- Elasticsearch 내부 동작을 이해한다.
- Elasticsearch에 새로운 컬럼?을 추가해본다.
데이터 색인#
- 색인(indexing): 데이터가 검색될 수 있는 구조로 변경하기 위해 원본 문서를 검색어 토큰들로 변환하여 저장하는 과정
- 인덱스(index): 색인을 거친 결과물, 또는 색인된 데이터가 저장되는 저장소. Elasticsearch에서 도큐먼트들의 논리적인 집합을 표현하는 단위이기도 하다.
- 검색(search): 인덱스에 들어있는 검색어 토큰들을 포함하고 있는 문서를 찾아과는 과정
- 질의(query): 사용자가 원하는 문서를 찾거나 집계 결과를 출력하기 위해 검색 시 입력하는 검색어 또는 검색 조건
Elasticsearch 환경 설정#
config/jvm.options: 힙 메모리 설정 가능하다.
-Xms1g
-Xmx1g
config/elasticsearch.yml: elasticsearch 실행 환경에 대한 대부분의 설정cluster.name: "<클러스터명>": 노드들은 클러스터명이 같으면 같은 클러스터로 묶이고, 클러스터명이 다르면 동일한 물리적 장비나 바인딩이 가능한 네트워크상에 있더라도 서로 다른 클러스터로 바인딩 된다.node.name: "<노드명>": 설정하지않으면 프로세스 UUID의 첫 7글자가 노드명으로 설정된다.node.attr.<key>: "<value>": 노드별로 속성을 부여하기 위한 일종의 네임스페이스path.data: [ "<경로>" ]: 색인된 데이터를 저장하는 경로path.logs: "<경로>": 실행 로그를 저장하는 경로bootstrap.memory_lock: true: elasticsearch가 사용중인 힙메머리 영역을 달느 자바 프로그램이 간섭 못하도록 미리 점유하는 설정. true 권장.network.host: <ip 주소>: elasticsearch가 실행되는 서버의 ip 주소. 디폴트는 루프백(127.0.0.1)이고, 디폴트를 사용할 경우 개발 모드로 실행이 된다. ip 주소를 변경하게 되면 운영모드로 실행된다.http.port: <포트 번호>: elasticsearch가 클라이언트와 통신하기 위한 http 포트 설정transport.port: <포트 번호>: elasticsearch 노드들 끼리 통신하기 위한 tcp 포트 설정discovery.seed_hosts: [ "<호스트-1>", "<호스트-2>", ... ]: 클러스터 구성을 위해 바인딩할 원격 노드들의 IP 또는 도메인 주소를 배열 형태로 입력cluster.initial_master_nodes: [ "<노드-1>", "<노드-2>" ]: 클러스터가 최초 실행 될 때 명시된 노드들을 대상으로 마스터 노드를 선출한다.
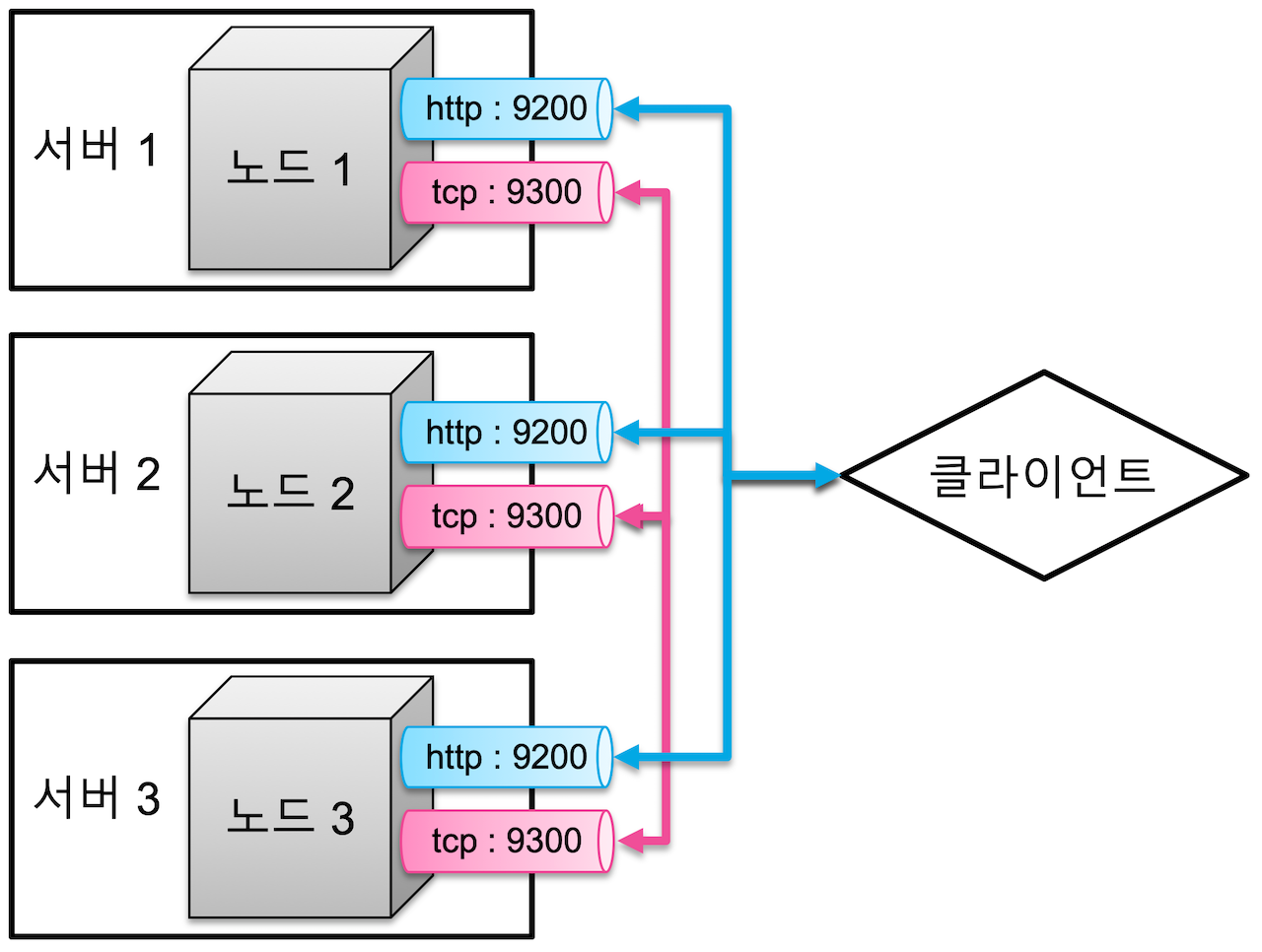
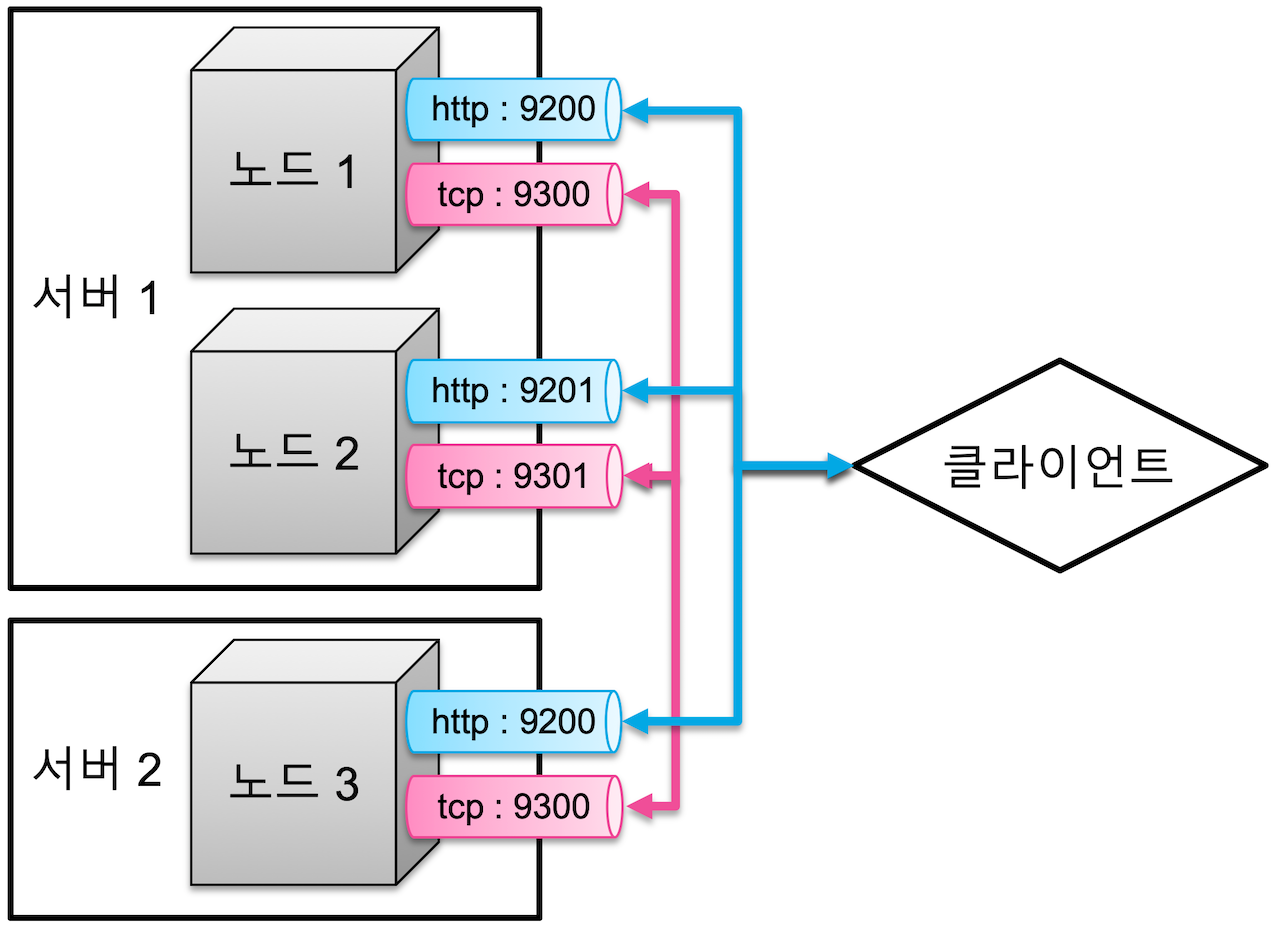
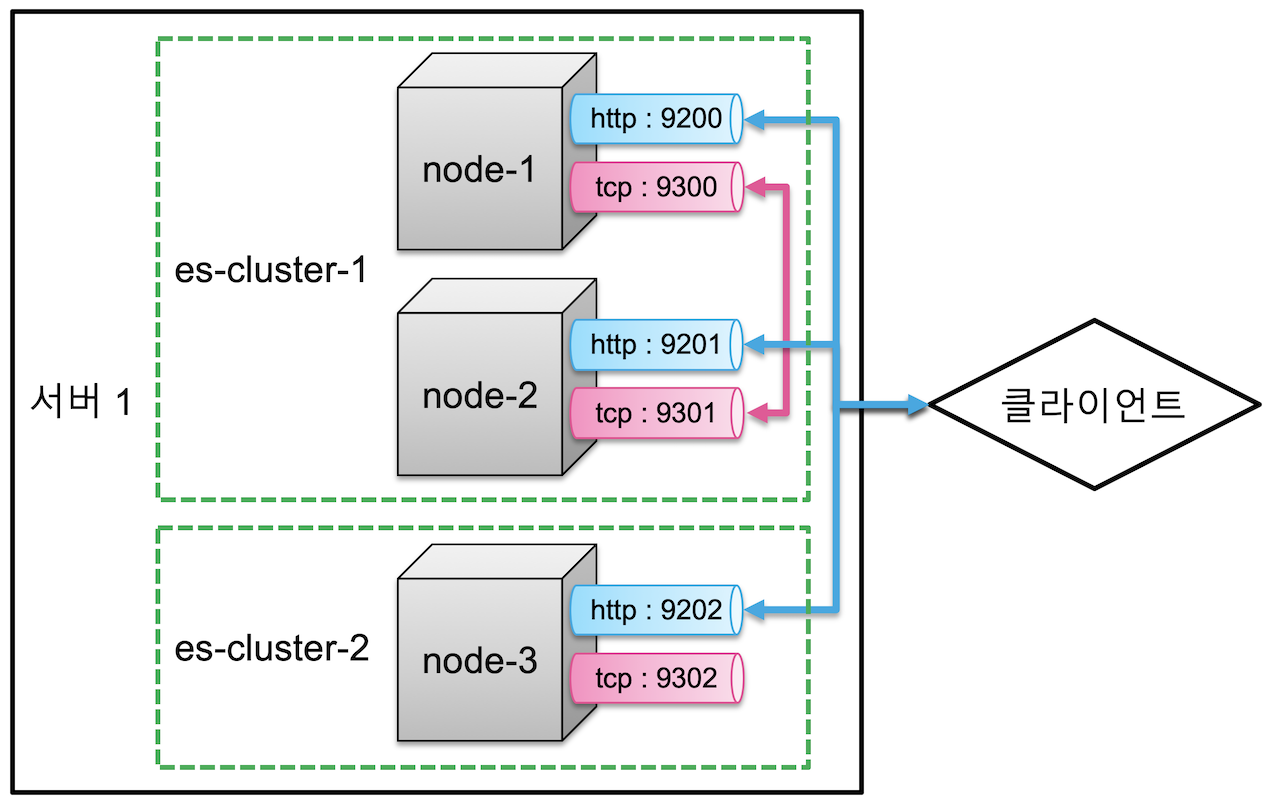
클러스터 구성#
- 여러 개의 서버를 하나의 클러스터로 구성
- 하나의 서버에서 여러 클러스터 실행
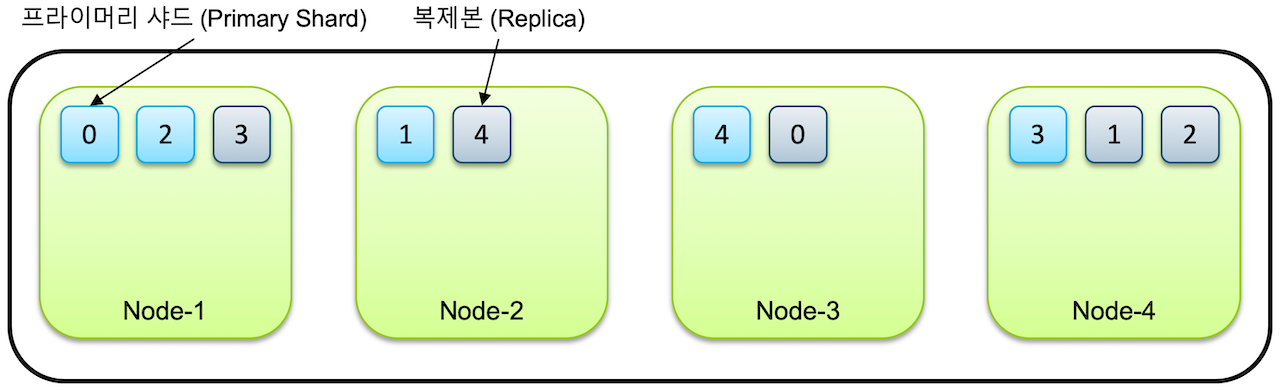
인덱스와 샤드#
- 도큐먼트: elasticsearch에서 단일 데이터 단위
- 인덱스: 도큐먼트를 모아놓은 집합
- 샤드: 인덱스가 분리되는 단위로, 각 노드에 분산되어 저장한다.
- 클러스터에 노드를 추가하게 되면 샤드들이 각 노드들로 분산되고 디폴트로 1개의 복제본을 생성한다.
- 프라이머리 샤드: 처음으로 생성된 샤드
- 리플리카: 복제본
- 노드가 1개만 있는 경우는 리플리카가 생성되지 않는다.
- 프라이머리와 복제본는 반드시 서로 다른 노드에 저장된다.
- 샤드 수는 인덱스를 처음 생성할 때 지정하며, 인덱스를 재색인 하지 않는 이상 바꿀 수 없다.
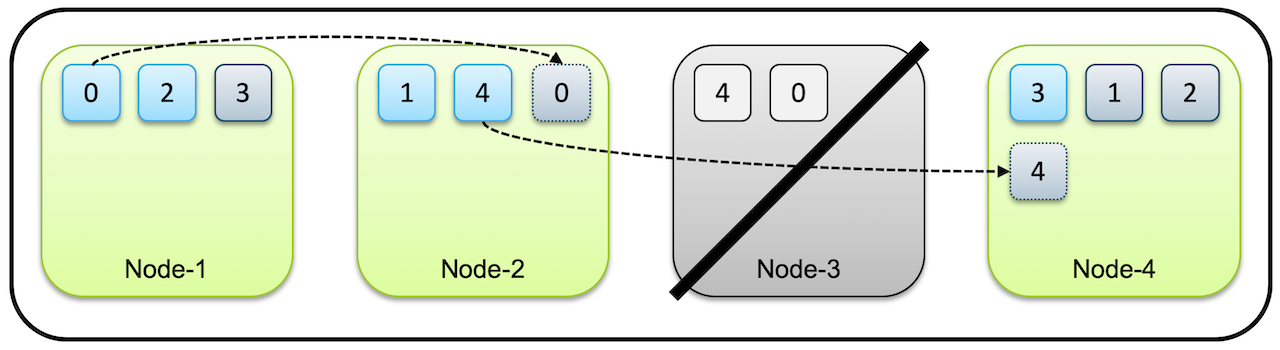
마스터 노드와 데이터 노드#
- 마스터 노드
- 인덱스의 메타 데이터, 샤드의 위치와 같은 클러스터 상태 정보를 관리한다.
- 클러스터마다 하나의 마스터 노드가 존재하며 마스터 노드의 역할을 수행할 수 있는 노드가 없다면 클러스터는 작동이 정지한다.
- 마스터 역할을 수행하고 있는 노드가 끊어지거나 다운되면 마스터 후보 노드 중 하나가 마스터 노드로 선출된다.
- 클러스터가 커져서 노드와 샤드의 개수가 많아지게 되면 모든 노드들이 마스터 노드의 정보를 계속 공유하는 것은 부담이 될 수 있어, 마스터 후보 노드들을 따로 설정해서 유지하는 것이 성능에 도움이 된다. (
node.master: false)
- 데이터 노드
- 실제로 색인된 데이터를 저장하고 있는 노드
- 마스터 후보 노드들은
node.data: false로 설정하여 마스터 노드 역할만 하고 데이터는 저장하지 않도록 할 수 있다.
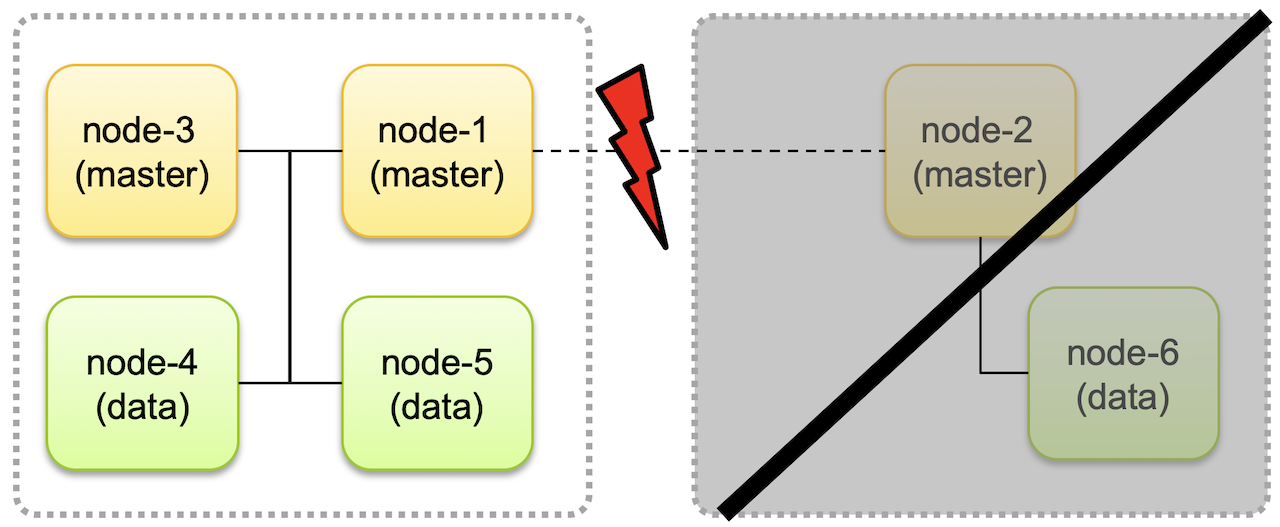
- 마스터 후보 노드는 홀수개가 좋다. 짝수개면 Split Brain 문제가 발생한다.
- Split Brain
- 네트워크 유실로 인해 클러스터가 두개로 분리되면, 각자가 서로 다른 클러스터로 구성되어 계속 동작할 수 있다.
- 이후에 네트워크가 복구되고 하나의 클러스터로 합쳐졌을 때 데이터 정합성 문제가 생길 수 있다.
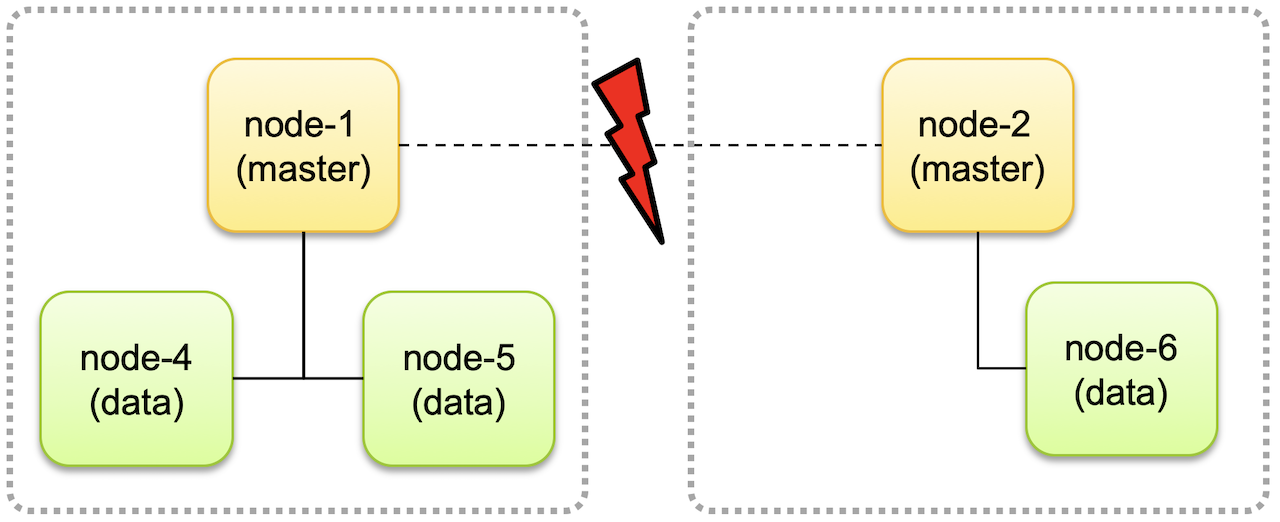
- 마스터 후보 노드를 홀수개로 두고, 클러스터가 분리되었을 때 노드의 개수가 과반수보다 적은 경우에는 클러스터 동작을 멈추도록 하면 split brain 문제가 해결된다.
데이터 처리#
- Elasticsearch는 REST API를 통해 데이터 crud 작업을 한다.
- 단일 도큐먼트별로 고유한 url을 갖는다.
http://<호스트>:<포트>/<인덱스>/_doc/<도큐먼트 id>
- _bulk API로 index, create, update, delete 동작이 가능하며 delete를 제외하고는 명령문과 데이터문을 한 줄씩 순서대로 입력해야 한다.
POST _bulk
{"index":{"_index":"test", "_id":"1"}}
{"field":"value one"}
{"index":{"_index":"test", "_id":"2"}}
{"field":"value two"}
{"delete":{"_index":"test", "_id":"2"}}
{"create":{"_index":"test", "_id":"3"}}
{"field":"value three"}
{"update":{"_index":"test", "_id":"1"}}
{"doc":{"field":"value two"}}
GET <인덱스명>/_search로 검색을 할 수 있다. 검색은 인덱스 단위로 이루어진다.q 파라미터를 사용해서 검색어를 입력할 수 있다.AND, OR, NOT 으로 조건을 추가할 수 있다.GET test/_search?q=value AND three
- 검색어를 특정 필드에서 검색하고 싶다면
<필드명>:<검색어> 형태로 입력하면 된다.GET test/_search?q=field:value
- 데이터 본문 검색: 검색 쿼리를 데이터 본문으로 입력하는 방식
GET test/_search
{
"query": {
"match": {
"field": "value"
}
}
}
검색과 쿼리#
풀 텍스트 쿼리#
match_all#
GET my_index/_search
{
"query":{
"match_all":{ }
}
}
match#
- 특정 필드에 검색어가 포함되어 있는지 검색하는 쿼리
GET my_index/_search
{
"query": {
"match": {
"message": "dog"
}
}
}
- 여러 개의 검색어를 넣게되면 디폴트로 OR 조건으로 검색된다.
GET my_index/_search
{
"query": {
"match": {
"message": "quick dog"
}
}
}
- 검색어가 여러 개일 때 OR가 아닌 AND로 검색하려면
operator 옵션을 추가할 수 있다.
GET my_index/_search
{
"query": {
"match": {
"message": {
"query": "quick dog",
"operator": "and"
}
}
}
}
match_phrase#
GET my_index/_search
{
"query": {
"match_phrase": {
"message": "lazy dog"
}
}
}
slop 이라는 옵션으로 단어 사이에 다른 검색어가 끼어드는 것을 허용할 수 있다.- 1로 설정하면 단어 사이에 1개의 단어까지만 허용한다.
GET my_index/_search
{
"query": {
"match_phrase": {
"message": {
"query": "lazy dog",
"slop": 1
}
}
}
}
Bool 복합 쿼리#
- must: 쿼리가 참인 도큐먼트들을 검색
- must_not: 쿼리가 거짓인 도큐먼트들을 검색
- should: 검색 결과 중 이 쿼리에 해당하는 도큐먼트의 점수를 높임
- filter: 쿼리가 참인 도큐먼트를 검색하지만 스코어를 계산하지 않는다. must 보다 검색 속도가 빠르고 캐싱이 가능하다.
GET <인덱스명>/_search
{
"query": {
"bool": {
"must": [
{ <쿼리> }, …
],
"must_not": [
{ <쿼리> }, …
],
"should": [
{ <쿼리> }, …
],
"filter": [
{ <쿼리> }, …
]
}
}
}
- should는 match_phrase 와 함께 유용하게 사용할 수 있다.
- 검색 결과 중에서 입력한 검색어 전체 문장이 정확히 일치하는 결과를 맨 상위에 위치 시키면 다른 결과를 누락시키지 않으면서 사용자가 정확하게 원하는 것을 제공할 수 있다.
GET my_index/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": {
"query": "lazy dog"
}
}
}
],
"should": [
{
"match_phrase": {
"message": "lazy dog"
}
}
]
}
}
}
정확값 쿼리#
- 값이 정확히 일치 하는지 여부 만 따지고, 스코어를 계산하지 않는다.
bool 쿼리에서 filter 내부에서 사용하게 된다.- 문자열 데이터는
keyword 형식으로 저장하여 정확값 검색이 가능하다.
GET my_index/_search
{
"query": {
"bool": {
"filter": [
{
"match": {
"message.keyword": "Brown fox brown dog"
}
}
]
}
}
}
범위 쿼리#
- 숫자나 날짜 형식들은 range 쿼리를 이요해 검색을 할 수 있다.
- gte: 이상
- gt: 초과
- lte: 이하
- lt: 미만
GET phones/_search
{
"query": {
"range": {
"price": {
"gte": 700,
"lt": 900
}
}
}
}
- 모든 인덱스는 settings와 mappings 두 개의 정보 단위를 가지고 있다.
- my_index의 settgins, mappings 확인
- 프라이머리 샤드 수는 인덱스를 처음 생성할 때 한번 지정하면 바꿀 수 없다. 바꾸려면 새로 인덱스를 정의하고 기존 인덱스의 데이터를 재색인해야 한다.
// request
GET my_index
// response
{
"my_index" : {
"aliases" : { },
"mappings" : { },
"settings" : {
"index" : {
"creation_date" : "1568695052917",
"number_of_shards" : "1", // 프라이머리 샤드 수
"number_of_replicas" : "1", // 리플리카 수
"uuid" : "Ol2vvLbgSfiJcjDC0Eo85A",
"version" : {
"created" : "7030099"
},
"provided_name" : "my_index"
}
}
}
}
settings#
// my_index 생성
PUT my_index
{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
- refresh_interval: 세그먼트가 만들어지는 리프레시 타임
mappings#
- elasticsearch는 동적 매핑을 지원하기 때문에 미리 정의하지 않아도 인덱스에 도큐먼트를 새로 추가하면 자동으로 매핑이 생성된다.
- 데이터가 입력되어 자동으로 매핑이 생성되기 전에 미리 먼저 인덱스의 매핑을 정의 해놓으면 정의 해 놓은 매핑에 맞추어 데이터가 입력된다.
PUT <인덱스명>
{
"mappings": {
"properties": {
"<필드명>":{
"type": "<필드 타입>"
… <필드 설정>
}
…
}
}
}
PUT <인덱스명>/_mapping
{
"properties": {
"<추가할 필드명>": {
"type": "<필드 타입>"
… <필드 설정>
}
}
}