- Cache Stampede가 무엇인지 이해한다.
- Cache Stampede를 해결하기 위해 적용할 수 있는 방법을 이해한다.
Cache Stampede 란?#
- server side cache는 자주 바뀌지 않는 데이터에 대해서 데이터베이스 읽기 동작을 최소화 하기위해 캐싱한다.
- redis를 사용한다고 하면, redis로 데이터를 조회한 후 존재하지 않는다면 데이터베이스로 조회를 하고, 이를 redis에 저장한다.
- 이런 경우 일반적으로 캐시에 TTL(만료 기간)을 설정해둔다.
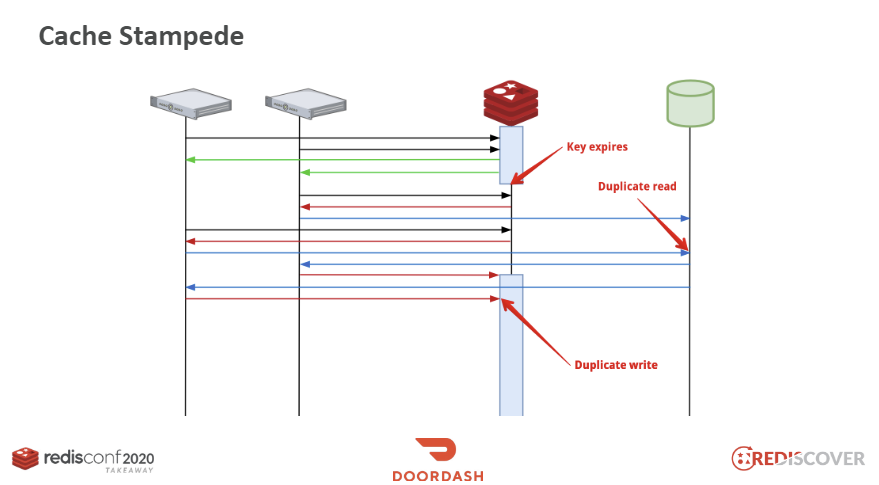
- 이 경우 트래픽이 1000rps 인 서비스에서 redis의 데이터가 TTL 만료가 되었다고 했을 때, 1초동안 redis에 캐싱을 하지 못 한다면 1초 동안 1000개의 요청이 모두 데이터베이스를 조회하면서 데이터베이스에 부하를 줄 수 있다.
- 이를 Cache Stmpede라고 부른다.
해결 방법1: Locking#
- TTL 만료시 DB를 조회해서 다시 캐시에 저장하는 과정을 lock을 획득하도록 한다.
- lock이 획득된 동안에 데이터 조회가 필요하면, 캐시가 성공적으로 저장될 때까지 대기를 하거나 이전 버전의 캐시를 조회하도록 할 수 있다.
해결 방법2: 주기적인 캐시 갱신#
- 외부 프로세스나 스레드를 통해 주기적으로 캐시 값을 재갱신하도록 만든다.
해결 방법3: Probabilistic Early Expiration(PER)#
- TTL이 만료되기 전에 확률적으로 캐시를 재갱신한다.
- TTL 만료 시각에 가까워질수록 재갱신 될 확률이 높아진다.
- 주로 사용하는 PER 갱신 기준은 “TTL까지 남은 시간 <= -∆β log(rand())” 으로 처리한다.
참고 자료#