- Spring Batch의 구조를 이해한다.
- Spring Batch 사용법을 이해한다.
Spring Batch 구조#
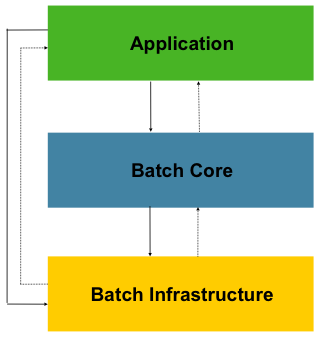
- 스프링 배치는 Application, Batch Core, Batch Infrastructure 3가지 컴포넌트를 가진다.
- Application: 개발자가 작성하는 모든 배치 job과 사용자 정의 코드가 있다.
- Batch Core: 배치 작업을 시작하고 제어하는 데 필요한 핵심 런타임 클래스가 포함되어 있다.
JobLauncher, Job, Step 구현체가 존재한다.
- Batch Infratstructure: 애플리케이션 개발자와 배치 코어에서 사용하는 클래스들이 포함되어 있다.
ItemReader, ItemWriterRetryTemplate
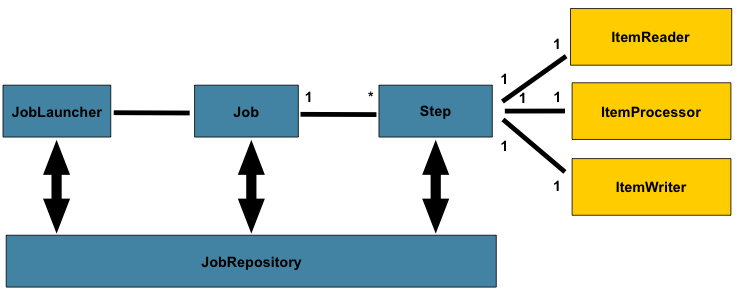
- 하나의
Job에는 여러 개의 Step이 있고, Step에는 ItemReader, ItemProcessor, ItemWriter를 하나씩 가지고 있다. Job: 배치 과정 전체의 캡슐화Step: job의 각 순차적인 단계의 캡슐화JobRepository: JobLaucnher, Job, Step에 구현체의 CRUD를 제공한다.JobLauncher: Job을 실행하는 역할ItemReader: Step의 input을 나타내는 추상화ItemWriter: Step의 output을 나타내는 추상화ItemProcessor: ItemReader가 읽고, ItemWriter가 쓰는 사이에 해야되는 비즈니스 처리의 추상화
Spring Batch 사용해보기#
configuration 클래스에서 ItemReader, ItemWriter, ItemProcessor 빈 등록하기#
@Bean
public FlatFileItemReader<Person> reader() {
return new FlatFileItemReaderBuilder<Person>()
.name("personItemReader")
.resource(new ClassPathResource("sample-data.csv"))
.delimited()
.names(new String[]{"firstName", "lastName"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<Person>() {{
setTargetType(Person.class);
}})
.build();
}
@Bean
public PersonItemProcessor processor() {
return new PersonItemProcessor();
}
@Bean
public JdbcBatchItemWriter<Person> writer(DataSource dataSource) {
return new JdbcBatchItemWriterBuilder<Person>()
.itemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>())
.sql("INSERT INTO people (first_name, last_name) VALUES (:firstName, :lastName)")
.dataSource(dataSource)
.build();
}
- 위 예에서는
FlatFileItemReader를 ItemReader로, JdbcBatchItemWriter를 ItemWriter로, PersonItemProcessor를 ItemProcessor로 사용하고 있다. FlatFileItemReader: 파일을 라인 단위로 읽는 ItemReaderJdbcBatchItemWriter: NamedParameterJdbcTemplate를 통해 모든 아이템을 쓰는 ItemWiterPersonItemProcessor: 사용자가 정의한 ItemProcessor의 구현체ItemProcessor의 첫 번째 타입 파라미터가 input, 두 번째 타입 파라미터가 output이 된다.
public class PersonItemProcessor implements ItemProcessor<Person, Person> {
private static final Logger log = LoggerFactory.getLogger(PersonItemProcessor.class);
@Override
public Person process(final Person person) throws Exception {
final String firstName = person.getFirstName().toUpperCase();
final String lastName = person.getLastName().toUpperCase();
final Person transformedPerson = new Person(firstName, lastName);
log.info("Converting (" + person + ") into (" + transformedPerson + ")");
return transformedPerson;
}
}
configuration 클래스에 Job과 Step 빈 등록하기#
@Bean
public Job importUserJob(JobRepository jobRepository,
JobCompletionNotificationListener listener, Step step1) {
return new JobBuilder("importUserJob", jobRepository)
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(step1)
.end()
.build();
}
@Bean
public Step step1(JobRepository jobRepository,
PlatformTransactionManager transactionManager, JdbcBatchItemWriter<Person> writer) {
return new StepBuilder("step1", jobRepository)
.<Person, Person> chunk(10, transactionManager)
.reader(reader())
.processor(processor())
.writer(writer)
.build();
}
- 위 예에서는 job에 하나의 step만 존재한다.
- step에 reader, processor, writer를 등록한 것을 확인할 수 있다.
- Job의 실행 상태를 DB에 저장하기 때문에, Job의 실행 ID 발급을 위해
RunIdIncrementer을 등록한다. - step에서 한번에 쓸 데이터의 개수를 정의하기위해
chunk 메소드를 사용한다.
job 완료 확인#
JobExecutionListener의 구현체를 bean 등록하면, Job 실행 전과 후에 추가 로직을 작성할 수 있다.
@Component
public class JobCompletionNotificationListener implements JobExecutionListener {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
if(jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("!!! JOB FINISHED! Time to verify the results");
jdbcTemplate.query("SELECT first_name, last_name FROM people",
(rs, row) -> new Person(
rs.getString(1),
rs.getString(2))
).forEach(person -> log.info("Found <{{}}> in the database.", person));
}
}
}
참고 자료#