- 옵티마이저의 기능: 쿼리를 최적으로 실행하기 위해 각 테이블의 데이터가 어떤 분포로 저장돼 있는지 통계 정보를 참조하며, 그러한 기본 데이터를 비교해 최적의 실행 계획을 수립한다.
EXPLAIN명령으로 쿼리의 실행 계획을 확인할 수 있다.
개요
쿼리 실행 절차
- SQL 파싱: 사용자로부터 요청된 SQL 문장을 잘게 쪼개서 MySQL 서버가 이해할 수 있는 수준으로 분리(파스 트리)한다.
- SQL 파서라는 모듈에서 처리한다.
- 최적화 및 실행 계획 수립: SQL의 파싱 트리를 확인하면서 어떤 테이블부터 읽거 어떤 인덱스를 이용해 테이블을 읽을지 선택한다.
- MySQL 서버의 옵티마이저에서 처리한다.
- 불필요한 조건 제거 및 복잡한 연산의 단순화
- 여러 테이블의 조인이 있는 경우 어떤 순서로 테이블을 읽을지 결정
- 각 테이블에 사용된 조건과 인덱스 통계 정보를 이용해 사용할 인덱스 결정
- 가져온 테이블을 임시 테이블에 넣고 다시 한번 가공해야 하는지 결정
- 두 번째 단계에서 결정된 테이블의 읽기 순서나 선택된 인덱스를 이용해 스토리지 엔진으로부터 데이터를 가져온다.
옵티마이저의 종류
- 규칙 기반 최적화 (Rule-based optimizer, RBO)
- 대상 테이블의 건수나 선택도 등을 고려하지 않고 옵티마이저에 내장된 우선순위에 따라 실행 계획을 수립한다.
- 같은 쿼리에 대해서 거의 항상 같은 실행 방법을 만든다.
- 사용자의 데이터는 분포도가 매우 다양하기 때문에 규칙 기반의 최적화는 이미 오래전부터 많은 DBMS에서 사용하지 않는다.
- 비용 기반 최적화 (Cost-based optimizer, CBO)
- 쿼리를 처리하기 위한 여러 가지 가능한 방법을 만들고, ㅁ각 단위 작업의 비용 정보와 대상 테이블의 예측된 통계 정보를 이용해 실행 계획별 비용을 산출한다.
기본 데이터 처리
풀 테이블 스캔과 풀 인덱스 스캔
- InnoDB는 풀 테이블 스캔이나 풀 인덱스 스캔을 실행할 때 한꺼번에 여러 개의 블록이나 페이지를 읽어오는 기능을 내장하고 있다.
- 특정 테이블의 연속된 데이터 페이지가 읽히면 백그라운드 스레드에 의해 리드 어헤드(Read ahead) 작업이 자동으로 시작한다.
- 리드 어헤드: 어떤 영역의 데이터가 앞으로 필요해지리라는 것을 예측해서 요청이 오기 전에 미리 디스크에서 읽어 InnoDB의 버퍼 풀에 가져다 두는 것
- 풀 테이블 스캔이 실행되면 처음 몇 개의 데이터 페이지는 포그라운드 스레드가 페이지 읽기를 실행하지만 특정 시점부터는 읽기 작업을 백그라운드 스레드로 넘긴다.
- 백그라운드 스레드가 읽기를 넘겨받은 시점부터는 한 번에 4개 또는 8개씩 페이지를 읽으면서 계속 그 수를 증가시킨다.
- 포그라운드 스레드는 미리 버퍼 풀에 준비된 데이터를 가져다 사용하기만 하면 되므로 쿼리가 상당히빨리 처리되는 것이다.
- 백그라운드 스레드로 넘어가는 시점은
innodb_read_ahead_threshold시스템 변수에 설정된 개수만큼 연속된 데이터가 읽히는 시점이다.
병렬 처리
- MySQL 8.0 버전부터는 한정적으로 하나의 쿼리를 여러 스레드가 작업을 나누어 동시 처리할 수 있다.
innodb_parallel_read_threads라는 시스템 변수를 이용하면, 아무런WHERE조건 없이 단순히 테이블의 전체 건수를 가져오는 쿼리만 병렬로 처리할 수 있다.

ORDER BY 처리(Using filesort)
정렬을 처리하는 방법은 인덱스를 이용하는 방법과 쿼리가 실행될 때 “Filesort"라는 별도의 처리를 이용하는 방법으로 나눌 수 있다.
- 인덱스 이용
- 장점: 이미 인덱스가 정렬돼 있어서 순서대로 읽기만하면 되므로 매우 빠르다.
- 단점:
INSERT,UPDATE,DELETE작업 시 부가적인 인덱스 추가/삭제 작업이 필요하므로 느리다. 인덱스 때문에 디스크 공간이 더 많이 필요하다. 인덱스의 개수가 늘어날수록 InnoDB의 버퍼 풀을 위한 메모리가 많이 필요하다.
- Filesort 이용
- 장점: 인덱스를 생성하지 않아도 되므로 인덱스를 이용할 때 단점이 장점으로 바뀐다. 정렬해야 할 레코드가 많지 않으면 메모리에서 Filesort가 되므로 충분히 빠르다.
- 단점: 정렬 작업이 쿼리 실행 시 처리되므로 레코드 대상 건수가 많아질수록 응답 속도가 느리다.
- 인덱스 이용
MySQL 서버에서 인덱스를 이용하지 않고 별도의 정렬 처리를 수행했는지는 실행 계획의
Extra컬럼에 “Using filesort” 메시지가 표시되는지 여부로 판단할 수 있다.소트 버퍼: MySQL은 정렬을 수행하기 위해 별도의 메모리 공간을 할당받아서 사용하는데, 이 메모리 공간을 소트 버퍼라고 한다.
- 소트 버퍼의 크기는 정렬해야 할 레코드의 크기에 따라 가변적으로 증가하지만 최대 사용 가능한 소트 버퍼의 공간은
sort_buffer_size라는 시스템 변수로 설정할 수 있다. - 정렬해야 할 레코드의 건수가 소트 버퍼의 최대 용량보다 커지면, 정렬해야할 레코드를 여러 조각으로 나눠서 처리하고 이 과정에서 임시 저장을 위해 디스크를 사용한다.
- 메모리의 소트 버퍼에서 정렬을 수행하고 그 결과를 임시로 디스크에 기록해두고, 그 다음 레코드를 가져와 다시 정렬해서 반복적으로 수행한다.
- 각 버퍼 크기만큼 정렬된 레코드를 다시 병합하면서 정렬을 수행한다.
sort_buffer_size가 클수록 처리가 빨라질 것으로 예상하지만, 너무 클 경우 큰 메모리 공간 할당 때문에 성능이 훨씬 떨어질 수도 있다.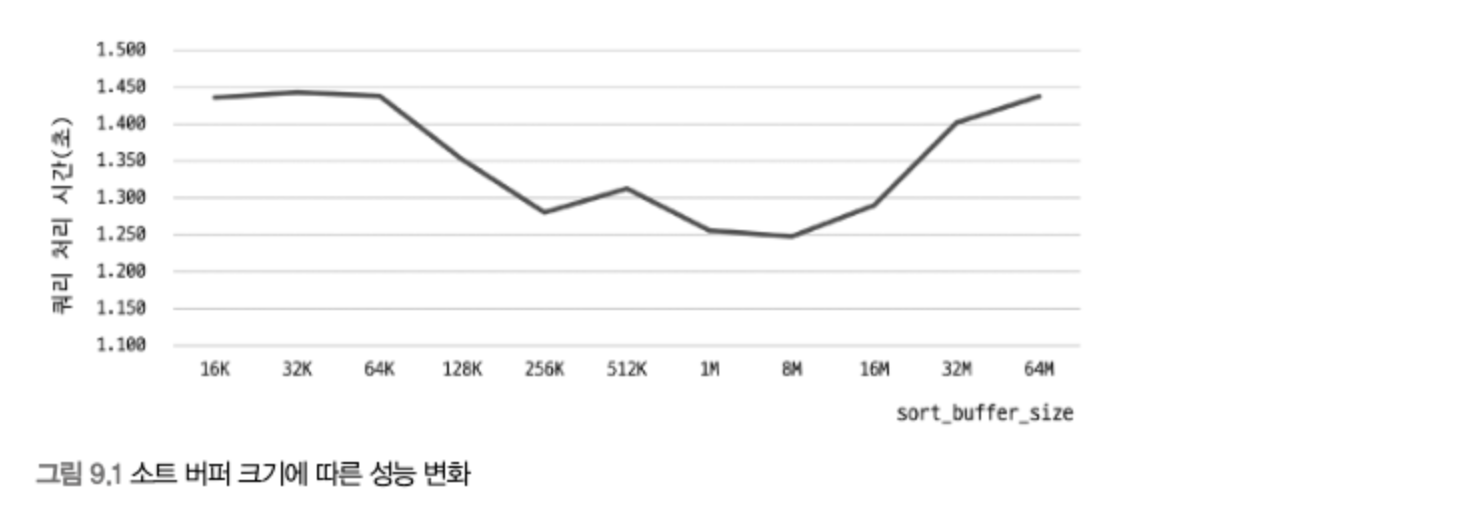
- 소트 버퍼의 크기는 정렬해야 할 레코드의 크기에 따라 가변적으로 증가하지만 최대 사용 가능한 소트 버퍼의 공간은
정렬 알고리즘
- 공식 명칭은 아니지만 “싱글 패스(single-pass)“와 “투 패스(two-pass)” 2가지 정렬 모드로 나눌 수 있다.
- 싱글 패스: 정렬할 때 레코드 전체를 소트 버퍼에 담음
- 투 패스: 정렬할 때 정렬 기준 컬럼만 소트 버퍼에 담음
- 싱글 패스 방식은 정렬 대상 레코드의 크기나 건수가 작은 경우 빠른 성능을 보이며, 투 패스 방식은 정렬 대상 레코드의 크기나 건수가 상당히 많은 경우 효율적이다.
- 최신 버전에서는 일반적으로 싱글 패스 정렬을 주로 사용하지만, 다음의 경우에는 투 패스 정렬 방식을 사용한다.
- 레코드의 크기가
max_length_for_sort_data시스템 변수에 설정된 값보다 클 때 - BLOB이나 TEXT 타입의 컬럼이 SELECT 대상에 포함할 때
- 레코드의 크기가
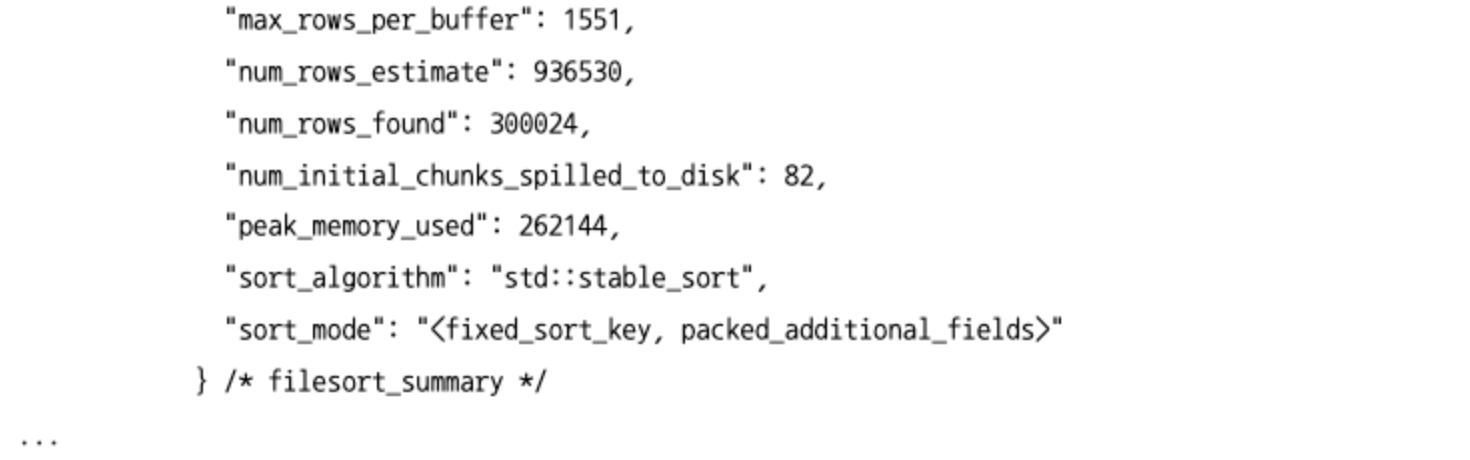
SELECT쿼리에서 꼭 필요한 컬럼만 조회하고, 모든 컬럼(*)을 가져오지 않도록 개발하라고 권장하는 이유 중 하나가 이런 정렬 알고리즘의 선택 때문이다.- 현재 어떤 정렬 모드를 사용하는지는 다음과 같이 옵티마이저 트레이스 기능으로 확인할 수 있다.
- 아래 출력된 내용에서 “filesort-summary” 섹션의 “sort_algorithm” 필드에 정렬 알고리즘이 표시된다.
<sort_key, rowid>: 정렬 키와 레코드의 로우 아이디만 가져와서 정렬하는 방식(투 패스)<sort_key, additional_fields>: 정렬 키와 레코드 전체를 가져와서 정렬하는 방식으로, 레코드의 컬럼들을 고정 사이즈로 메모리 저장(원 패스)<sort_key, packed_additional_fields>: 정렬 키와 레코드 전체를 가져와서 정렬하는 방식으로, 레코드의 컬럼들은 가변 사이즈로 메모리 저장(원 패스)
- 아래 출력된 내용에서 “sort_algorithm” 필드에 보여진 “std:stable_sort"는 MySQL 서버에서 실제 정렬을 수행할 때 사용한 라이브러리의 함수 이름을 보여준다. (C++의 STL에서 제공된
stable_sort()함수를 사용함)- 운영체제별로 STL의
stable_sort()함수가 어떤 정렬 알고리즘을 사용하는지는 조금씩 차이가 있다. 리눅스 서버에서 사용하는 GNU C++의 STL에서는 퀵 소트와 힙 소트 알고리즘을 복합적으로 사용한다.
- 운영체제별로 STL의

- 공식 명칭은 아니지만 “싱글 패스(single-pass)“와 “투 패스(two-pass)” 2가지 정렬 모드로 나눌 수 있다.
정렬 처리 방법: 쿼리에
ORDER BY가 사용되면 반드시 다음 3가지 처리 방법 중 하나로 정렬이 처리된다. 일반적으로 아래쪽에 있는 정렬 방법으로 갈수록 처리 속도는 떨어진다.- 일반적으로 조인이 수행되면서 레코드 건수와 레코드의 크기는 거의 배수로 불어나기 때문에 가능하다면 드라이빙 테이블만 정렬한 다음 조인을 수행하는 방법을 사용한다.
| 정렬 처리 방법 | 실행 계획의 Extra 칼럼 내용 |
|---|---|
| 인덱스를 사용한 정렬 | 별도 표기 없음 |
| 조인에서 드라이빙 테이블만 정렬 | “Using filesort” 메시지가 표시됨 |
| 조인에서 조인 결과를 임시 테이블로 저장 후 정렬 | “Using temporary; Using filesort” 메시지가 표시됨 |
- 인덱스를 이용한 정렬
- 조건
ORDER BY에 명시된 컬럼이 제일 먼저 읽는 테이블(드라이빙 테이블)에 속하고,ORDER BY의 순서대로 생성된 인덱스가 있어야한다.WHERE절에 첫 번째로 읽는 테이블의 컬럼에 대한 조건이 있담녀 그 조건과ORDER BY는 같은 인덱스를 사용할 수 있어야 한다.- 여러 테이블이 조인되는 경우에는 nested-loop 방식의 조인에서만 사용할 수 있다.
- 만약 조인이 사용된 쿼리의 실행 계획에 조인 버퍼(join buffer)가 사용되면 순서가 흐트러질 수 있기 때문에, 인덱스를 사용하지 못한다.
- 조건
- 조인의 드라이빙 테이블만 정렬
- 조건
- 조인에서 드라이빙 테이블의 컬럼만으로
ORDER BY절을 작성해야 한다.
- 조인에서 드라이빙 테이블의 컬럼만으로
- 조건
- 정렬 처리 방법의 성능 비교
ORDER BY와LIMIT이 같이 사용되면, 조건을 만족하는 레코드를 모두 가져와서 정렬을 수행하거나 그루핑 작업을 실행해야만 비로소LIMIT으로 건수를 제한할 수 있다.- 쿼리에 인덱스를 사용하지 못하는 정렬이나 그루핑 작업이 왜 느리게 작동할 수밖에 없는지 알아본다. 이를 위해 쿼리가 처리가 실행되는 방법을 “스트리밍 처리"와 “버퍼링 처리"라는 2가지 방식으로 구분해 보자.
- 스트리밍 방식
- 서버 쪽에서 처리할 데이터가 얼마인지에 관계없이 조건에 일치하는 레코드가 검색될 때마다 바로바로 클라이언트로 전송해주는 방식을 의미한다.
- 클라이언트는 MySQL 서버가 일치하는 레코드를 찾는 즉시 전달받기 때문에 동시에 데이터의 가공 작업을 시작할 수 있다.
- 스트리밍 방식으로 처리되는 쿼리는 쿼리가 얼마나 많은 레코드를 조회하느냐에 상관없이 빠른 응답 시간을 보장해준다.
- 스트리밍 방식으로 처리되는 쿼리에서
LIMIT처럼 결과 건수를 제한하는 조건들은 쿼리의 전체 실행 시간을 상당히 줄여줄 수 있다. 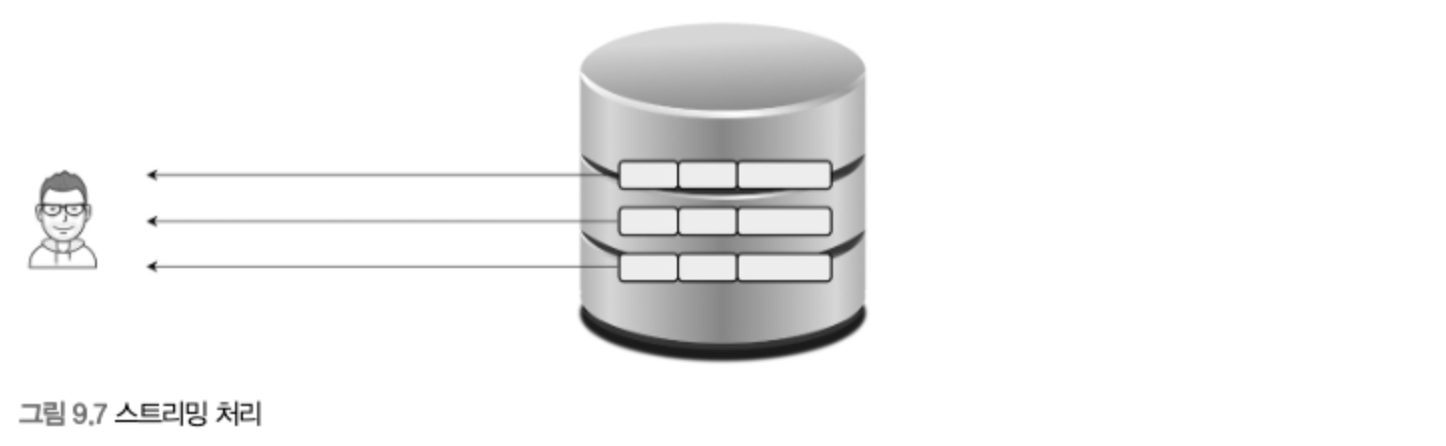
- 버퍼링 방식
ORDER BY나GROUP BY같은 처리는 쿼리의 결과가 스트리밍되는 것을 불가능하게 한다.- 모든 레코드를 검색하고 정렬 작업을 하는 동안 클라이언트는 아무것도 하지 않고 기다려야 하기 때문에 응답 속도가 느려진다.
- 버퍼링 방식으로 처리되는 쿼리는
LIMIT처럼 결과 건수를 제한하는 조건이 있었도 성능 향상에 별도 도움이 되지 않는다. - 스트리밍 처리는 어떤 클라이언트 도구나 API를 사용하느냐에 따라 그 방식에 차이가 있을 수도 있다.
- 대표적으로 JDBC 라이브러리를 이용해 쿼리를 실행하면 MySQL 서버는 레코드를 읽자마자 클라이언트로 그 결과를 전달하지만, JDBC는 MySQL 서버로부터 받은 레코드를 일단 내부 버퍼에 모두 담아둔다.
- 그리고 마지막 레코드가 전달될 때까지 기다렸다가 모든 결과를 전달받으면 그때서야 비로소 클라이언트의 애플리케이션에 반환한다.
- JDB의 버퍼링 처리 방식은 기본 작동 방식이며, 아주 대량의 데이터를 가져와야 할 때는 MySQL 서버와 JDBC 간의 전송 방식을 스트리밍 방식으로 변경할 수 있다.
- 정렬 관련 상태 변수
- MySQL 서버는 처리하는 주요 작업에 대해서는 해당 작업의 실행 횟수를 상태 변수로 저장한다.
SHOW STATUS LIKE 'Sort%';Sort_merge_passes: 멀티 머지 처리 횟수Sort_range: 인덱스 레인지 스캔을 통해 검색된 결과에 대한 정렬 작업 횟수Sort_scan: 풀 테이블 스캔을 통해 검색된 결과에 대한 정렬 작업 횟수Sort_rows: 지금까지 정렬한 전체 레코드 건수
GROUP BY 처리
HAVING절은 인덱스를 사용해서 처리될 수 없으므로 튜닝하려고 인덱스를 생성하거나 다른 방법을 고민할 필요가 없다.GROUP BY작업도 인덱스를 사용하는 경우와 그렇지 못한 경우로 나눠 볼 수 있다.- 인덱스를 이용할 때는 인덱스 스캔 방법과 루스 인덱스 스캔이라는 방법으로 나뉜다.
- 인덱스를 사용하지 못하는 쿼리에서
GROUP BY작업은 임시 테이블을 사용한다.
- 인덱스 스캔을 이용하는 GROUP BY(타이트 인덱스 스캔)
ORDER BY경우와 마찬가지로 조인의 드라이빙 테이블에 손한 컬럼만 이용해 그루핑할 때GROUP BY칼럼으로 이미 인덱스가 있다면 그 인덱스를 차례대로 읽으면서 그루핑 작업을 수행하고 그 결과로 조인을 처리한다.GROUP BY가 인덱스르 사용해 처리된다 하더라도 그룹 함수(aggregation function) 등의 그룹값을 처리해야 해서 임시 테이블이 필요할 때도 있다.
- 루스 인덱스 스캔을 이용하는 GROUP BY
- 루스 인덱스 스캔을 사용할 때는 실행 계획의 Extra 컬럼에 “Using index for group-by” 코멘트가 표시된다.
- 루스 인덱스 스캔이 사용될 수 있을지 없을지 판단하는 것은 어렵다.
- 아래 쿼리는 루스 인덱스 스캔을 사용할 수 없는 쿼리 패턴이다.
- (col1, col2, col3) 컬럼으로 인덱스가 생성된 테이블이다.

- 임시 테이블을 사용하는 GROUP BY
- Extra 컬럼에 “Using temporary” 메시지가 표시된다.
- Extra 컬럼에 “Using filesort"는 표시되지 않는다.
- MySQL 8.0 이전 버전까지는 GROUP BY가 사용된 쿼리는 그루핑되는 컬럼 기준으로 묵시적인 정렬까지 함께 수행했다.
- 하지만 MySQL 8.0 버전부터는 이 같이 묵시적인 정렬은 더 이상 실행되지 않게 바뀌었다.
DISTINCT 처리
DISTINCT는 2가지로 구분해서 살펴본다.MIN(),MAX(),COUNT()같은 집합 함수와 함께 사용하는 경우- 집합 함수가 없는 경우
- 집합 함수와 같이
DISTINCT가 사용되는 쿼리 실행 계획에서DISTINCT처리가 인덱스를 사용하지 못할 때는 항상 임시 테이블을 사용한다. - 단순히
SELECT되는 레코드 중에서 유니크한 레코드만 가져오고자 하면GROUP BY와 동일한 방식으로 처리한다.- 아래 두 쿼리는 같은 작업으로 수행한다.
SELECT DISTINCT emp_no FROM salaries;SELECT emp_no FROM salaries GROUP BY emp_no;
- 아래 두 쿼리는 같은 작업으로 수행한다.
- 집합 함수 내에서 사용된
DISTINCT는 그 집합 함수의 인자로 전달된 컬럼값이 유니크한 것들을 가져온다.- 아래 쿼리는 내부적으로
COUNT(DISTINCT s.salary)를 처리하기 위해 임시 테이블을 사용한다. 하지만DISTINCT를 처리하기 위해 생성되는 임시테이블은 “Using temporary"를 표시하지 않고 있다. 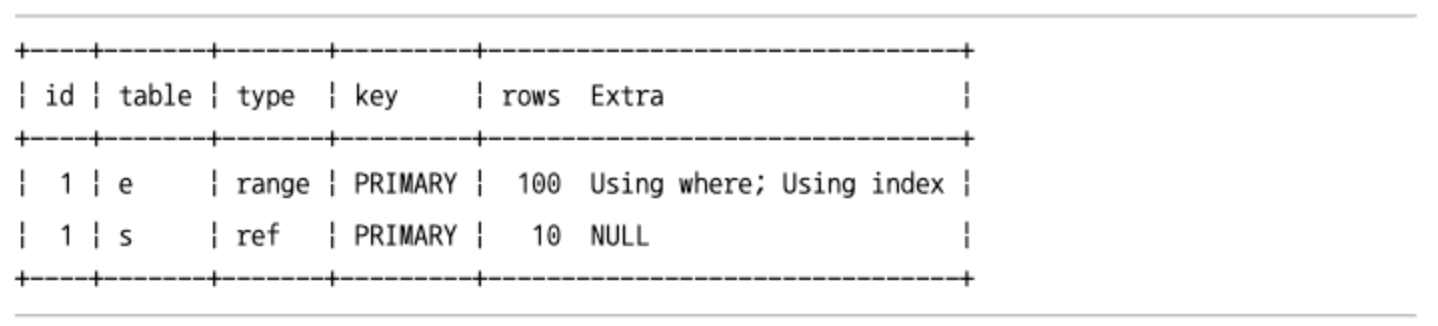
- 아래 쿼리는 내부적으로
EXPLAIN SELECT COUNT(DISTINCT s.salary)
FROM employees e, salaries s
WHERE e.emp_no=s.emp_no
AND e.emp_no BETWEEN 100001 AND 100100;
- 아래 쿼리는 2개의 임시 테이블을 사용한다.
SELECT COUNT(DISTINCT s.salary), COUNT(DISTINCT e.last_name)
FROM employees e, salaries s
WHERE e.emp_no=s.emp_no
AND e.emp_no BETWEEN 100001 AND 100100;
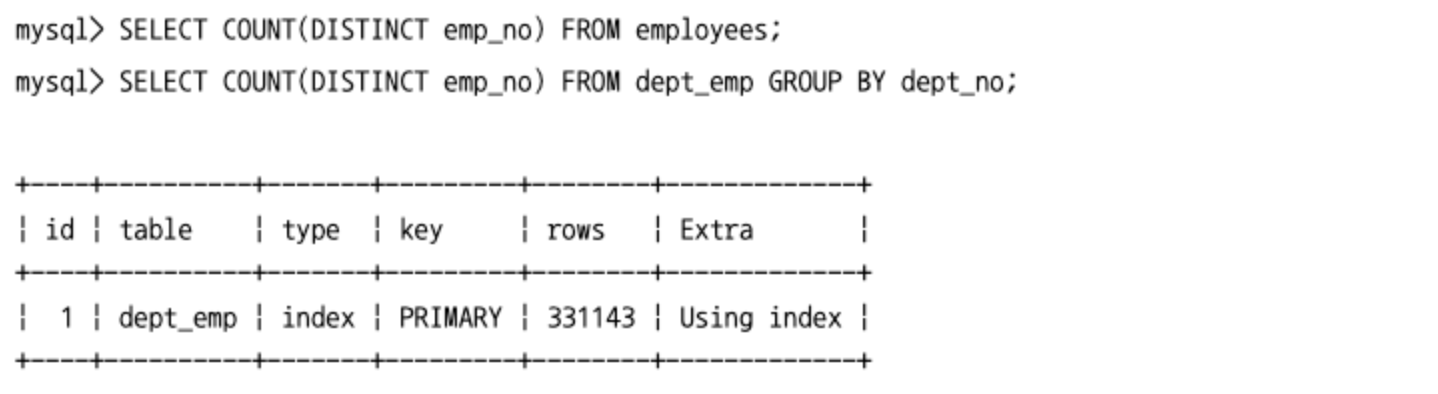
- 아래의 쿼리의 경우는
DISTINCT처리를 수행할 때 인덱스를 풀 스캔하거나 레인지 스캔하면서 임시 테이블 없이 최적화된 처리를 수행할 수 있다.
내부 임시 테이블 활용
- MySQL 엔진이 스토리지 엔진으로부터 받아온 레코드를 정렬하거나 그루핑할 때는 내부적인 임시 테이블을 사용한다.
- MySQL 엔진이 사용하는 임시 테이블은 처음에는 메모리에 생성됐다가 테이블의 크기가 커지면 디스크로 옮겨진다.
- MySQL 엔진이 내부적인 가공을 위해 생성하는 임시 테이블은 다른 세션이나 다른 쿼리에서는 볼 수 없으며 사용하는 것도 불가능하다.
- 사용자가 생성한 임시 테이블(
CREATE TEMPORARY TABLE)과는 다르게 내부적인 임시 테이블은 쿼리의 처리가 완료되면 자동으로 삭제된다. - MySQL 8.0 이전 버전까지는 원본 테이블의 스토리지 엔진과 관계없이 임시테이블이 메모리를 사용할 때는 MEMORY 스토리지 엔진을 사용하며, 디스크에 저장될 때는 MyISAM 스토리지 엔진을 이용한다.
- MEMORY 스토리지 엔진은
VARBINARY나VARCHAR같은 가변 길이 타입을 지원하지 못하기 때문에 임시 테이블이 메모리에 만들어지면 가변 길이 타입의 경우 최대 길이만큼 메모리를 할당해서 사용한다. 이는 ㅁ네모리 낭비가 심해지는 문제점을 가지고 있다. - MyISAM 스토리지 엔진은 트랜잭션을 지원하지 못한다는 문제점을 가지고 있다.
- MEMORY 스토리지 엔진은
- MySQL 8.0부터는
internal_tmp_mem_storage_engine시스템 변수를 이용해 메모리용 임시 테이블을 MEMORY와 TempTable(기본값)을 사용할 수 있다.- TempTable이 최대한 사용 가능한 메모리 공간의 크기는
temptable_max_ram시스템 변수로 제어할 수 있는데, 기본값은 1GB로 설정돼 있다. - 임시 테이블의 크기가 1GB보다 커지는 경우 MySQL 서버는 메모리의 임시테이블을 디스크로 기록하게 되는데, 이때 MySQL 서버는 다음의 2가지 디스크 저장 방식 중 하나를 선택한다.
- MMAP 파일로 디스크에 기록
- InnoDB 테이블로 기록
- TempTable이 최대한 사용 가능한 메모리 공간의 크기는
- MySQL 8.0부터는 MMAP 파일로 기록할지 InnoDB 테이블로 전환할지는
temptable_use_mmap시스템 변수로 설정할 수 있는데, 기본값은ON(mmap)으로 설정돼 있다.- 메모리의 TempTable을 MMAP 파일로 전환하는 것은 InnoDB 테이블로 전환하는 것보다 오버헤드가 적기 때문에
temptable_use_mmap시스템 변수의 기본값이ON으로 선택된것이다.
- 메모리의 TempTable을 MMAP 파일로 전환하는 것은 InnoDB 테이블로 전환하는 것보다 오버헤드가 적기 때문에
- 하지만 내부 임시테이블이 메모리에 생성되지 않고 처음부터 디스크 테이블로 생성되는 경우도 있다.
- 이 경우는
internal_tmp_disk_storage_engine시스템 변수에 설정된 스토리지 엔진이 사용되고, 기본값은 InnoDB다.
- 이 경우는
- 임시 테이블이 필요한 쿼리
- ORDER BY와 GROUP BY에 명시된 컬럼이 다른 쿼리
- ORDER BY나 GROUP BY에 명시된 컬럼이 조인의 순서상 첫 번째 테이블이 아닌 쿼리
- DISTINCT와 ORDER BY가 동시에 쿼리에 존재하는 경우 또는 DISTINCT가 인덱스로 처리되지 못하는 쿼리
- UNION이나 UNION DISTINCT가 사용된 쿼리
- 쿼리의 실행 계획에서 select_type이 DERIVED인 쿼리
- 임시 테이블이 바로 디스크 기반으로 사용되는 경우
- UNION이나 UNION ALL에서 SELECT 되는 컬럼 중에서 길이가 512바이트 이상인 크기의 컬럼이 있는 경우
- GROUP BY나 DISTICT 컬럼에서 512바이트 이상인 크기의 컬럼이 있는 경우
- 메모리 임시 테이블의 크기가 (MEMORY 스토리지 엔진에서) tmp_table_size 또는 max_heap_table_size 시스템 변수보다 크거나 (TempTable 스토리지 엔진에서) temptable_max_ram 시스템 변수 값보다 큰 경우
- 임시 테이블 관련 상태 변수
- 임시 테이블이 디스크에 생성됐는지 메모리에 생성됐는지 확인하려면 MySQL 서버의 상태 변수를 확인해 보면된다.
FLUSH STATUS로 현재 세션의 상태 값을 초기화한다.Created_tmp_tables: 쿼리의 처리를 위해 만들어진 내부 임시 테이블의 개수를 누적하는 상태 값이다. 이 값은 내부 임시 테이블이 메모리에 만들어졌는지 디스크에 만들어졌는지 구분하지 않고 모두 누적한다.Created_tmp_disk_tables: 디스크에 내부 임시 테이블이 만ㄷ늘어진 개수만 누적해서 가지고 있는 상태 값이다.