수행한다.
- 장점: 대상 시스템의 사용자에게 최대한의 유연성을 제공해 줄 수 있다.
- 단점: 변환 작업이 대상 시스템의 CPU와 자원을 잡아먹는다.
- 카프카 커넥트는 원본 시스템의 데이터를 카프카로 옮길 때 혹은 카프카의 데이터를 대상 시스템으로 옮길 때 단위 레코드를 변환할 수 있게 해주는 단일 메시지 변환 기능을 탑재하고 있다.
- 다른 토픽으로 메시지를 보내거나, 필터링하거나, 자료형을 바꾸거나, 특정한 필드를 삭제하거나 하는 등의 기능을 포함한다.
- 조인이나 집적과 같이 더 복잡한 변환 작업은 카프카 스트림을 사용해서 처리할 수 있다.
- 카프카는 소스에서 카프카로 데이터를 보내거나 아니면 카프카에서 싱크로 데이터를 보내는 데이터 전송 과정에서 데이터 암호화를 지원한다.
- SASL을 사용한 인증과 인가 역시 지원한다.
- 카프카는 허가받거나 허가받지 않은 접근 내역을 추적할 수 있는 감사 로그 역시 지원한다.
- 카프카 커넥트와 커넥터는 외부 데이터 시스템에 연결하고,인들할 수 있어야 하며 커넥터 설정 역시 외부 데이터 시스템의 인증을 통과할 수 있도록 자격 증명을 포함해야 한다.
장애 처리#
- 모든 이벤트를 장기간에 걸쳐 저장하도록 카프카를 설정할 수 있기 때문에, 필요할 경우 이전 시점으로 돌아가서 에러를 복구할 수 있다.
- 만약 대상 시스템이 유실되었을 경우, 카프카에 저장된 이벤트들을 재생하는 것역시 가능하다.
결합과 민첩성#
- 데이터 파이프라인을 구현할 때 중요한 것 중 하나는 데이터 원본과 대상을 분리할 수 있어야 한다.
- 의도치 않게 결합이 생길 수 있는 경우는 다음과 같다.
- 임기응변 파이프라인: 어떤 조직들은 애플리케이션을 연결해야 할 때마다 커스텀 파이프라인을 구축한다.
- 예시: 로그스태시를 사용해서 로그를 엘라스틱서치에 밀어 넣는다.
- 문제점1: 이 경우 데이터 파이프라인이 특정한 엔드포인트에 강하게 결합되기 때문에 설치, 유지 보수, 모니터링에 상당한 노력이 소요되어야 하는결과물이 나오기 쉽다.
- 문제점2: 새로운 시스템을 도입할 때마다 추가적인 데이터 파이프라인을 구축해야 한다.
- 메타데이터 유실: 만약 데이터 파이프라인이 스키마 메타데이터를 보존하지 않고 스키마 진화 역시 지원하지 않는 경우
- 문제점1: 소스 쪽에서 데이터를 생성하는 소프트웨어와 싱크 쪽에서 데이터를 사용하는 소프트웨어를 강하게 결합시키게 된다.
- 문제점2: 스키마 정보가 없기 때문에, 두 소프트웨어 모두 데이터를 파싱하고 해석하는 방법에 대해 알고 있어야 한다.
- 과도한 처리: 파이프라인에서 너무 많은 데이터 처리를 하는 경우
- 가능하면 가공 되지않은 로데이터를 가능한 한 건드리지 않은 채로 하단에 있는 애플리케이션으로 내려보내고, 데이터를 처리하고 집적하는 방법은 애플리케이션이 알아서 결정하게 하는 것이 좀 더 유연한 방법이다.
- 문제점1: 하단에 있는 시스템들이 데이터 파이프라인을 구축할 때 어떤 필드를 보존할지, 어떻게 데이터를 집적할지 등에 선택지가 별로 남지 않게 된다.
- 문제점2: 하단에 있는 애플리케이션의 요구 조건이 변견 될 때마다 계속해서 파이프라인도 변경해 줘야 하는 사태가 발생하는데, 이것은 유연하지도, 효율적이지도, 안전하지도 않다.
카프카 커넥트 vs. 프로듀서/컨슈머#
- 카프카 커넥트는 카프카를 직접 코드나 API를 작성하지 않았고, 변경도 할 수 없는 데이터 저장소에 연결시켜야 할 때 쓴다.
- 카프카 커넥트를 사용해서 외부 데이터 저장소의 데이터를 카프카로 가져올 수도, 카프카에 저장된 데이터를 외부 저장소로 내보낼 수도 있다.
- 카프카 커넥트를 사용하려면 연결하고자 하는 데이터 저장소에 맞는 커넥터가 필요한데, 요즘은 많은 커넥터가 나와 있다.
- 만약 카프카와 연결하고자 하는 데이터 저장소의 커넥터가 아직 없다면, 카프카 클라이언트 또는 커넥트 API 둘 중 하나를 사용해서 애플리케이션을 직접 작성할 수 있다.
- 커넥트 API 쪽이 설정 관리, 오프셋 저장, 병렬 처리, 에러 처리, 서로 다른 데이터 형식 지원 및 REST API를 통한 표준화된 관리 기능을 제공하는 만큼 후자를 사용하길 권장한다.
- 카프카 커넥트는 카프카 생태계의 표준화된 일부일 뿐만 아니라 작업 대부분을 대신 처리해 준다.
카프카 커넥트#
- 커넥터 플러그인: 카프카 커넥트가 실행시키는 라이브러리로, 데이터를 이동시키는 것을 담당한다.
- 커넥트는 커넥터 플러그인을 개발하고 실행하기 위한 API와 런타임을 제공한다.
- 카프카 커넥트는 여러 워커 프로세스들의 클러스터 형태로 실행된다.
- 사용자는 워커에 커넥터 플러그인을 설치한 뒤 REST API를 사용해서 커넥터별 설정을 잡아 주거나 관리해주면 된다.
- 커넥터는 대용량의 데이터 이동을 병렬화해서 처리하고 워커 유휴 자원을 더 효율적으로 활용하기 위해 태스크를 추가로 실행시킨다.
- 소스 커넥터 태스크: 원본 시스템으로부터 데이터를 읽어 와서 커넥트 자료 객체의 형태로 워커 프로세스에 전달한다.
- 싱크 커넥터 태스크: 워커로부터 커넥트 자료 객체를 받아서 대상 시스템에 쓰는 작업을 담당한다.
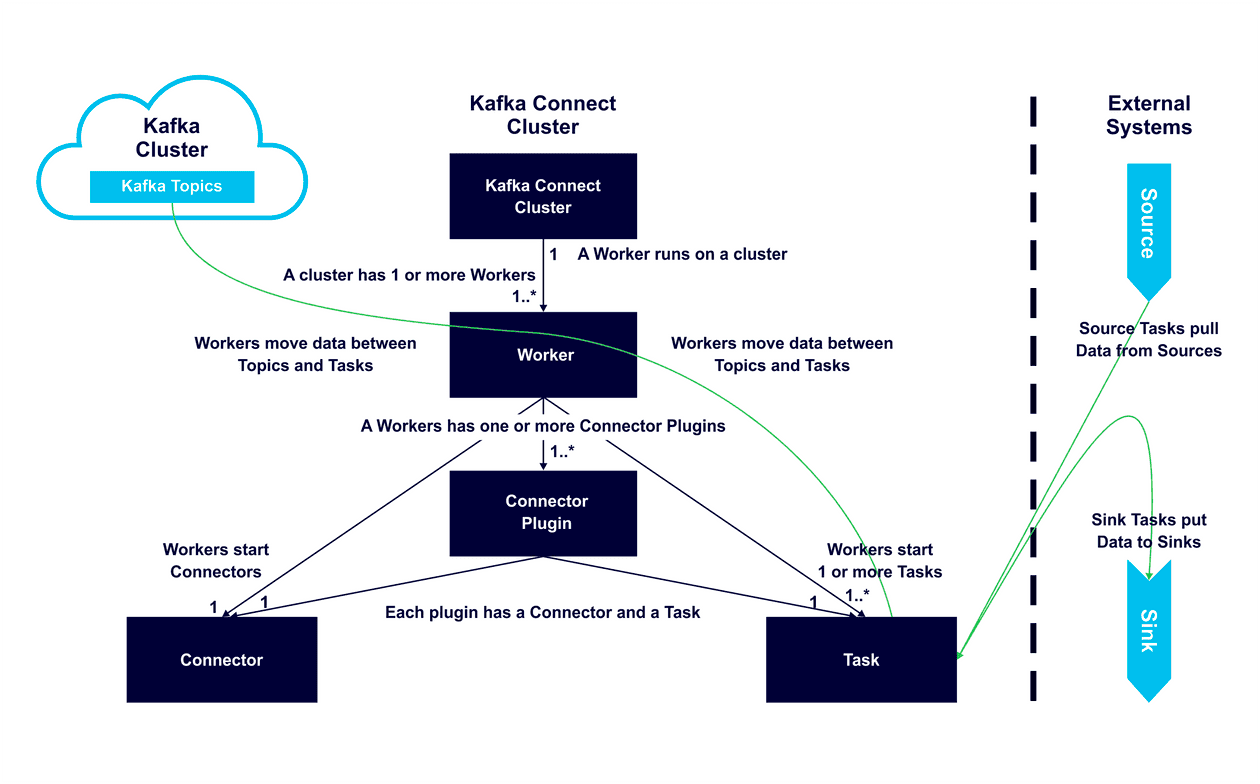
- 카프카 커넥트는 자료 객체를 카프카에 쓸 떄 사용되는 형식으로 바꿀 수 있또록 컨버터를 사용한다.
- JSON 형식은 기본적으로 지원되며, 컨플루언트 스키마 레지스트리와 함꼐 사용할 경우 Avro, Protobuf, 그리고 JSON 스키마 컨버터가 지원된다.
카프카 커넥트 실행하기#
- 카프카 커넥트는 아파치 카프카에 포함되어 배포되므로 별도로 설치할 필요는 없다.
- 카프카 커넥트를 프로덕션 환경에서 사용할 경우, 카프카 브로커와는 별도의 서버에 커넥트를 실행시켜야 한다.
- 커넥트 워커 핵심 설정
bootstrap.servers- 카프카 커넥트와 함께 작동하는 카프카 브로커의 목록
- 클러스터 안의 모든 브로커를 지정할 필요는 없지만, 최소 3개 이상이 권장된다.
group.id- 동일한 그룹 ID를 갖는 모든 워커들은 같은 커넥트 클러스터를 구성한다.
plugin.path- 카프카 커넥트가 커넥터와 그 의존성들을 찾을 수 있는 디렉토리
- 카프카 커넥트는 커넥터, 컨버터, 트랜스포메이션, 그리고 비밀 제공자를 다운받아서 플랫폼에 플러그인할 수 있도록 설계되어 있다.
key.converter와 value.converter- 커넥트는 카프카에 저장된 여러 형식의 데이터를 처리할 수 있다. 카프카에 저장될 메시지의 키와 밸류 부분 각각에 대해 컨버터를 설정해 줄 수 있다.
- 어떤 컨버터에는 해당 컨버터에만 한정해서 사용 가능한 설정 매개변수들이 있다.
- 매개변수 이름 앞에
key.converter.나 value.converter.를 붙여 줌으로써 설정이 가능하다. - 예시: JSON 메시지는 스키마를 포함할 수도 있고 아닐 수도 있는데, 어느 한쪽을 선택하고 싶다면
key.converter.schemas.enable를 true 혹은 false로 잡아주면 된다.
rest.host.name과 rest.port- 커넥터를 설정하거나 모니터링할 때는 카프카 커넥트의 REST API를 사용하는 것이 보통이다.
- base url을 호출하면 현재 실행되고 있는 카프카 버전을 확인할 수 있다.
{baseUrl}/connector-plugins를 호출하면 사용 가능한 커넥터 목록 역시 확인이 가능하다.
커넥터 예제: 파일 소스와 파일 싱크#
- 목표: 카프카 설정을 읽어 오도록 커넥터를 설정한다. 즉, 카프카의 설정을 카프카 토픽으로 보내는 셈이다.
- REST API로 커넥터를 생성한다.
- 커넥터 이름과 설정 맵을 포함하는 JSON 형식을 사용하였다.
- 설정 맵에는 커넥터 클래스 이름, 읽고자 하는 파일의 위치, 그리고 파일에서 읽은 내용을 보내고자 하는 토픽 이름이 포함된다.
- 이 커텍터는
config/server.properties 파일의 내용물이 커넥터에 의해 줄 단위로 JSON으로 변환된 뒤 kafka-config-topic 토픽에 저장된 것이다. 
- REST API로 싱크 커넥터를 생성한다.
- 클래스 이름이
FileStreamSink이다. file 속성은 레코드를 쓸 파일을 가리킨다.- 토픽 하나를 지정하는 대신 다수의 토픽일 지정한다.
- 복수형인 데서알 수 있 듯이 여러 토픽의 내용물을 하나의 싱크 파일에 쓸 수 있다.
- 하지만, 소스 커넥터는 하나의 토픽에만 쓸 수 있다.

- 커넥터를 삭제하려면 다음과 같이 한다.
커넥터 예제: MySQL에서 Elasticsearch로 데이터 보내기#
- 목표: MySQL 테이블 하나의 내용을 카프카 토픽으로 보낸 뒤, 여기서 다시 엘라스틱서치로 보내서 내용물을 인덱스하게 해보자.
- 엘라스틱서치와 JDBC 커넥터 다운로드
- 방법1: 컨플루언트 허브 클라이언트를 사용해서 다운로드하고 설치한다.
- 방법2: 컴프루언트 허브 웹사이트에서 다운로드한다.
- 방법3: 소스코드에서 직접 빌드한다.
- 커넥터를 적재한다.
/opt/connectors 같은 디렉토리를 만든 뒤 config/connect-distributed.properties 를 수정하여 plug.path=/opt/connectors라고 넣어 주자.
- MySQL에 접속하기 위해 MySQL JDBC 드라이버를 다운로드해서
/opt/connectors/jdbc 아래 넣어주자.
- 카프카 커넥트 워커를 재시작한 뒤 새로 설치해준 플러그인들이 보이는지 확인한다.
- JDBC 소스 커넥터에 사용 가능한 옵션들에 대해서는 REST API를 사용해서 확인 가능하다.
- 유효성 검사할 때 쓰이는 REST API에 클래스 이름만 포함되어 있는 설정을 보냈다.

- JDBC 커넥터를 설정하고 생성한다.
- 엘라스틱서치 싱크 커넥터를 생성한다.
connection.url: 엘라스틱서버의 URL- 기본적으로 카프카의 각 토픽은 별개의 엘라스틱서치 인덱스와 동기화된다. (인덱스의 이름은 토픽과 동일하다)
- 여기서는
mysql.login 토픽의 엘라스틱서치에 쓴다.
key.ignore을 true로 잡아주면 메시지의 키를 엘라스틱서치 문서의 id로 사용하지 않고, 자동으로 생성한다.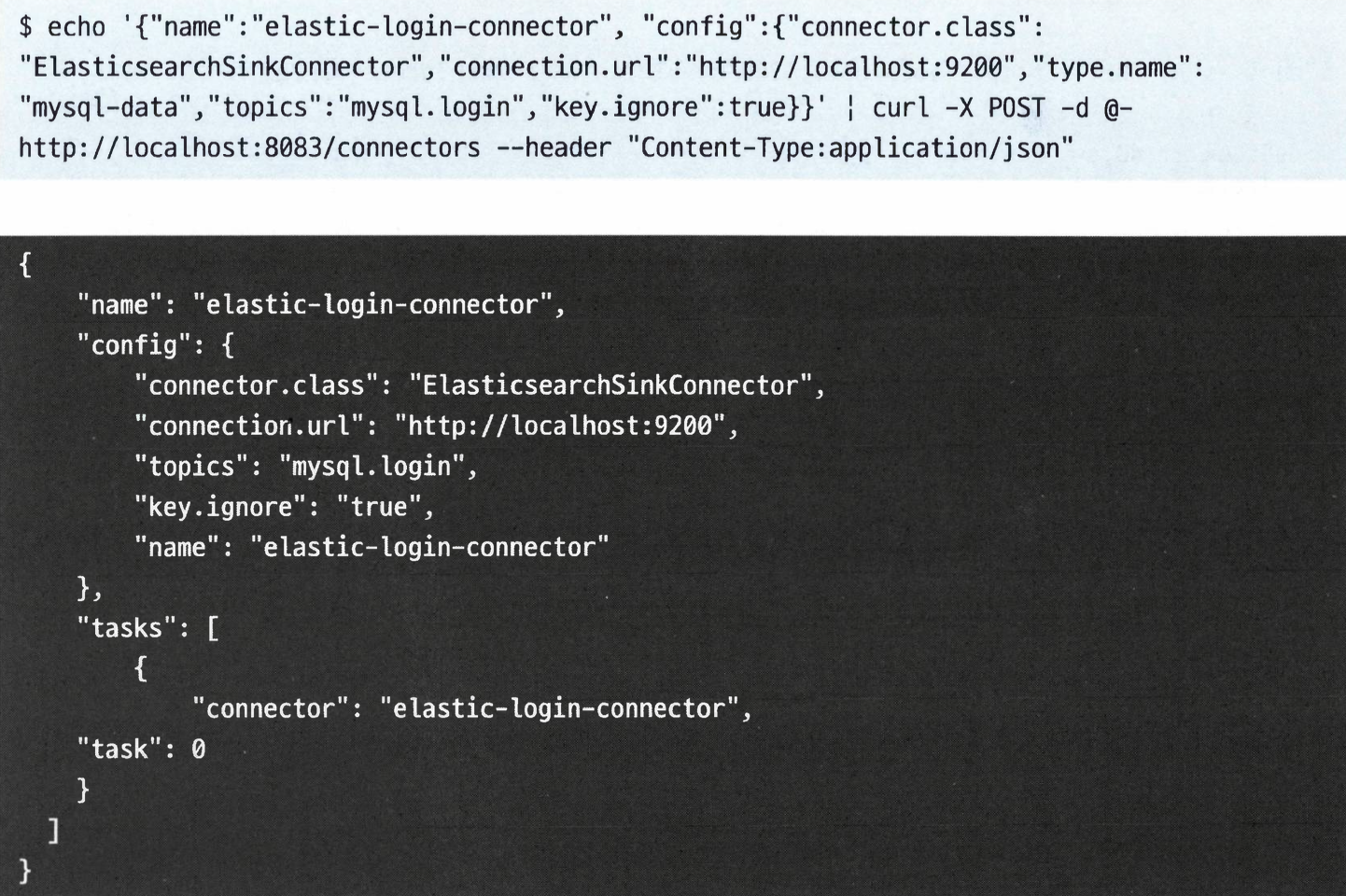
- 여기까지까지 하면 MySQL 테이블에 새 레코드를 추가할 떄마다 해당 레코드가 카프카의
mysql.login 토픽 그리고 여기에 대응하는 엘라스틱서치 인덱스에 자동으로 나타날 것이다.
변경 데이터 캡처와 디비지움 프로젝트#
- JDBC 커넥터는 JDBC와 SQL을 사용해서 데이터베이스 테이블에 새로 들어온 레코드를 찾아낸다.
- 구체적으로 타임스탬프 필드와 기본 키가 증가하는 것을 사용해서 새 레코드를 탐지하는데, 이 방식은 다소 비효율적일 뿐만 아니라 때로는 정확하지 않은 결과물을 낸다.
- 변경 데이터 캡처(Change Data Capture, CDC): 트랜잭션 로그를 읽음으로써 관계형 데이터베이스 내용물의 변경을 탐지하는 방식
- CDC 방식이 더 정확하고 효율적이다.
- 대부분의 최신 ETL 시스템들은 CDC를 데이터 저장소로서 사용한다.
- Debezium에 포함된 CDC 커넥터를 사용할 것을 강력하게 권장한다.
개별 메시지 변환#
- 개별 메시지 변환(single message transformation, SMT): 카프카 커넥트가 메시지를 복사하는 도중에 데이터 변환 작업의 일부로서, 보통 코들르 작성할 필요 없이 수행한다.
- 아파치 카프카는 다음과 같은 SMT들을 포함한다.
카프카 커넥트: 좀 더 자세히 알아보기#
- 커넥터와 태스크
- 커넥터 플러그인은 커넥터 API를 구현한다. 이것은 아래에서 설명하는 커넥터와 태스크 두 부분을 포함한다.
- 커넥터가 하는 3가지 작업
- 커넥터에서 몇 개의 태스크가 실행되어야 하는지 결정한다.
- 데이터 복사 작업을 각 태스크에 어떻게 분할해 줄지 결정한다.
- 워커로부터 태스크 설정을 얻어와서 태스크에 전달해준다.
- 태스크: 데이터를 실제로 카프카에 넣거나 가져오는 작업을 담당한다.
- 모든 태스크는 워커로부터 컨텍스틀르 받아와서 초기화된다.
- 소스 컨텍스트: 소스 커넥터가 소스 레코드의 오프셋을 저장할 수 있게 해주는 객체를 포함한다.
- 싱크 컨텍스트: 싱크 커넥터가 카프카로부터 받은 레코드를 제어할 수 있는데, 이를 백프레셔를 적용하거나, 재시도를 하거나, ‘정확히 한 번’ 전달을 위해 오프셋을 외부에 저장하거나 할 때 사용된다.
- 태스크가 시작되면 소스 태스크는 외부 시스템을 폴링해서 워커가 카프카 브로커로 보낼 레코드 리스트를 리턴한다.
- 싱크 태스크는 워커를 통해 카프카 레코드를 받아서 외부 시스템에 쓰는 작업을 담당한다.
- 워커
- 역할1: 커넥터와 그 설정을 정의하는 HTTP 요청을 처리할 뿐만 아니라 커넥터 설정을 내부 토픽에 저장한다.
- 역할2: 커넥터와 태스크를 실행시키고, 여기에 적절한 설정값을 전달해주는 역할을 한다.
- 역할3: 만약 워커 프로세스가 정지하거나 크래시 날 경우, 커넥트 클러스터 안의 다른 워커들이 이것을 감지해서 해당 워커에서 실행중이던 커넥터와 태스크를 다른 워커로 재할당한다.
- 역할4: 만약 새로운 워커가 커넥트 클러스터에 추가된다면, 다른 워커들이 이것을 감지해서 모든 워커 간에 부하가 균형이 잡히도록 커넥터와 태스크를 할당해준다.
- 역할5: 소스와 싱크 커넥터의 오프셋을 내부 카프카 토픽에 자동으로 커밋하는 작업과 태스크에서 에러가 발생할 경우, 재시도하는 작업도 한다.
- 컨버터 및 커넥트 데이터 모델
- 카프카 커넥터 API에는 데이터 API가 포함되어 있다.
- 데이터 API는 데이터 객체와 이 객체의 구조를 나타내는 스키마 모두를 다룬다.
- 사용자가 워커나 커넥터를 설정할 때, 카프카에 데이터를 저장할 때 사용하고자하는 컨버터를 선택해 준다.
- 사용가능한 컨버터: 기본 데이터 타입, 바이트 배열, 문자열, Avro, JSON, 스키마가 있는 JSON, Protobuf
- 커넥터가 데이터 API 객체를 워커에 리턴하면, 워커는 설정된 컨버터를 사용해서 이 레코드를 Avro 객체나 JSON 객체, 혹은 문자열로 변환한 뒤 카프카에 쓴다.
- 싱크 커넥터에서는 정확히 반대 방향의 처리 과정을 거친다.
- 오프셋 관리
- 소스 커넥터의 경우,
- 커넥터가 커넥트 워커에 리턴되는 레코드에는 논리적인 파티션과 오프셋이 포함된다.
- 이것은 카프카의 파티션과 오프셋이 아니라 원본 시스템에서 필요로 하는 파티션과 오프셋이다.
- 워커는 레코드를 성공적으로 쓴 뒤 해당 요청에 대한 응답을 보내면, 방금전 카프카로 보낸 레코드에 대한 오프셋을 저장한다.
- 이렇게 함으로써 커넥터는 재시작 혹은 크래시 발생 후에도 마지막으로 저장되었던 오프셋에서부터 이벤트 처리를 시작할 수 있다.
- 이 오프셋은 대체로 카프카 토픽에 저장되지만, 저장소 메커니즘 자체가 플로그인이 가능한 구조이기 때문에 오프셋 저장위치를 바꿀 수 있다.
- 카프카에 저장할 경우,
offset.storage.topic 설정을 사용해서 토픽 이름을 바꿀 수 있다.
- 싱크 커넥터의 경우,
- 토픽, 파티션, 오프셋 식별자가 이미 포함되 어씽쓴 카프카 레코드를 읽은 뒤 커넥터의
put() 메서드를 호출해서 이 레코드를 대상 시스템에 저장한다.
- 작업이 성공하면 싱크 커넥터는 커넥터에 주어졌던 오프셋을 카프카에 커밋한다.
카프카 커넥트의 대안#
다른 데이터 저장소를 위한 수집 프레임워크#
- 카프카가 아키텍처의 핵심 부분이면서 많은 수의 소스와 싱크를 연결하는 것이 목표라면 카프카 커넥트 API를 추천한다.
- 하지만 실제로 구축중인 것이 하둡 중심, 혹은 엘라스틱서치 중심이고 카프카는 그저 해당 시스템의 수많은 입력 중 하나일 뿐이라면 플룸이나 로그스태시를 쓰는 것이 더 바람직할 것이다.
GUI 기반 ETL 툴#
- 인포매티카와 같은 전통적인 시스템이나 오픈소스 기반의 탈렌드와 펜타호, 아파치 나이파이나 스트림세츠와 같은 상대적으로 새로운 대안들 모두가 아파치 카프카와의 데이터 교환을 지원한다.
- 장점: GUI 기반으로 ETL 파이프라인을 개발하고 있을 경우에 합리적인 선택이다.
- 단점: 대개 복잡한 워크플로를 상정하고 개발되었다는 점과 단순히 카프카와의 데이터 교환이 목적일 경우 다소 무겁고 복잡할 수 있다.
스트림 프로세싱 프레임워크#
- 대부분의 스트림 처리 프레임워크는 카프카에서 이벤트를 읽어와서 다른 시스템에 쓰는 기능을 포함한다.
- 장점: 스트림 처리 워크플로에서 스트림 처리 워크플로에서 한 단계를 줄일 수 있다.
- 단점: 메시지 유실이나 오염과 같은 문제에 대응하기는 좀 더 어려울 수 있다.



