영속성(Persistence)이란?
프로세스와 별개로 데이터가 유지되는 성질을 말하며, 일반적으로는 별도의 저장 장치에 보존한다.
Persistence Layer
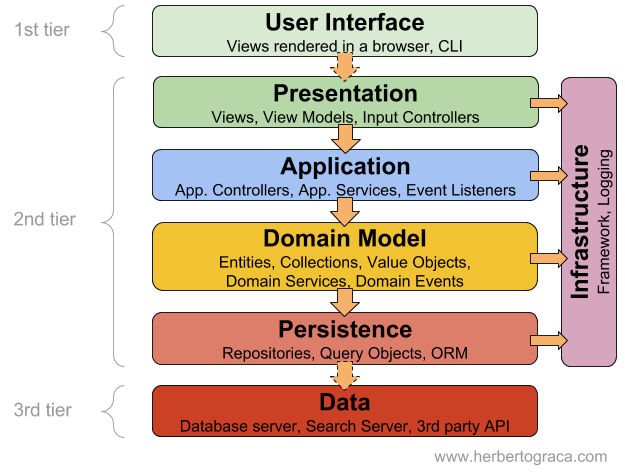
Layered Architecture에서 영속성을 관리하는 레이어를 Persistence Layer라고 부른다. 이 레이어는 위 레이어인 도메인 모델에 있는 객체들에게 영속성을 부여하는 역할을 한다. 일반적으로 Persistence Layer는 직접 영속성을 처리하지않고 DBMS를 사용하여 처리한다.
바로 이 Persistence Layer를 구현하는 방법으로는 크게 JDBC만을 이용하는 방법과 Persistence Framework를 사용하는 방법이 있다.
JDBC
JDBC(Java Database Connectivity)는 자바에서 데이터베이스에 접속할 수 있도록 하는 자바 API다. JDBC를 통해 DBMS의 종류에 상관없이 DB에 접근할 수 있도록 한다. 하지만 JDBC만 사용했을 경우 이전 글에서 볼 수 있듯이 다음과 같은 단점이 있다.
- DB에 접근할 때마다
Connection,Statement,ResultSet을 매번 열고 닫아줘야되어서 중복 코드가 많아진다. - 매번
SQLException이라는 Checked Exception을 직접 처리해줘야된다.
Persistence Framework
위에서 언급한 문제점을 해결하기 위해서 Persistence Framework를 사용한다. Persistence Framework는 내부적으로 JDBC를 사용하는데 앞에서 나온 반복적인 처리를 대신해준다. Persistence Framework는 SQL Mapper와 ORM으로 나눌 수 있다.
SQL Mapper
SQL문을 객체로 매핑시켜주는 프레임워크를 SQL Mapper라고 부른다. 대표적으로 Spring JDBC의 JdbcTemplate와 MyBatis가 있다. Spring JDBC의 경우에는 이전 글에서 볼 수 있듯이 SQL문의 결과를 객체에 매핑시켜주는 작업을 할 수 있다.
MyBatis의 경우에는 SQL 쿼리들을 XML파일로 따로 저장하여 코드와 SQL문을 분리하여 관리한다. MyBatis의 사용법은 여기서 다룰 주제는 아니므로 생략한다.
이렇게 JDBC만을 사용했을 때의 문제를 해결했지만 SQL Mapper의 경우에도 문제점이 있다. SQL Mapper의 경우에는 여전히 SQL문을 직접 다루기때문에 다음과 같은 문제를 가진다.
- DB에 종속적이기 쉽다. 즉, 도메인 모델의 객체지향적인 설계와 DB 테이블의 데이터 중심적인 설계에서 충돌이 발생할 수 있다. 이를 패러다임 불일치 문제라고 부른다.
- 각 테이블마다 비슷한 SQL문이 많기 때문에 반복되는 작업이 발생한다.
ORM
SQL문이 아닌 DB를 객체와 직접 매핑시켜주는 프레임워크를 ORM이라고 부른다. ORM은 SQL문을 개발자가 다루지 않고 메서드로 영속성을 유지한다. ORM의 대표적인 예가 JPA(Japa Persistence API)다. JPA는 자바 진영의 ORM 기술에 대한 API 표준 명세다.
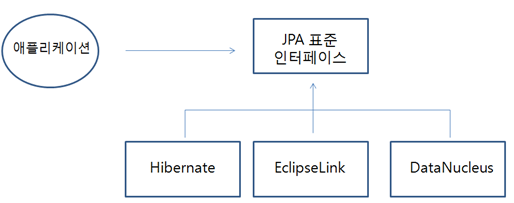
이 JPA 중 가장 대중적인 프레임워크가 Hibernate다. 이 JPA가 어떤 패러다임 불일치 문제를 해결해주는지 알아보자.
-
상속: 객체는 상속이라는 기능을 가지고 있지만 테이블에는 이런 상속이라는 기능이 없다. 아래와 같은 예시의 경우 DB에서는
Person과Crew라는 테이블을 따로 만들고Crew테이블에Person테이블의 키를 외래키로 가지도록 설계하게 될 것이다. 만약 개발자가 직접 SQL문을 작성한다면INSERT의 경우에도 각 테이블이 2번 날리게되고,SELECT의 경우에는 하나의 객체를 가져오는데JOIN문이 필요하게 될 것이다.class Person { Long id; String name; //... } class Crew extends Person { String nickname; //... }JPA는 이 상속과 관련된 패러다임 불일치를 개발자 대신 해결해준다. 따라서 객체를 가져오거나 저장할 때 아래와 같이 하나의 메서드만 호출하면 된다.
// 저장 jpa.persist(crew); // 가져오기 jpa.find(Crew.class, crewId); -
연관 관계: 객체가 참조를 사용해 다른 객체와 연관관계를 가지고 있는 경우이다. 아래와 같은 예시의 경우에는
Crew테이블에Team의 키를 외래키로 가지도록 설계하게 될 것이다.class Crew { Long id; String nickname; Team team; //... } class Team { Long id; String name; //... }JPA는 이러한 패러다임 불일치를 해결하여 아래와 같이 객체 간의 관계를 설정하고 저장만하면 되게 해준다.
crew.setTeam(team); jpa.persist(crew); Crew crew = jpa.find(Crew.class, crewId); Team team = crew.getTeam(); -
객체 그래프 탐색: SQL을 직접 다루다보면 현재 이 객체가 어느 객체까지 가져올 수 있는지에대한 확식하기가 힘들다. 아래의 예시의 경우에도 현재 SQL문이 제대로
Mission객체를 가지고 왔는지 확인을 해봐야된다.crew.getMission().getCoach(); // 현재 이 객체는 Coach 객체까지 가져왔나?JPA는 연관된 객체를 사용하는 시점에 적절한 SQL을 실행하면서, 개발자가 SQL문에대한 걱정을 하지 않을 수 있게 해준다.
-
비교: DB에서는 기본키의 값으롤 각 row를 비교하지만, 객체는 동일성 비교과 동등성 비교가 별도로 구분된다. 따라서 아래와 같이 SQL문을 직접 작성한 경우에는 두 객체가 다르다는 결과가 나올 것이다.
Member member1 = memberDao.getMember(memberId); Member member2 = memberDao.getMember(memberId);하지만 JPA를 사용할 경우에는 같은 행이면 같은 객체로 처리하도록 해주기 때문에 두 객체는 같다는 결과가 나올 것이다.
Member member1 = jpa.find(Member.class, memberId); Member member2 = jpa.find(Member.class, memberId);
이렇게 ORM은 개발자가 SQL문을 직접 작성하지 않아도되게 해줌으로써 패러다임 불일치를 해결하고 생산성이 좋아진다. 이 때, 정교한 쿼리 사용이 불가능 하지 않냐는 의문을 가질 수 있다. 하지만 JPA에는 SQL과 유사한 기술인 JPQL의 지원하기도 하고, SQL 자체 쿼리를 사용할 수도 있고 SQL Mapper와 혼용해서 사용도 가능하다.
참고 자료
https://www.youtube.com/watch?v=VTqqZSuSdOk
https://en.wikipedia.org/wiki/Persistence_(computer_science)
https://herbertograca.com/2017/08/03/layered-architecture/
https://gmlwjd9405.github.io/2018/12/25/difference-jdbc-jpa-mybatis.html
https://ultrakain.gitbooks.io/jpa/content/chapter1/chapter1.2.html
댓글남기기